【Linux】Linux自动化构建工具make/makefile
文章目录
- Linux自动化构建工具make/makefile
-
- 1.Makefile文件格式
-
- ⭐1.1 简单makefile例子
- ⭐1.2 概述
- ⭐1.3 目标(target)
- ⭐1.4 前置条件(prerequisites)
- ⭐1.5 命令(commands)
- 2.Makefile文件语法
-
- ⭐2.1 注释
- ⭐2.2 回声
- ⭐2.3 通配符
- ⭐2.4 变量和赋值符
- ⭐2.5 内置变量
- ⭐2.6 自动变量
- ⭐2.7 函数
- 3.Linux小程序进度条
-
- ⭐3.1 缓冲区概念
- ⭐3.2 进度条代码
Linux自动化构建工具make/makefile
为什么Linux会有自动化构建工具呢?一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂
的功能操作,makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率,会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建
1.Makefile文件格式
make会在当前目录下找名字叫“Makefile”或“makefile”的文件,然后开始自动化构建,下面我们先来看一个例子。
⭐1.1 简单makefile例子
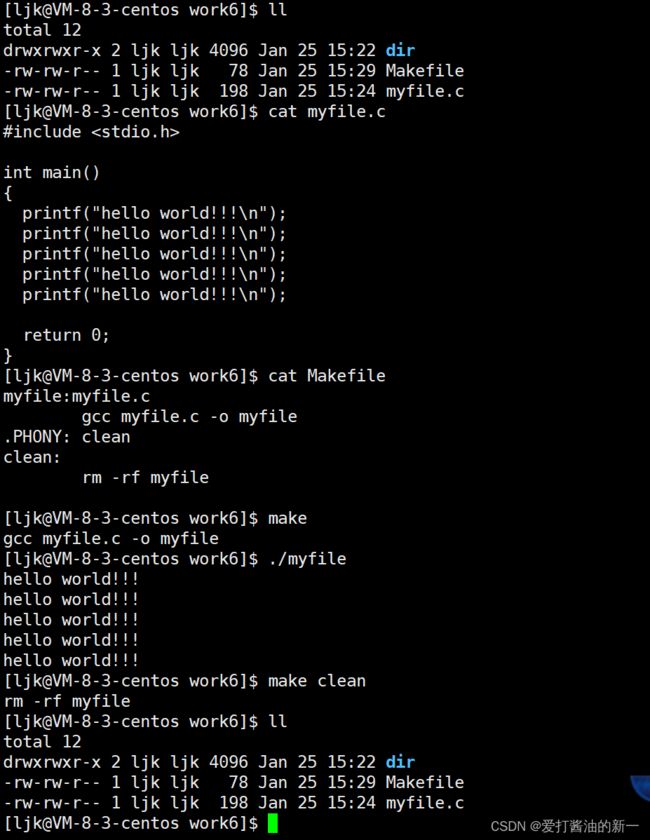
⭐1.2 概述
Makefile文件由一系列规则(rules)构成。每条规则的形式如下:
<target> : <prerequisites>
[tab] <commands>
上述例子中形成的可执行文件myfile就是target,而myfile.c就是prerequisites,下面一行commands就是"命令",第二行必须以tab键起首
我们在构建之前必须清楚:构建目标的前置条件是什么,以及怎么构建
⭐1.3 目标(target)
一个目标(target)就构成一条规则。目标通常是文件名,指明Make命令所要构建的对象,比如上文的 myfile 。目标可以是一个文件名,也可以是多个文件名,之间用空格分隔
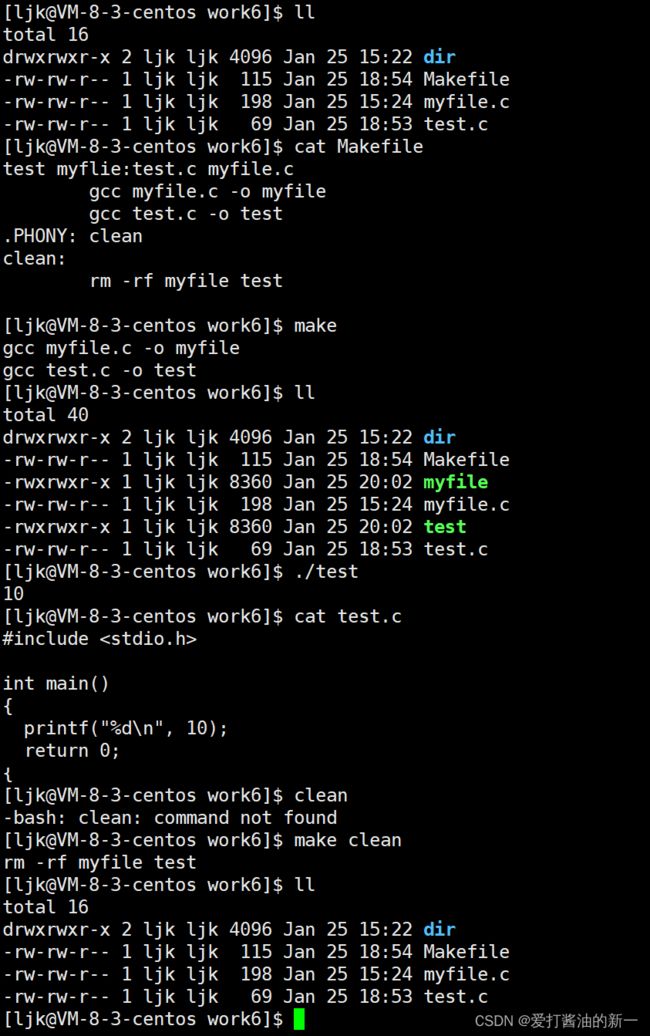
关于目标我们还得注意以下几点:
- 默认输入make执行的是第一个目标
我们将Makefile文件修改为如下:
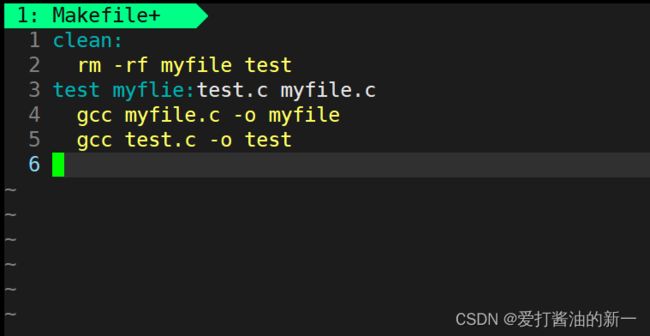
这时我们键入make
- 声明伪目标
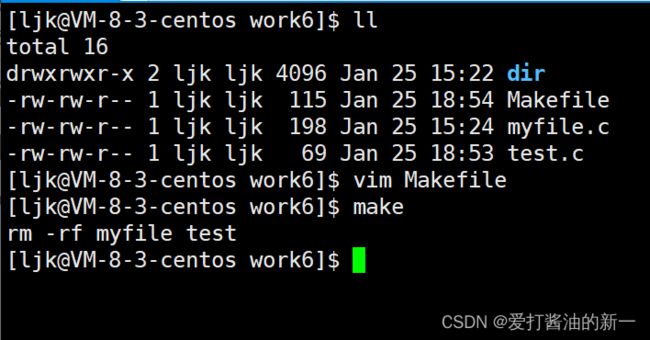
除了文件名,目标还可以是某个操作的名字,这称为"伪目标"(phony target),例如:
clean:
rm -rf myflie
如果这样的话那么make每次需要检查clean是否是一个文件,我们可以用.PHONY来声明clean是个伪目标,这样make就不会检查clean是否是个文件,而是直接执行以下的命令.
我们还可以查询手册知道其它关于makefile的关键字:makefile关键字手册
⭐1.4 前置条件(prerequisites)
前置条件通常是一组文件名,之间用空格分隔。它指定了"目标"是否重新构建的判断标准:只要有一个前置文件不存在,或者有过更新(前置文件的last-modification时间戳比目标的时间戳新),"目标"就需要重新构建。
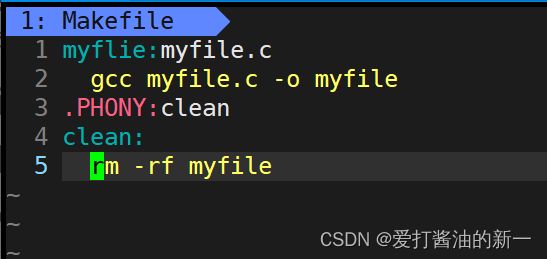
- 多级构建:当第一个目标的前置条件不存在时,make会自动调用后续目标生成前置条件
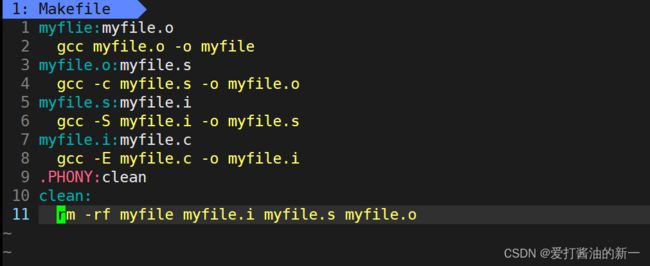
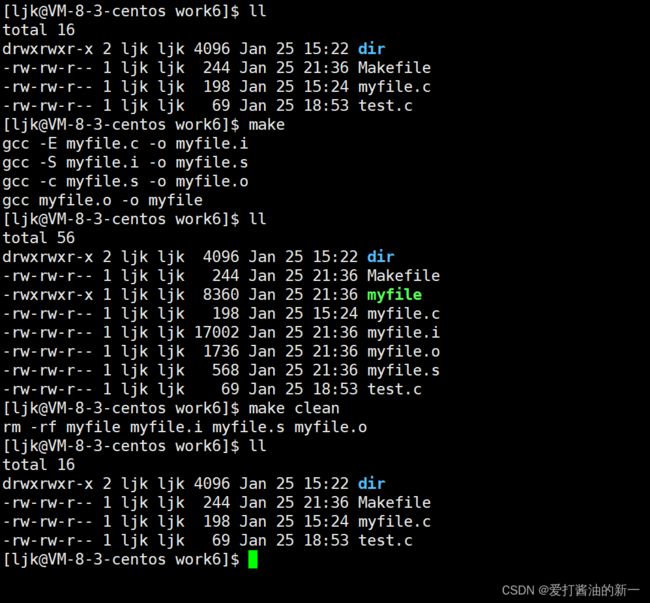
这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
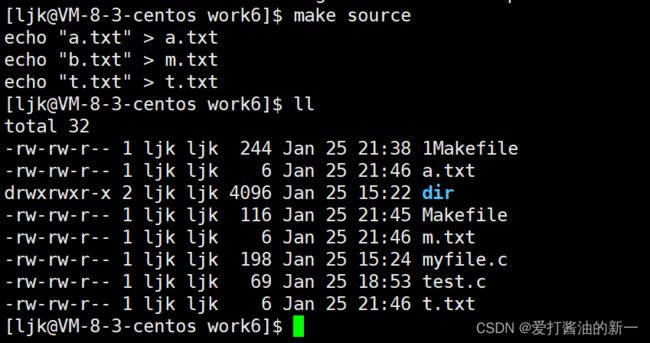
- 多步执行:当我们需要生成多个文件或者执行多不时,只需要再定义一个目标,再将其余需要构建的目标加入即可
Makefile:
a.txt:
echo "a.txt" > a.txt
m.txt:
echo "b.txt" > m.txt
t.txt:
echo "t.txt" > t.txt
source: a.txt m.txt t.txt
⭐1.5 命令(commands)
命令(commands)表示如何更新目标文件,由一行或多行的Shell命令组成。它是构建"目标"的具体指令,它的运行结果通常就是生成目标文件。
- 每个命令前都必须有一个tab键,我们也可以用
.RECIPEPREFIX声明其它键
.RECIPEPREFIX = >
myfile:myfile.c
>gcc myfile.c -o myfile
.PHONY:clean
clean:
>rm -rf myfile
我们用>号代替了tab键,每个命令前用>就可以了
2.Makefile文件语法
⭐2.1 注释
#在Makefile中表示注释。
# 这是注释
myfile: myfile.c
# 这是注释
gcc myfile.c -o myfile # 这也是注释
⭐2.2 回声
正常情况下我们每次执行make命令时,系统都会打印相应的命令再执行

我们在命令前加上@就可以关闭回声。
.PHONT:source
source:
@echo "这是第二次" > test.c
@cat test.c

注意:由于我们具体要看我们到底执行了哪些命令,所以我们一般只在注释和纯echo显示命令前加上@
⭐2.3 通配符
通配符(wildcard)用来指定一组符合条件的文件名。Makefile 的通配符与 Bash 一致。
- 星号
*:可以使用星号代替零个、单个或多个字符- 问号
?:可以匹配任意一个字符- 中括号
[]:匹配中括号任意一个字符,如[ljk]代表匹配一个l,j或k的字符[-]:匹配范围,[0-9]代表匹配任一个数字[!]:匹配不是中括号的一个字符,[!0-9]表示不匹配a-z中任意字符
关于通配符更详细的讲解:Linux通配符
⭐2.4 变量和赋值符
Makefile 允许使用=自定义变量。
ret = hello world
test:
@echo $(ret)
上面代码中,变量 ret 等于 Hello World。调用时,变量需要放在 $( ) 之中。此时会打印出hello world
有时变量的值可能会指向另外一个变量。
a1 = $(a2)
这时就出现了问题,a1 的值到底在定义时扩展(静态扩展),还是在运行时扩展(动态扩展)?如果 a2 的值是动态的,这两种扩展方式的结果可能会差异很大。
为了解决类似问题,makefile提供了四个运算符:
a1 := $(a2)
# 在执行时扩展,允许递归扩展。
a1 := $(a2)
# 在定义时扩展。
a1 ?= $(a2)
# 只有在该变量为空时才设置值。
a1 += $(a2)
# 将值追加到变量的尾端。
⭐2.5 内置变量
Make命令提供一系列内置变量,比如,(CC) 指向当前使用的编译器,(MAKE) 指向当前使用的Make工具。这主要是为了跨平台的兼容性,详细的内置变量清单见手册。
output:
$(CC) -o output input.c
⭐2.6 自动变量
Make命令还提供一些自动变量,它们的值与当前规则有关。主要有以下几个:
- $ @
@指代当前目标,就是Make命令当前构建的那个目标。比如,make clean的@ 就指代clean。
a.txt b.txt:
touch $@
等同于下面的写法
a.txt:
touch a.txt
b.txt:
touch b.txt
- $ <
<指代第一个前置条件,比如规则为 a.txt: b.txt c.txt,那么$<就指代b.txt
a.txt: b.txt c.txt
cp $< $@
等同于下面的写法
a.txt: b.txt c.txt
cp b.txt a.txt
-
$ ?
?指代比目标时间戳更新的所有前置条件,例如t:p1 p2 p3,p1,p2时间戳新于t,则$?指代p1,p2 -
$ ^
^指代所有前置条件,例如t:p1 p2 p3,p1,p2时间戳新于t,则$^指代p1,p2,p3
⭐2.7 函数
Makefile还可以使用函数,格式如下:
$(function arguments)
Makefile提供了许多内置函数,可供调用。下面是几个常用的内置函数。
1. shell函数
shell 函数用来执行 shell 命令。
srcfiles := $(shell echo src/{00..99}.txt)
2. wildcard函数
wildcard 函数用来在 Makefile 中,替换 Bash 的通配符。
srcfiles := $(wildcard src/*.txt)
3. subst函数
subst 函数用来文本替换,格式如下:
$(subst from,to,text)
下面的例子将字符串"feet on the street"替换成"fEEt on the strEEt"。
$(subst ee,EE,feet on the street)
4. patsubst函数
patsubst 函数用于模式匹配的替换,格式如下。
$(patsubst pattern,replacement,text)
下面的例子将文件名"x.c.c bar.c",替换成"x.c.o bar.o"。
$(patsubst %.c,%.o,x.c.c bar.c)
5. 替换后缀名
替换后缀名函数的写法是:变量名 + 冒号 + 后缀名替换规则。它实际上patsubst函数的一种简写形式。
min: $(OUTPUT:.js=.min.js)
上面代码的意思是,将变量OUTPUT中的后缀名 .js 全部替换成 .min.js
3.Linux小程序进度条
⭐3.1 缓冲区概念
我们利用printf函数进行输出的时候,实际上编译器会将我们的输出内容写到缓冲区,等到系统刷新缓冲区的时候,屏幕上才会输出相应内容,同时清空缓冲区
所以我们进行输出的时候会带上/n等选项,因为那会帮我们自动刷新缓冲区,但是加上/r,会将光标移动到行开头,然后刷新缓冲区,我们的结果就会被新打印出来的结果给覆盖掉,所以我们应该在之前刷新缓冲区,我们有一个刷新缓冲区的函数fflush,以下为test.c用例
此时会观察到屏幕先打印了结果,并且光标移动到了行首,因此接下打印出的命令行将原结果覆盖掉了

⭐3.2 进度条代码
#include "proc.h"
#define SIZE 102
#define STYLE '='
#define ARR '>'
// "|/-\\"
void process()
{
const char *lable = "|/-\\";
char bar[SIZE];
memset(bar, '\0', sizeof(bar));
int i = 0;
while( i <= 100 )
{
printf("[%c][\033[42;32;31m%-100s\033[0m][%d%%]\r", lable[i%4], bar, i);
fflush(stdout);
bar[i++] = STYLE;
if(i != 100) bar[i] = ARR;
usleep(100000);
}
printf("\n");
}
我们还可以自己添加颜色输出:printf颜色输出