CH7-HarmonyOS数据持久化
文章目录
- 前言
- 目标
- 1.创建Data Ability
-
- 创建Data
- 实现UserDataAbility
- URI介绍
- 2.文件存储
-
- 打开文件
- 访问Data
- 3.关系型数据库
-
- 基本概念
- 数据库的增删改查
- 数据库谓词的使用
- 查询结果集的使用
- 开发步骤
- 4.对象关系数据库
-
- 基本概念
- 运作机制
- ORM开发过程
- 数据服务端开发步骤
- 访问数据库-客户端
- 5.偏好文件
-
- 开发示例
- 6.分布式数据服务
-
- 分布式数据库ACID特性
- 运作机制
- 操作步骤
- 7.分布式文件系统服务
-
- 运作机制
- 操作步骤
- 本章总结
- 本章总结
前言
我们在前面章节的例子中碰到过很多类型的数据。
- 如在JS页面设计中,用户可以在输入框中输入对冰山图片的评论后发表,这里用户的评论就是文本数据。
- 这些数据是瞬时的,只存在于内存中,严格来说就是input对象的text属性值,
- 当程序关闭时,input对象也从内存中释放,评论数据就丢失了。
- 本章介绍的是应用程序如何访问持久化数据。
目标
- 掌握HarmonyOS中将数据持久化的几种主流方法,包括:
文件,关系数据库,对象关系数据库,分布式数据库,偏好文件和分布式文件。 - 此外,要注重理解
Data Ability的工作特点,它可以实现将数据访问接口统一化,屏蔽底层实现细节,对外提供统一的数据服务
1.创建Data Ability
Data Ability
- 使用Data模板的Ability(以下简称“Data”)有助于应用管理其自身和其他应用存储数据的访问,并提供与其他应用共享数据的方法。Data既可用于
同设备不同应用的数据共享, 也支持跨设备不同应用的数据共享。 - 数据的存放形式多样,可以是数据库,也可以是磁盘上的文件。Data对外提供对数据的
增、删、改、查,以及打开文件等接口,这些接口的具体实现由开发者提供
确定数据存储方式
- 确定数据的存储方式,Data支持以下两种数据形式:
- ·
文件数据:如文本、图片、音乐等。 结构化数据:如数据库等
- ·
创建Data
- 使用Data模板的Ability形式仍然是Ability,因此,开发者需要为应用
添加一个或多个 Ability的子类,来提供程序与其他应用之间的接口。Data为结构化数据和文件提供了不同 API接口供用户使用,因此,开发者需要首先确定好使用何种类型的数据。 - 本章节主要讲述 了创建Data的基本步骤和需要使用的接口。
- Data提供方可以
自定义数据的增、删、改、查,以及文件打开等功能,并对外提供这些 接口
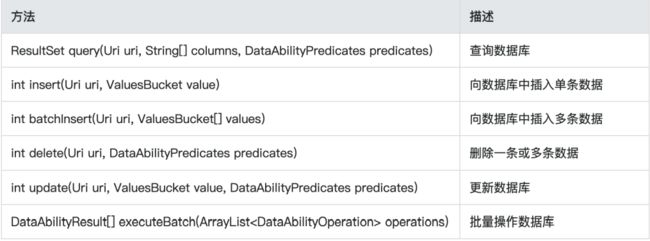
Data Ability数据库操作服务
- Ability定义了
6个方法供用户处理对数据库表数据的增删改查。这6个方法在Ability中已 默认实现,开发者可按需重写
实现UserDataAbility
- UserDataAbility用于
接收其他应用发送的请求,提供外部程序访问的入口,从而实现应用间的数据访问。 - 实现UserDataAbility,需要在“Project”窗口当前工程的主目录(“entry > src > main > java > com.xxx.xxx ”)选择“File > New > Ability > Empty Data Ability” ,设置 “Data Name”后完成UserDataAbility的创建。
- Data提供了
文件存储和数据库存储两组接口供用户使用
注册UserDataAbility
- 和Service Ability类似,开发者必须在配置配置文件中
注册Data Ability。 - 配置文件中该字段在创建Data Ability时会自动创建,
name与创建的Data Ability一致。 - 需要关注以下属性:
type: 类型设置为data;uri: 对外提供的访问路径,全局唯一;permissions: 访问该data ability时需要申请的访问权限
config.json中的Data Ability
{
"name": ".UserDataAbility",
"type": "data",
"visible": true,
"uri": "dataability://com.example.myapplication5.DataAbilityTest",
"permissions": [ "com.example.myapplication5.DataAbility.DATA"
]
}
URI介绍
- Data的提供方和使用方都通过URI(Uniform Resource Identifier)来标识一个具体的数 据,例如数据库中的某个表或磁盘上的某个文件。HarmonyOS的URI仍基于URI通用标 准,格式如下:

- 跨设备场景:dataability://device_id/com.huawei.dataability.persondata/person/10
- 本地设备:dataability:///com.huawei.dataability.persondata/person/10
URI格式解析
- ·
scheme:协议方案名,固定为“dataability”,代表Data Ability所使用的协议类型。 authority:设备ID。如果为跨设备场景,则为目标设备的ID;如果为本地设备场景,则不需要填写。path:资源的路径信息,代表特定资源的位置信息;query:查询参数;fragment:可以用于指示要访问的子资源
2.文件存储
- 开发者需要在Data中
重写FileDescriptor openFile(Uri uri, String mode)方法来操作文件:uri为客户端传入的请求目标路径;mode为开发者对文件的操作选项,可选方式包含 “ r ”(读), “ w ”(写), “ rw ”(读写)等。
- ohos.rpc.MessageParcel类提供了一个静态方法,用于获取MessageParcel实例。开发者 可通过获取到的MessageParcel实例,使用
dupFileDescriptor()函数复制待操作文件流的文件描述符,并将其返回,供远端应用访问文件
打开文件
根据传入的uri打开对应的文件
@Override
public FileDescriptor openFile(Uri uri, String mode) throws File
NotFoundException {
// 创建messageParcel
MessageParcel messageParcel = MessageParcel.obtain();
File file = new File(uri.getDecodedPathList().get(1));
if (mode == null || !"rw".equals(mode)) {
file.setReadOnly();
}
FileInputStream fileIs = new FileInputStream(file);
FileDescriptor fd = fileIs.getFD();
// 绑定文件描述符
return messageParcel.dupFileDescriptor(fd);
}
访问Data
- 开发者可以通过
DataAbilityHelper类来访问当前应用或其他应用提供的共享数据。 - `DataAbilityHelper作为客户端,与提供方的Data进行通信。Data接收到请求后,执行相应的处理,并返回结果。
- DataAbilityHelper提供了一系列与Data Ability对应的方法。使用步骤如下
声明使用权限
- 如果待访问的Data声明了访问
需要权限,则访问此Data需要在配置文件中声明需要此权限。
"reqPermissions": [
{
"name":
"com.example.myapplication5.DataAbility.DATA"
},
// 访问文件还需要添加访问存储读写权限
{
"name": "ohos.permission.READ_USER_STORAGE"
},
{
"name": "ohos.permission.WRITE_USER_STORAGE"
}
]
创建DataAbilityHelper
- DataAbilityHelper为开发者提供了
creator()方法来创建DataAbilityHelper实例。该方法 为 静 态 方 法 ,有 多 个 重 载。 最 常 见 的 方 法 是 通 过 传 入 一 个 c o n t e x t 对 象 来 创 建 DataAbilityHelper对象。获取helper对象示例:
DataAbilityHelper helper = DataAbilityHelper.creator(this);
访问Data Ability
- DataAbilityHelper为开发者提供了一系列的接口来
访问不同类型的数据(文件、数据库 等)。 - DataAbilityHelper为开发者提供了
FileDescriptor openFile(Uri uri, String mode)方法来 操作文件。此方法需要传入两个参数,- 其中
uri用来确定目标资源路径, mode用来指定 打开文件的方式,可选方式包含“ r ”(读), “ w ”(写), “ rw ”(读写), “wt”(覆盖写), “ wa ”(追加写), “rwt”(覆盖写且可读)
- 其中
- DataAbilityHelper为开发者提供了
客户端访问文件
- 该方法
返回一个目标文件的FD(文件描述符),把文件描述符封装成流,开发者就可以 对文件流进行自定义处理。访问文件示例:
// 读取文件描述符
FileDescriptor fd = helper.openFile(uri, "r");
// 使用文件描述符封装成的文件流,进行文件操作
FileInputStream fis = new FileInputStream(fd);
3.关系型数据库
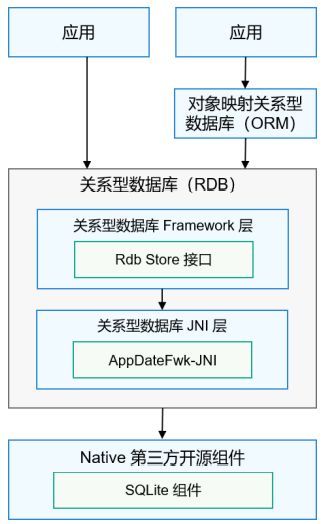
关系型数据库(Relational Database,RDB)是一种基于关系模型来管理数据的数据库。SQLite组件提供了一套完整的对本地数据库进行管理的机制,对外提供了一系列的增、删、改、查接口,也可以直接运行用户输入的SQL语句来 满足复杂的场景需要。HarmonyOS提供的关系型数据库功能更加完善,查询效率更高
基本概念
- 关系型数据库创建在关系模型基础上的数据库,
以行和列的形式存储数据谓词数据库中用来代表数据实体的性质、特征或者数据实体之间关系的词项,主要用来定义数据库的操作条件。结果集指用户查询之后的结果集合,可以对数据进行访问。结果集提供了灵活的数据访问方式,可以更方便的拿到用户想要的数据。SQLite数据库一款轻型的数据库,是遵守ACID的关系型数据库管理系统。它是一个开源的项目
运作机制
HarmonyOS关系型数据库对外提供通用的操作接口,底层使用SQLite作为持久化存储引擎,支持SQLite具有的所有数据库特性,包括但不限于事务、索引、视图、触发器、外键、参数化查询和预编译SQL语句

数据库的增删改查
- 新增:关系型数据库提供了插入数据的接口,通过
ValuesBucket输入要存储的数据,通 过返回值判断是否插入成功,插入成功时返回最新插入数据所在的行号,失败则返回-1

- 查询:关系型数据库提供了
两种查询数据的方式:直接调用查询接口。使用该接口,会将包含查询条件的谓词自动拼接成完整的SQL语句进行查 询操作,无需用户传入原生的SQL;执行原生的用于查询的SQL语句。

数据库谓词的使用
- 关系型数据库提供了用于
设置数据库操作条件的谓词AbsRdbPredicates,其中包括两个 实现子类RdbPredicates和RawRdbPredicates:RdbPredicates:开发者无需编写复杂的SQL语句,仅通过调用该类中条件相关的方法,如equalTo、notEqualTo、groupBy、orderByAsc、beginsWith等,就可自动完成SQL语句拼接, 方便用户聚焦业务操作;RawRdbPredicates:可满足复杂SQL语句的场景,支持开发者自己设置where条件子句和 whereArgs参数。不支持equalTo等条件接口的使用
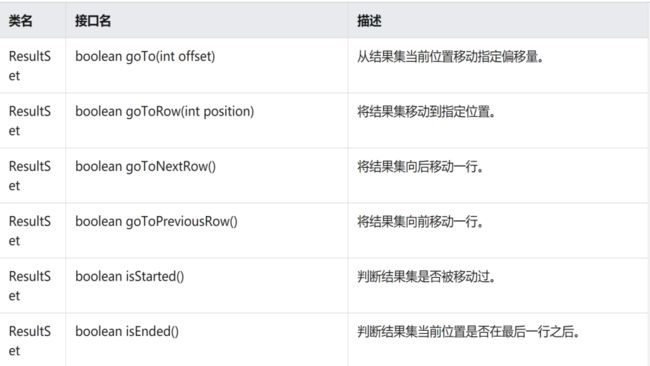
查询结果集的使用
- ·
关系型数据库提供了查询返回的结果集ResultSet,它指向查询结果中的一行数据,供用户对查询结果进行遍历和访问。ResultSet的对外API如下表格。
开发步骤
-
创建数据库:
配置数据库相关信息,包括数据库的名称、存储模式、是否为只读模式等。
-
初始化数据库表结构和相关数据。 -
创建数据库。
StoreConfig config = StoreConfig.newDefaultConfig("RdbStoreTest.db");
private static RdbOpenCallback callback = new RdbOpenCallback() {
@Override
public void onCreate(RdbStore store) {
store.executeSql("CREATE TABLE IF NOT EXISTS test (id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL, age INTEGER, salary REAL, blobType BLOB)");
}
@Override
public void onUpgrade(RdbStore store, int oldVersion, int newVersion) {}
};
DatabaseHelper helper = new DatabaseHelper(context);
RdbStorestore = helper.getRdbStore(config, 1, callback, null);
-
插入数据。
-
构造要插入的数据,以ValuesBucket形式存储。 -
调用关系型数据库提供的插入接口。
-
ValuesBucket values = new ValuesBucket();
values.putInteger("id", 1);
values.putString("name", "zhangsan");
values.putInteger("age", 18);
values.putDouble("salary", 100.5);
values.putByteArray("blobType", new byte[] {1, 2, 3});
long id = store.insert("test", values);
-
查询数据。
构造用于查询的谓词对象,设置查询条件。
指定查询返回的数据列。调用查询接口查询数据。
调用结果集接口,遍历返回结果。
String[] columns = new String[] {"id", "name", "age", "salary"};
RdbPredicates rdbPredicates = new RdbPredicates("test").equalTo("age",25).orderByAsc("salary");
ResultSet resultSet = store.query(rdbPredicates, columns);
resultSet.goToNextRow();
4.对象关系数据库
基本概念
-
HarmonyOS对象关系映射(Object Relational Mapping,ORM)数据库是一款基于 SQLite的数据库框架,屏蔽了底层SQLite数据库的SQL操作,针对实体和关系提供了增 删改查等一系列的面向对象接口。应用开发者不必再去编写复杂的SQL语句, 以操作对 象的形式来操作数据库,提升效率的同时也能聚焦于业务开发 -
对象关系映射数据库的三个主要组件:- ·
数据库:被开发者用@Database注解,且继承了OrmDatabase的类,对应关系型数据库; -
实体对象:被开发者用@Entity注解,且继承了OrmObject的类,对应关系型数据库中的表; -
对象数据操作接口:包括数据库操作的入口OrmContext类和谓词接口(OrmPredicate)等。
- ·
-
谓词:数据库中是用来
代表数据实体的性质、特征或者数据实体之间关系的词项,主要用来定义数据库的操作条件。对象关系映射数据库将SQLite数据库中的谓词封装成了接口方法供开发者调用。开发者通过对象数据操作接口,可以访问到应用持久化的关系型数据。对象关系映射:数据库通过将实例对象映射到关系上,实现使用操作实例对象的语法, 来操作关系型数据库。它是在SQLite数据库的基础上提供的一个抽象层。
-
SQLite数据库:一款轻型的数据库,是遵守ACID的关系型数据库管理系统
运作机制
-
对象关系映射数据库操作是·基于关系型数据库操作接口完成的,实际是在关系型数据库 操作的基础上又实现了对象关系映射等特性。因此对象关系映射数据库跟关系型数据库 一样,都使用SQLite作为持久化引擎,底层使用的是同一套数据库连接池和数据库连接机制。 -
使用对象关系映射数据库的开发者需要
先配置实体模型与关系映射文件。应用数据管理框架提供的类生成工具会解析这些文件,生成数据库帮助类,这样应用数据管理框架就能在运行时,根据开发者的配置创建好数据库,并在存储过程中自动完成对象关系映射。 开发者再通过对象数据操作接口,如OrmContext接口和谓词接口等操作持久化数据库。
对象数据操作接口
- 对象数据操作接口提供一组
基于对象映射的数据操作接口,实现了基于SQL的关系模型数据到对象的映射,让用户不需要再和复杂的 SQL语句打交道,只需简单地操作实体对象的属性和方法。对象数据操作接口支持对象的增删改查操作,同时支持事务操作等

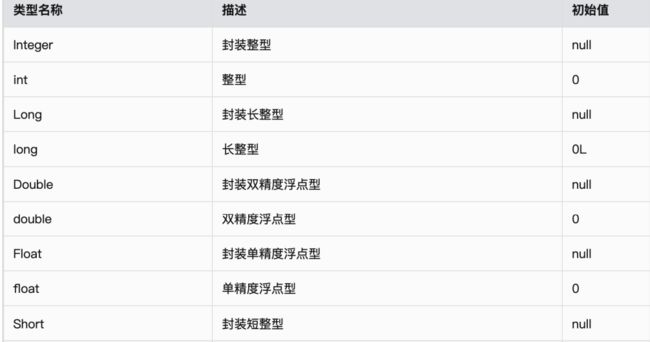
约束与限制
- 实体对象支持的属性
ORM开发过程
-
对象关系映射数据库目前可以支持
数据库和表的创建,对象数据的增删改查、对象数据变化回调、数据库升降级和备份等功能。 -
创建数据库。开发者需要
定义一个表示数据库的类,继承OrmDatabase,再通过 @Database注解内的entities属性指定哪些数据模型类属于这个数据库。 -
创建数据表。开发者可通过创建一个继承了OrmObject并用@Entity注解的类,获取数据 库实体对象,也就是表的对象。属性包括:
tableName:表名;primaryKeys:主键名,一个表里只能有一个主键,一个主键可以由多个字段组成
-
初始化数据库连接
- 系统会在应用启动时调用onStart()方法创建Data实例。在此方法中,开发者应该
创建数 据库连接,并获取连接对象,以便后续和数据库进行操作。为了避免影响应用启动速度, 开发者应当尽可能将非必要的耗时任务推迟到使用时执行,而不是在此方法中执行所有 初始化
- 系统会在应用启动时调用onStart()方法创建Data实例。在此方法中,开发者应该
-
数据库操作-OR Mapping(ORM)
query():该方法接收三个参数,分别是查询的目标路径,查询的列名,以及查询条件,查询条件由类DataAbilityPredicates构建。根据传入的列名和查询条件查询用户表的代 码示例如下:
OrmPredicates ormPredicates = DataAbilityUtils.createOrmPredicates(predicates,User.class);
ResultSet resultSet = ormContext.query(ormPredicates, columns);
-
-
insert():该方法接收两个参数,分别是插入的目标路径和插入的数据值。其中,插 入的数据由ValuesBucket封装,服务端可以从该参数中解析出对应的属性,然后插入到数 据库中。此方法返回一个int类型的值用于标识结果。 -
delete():该方法用来执行删除操作。删除条件由类DataAbilityPredicates构建,服 务端在接收到该参数之后可以从中解析出要删除的数据,然后到数据库中执行。
-
数据服务端开发步骤
- 配置“build.gradle”文件。
- 如果使用注解处理器(Annotation)的模块为“com.huawei.ohos.hap”模块,则需要 在模块的
“build.gradle”文件的“ohos”节点中添加以下配置。注解器的作用就是在数据库和对象之间形成映射,把记录映射为实体类,将数据库操作映射为对象操作,该过程会自动生成一些实体操作服务类。
- 如果使用注解处理器(Annotation)的模块为“com.huawei.ohos.hap”模块,则需要 在模块的
compileOptions{
annotationEnabled true
}
- 构造数据库,即创建数据库类并配置对应的属性。如定义了一个数据库类BookStore.java, 数据库
包含了“User” , “Book” , “AllDataType”三个表
@Database(
entities = {
User.class,
Book.class,
AllDataType.class
},
version = 1)
public abstract class BookStore extends OrmDatabase { }
- 构造数据表,即
创建数据库实体类并配置对应的属性(如对应表的主键,外键等)。数 据表必须与其所在的数据库在同一个模块中。例如,定义了一个实体类User.java,对应数 据库内的表名为“ user ”;indices 为“firstName”和“lastName”两个字段建立了复合 索引“name_index” ,并且索引值是唯一的;“ignoreColumns”表示该字段不需要添加 到“ user ”表的属性中
@Entity(tableName = "user",
ignoredColumns = {"ignoreColumn1", "ignoreColumn2"},
indices = {@Index(value = {"firstName", "lastName"},
name = "name_index", unique = true)})
public class User extends OrmObject {
// 此处将userId设为了自增的主键。注意只有在数据类型为包装类型时,自增主键才能生效。
@PrimaryKey(autoGenerate = true)
private Integer userId;
private String firstName;
private String lastName;
private int age;
private double balance;
private int ignoreColumn1;
private int ignoreColumn2;
//自行编写setter和getter方法
}
- 使用对象数据操作接口OrmContext创建数据库。例如,通过对象数据操作接口 OrmContext,创建一个别名为“BookStore” ,数据库文件名为“BookStore.db”的数据库。 如果数据库已经存在,执行以下代码不会重复创建。通过context.getDatabaseDir()可以获 取创建的数据库文件所在的目录。
DatabaseHelper helper = new DatabaseHelper(context); // context入参类型为
ohos.app.Context,注意不要使用slice.getContext()来获取context,请直接传入
slice,否则会出现找不到类的报错。
OrmContext context = helper.getOrmContext("BookStore", "BookStore.db",
BookStore.class);
- 使用对象数据操作接口OrmContext对数据库进行增删改查、注册观察者、备份数据库等。 增加数据。例如,在数据库的名为“ user ”的表中,首先新建一个User对象并设置对象的 属性;然后直接传入OrmObject对象的增加接口,只有在flush()接口被调用后才会持久化 到数据库中。
User user = new User();
user.setFirstName("Zhang");
user.setLastName("San");
user.setAge(29);
user.setBalance(100.51);
boolean isSuccessed = context.insert(user);
isSuccessed = context.flush();
访问数据库-客户端
- 编写数据库操作方法:DataAbilityHelper为开发者提供了增、删、改、查以及批量处理 等方法来操作数据库。这几个方法与Ability对象自有的六个方法是一致的
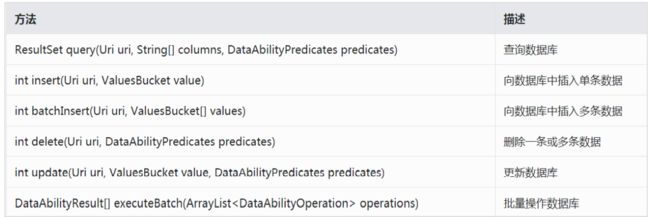
- query():查询方法,其中uri为目标资源路径,columns为想要查询的字段。开发者的查 询条件可以通过DataAbilityPredicates来构建。查询用户表中id在101-103之间的用户, 并把结果打印出来,代码示例如下:
DataAbilityHelper helper = DataAbilityHelper.creator(this);
// 构造查询条件
DataAbilityPredicates predicates = new DataAbilityPredicates();
predicates.between("userId", 101, 103);
// 进行查询
ResultSet resultSet = helper.query(uri,columns,predicates);
// 处理结果
resultSet.goToFirstRow();
do{
// 在此处理ResultSet中的记录;
}while(resultSet.goToNextRow());
- insert():新增方法,其中uri为目标资源路径,ValuesBucket为要新增的对象。插入一条 用户信息的代码示例如下:
DataAbilityHelper helper = DataAbilityHelper.creator(this);
// 构造插入数据
ValuesBucket valuesBucket = new ValuesBucket();
valuesBucket.putString("name", "Tom");
valuesBucket.putInteger("age", 12);
helper.insert(uri, valuesBucket);
5.偏好文件
轻量级偏好文件
- 轻量级偏好文件
主要提供轻量级Key-Value操作,支持本地应用存储少量数据,数据存储 在本地文件中,同时也加载在内存中的,所以访问速度更快,效率更高。轻量级偏好文件属于非关系型数据库,不宜存储大量数据,经常用于操作键值对形式数据的场景。
基本概念
-
Key-Value数据库:一种以键值对存储数据的一种数据库,类似Java中的map。Key是关 键字,Value是值。 -
非关系型数据库:区别于关系数据库,不保证遵循ACID(Atomic、Consistency、 Isolation及Durability)特性,不采用关系模型来组织数据,数据之间无关系,扩展性好。 -
偏好数据:用户经常访问和使用的数据
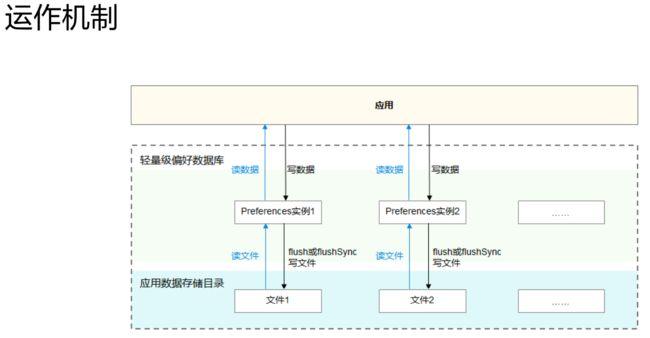
运作机制
-
Java代码中借助
DatabaseHelper API,应用可以将指定文件的内容加载到Preferences实例,每个文件最多有一个Preferences实例,系统会通过静态容器将该实例存储在内存中, 直到应用主动从内存中移除该实例或者删除该文件。 -
获取到文件对应的Preferences实例后,应用可以借助
Preferences API,从Preferences实 例中读取数据或者将数据写入Preferences实例, -
通过
flush或者flushSync将Preferences 实例持久化
开发示例
- 引入依赖包 import data_storage from ‘@ohos.data.storage’;
进行数据初始化:PATH为偏好文件所在的路径,注意这里的写法data/data代表用户应 用的数据存储路径,ohos.samples.preferences代表应用的包名,app_preference.xml可以 随便设置,这是用户偏好文件的名称。
data: {
selectedColor: "#ffffff",
appliedColor: "#ffffff",
lastSelectedColor:"#ffffff",
PATH:'/data/data/ohos.samples.preferences/app_preference.xml',
...}
- 初始化
应用背景色:偏好文件的访问有同步和异步两种,都有对应的函数支持。
onInit() {
var that = this;
let store = data_storage.getStorageSync(that.PATH);
that.lastSelectedColor = store.getSync('app_background_color','default');
...}
存储背景色:对偏好文件的写入是通过putSync(key,value)函数来是实现的,作用是将
value参数的值同步写到到key对应的值中。
let store = data_storage.getStorageSync(that.PATH);
if (that.appliedColor!='#ffffff')
{
store.putSync('app_background_color',that.appliedColor);
store.flushSync();
let storedata = store.getSync('app_background_color','default');
console.log('output1'+storedata);
-
清除背景色
let store = data_storage.getStorageSync(that.PATH); store.deleteSync('app_background_color'); store.flushSync(); let data=store.getSync('app_background_color','default'); console.log('output1'+data);
6.分布式数据服务
分布式数据服务
分布式数据服务(Distributed Data Service,DDS)为应用程序提供不同设备间数据库数据分布式的能力。通过调用分布式数据接口,应用程序将数据保存到分布式数据库中。 通过结合帐号、应用和数据库三元组,分布式数据服务对属于不同的应用的数据进行隔 离,保证不同应用之间的数据不能通过分布式数据服务互相访问。在通过可信认证的设 备间,分布式数据服务支持应用数据相互同步,为用户提供在多种终端设备上一致的数 据访问体验
KV数据模型
- “KV数据模型”是“Key-Value数据模型”的简称, “Key-Value”即“键-值” 。它是 一种NoSQL类型数据库,其数据以键值对的形式进行组织、索引和存储。
- KV数据模型适合
不涉及过多数据关系和业务关系的业务数据存储,比SQL数据库存储拥有更好的读写性能,同时因在分布式场景中降低了数据库版本兼容和数据同步过程中冲突解决的复杂度而被广泛使用。分布式数据库也是基于KV数据模型,对外提供KV类型的访问接口。
分布式数据库ACID特性
- 分布式数据库
事务性:分布式数据库事务支持本地事务(和传统数据库的事务概念一致)和
同步事务,同步事务是指在设备之间同步数据时,是以本地事务为单位进行同步,一次本地
事务的修改要么都同步成功,要么都同步失败。- 分布式数据库
一致性:在分布式场景中一般会涉及多个设备,组网内设备之间看到的数据是
否一致称为分布式数据库的一致性。分布式数据库一致性可以分为强一致性、弱一致性和最
终一致性。强一致性:是指某一设备成功增、删、改数据后,组网内设备对该数据的读取操作都将得到更新后的值;弱一致性:是指某一设备成功增、删、改数据后,组网内设备可能能读取到本次更新数据,也可能读取不到,不能保证在多长时间后每个设备的数据一定是一致的;最终一致性:是指某一设备成功增、删、改数据后,组网内设备可能读取不到本次更新数据,但在某个时间窗口之后组网内设备的数据能够达到一致状态
- 分布式数据库
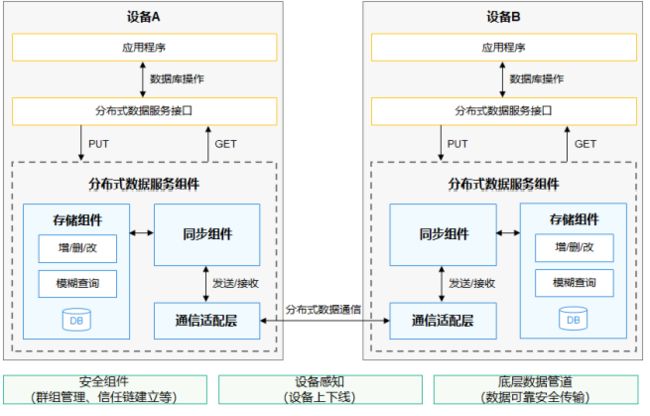
运作机制
-
分布式数据服务支撑HarmonyOS系统上应用程序数据库数据分布式管理,支持数据在相
同帐号的多端设备之间相互同步,为用户在多端设备上提供一致的用户体验,分布式数
据服务包含五部分:-
服务接口:分布式数据服务提供专门的数据库创建、数据访问、数据订阅等接口给应用程序调
用,接口支持KV数据模型,支持常用的数据类型,同时确保接口的兼容性、易用性和可发布性; -
服务组件:负责服务内元数据管理、权限管理、加密管理、备份和恢复管理以及多用户管理等、
同时负责初始化底层分布式DB的存储组件、同步组件和通信适配层; -
存储组件:负责数据的访问、数据的缩减、事务、快照、数据库加密,以及数据合并和冲突解
决等特性 -
同步组件:连结了存储组件与通信组件,其目标是保持在线设备间的数据库数据一致性,包括
将本地产生的未同步数据同步给其他设备,接收来自其他设备发送过来的数据,并合并到本地
设备中; -
通信适配层:负责调用底层公共通信层的接口完成通信管道的创建、连接,接收设备上下线消
息,维护已连接和断开设备列表的元数据,同时将设备上下线信息发送给上层同步组件,同步
组件维护连接的设备列表,同步数据时根据该列表,调用通信适配层的接口将数据封装并发送
给连接的设备
-
分布式数据服务架构
- 应用程序通过
调用分布式数据服务接口实现分布式数据库创建、访问、订阅功能,服务
接口通过操作服务组件提供的能力,将数据存储至存储组件,存储组件调用同步组件实 现将数据同步,同步组件使用通信适配层将数据同步至远端设备,远端设备通过同步组
件接收数据,并更新至本端存储组件,通过服务接口提供给应用程序使用
操作步骤
-
在config.json中添加permisssion权限;
-
创建分布式数据库管理器实例;
KvManagerConfig config = new KvManagerConfig(this); manager = KvManagerFactory.getInstance().createKvManager(config); -
获取/创建单版本分布式数据库;
kvStore = kvManager.getKvStore(options, "contact_db"); -
订阅分布式数据库变化;
kvStore = kvManager.getKvStore(options, "contact_db"); -
将数据写入单版本分布式数据库:
kvStore = kvManager.getKvStore(options, "contact_db"); -
同步数据到其他设备。
7.分布式文件系统服务
- ·
分布式文件服务能够为用户设备中的应用程序提供多设备之间的文件共享能力,支持相同帐号下同一应用文件的跨设备访问,应用程序可以不感知文件所在的存储设备,能够在多个设备之间无缝获取文件。 分布式文件:分布式文件是指依赖于分布式文件系统,分散存储在多个用户设备上的文件,应用间的分布式文件目录互相隔离,不同应用的文件不能互相访问
运作机制
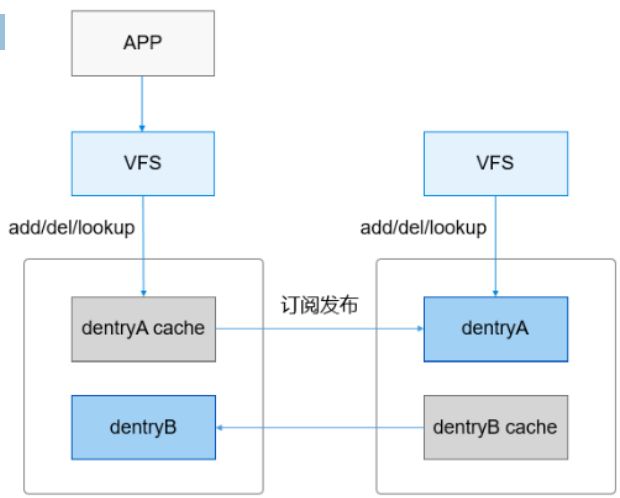
- 分布式文件服务采用
无中心节点的设计,每个设备按目录树管理。当应用需要访问分布式文件时,根据Cache订阅发布,按需缓存文件所在的存储设备,然后对缓存的分布式文件服务发起文件访问请求。
操作步骤
分布式文件兼容POSIX文件操作接口,应用使用Context.getDistributedDir()接口获取目录后,可以直接使用libc或JDK访问分布式文件。
- 设备1上的应用A创建文件hello.txt,并写入内容"Hello World"。
Context context;
File distDir = context.getDistributedDir();
String filePath = distDir + File.separator + "hello.txt";
FileWriter fileWriter = new FileWriter(filePath,true);
fileWriter.write("Hello World");
fileWriter.close();
-
设备2上的应用A
通过Context.getDistributedDir()接口获取分布式目录。 -
设备2上的应用A读取文件 hello.txt。
FileReader fileReader = new FileReader(filePath);
char[] buffer = new char[1024];
fileReader.read(buffer);
fileReader.close();
System.out.println(buffer);
本章总结
- HarmonyOS支持的
几种数据持久化的方法的特点和使用他们的方式, 包括文件,关系数据库,对象关系数据库和偏好文件等; - 为了屏蔽这些数据持久化方法底层实现的差异性,
Data Ability通过对外提供了统一的数据增删改查接口,大大提高了客户端数据访问的便利性; - 最后
分布式数据服务和分布式文件服务有效的提升了HarmonyOS系统支持多设备互访的能力
stDir = context.getDistributedDir();
String filePath = distDir + File.separator + “hello.txt”;
FileWriter fileWriter = new FileWriter(filePath,true);
fileWriter.write(“Hello World”);
fileWriter.close();
2. 设备2上的应用A`通过Context.getDistributedDir()接口获取分布式目录`。
3. 设备2上的应用A读取文件 hello.txt。
```js
FileReader fileReader = new FileReader(filePath);
char[] buffer = new char[1024];
fileReader.read(buffer);
fileReader.close();
System.out.println(buffer);
本章总结
- HarmonyOS支持的
几种数据持久化的方法的特点和使用他们的方式, 包括文件,关系数据库,对象关系数据库和偏好文件等; - 为了屏蔽这些数据持久化方法底层实现的差异性,
Data Ability通过对外提供了统一的数据增删改查接口,大大提高了客户端数据访问的便利性; - 最后
分布式数据服务和分布式文件服务有效的提升了HarmonyOS系统支持多设备互访的能力