libxml2库的安装,xpath的使用
http://www.redicecn.com/html/Python/20101101/185.html
Python的libxml2库支持xpath。但默认没有包含该库,需要单独安装。
libxml2 Win32版可以在如下地址下载:
http://xmlsoft.org/sources/win32/python/
我的Python版本是2.5,这里我下载安装了libxml2-python-2.6.30.win32-py2.5.exe
安装程序会将libxml2安装到python2.5的默认目录下(我安装的是ActivePython-2.5.2.2-win32-x86.msi,默认安装路径是C:Python25)。
附下载:ActivePython_25_with_libxml2_2.6.30.7z
File: Click to Download
另外一种安装方法是利用easy_install工具,它有点类似linux下的yum工具。
详见: http://codespeak.net/lxml/installation.html
Get the easy_install tool and run the following as super-user (or administrator):
easy_install lxml
-
On MS Windows, the above will install the binary builds that we provide. If there is no binary build of the latest release yet, please search PyPI for the last release that has them and pass that version to easy_install like this:
easy_install lxml==2.2.2
-
On Linux (and most other well-behaved operating systems), easy_install will manage to build the source distribution as long as libxml2 and libxslt are properly installed, including development packages, i.e. header files, etc. Use your package management tool to look for packages like libxml2-dev or libxslt-devel if the build fails, and make sure they are installed.
-
On MacOS-X, use the following to build the source distribution, and make sure you have a working Internet connection, as this will download libxml2 and libxslt in order to build them:
STATIC_DEPS=true easy_install lxml
附:setuptools-0.6c11.win32-py2.5.exe 即easy_install,注意:本安装包适用于Python25。
| |
setuptools-0.6c11.win32-py2.5.rar |
解压后,直接安装即可。
然后,命令行切换至C:\Python25\Lib\site-packages,并运行 easy_install lxml==2.2.2 即可完成libxml2的安装。
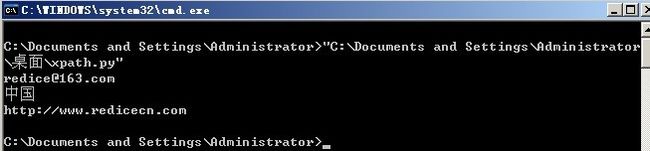
安装后可以用下面的程序测试,让我们一起来见识一下强大的xpath!
File: Click to Download
#coding:utf-8
import codecs
import sys
#不加如下行,无法打印Unicode字符,产生UnicodeEncodeError错误。?
sys.stdout = codecs.lookup('iso8859-1')[-1](sys.stdout)
from lxml import etree
html = r'''
tree = etree.HTML(html)
#获取email。email所在的div的id为email
nodes = tree.xpath("//div[@id='email']")
print nodes[0].text
#获取地址。地址所在的div的name为address
nodes = tree.xpath("//div[@name='address']")
print nodes[0].text
#获取博客地址。博客地址位于email之后兄弟节点的第二个
nodes = tree.xpath("//div[@id='email']/following-sibling::div[2]")
print nodes[0].text
写了个程序需要解析HTML,据说lxml很牛,于是就用了一下,结果遇到了一个小问题。
首先程序要提取HTML文档的title标签中的文本,代码如下:
#!/usr/bin/python |
#coding=utf-8 |
import sys from lxml import * |
import lxml.html as HTML |
reload(sys) |
sys.setdefaultencoding('utf8') |
doc = """ |
root = HTML.document_fromstring(doc) tnodes = root.xpath("//title") #以xpath方式解析 print tnodes[0].text #获取第一个title的内容,有可能HTML文档有多个title标签。 |
Print "Title is : " + tnodes[0].text |
输出:Title is : why len(y) == 1
比较正常没发现啥问题。将title改一下,改成why len(y) <= 1
#!/usr/bin/python |
#coding=utf-8 |
import sys from lxml import * |
import lxml.html as HTML |
reload(sys) |
sys.setdefaultencoding('utf8') |
doc = """ |
root = HTML.document_fromstring(doc) tnodes = root.xpath("//title") |
print "Title is : " + tnodes[0].text |
输出:Title is : why len(y)
问题现了,不能正确解析HTML文档,lxm在提取标签(tag)中的文本时遇到字符'<'就结束了,不能正确解析。
开始以为是xpath的问题,于是换了一种方法。直接以文档树的方式解析。
代码前半部分不变,第9行开始变成:
tnodes = root.getchildren()
print "Title is : " + tnodes[0][0].text
结果还是不能正确解析。看来是解析引擎的问题了。
于是换了个解析器,换成了BeautifulSoup。据说BeautifulSoup很方便,很好用。
#!/usr/bin/python# |
coding=utf-8 |
from BeautifulSoup import BeautifulSoup |
reload(sys) |
sys.setdefaultencoding('utf8') |
doc = """ |
root = BeautifulSoup(''.join(doc)) |
print "Title is : " + root.head.title.string |
输出:Title is : why len(y) <= 1
结果正常解析了,看来BeautifulSoup解析引擎还是比较牛的。
其实lxml本身是支持 BeautifulSoup解析引擎的,不过要选择一下。
代码如下:
#!/usr/bin/python |
#coding=utf-8 |
from lxml.html.soupparser import fromstring |
reload(sys) |
sys.setdefaultencoding('utf8') |
doc = """ |
root = fromstring(doc) |
find_text = root.xpath("//title") |
print "Title is : " + find_text[0].text |
结果同样能够正确解析HTML文档。看来还是lxml强大什么都包含了,还能选择解析引擎。
BeautifulSoup的安装与使用详见其官方主页。
不过使用BeautifulSoup时还要注意,如果HTML文档不存在body标签,例如上边的doc,则root.body是不存在的。
但lxml默认的解析引擎若HTML文档body标签不存在时,却能自动纠正。太详细的东西我也不清楚了,就先到这吧。