基于 CUDA 的神经网络进行气温预测
基于 CUDA 的神经网络进行气温预测
一、基于 CUDA 的神经网络进行气温预测
任务描述:搭建神经网络,根据之前已有的天气信息预测接下来的最高气温。
二、数据
1. 数据介绍
| \ | year | month | day | week | temp_2 | temp_1 | average | actual | friend |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016 | 1 | 1 | Fri | 45 | 45 | 45.6 | 45 | 29 |
| 1 | 2016 | 1 | 2 | Sat | 44 | 45 | 45.7 | 44 | 61 |
| 2 | 2016 | 1 | 3 | Sun | 45 | 44 | 45.8 | 41 | 56 |
数据介绍:
- year:年。
- month:月。
- day:日。
- week:星期几。
- temp_2:前天最高气温。
- temp_1:昨天最高气温。
- average:历史上,每年这一天的平均最高气温。
- actual:当天实际最高气温。
- friend:朋友认为的最高气温。
2. 数据预处理
以下只需要把数据路径(变量datapath)替换就行:
# 数据预处理
datapath = ''
features = pd.read_csv(datapath)
features = pd.get_dummies(features)
labels = np.array(features['actual'])
input_features = features.drop('actual',axis=1)
input_features = np.array(input_features)
device = 'cuda' # 设置 cuda
# 标准化
input_features = StandardScaler().fit_transform(input_features)
x = torch.tensor(input_features, dtype=float).to(device)
y = torch.tensor(labels, dtype=float).to(device)
batchsize = 16 # 采用 mini-batch 方式训练
三、模型
1. 前言
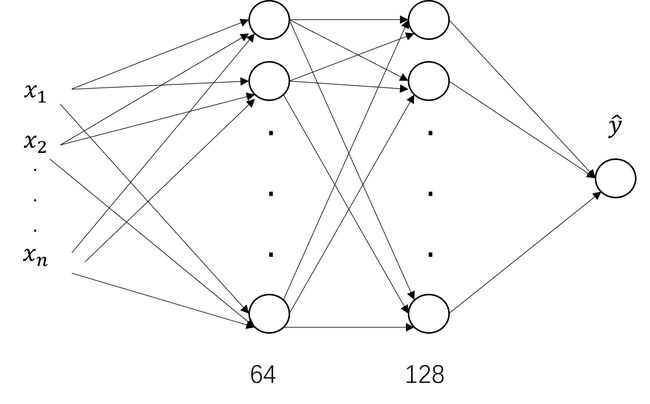
本文搭建一个有两层隐藏层的神经网络,网络图如下所示:
2. 最原始模型实现
此种方法采用最简单粗暴、最原始方法搭建网络,即一步步设置每层的参数,从初始化到更新,简单但是对初学者理解很友好:
# 参数初始化
weights1 = torch.randn(14, 64, dtype=float, requires_grad=True, device=device)
bias1 = torch.randn(64, dtype=float, requires_grad=True, device=device)
weights2 = torch.randn(64 , 128, dtype=float, requires_grad=True, device=device)
bias2 = torch.randn(128, dtype=float, requires_grad=True, device=device)
weights3 = torch.randn(128, 1, dtype=float, requires_grad=True, device=device)
bias3 = torch.randn(1, dtype=float, requires_grad=True, device=device)
lr = 0.0001 # 设置学习率
losses = [] # 保存 loss
# 开始训练
for epoch in range(100000):
for start in range(0, len(x), batchsize):
end = start + batchsize if start + batchsize < len(x) else len(x)
xx = x[start:end]
yy = y[start:end]
# 前向传播
hidden1 = xx.mm(weights1) + bias1
hidden1 = torch.relu(hidden1)
hidden2 = hidden1.mm(weights2) + bias2
hidden2 = torch.relu(hidden2)
prediction = hidden2.mm(weights3) + bias3
loss = torch.mean((prediction - yy)**2)
loss.backward()
losses.append(loss.to('cpu').data.numpy())
# 参数更新
weights1.data.add_(- lr * weights1.grad.data)
bias1.data.add_(- lr * bias1.grad.data)
weights2.data.add_(- lr * weights2.grad.data)
bias2.data.add_(- lr * bias2.grad.data)
weights3.data.add_(- lr * weights3.grad.data)
bias3.data.add_(- lr * bias3.grad.data)
# 梯度清零
weights1.grad.data.zero_()
bias1.grad.data.zero_()
weights2.grad.data.zero_()
bias2.grad.data.zero_()
weights3.grad.data.zero_()
bias3.grad.data.zero_()
if epoch % 1000 == 0:
print('epoch: {0:5} loss: {1}'.format(epoch, np.mean(losses)))
losses.clear()
PS: 此种实现方法没写推理,过于简单,只需要按照前向传播把测试数据走一遍就是预测结果。
3. nn.Sequential 实现
nn.Sequential 是 nn.Module 的子类,已经实现了内部的 forward 函数。里面的模块必须是按照顺序进行排列的(代价是失去了部分灵活性)。
x_size = x.shape[1]
hidden1 = 64
hidden2 = 128
output_size = 1
my_nn = torch.nn.Sequential(
torch.nn.Linear(x_size,hidden1),
torch.nn.ReLU(),
torch.nn.Linear(hidden1,hidden2),
torch.nn.ReLU(),
torch.nn.Linear(hidden2,output_size)
).to(device)
# 优化器
lr = 0.0001
optimizer = torch.optim.Adam(my_nn.parameters(), lr=lr)
# 损失函数
crition = torch.nn.MSELoss()
losses = []
# 训练
for epoch in range(100000):
for start in range(0, len(x), batchsize):
end = start + batchsize if start + batchsize < len(x) else len(x)
xx = x[start:end]
yy = y[start:end]
predition = my_nn(xx.to(torch.float32))
loss = crition(predition.reshape(-1), yy.to(torch.float32))
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.to('cpu').data.numpy())
if epoch % 1000 == 0:
print('epoch: {0:5} loss: {1}'.format(epoch, np.mean(losses)))
losses.clear()
4. nn.ModuleList 实现
nn.ModuleList 是 nn.Module 的子类,用来存储任意数量的 nn.module(比较灵活自由),需要写 forward 函数。此种方法实现需要在类中实现网络各层的定义及前向计算。
class net(torch.nn.Module):
def __init__(self):
super().__init__()
self.linears = torch.nn.ModuleList(
[torch.nn.Linear(14,64),
torch.nn.ReLU(),
torch.nn.Linear(64,128),
torch.nn.ReLU(),
torch.nn.Linear(128,1)]
)
def forward(self,x):
for module in self.linears:
x = module(x)
return x
my_nn = net().to(device)
# 优化器
lr = 0.0001
optimizer = torch.optim.Adam(my_nn.parameters(), lr=lr)
# 损失函数
crition = torch.nn.MSELoss()
losses = []
for epoch in range(100000):
for start in range(0, len(x), batchsize):
end = start + batchsize if start + batchsize < len(x) else len(x)
xx = x[start:end]
yy = y[start:end]
prediction = my_nn(xx.to(torch.float32))
loss = crition(prediction.reshape(-1), yy.to(torch.float32))
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.to('cpu').data.numpy())
if epoch % 1000 == 0:
print('epoch: {0:5} loss: {1}'.format(epoch, np.mean(losses)))
losses.clear()
nn.Sequential 和 nn.ModuleList 容器自动完成网络参数的初始化,故代码中不需要初始化。
PS: 以上方法均是采用 GPU 训练神经网络,若要采用 CPU 训练,只需要把代码中和device相关的关键字去掉,其它的保留即可。
四、推理
1. 推理
直接上代码:
test_data = features.drop('actual',axis=1)
test_data = np.array(test_data, dtype=float)
test_data = StandardScaler().fit_transform(test_data)
years = features['year']
months = features['month']
days = features['day']
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
prediction_datas = my_nn(torch.tensor(test_data, dtype=float).to(torch.float32).to(device))
prediction_datas = prediction_datas.to('cpu').data.numpy()
true_datas = np.array(features['actual'])
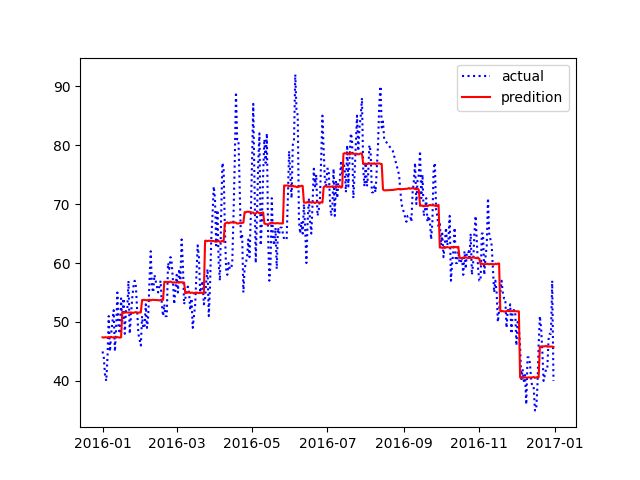
2. 结果可视化
plt.plot(dates, true_datas, 'b:', label = 'actual')
plt.plot(dates, prediction_datas, 'r-', label = 'predition')
plt.legend()
plt.savefig('result.png')
六、总结
1. nn.Sequential 实现的完整代码
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
import torch
from tqdm import tqdm
import datetime
import matplotlib.pyplot as plt
# 数据预处理
datapath = ''
features = pd.read_csv(datapath)
features = pd.get_dummies(features)
labels = np.array(features['actual'])
input_features = features.drop('actual',axis=1)
input_features = np.array(input_features)
device = 'cuda'
# 标准化
input_features = StandardScaler().fit_transform(input_features)
x = torch.tensor(input_features, dtype=float).to(device)
y = torch.tensor(labels, dtype=float).to(device)
batchsize = 16
x_size = x.shape[1]
hidden1 = 64
hidden2 = 128
output_size = 1
my_nn = torch.nn.Sequential(
torch.nn.Linear(x_size,hidden1),
torch.nn.ReLU(),
torch.nn.Linear(hidden1,hidden2),
torch.nn.ReLU(),
torch.nn.Linear(hidden2,output_size)
).to(device)
# 优化器
lr = 0.0001
optimizer = torch.optim.Adam(my_nn.parameters(), lr=lr)
# 损失函数
crition = torch.nn.MSELoss()
losses = []
# 训练
for epoch in range(100000):
for start in range(0, len(x), batchsize):
end = start + batchsize if start + batchsize < len(x) else len(x)
xx = x[start:end]
yy = y[start:end]
predition = my_nn(xx.to(torch.float32))
loss = crition(predition.reshape(-1), yy.to(torch.float32))
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.to('cpu').data.numpy())
if epoch % 1000 == 0:
print('epoch: {0:5} loss: {1}'.format(epoch, np.mean(losses)))
losses.clear()
# inference
test_data = features.drop('actual',axis=1)
test_data = np.array(test_data, dtype=float)
test_data = StandardScaler().fit_transform(test_data)
years = features['year']
months = features['month']
days = features['day']
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
prediction_datas = my_nn(torch.tensor(test_data, dtype=float).to(torch.float32).to(device))
prediction_datas = prediction_datas.to('cpu').data.numpy()
true_datas = np.array(features['actual'])
# 结果展示
plt.plot(dates, true_datas, 'b:', label = 'actual')
plt.plot(dates, prediction_datas, 'r-', label = 'predition')
plt.legend()
plt.savefig('result.png')
2. nn.ModuleList 实现的完整代码
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
import torch
from tqdm import tqdm
import datetime
import matplotlib.pyplot as plt
# 数据预处理
datapath = ''
features = pd.read_csv(datapath)
features = pd.get_dummies(features)
labels = np.array(features['actual'])
input_features = features.drop('actual',axis=1)
input_features = np.array(input_features)
device = 'cuda'
# 标准化
input_features = StandardScaler().fit_transform(input_features)
x = torch.tensor(input_features, dtype=float).to(device)
y = torch.tensor(labels, dtype=float).to(device)
batchsize = 16
class net(torch.nn.Module):
def __init__(self):
super().__init__()
self.linears = torch.nn.ModuleList(
[torch.nn.Linear(14,64),
torch.nn.ReLU(),
torch.nn.Linear(64,128),
torch.nn.ReLU(),
torch.nn.Linear(128,1)]
)
def forward(self,x):
for module in self.linears:
x = module(x)
return x
my_nn = net().to(device)
# 优化器
lr = 0.0001
optimizer = torch.optim.Adam(my_nn.parameters(), lr=lr)
# 损失函数
crition = torch.nn.MSELoss()
losses = []
for epoch in range(100000):
for start in range(0, len(x), batchsize):
end = start + batchsize if start + batchsize < len(x) else len(x)
xx = x[start:end]
yy = y[start:end]
prediction = my_nn(xx.to(torch.float32))
loss = crition(prediction.reshape(-1), yy.to(torch.float32))
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.to('cpu').data.numpy())
if epoch % 1000 == 0:
print('epoch: {0:5} loss: {1}'.format(epoch, np.mean(losses)))
losses.clear()
# inference
test_data = features.drop('actual',axis=1)
test_data = np.array(test_data, dtype=float)
test_data = StandardScaler().fit_transform(test_data)
years = features['year']
months = features['month']
days = features['day']
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
prediction_datas = my_nn(torch.tensor(test_data, dtype=float).to(torch.float32).to(device))
prediction_datas = prediction_datas.to('cpu').data.numpy()
true_datas = np.array(features['actual'])
# 结果展示
plt.plot(dates, true_datas, 'b:', label = 'actual')
plt.plot(dates, prediction_datas, 'r-', label = 'predition')
plt.legend()
plt.savefig('result.png')
说明: 以上完整代码均需要加上数据路径才能正常运行!若要把完整代码放在 CPU上跑,只需要把和device有关的关键字去掉,其它部分不变即可。
参考资料
1.https://zhuanlan.zhihu.com/p/624916177
2.https://blog.csdn.net/chengyuhaomei520/article/details/123708619?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168638769416782425158486%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=168638769416782425158486&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-2-123708619-null-null.142v88insert_down38v5,239v2insert_chatgpt&utm_term=%E6%B0%94%E6%B8%A9%E9%A2%84%E6%B5%8B&spm=1018.2226.3001.4187