C++ 数据结构与算法 (十一)(排序算法)
排序算法
排序简介 - OI Wiki
排序–全栈潇晨
排序算法
十大排序算法 |菜鸟教程
排序算法(英语:Sorting algorithm)是一种将一组特定的数据按某种顺序进行排列的算法。排序算法多种多样,性质也大多不同。
(一)稳定性:
稳定性是指相等的元素经过排序之后相对顺序是否发生了改变。
稳定的排序算法会让原本有相等键值的纪录维持相对次序。
-
稳定排序:基数排序、计数排序、插入排序、冒泡排序、归并排序、桶排序。
-
不稳定排序:选择排序、希尔排序、堆排序、快速排序。
(二)复杂度:
基于比较的排序算法的时间复杂度下限是 O ( n l o g n ) O(n logn) O(nlogn) 的。
当然也有不是 O ( n l o g n ) O(n logn) O(nlogn) 的。例如,计数排序 的时间复杂度是 O ( n + w ) O(n+w) O(n+w) ,其中 w w w 代表输入数据的值域大小。
(三)存储器:
- 内部排序: 待排序记录存放在计算机随机存储器中进行的排序过程;
- 外部排序: 待排序记录的数量很大,以致内存一次不能容纳全部记录,在排序过程中尚需对外存进行访问的排序过程。

1. 选择排序(Selection sort)
- 工作原理:每次找出第 i i i 小的元素(也就是 A A Ai…n 中最小的元素),然后将这个元素与数组第 i i i 个位置上的元素交换。

- 不稳定性:由于 swap(交换两个元素)操作的存在,选择排序是一种不稳定的排序算法。
- 时间复杂度:最优时间复杂度、平均时间复杂度和最坏时间复杂度均为 O ( n 2 ) O(n^2) O(n2)
#include 2. 冒泡排序(Bubble sort)
在算法的执行过程中,较小的元素像是气泡般慢慢「浮」到数列的顶端,故叫做冒泡排序。
- 工作原理:
每次检查相邻两个元素,如果前面的元素与后面的元素满足给定的排序条件,就将相邻两个元素交换。当没有相邻的元素需要交换时,排序就完成了。
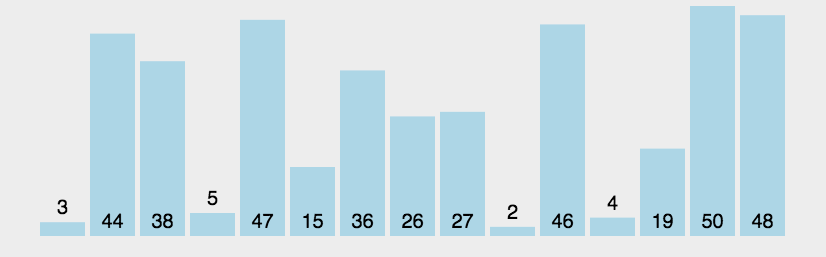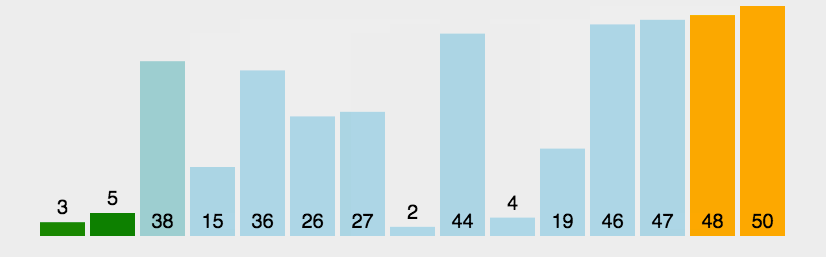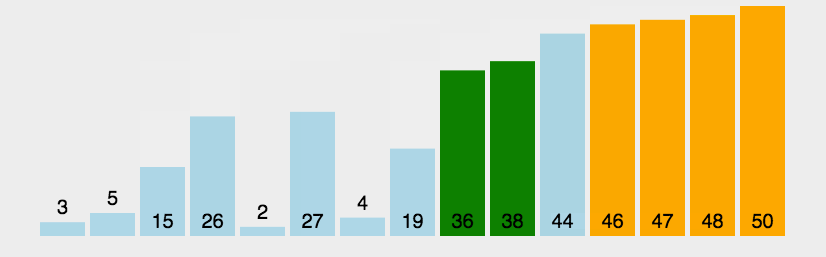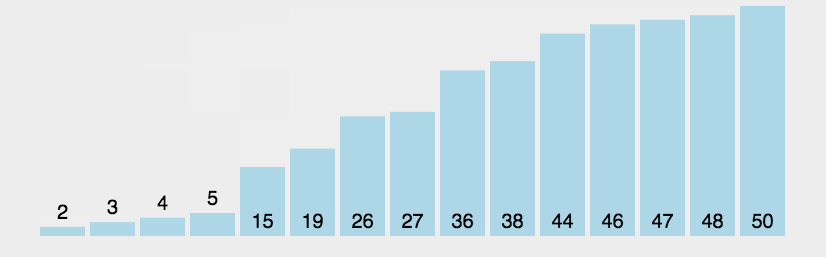
经过 i i i 次扫描后,数列的末尾 i i i 项必然是最大的 i i i 项,因此冒泡排序最多需要扫描 n − 1 n-1 n−1遍数组就能完成排序。 - 稳定性:
冒泡排序是稳定排序算法。 - 时间复杂度:
在序列完全有序时,冒泡排序只需遍历一遍数组,不用执行任何交换操作,时间复杂度为 O ( n ) O(n) O(n)。
在最坏情况下,冒泡排序要执行 ( n − 1 ) n / 2 (n-1)n/2 (n−1)n/2 次交换操作,时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
冒泡排序的平均时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
#include 3. 插入排序(Insertion sort)
- 工作原理:
将待排列元素划分为“已排序”和“未排序”两部分,每次从“未排序的”元素中选择一个插入到“已排序的”元素中的正确位置。
- 稳定性:
插入排序是稳定的排序算法。 - 时间复杂度:
插入排序的最优时间复杂度为 O ( n ) O(n) O(n),在数列几乎有序时效率很高。
插入排序的最坏时间复杂度和平均时间复杂度都为 O ( n 2 ) O(n^2) O(n2)。
// insertion sort
#include 4. 希尔排序(Shell sort)
也称为缩小增量排序法,是 插入排序 的一种改进版本。
- 工作原理 :
(1)将待排序序列分为 若干子序列 (每个子序列的元素在原始数组中 间距step相同 );
(2)对这些子序列进行 插入排序 ;
(3)减小每个子序列中元素之间的间距,重复上述过程直至 间距减少为 1 。 - 不稳定性:
希尔排序是不稳定的排序算法。 - 复杂度:
最优时间复杂度为 O ( n ) O(n) O(n);
平均时间复杂度和最坏时间复杂度与间距序列的选取(就是间距如何减小到 1)有关,
常见的增量值有 N 2 i \frac N{2^i} 2iN,即对序列的长度不断折半作为增量大小。还有 2 k − 1 2^k-1 2k−1。
比如「间距每次除以 3」的希尔排序的时间复杂度是 O ( n 3 / 2 ) O(n^{3/2}) O(n3/2)。已知最好的最坏时间复杂度为 O ( n l o g 2 n ) O(nlog^2n) O(nlog2n) 。
空间复杂度为 O ( 1 ) O(1) O(1)。
希尔排序属于原地排序算法,不需要申请额外的存储空间。它是在插入排序的基础上进行了改进,实际就是除了最后的插入排序外,对多个子分组也执行了排序。所以看到该算法的第一印象就是,它额外做了这么多工作,复杂度应该大于插入排序才对。所以导致希尔排序最坏复杂度低于插入排序的原因就是,通过合理的增量值设置,可以将本来需要多次比较和交换才能调整到正确位置的元素,只需要很少次的比较和交换就可完成。
#include 5. 归并排序(Merge sort)
归并排序是通过分治的方式,将待排序集合拆分为多个子集合,对子集合排序后,合并子集合成为较大的子集合,不断合并最终完成整个集合的排序。
以下所讲归并都是指二路归并:
之前的冒泡、选择和插入排序都是维持一个待排序集合和一个已排序集合,在每次的迭代过程中从待排序集合中移动一个元素到已排序集合中,通过不断的迭代来完成排序,所以需要进行的迭代次数一般都是 O ( N ) O(N) O(N) 级别。
而归并排序则是每轮迭代消除半数的待排序子集合,所以需要进行的迭代次数为 O ( l o g 2 N ) O(log_2N) O(log2N) 级别。
步骤为:
(1)将数列划分为两部分;
(2)递归地分别对两个子序列进行归并排序;
(3)合并两个有序子序列。
性质:
归并排序是一种稳定的排序算法。
归并排序的最优时间复杂度、平均时间复杂度和最坏时间复杂度均为 O ( n l o g n ) O(nlogn) O(nlogn) 。
归并排序的空间复杂度为 O ( n ) O(n) O(n) 。
归并排序适用于数据量大,并且对稳定性有要求的场景。

代码中采用递归的思路进行划分-排序-合并,
在排序前先创建备用数组sorted,避免递归时重复创建增加消耗。
#include - 逆序对
归并排序还可以用来求逆序对的个数。
所谓逆序对,就是对于一个数组 ,满足 n u m s [ i ] > n u m s [ j ] nums[i] > nums[j] nums[i]>nums[j] 且 i < j i < j i<j 的数对 ( i , j ) (i, j) (i,j)。
代码实现中 reversePairNum += mid - left + 1; 就是在统计逆序对个数。
具体来说,算法把靠后的数放到前面了(较小的数放在前面),所以在这个数原来位置之前的、比它大的数都会和它形成逆序对,而这个个数就是还没有合并进去的数的个数,即 m i d − l e f t + 1 mid - left + 1 mid−left+1。
6. 快速排序(Quick sort)
快速排序,又称分区交换排序(partition-exchange sort),简称快排,是内排序中平均效率最高的排序算法。
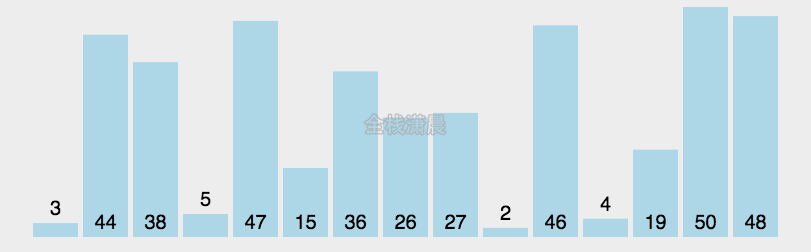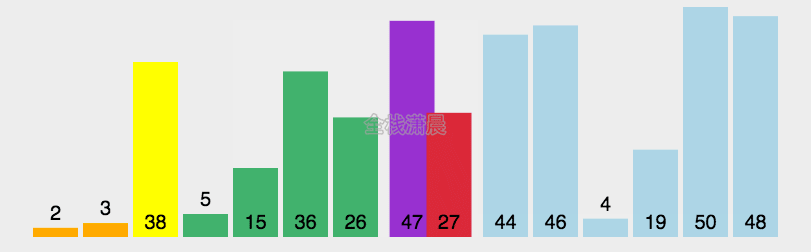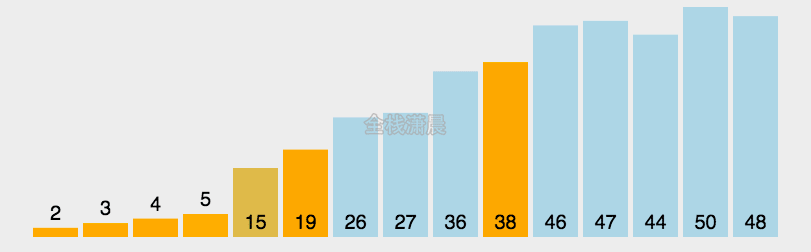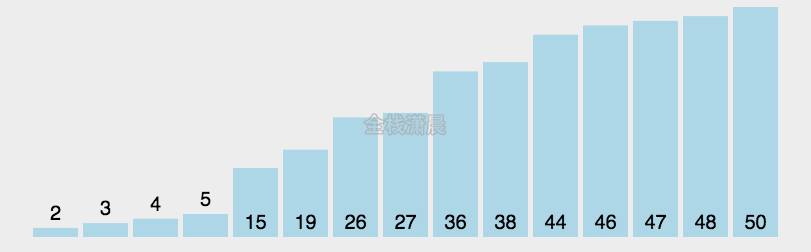
快速排序的工作原理是通过 分治 的方式来将一个数组排序。
通过多次比较和交换来实现排序,在一趟排序中把将要排序的数据分成两个独立的部分,对这两部分进行排序使得其中一部分所有数据比另一部分都要小,然后继续递归排序这两部分,最终实现所有数据有序。
快速排序分为三个过程:
(1)首先设置一个分界值,通过该分界值将数据分割成两部分(要求保证相对大小关系);
(2)递归到两个子序列中分别进行快速排序;
(3)不用合并,因为此时数列已经完全有序。
-
稳定性
快速排序是一种不稳定的排序算法。 -
时间复杂度:分区复杂度 O ( n ) O(n) O(n),递归复杂度是 O ( l o g n ) O(logn) O(logn)
快速排序的最优时间复杂度和平均时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn) ,最坏时间复杂度为 O ( n 2 ) O(n^2) O(n2) 。
最坏情况下,每次所选的分界值是当前序列中的最大或最小元素,这使得每次划分所得的子表中一个为空表,另一子表的长度为原表的长度-1。这样,长度为 n 的数据表的快速排序需要经过 n 趟划分,使得整个排序算法的时间复杂度为 O ( n 2 ) O(n^2) O(n2),可以通过随机选择分界值来避免这种情况。 -
空间复杂度:递归层数 O ( l o g n ) O(logn) O(logn)
#include 7. 堆排序(Heapsort)
堆描述的是一颗完全二叉树,父节点的值不小于子节点的值则是大根堆,父不大于子则是小根堆。
在对数组进行排序的过程中,并不是真的构建一个二叉树结构,只是将数组中元素下标映射到完全二叉树,利用元素下标来表示父节点和子节点关系。
二叉堆的结构、插入、删除、修改
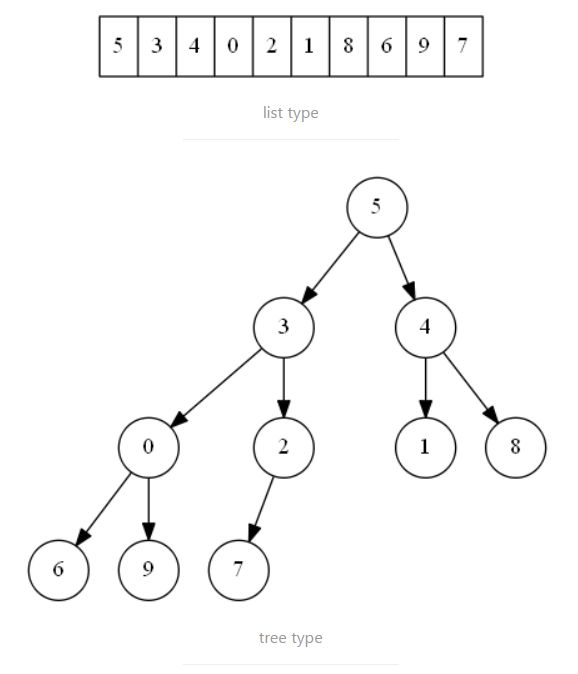
通过以上两张图可知,堆中父子节点的下标关系为:
– 下标为 i i i 的节点,其左子节点下标为 2 ∗ i + 1 2*i+1 2∗i+1
– 下标为 i i i 的节点,其右子节点下标为 2 ∗ i + 2 2*i+2 2∗i+2
– 下标为 i i i 的节点,其父节点下标为 ⌊ i − 1 2 ⌋ ( i ≥ 1 ) \lfloor {\frac {i-1} 2} \rfloor(i\ge1) ⌊2i−1⌋(i≥1)
算法步骤:
- 将无序序列构建成一个初始堆,根据升序降序需求选择大顶堆或小顶堆;
- 交换待排序集合中第一个元素和最后一个元素值,即在待排序集合映射出的完全二叉树上,将根节点值和树中最下面一层、最右边的节点值进行替换
- 重新调整结构,使其满足堆定义,标记待排序集合最后一个元素为已排序
- 重复步骤2、3,直到待排序集合只有一个元素
构建初始堆:
首先要清楚数组下标和元素在树结构中位置的关系,然后关键是要找到 最后一个非叶子节点(下标为n/2-1) 开始,逐个进行堆结构的调整,在交换之后,要继续往下检查调整。
不稳定性:
同选择排序一样,由于其中交换位置的操作,所以是不稳定的排序算法。
时间复杂度:
堆排序的最优时间复杂度、平均时间复杂度、最坏时间复杂度均为 O ( n l o g n ) O(nlogn) O(nlogn)。
空间复杂度:
由于可以在输入数组上建立堆,所以这是一个原地算法 O ( 1 ) O(1) O(1)。
对于 n n n 个元素的序列,构造堆过程,需要遍历的元素次数为 O ( n ) O(n) O(n),每个元素的调整次数为 O ( l o g 2 n ) O(log_2n) O(log2n),所以构造堆复杂度为 O ( n l o g n ) O(nlogn) O(nlogn) 。迭代替换待排序集合首尾元素的次数为 O ( n ) O(n) O(n),每次替换后调整次数为 O ( l o g 2 n ) O(log_2n) O(log2n),所以迭代操作的复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。由此可知堆排序的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn) ,排序过程属于原地排序,不需要额外的存储空间,所以空间复杂度为 O ( 1 ) O(1) O(1)。
#include 8. 计数排序(Counting sort)
- 工作原理:
使用一个额外的数组 C C C,其中第 i i i 个元素是待排序数组 A A A 中值等于 i i i 的元素的个数,然后根据数组 C C C 来将 A A A 中的元素排到正确的位置。
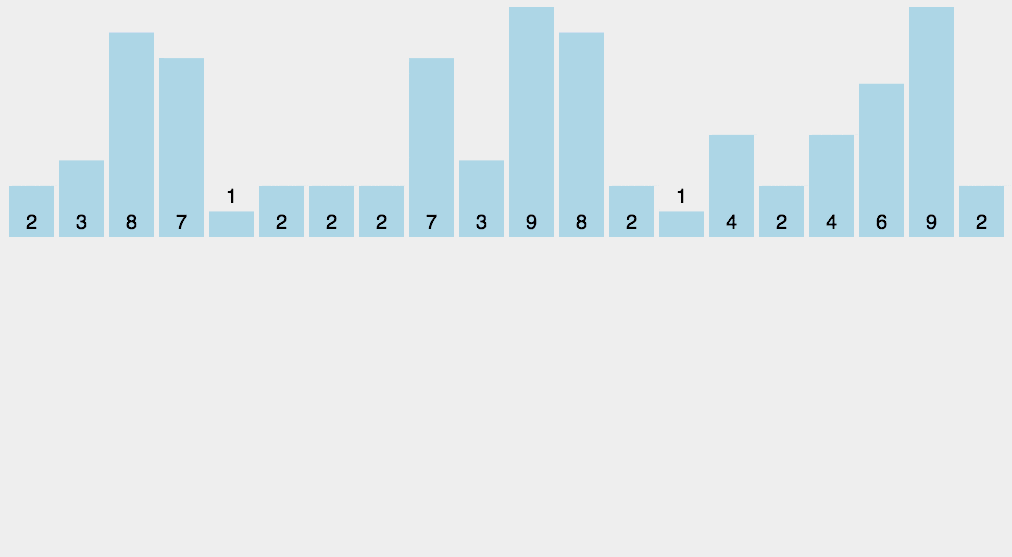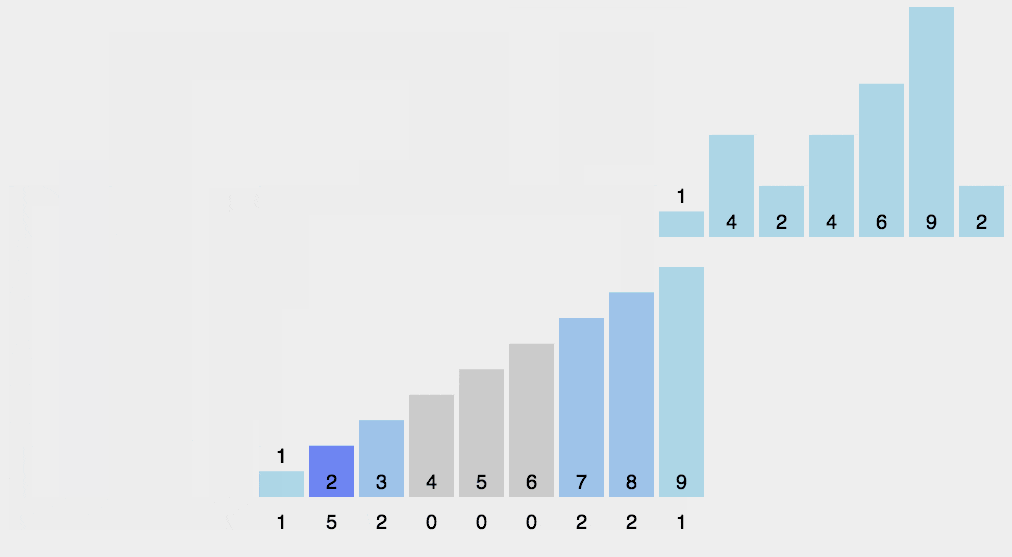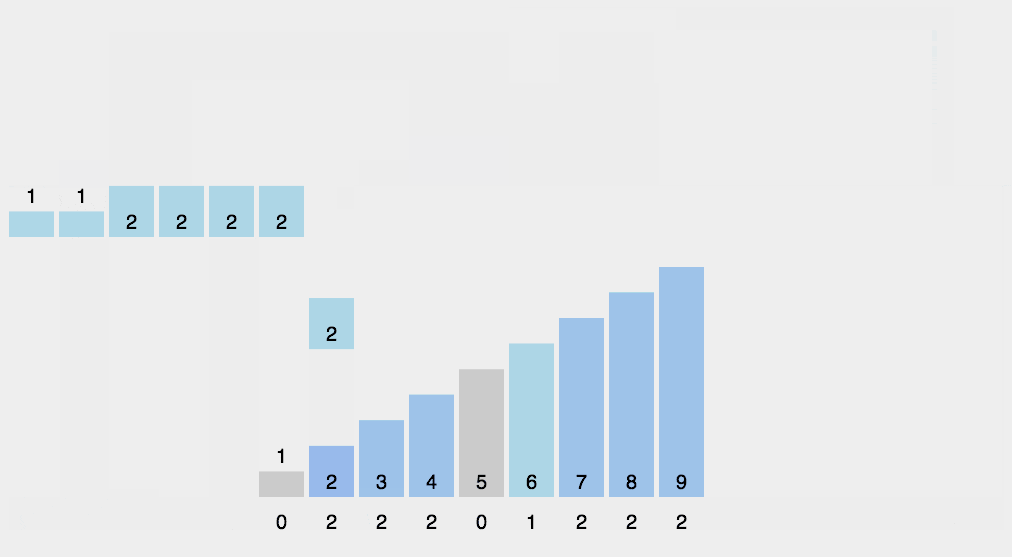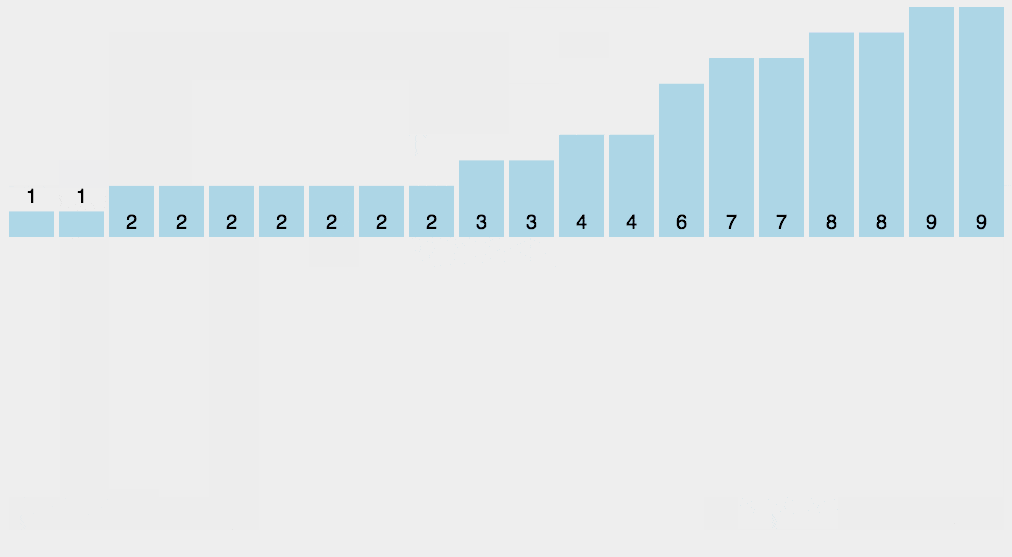
- 工作步骤:
1.计算每个数出现的次数;
2.求出每个数出现次数的 前缀和;
3.利用出现次数的前缀和,从右至左计算每个数的排名。 - 稳定性:
计数排序是一种稳定的排序算法。 - 复杂度:
时间复杂度为 O ( n + w ) O(n+w) O(n+w),
空间复杂度为 O ( w ) O(w) O(w),其中 w w w 代表待排序数据的值域大小。 - 局限性:
(1)当数列最大最小值差距 (值域)过大 时,会造成空间浪费,并不适用于计数排序;
(2)当数列元素不是整数时,无法创建对应的统计数组,并不适用于计数排序。
// Counting sort
#include 稳定的计数排序过程可见基数排序部分。
9. 桶排序(Bucket sort)
桶排序是将待排序集合中处于同一个值域的元素存入同一个桶中,也就是根据元素值特性将集合拆分为多个区域,则拆分后形成的多个桶,从值域上看是处于有序状态的。对每个桶中元素进行排序,则所有桶中元素构成的集合是已排序的。适用于待排序数据值域较大但分布比较均匀的情况。
快速排序是将集合拆分为两个值域,这里称为两个桶,再分别对两个桶进行排序,最终完成排序。桶排序则是将集合拆分为多个桶,对每个桶进行排序,则完成排序过程。两者不同之处在于,快排是在集合本身上进行排序,属于原地排序方式,且对每个桶的排序方式也是快排。桶排序则是提供了额外的操作空间,在额外空间上对桶进行排序,避免了构成桶过程的元素比较和交换操作,同时可以自主选择恰当的排序算法对桶进行排序。
当然桶排序更是对计数排序的改进,计数排序申请的额外空间跨度从最小元素值到最大元素值,若待排序集合中元素不是依次递增的,则必然有空间浪费情况。桶排序则是弱化了这种浪费情况,将最小值到最大值之间的每一个位置申请空间,更新为最小值到最大值之间每一个固定区域申请空间,尽量减少了元素值大小不连续情况下的空间浪费情况。
- 关键环节:
(1)元素值域的划分,也就是元素到桶的映射规则。映射规则需要根据待排序集合的元素分布特性进行选择,若规则设计的过于模糊、宽泛,则可能导致待排序集合中所有元素全部映射到一个桶上,则桶排序向比较性质排序算法演变。若映射规则设计的过于具体、严苛,则可能导致待排序集合中每一个元素值映射到一个桶上,则桶排序向计数排序方式演化。
(2)排序算法的选择,从待排序集合中元素映射到各个桶上的过程,并不存在元素的比较和交换操作,在对各个桶中元素进行排序时,可以自主选择合适的排序算法,桶排序算法的复杂度和稳定性,都根据选择的排序算法不同而不同。
- 工作原理:
1、设置一个定量的数组当作空桶;
2、遍历序列,并将元素一个个放到对应的桶中;
3、对每个不是空的桶进行排序(内层排序);
4、从不是空的桶里把元素再放回原来的序列中。

- 稳定性:
如果使用稳定的内层排序,并且将元素插入桶中时不改变元素间的相对顺序,那么桶排序就是一种稳定的排序算法。由于每块元素不多,一般使用插入排序。此时桶排序是一种稳定的排序算法。
- 复杂度:
对于待排序序列大小为 N,共分为 M 个桶,主要步骤有:
(1)N 次循环,将每个元素装入对应的桶中
(2)M 次循环,对每个桶中的数据进行排序(平均每个桶有 N/M 个元素)
一般使用较为快速的排序算法,时间复杂度为 O ( N l o g N ) O ( N l o g N ) O(NlogN),实际的桶排序过程是以链表形式插入的。
时间复杂度为:
O ( N ) + O ( M ∗ ( N / M ∗ l o g ( N / M ) ) ) = O ( N ∗ ( l o g ( N / M ) + 1 ) ) O ( N ) + O ( M ∗ ( N / M ∗ l o g ( N / M ) ) ) = O ( N ∗ ( l o g ( N / M ) + 1 ) ) O(N)+O(M∗(N/M∗log(N/M)))=O(N∗(log(N/M)+1))
当 N = M 时,复杂度为 O ( N ) O ( N ) O(N)
平均时间复杂度为 O ( n + k ) O ( n + k ) O(n+k),最坏的情况为 O ( n 2 ) O(n^2) O(n2)
空间复杂度: O ( N + M ) O(N + M) O(N+M)
代码:
#include 10. 基数排序(Radix sort)
一种非比较型的排序算法,最早用于解决卡片排序的问题。
- 工作原理:
将待排序的元素拆分为 k k k 个关键字(比较两个元素时,先比较第一关键字,如果相同再比较第二关键字……),然后先对第 k k k 关键字进行稳定排序,再对第 k − 1 k-1 k−1 关键字进行稳定排序,再对第 k − 2 k-2 k−2 关键字进行稳定排序……最后对第一关键字进行稳定排序,这样就完成了对整个待排序序列的稳定排序。
基数排序需要借助一种 稳定算法 完成 内层对关键字的排序。 - 稳定性:
基数排序是一种稳定排序算法。 - 复杂度:
(1)时间复杂度:O(K * (N + M)),N为数组长度,M为值域大小,K为执行的计数排序次数(最大长度)。
(2)空间复杂度:O(N + M),N为数组长度,M为值域大小。 - 说明:
通常而言,基数排序比基于比较的排序算法(比如快速排序)要快。但由于需要额外的内存空间,因此当内存空间稀缺时,原地置换算法(比如快速排序)或许是个更好的选择。
在进行关键字排序时,通常已知值域大小,且不会很大,因此可以用计数排序进行内层排序。
但是普通的计数排序无法保证稳定性,因此需要对其进行改动,实现稳定的计数排序。
主要的思路就是,首先用数组统计每位数出现的次数,然后对统计数组进行前缀和计算,此时数组为最后一个该位数到数组首位的长度;然后再从后往前遍历待排序序列,将元素放到相应的位置上(长度-1),同时该位长度元素也减一,以此来实现稳定的计数排序。
#include - 基数排序对字符串进行排序:
#include 11. 外部排序
当所要排序的的数据量太多或者文件太大,无法直接在内存里排序,而需要依赖外部设备(磁盘)时,就会使用到外部排序(归并思想)。
-
假设文件需要分成 k 块读入,需要从小到大进行排序。
-
依次读入每个文件块,在内存中对当前文件块进行排序并存储(应用恰当的内排序算法),此时,每块文件相当于一个由小到大排列的有序队列;
-
在内存中建立一个最小堆,读入每块文件的队列头;
-
弹出堆顶元素,如果元素来自第 i 块,则从第i块文件中补充一个元素到最小值堆,弹出的元素暂存至临时数组;
-
当临时数组存满时,将数组写至磁盘,并清空数组内容;
-
重复过程3、4,直至所有文件块读取完毕。

#include