操作系统——期末复习
文章目录
- 第一章 操作系统引论
-
- 操作系统基本特性
-
- 并发
- 共享
- 虚拟
- 异步
- 操作系统主要功能
-
- 处理机管理功能
- 存储器管理功能
- 设备管理功能
- 文件管理功能
- 操作系统与用户之间的接口
- 微内核
- 第二章 进程
-
- 进程的特征和生命周期
-
- 进程的三种定义
- 进程的特征(教材P39)
- 进程控制块PCB
- 进程的状态转换
- 前趋图DAG
- 进程同步
-
- 进程对临界资源的访问需要互斥,其需要遵从以下四个原则:
- Perterson方法
- 硬件同步
- 信号量
- PV操作
- 记录型信号量
- 三个经典同步问题
-
- 生产者-消费者问题
- 读者-写者问题
- 哲学家进餐问题
- 进程通信
- 第三章 处理机调度与死锁
-
- 低/中/高级调度
- 死锁定理
- 死锁的资源分配图(教材P114)
- 死锁的必要条件
- 安全/不安全状态
- 处理死锁的策略
-
- 预防
- 避免策略
- 死锁的检测和解除
- 忽略策略
- 死锁避免
- 银行家算法
- CPU调度算法
-
- 抢占式和非抢占式
- 多级反馈队列调度算法
- 先来先服务
- 短作业SJF(进程SPF)优先
- 最短剩余时间优先
- 高响应比优先(作业调度)
- 高优先级优先
- 一些性能指标的含义和计算
- 第四章 存储器管理 第五章 虚拟存储器
-
- 装入
- 静态链接,装入时动态链接,运行时动态链接的对比/优劣
- 连续内存管理的空闲内存适应算法
-
- 首次适应
- 循环首次适应
- 最佳适应
- 最坏适应
- 逻辑/物理地址的相互变换
- 离散内存分配的缺点?如何解决
- 请求分页的内部机制
- 页面置换算法
- 段式/页式的区别
-
- 页式存储管理
- 段式存储管理
- 段页式
- 第六章 输入输出系统
-
- 第七章 文件管理(都要看)
-
- 磁盘调度算法
-
- 先来先服务
- 最短寻道时间优先
- 电梯调度\
- 循环扫描法\
- 外存的组织方式
-
- 文件系统的连续分配
- 文件系统的隐式链接
- 文件系统的显式链接
- 索引节点分配
- 混合索引
- 混合索引计算文件最大长度
- inode数据结构时,计算I/O次数
- 第八章 磁盘存储器的管理
-
- 磁盘管理空闲块的方法(文件存储空间的管理)
-
- 空闲表法
- 空闲链表法
- 位示图法
- 成组链接法
- buffer和cache的区别
- SPOOLing
- 第九章 操作系统接口
第一章 操作系统引论
操作系统基本特性
并发
并发:两个或多个事件在同一时间间隔内发生。
程序并发执行时的特征:间断性,失去封闭性,不可再现性。
并行:两个或多个事件在同一时刻发生。
共享
虚拟
时分复用,空分复用
异步
程序的执行”走走停停“
操作系统主要功能
处理机管理功能
进程控制,进程同步,进程通信,调度(作业调度、进程调度)
存储器管理功能
内存分配,内存保护,地址映射,内存扩充
设备管理功能
缓冲管理,设备分配,设备处理
文件管理功能
文件存储空间的管理,目录管理,文件的读/写管理和保护
操作系统与用户之间的接口
用户接口,程序接口
微内核
(1)提高系统可扩展性。
(2)增强系统可靠性。
(3)可移植性强。
(4)提供对分布式系统的支持。
(5)融入了面对对象技术。
第二章 进程
进程的特征和生命周期
进程的三种定义
(1)进程是程序的一次执行。
(2)进程是一个程序及数据在处理机上顺序执行时所发生的活动。
(3)进程是具有独立功能的程序在一个数据集合上运行的过程,他是系统进行资源分配和调度的一个独立单位。
进程的特征(教材P39)
动态性:有一定的生命周期。而程序是一组有序指令的集合,存放在介质上,本身不具有活动的含义,是静态的。
并发性:指多个实体同存于内存中,且能在一段时间内同时执行。
独立性:指进程实体是一个能独立运行、独立获得资源、独立接受调度的基本单位。
异步性:进程是按异步方式执行的,即按各自独立的、不可预知的速度向前推进->导致并发执行产生结果的不可再现性->配置相应进程同步机制实现可实现可再现。
进程控制块PCB
进程的状态转换
前趋图DAG
有向无循环图。用于描述进程之间执行的先后顺序。图中每一个节点可用来表示一个进程或程序段、乃至一条语句,结点间的有向边则表示两个结点之间存在的偏序或前趋关系。
根据前驱图设计信号量。
进程同步
临界区问题的解决方案应满足的条件:互斥访问,空闲让进、有限等待
进程对临界资源的访问需要互斥,其需要遵从以下四个原则:
空闲让进:临界区空闲时应该允许一个进程访问
忙则等待:临界区被访问时,其余想访问他的进程必须等待
有限等待:等待的进程在外等待的时间必须是有限的
让权等待:若等待进程一直等待,迟迟进不到临界区时,应该让出cpu处理机,防止忙等
临界区的解决方案:
Perterson方法
硬件同步
硬件指令,使不能被打断:test_and_set,swap
有可能出现无穷等待;忙等
信号量
一般表示资源数量
初始值为1的信号量又称为mutex互斥锁
信号量的应用:互斥,同步,前趋关系
PV操作
P:wait(s),V:signal(s),作为系统调用。原子操作。
记录型信号量
使用记录型信号量要保证wait和signal成对出现使用
三个经典同步问题
生产者-消费者问题
读者-写者问题
哲学家进餐问题
进程通信
两种通信模型
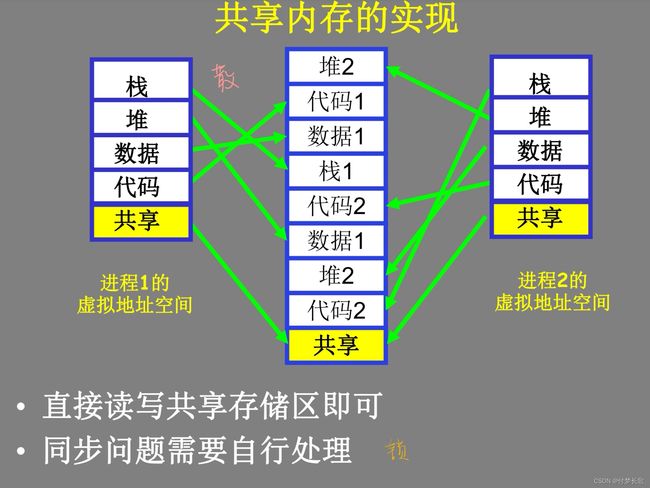
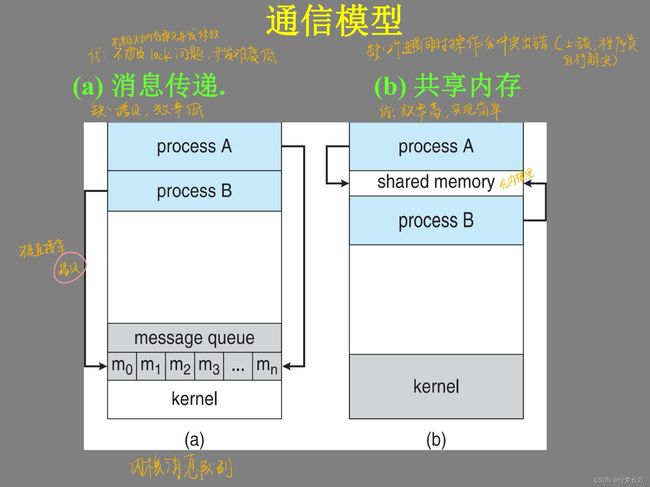
补充:管道pipe
注:不考线程
第三章 处理机调度与死锁
低/中/高级调度
作业从提交到完成需要经历哪些调度?
高级调度:
死锁定理
一组进程处于死锁状态,如果他们中每个进程都在等待只由组内其他进程才能引发的事件
死锁的资源分配图(教材P114)
死锁的必要条件
互斥条件:资源只能由一个进程使用。不能被破坏
请求和保持:需要其他资源时不(完全)释放自己的资源
不可抢占:只能由自己主动释放
循环等待:可以找到一个进程资源的循环链
安全/不安全状态
如果系统无法找到一个安全序列,则称系统处于不安全状态。虽然并非所有不安全状态都必然会转化为死锁状态,但当系统进入不安全状态后,就有可能进入死锁状态。
反之,只要系统处于安全状态,系统便不会进入死锁状态。
即,不安全状态真包含死锁。原因如下:
进程在正常运行过程中途可能会释放一部分资源
进程在执行过程中,可能提前终止
实际进程需要的最大资源小于声名的最大需求资源
进程申请的资源为可消耗性资源
处理死锁的策略
预防
破坏必要条件
过于保守,限制资源利用率
避免策略
防止进入不安全状态
死锁的检测和解除
允许进入死锁,然后检测并解除。
检测:死锁的检测算法。算法思想同银行家算法。实际情况。
解除:(1)剥夺资源:从其他进程剥夺足够数量的资源给发生死锁的进程
(2)撤销进程(使全部死锁进程都夭折)
忽略策略
do nothing
死锁避免
死锁避免的实质:
银行家算法
为了找到一个安全序列
available
work:系统当前资源数目
finish:进程是否顺利运行结束
已获取资源allocation[i,j]
最大需求矩阵max[i,j]
需求矩阵need[i,j]=max[i,j] - allocation[i,j]
CPU调度算法
调度顺序,甘特图
会考1~2种,提到了多级反馈队列
作业调度:作业从外存调入内存的过程
进程调度:进程从内存到分配CPU执行的过程
抢占式和非抢占式
抢占式:优先权原则,短进程优先,时间片原则
非抢占式:系统一旦将处理机分配出去,此进程一直执行到完成
多级反馈队列调度算法
对其他算法的折中权衡。设置多个就绪队列,为各队列设置不同的优先级。优先级由高到低,时间片由小到大。对各类进程相对公平,每个新到达的进程都可以很快得到响应,短进程只需要较少的时间就可以完成,不必实现估计进程的运行时间,可以灵活调整对各类进程偏好程度。
当新进程到达时,按照先到先服务的方式排到第一队列的末尾,如果在第一个时间片结束时未完成,则会到第二个队列的末尾,如此下去。如果处于最低级队列则放到末尾。
当执行第i级的进程时,此时有新的进程到达比i高优先级的队列中,会发生抢占处理机,未执行完的进程放到i队列的末尾。
当k级队列为空才会为k+1队列分配处理机。
先来先服务
既可用于作业调度又可由于进程调度
具有良好的公平性,没有饥饿,系统开销小
较长的平均等待时间,较长的平均周转时间
对长作业友好,短作业不友好
短作业SJF(进程SPF)优先
短作业优先:从后备队列选几个
短进程优先:从就绪队列中选一个
提高系统吞吐量,缩短平均周转时间,平均等待时间最小,平均周转时间最小
但对长作业不利,可能造成饥饿,需要估计CPU burst的长度
最短剩余时间优先
是短作业优先的可抢占模式,性能与短作业优先相似
高响应比优先(作业调度)
响应时间:从用户通过键盘提交一个请求开始,直至系统首次产生响应为止的时间间隔,包括:从键盘输入的请求信息传到处理及的时间、处理机对请求信息进行处理的时间、将响应信息回送到终端显示器的时间。
响应比=(等待时间+服务时间)/ 服务时间
通过计算等待时间和运行时间的加权来判别,性能介于FCFS和SJF之间
高优先级优先
约定最小整数为最高优先级
注:时间片轮转是进程调度而不是作业调度
一些性能指标的含义和计算
给出CPU时间、I/O时间。计算CPU占用率、周转时间等。
周转时间=作业完成时间-作业提交时间
平均周转时间=周转时间和/作业数
带权周转时间=作业周转时间/作业实际运行时间
注:本章不考实时调度
第四章 存储器管理 第五章 虚拟存储器
装入
静态链接,装入时动态链接,运行时动态链接的对比/优劣
静/动链接的比较
连续内存管理的空闲内存适应算法
首次适应
地址递增,顺序查找,第一个能满足的即分配给进程
循环首次适应
邻近适应
最佳适应
容量递增,找到第一个能满足要求的空闲分区
最坏适应
容量递减,找到第一个能满足要求的分区
逻辑/物理地址的相互变换
注:不考二级页表
离散内存分配的缺点?如何解决
请求分页的内部机制
页面置换算法
注:本章不考概念,只考对比
页面置换算法
段式/页式的区别
页式存储管理
特征是等分内存,解决外碎片的问题。
段式存储管理
特征是逻辑分段,便于实现共享和保护。
地址转换公式:物理地址=段首地址+段内地址
段式存储管理方式的引入,主要是为了更好地满足用户在编程和使用上多方面的要求,其中有些要求是其他几种存储管理方式所难满足的,正因为如此,这种存储管理方式已成为当今所有存储管理方式的基础,许多高级语言的程序,也都支持段式存储管理方式。引入段式存储管理方式,主要是为了满足用户的下述要求:
(1)方便编程:通常一个作业是由若千个自然段组成,因而要把自己的作业按照逻辑关系划分成若干个段,每个段都有自己的名字和长度,要访问的逻辑地址是由段名(段号)和段内偏移量(段内地址)决定,每个段从0开始编址。这样用户程序在执行中可用段名和段内地址进行访问。
(2)分段共享:通常在实现程序和数据的共享时,以信息的逻辑单位为基础,例如共享某个例程和函数。而在分页系统中每一页都只是存放信息的物理单位,其本身并无完整的意义,不便于实现信息共享。而段是信息的逻辑单位。因此,为了实现段的共享,也要使存储管理能与用户程序分段的组织方式相适应。
(3)分段保护:在多道程序环境下,为了防止其他程序对某程序在内存中的数据被破坏,必须采取保护措施。对内存中信息的保护,同样是对信息的逻辑单位进行保护。因此采用分段的组织和管理方式,对于实现保护功能,更方便。
(4)动态链接:通常,用户源程序经过编译后所形成的若千个目标程序,还须经过链接形成可执行程序,方能执行。这种在装入时运行的链接称为静态连接。动态链接是指在作业运行前不链接目标程序段。作业要运行之前先将主程序所对应的目标程序装入内存并启动运行,当运行过程中又需要调用某段时,才将该段调入内存并进行链接。可见,动态链接也要求以段作为管理的逻辑单位。
(5)动态增长:在实际使用中,有些段特别是数据段,会不断地增长,而事先又无法确切地知道数据段会增长到多大,这种动态增长的情况是其他几种存储管理方式都难于应付的,而段式存储管理方式能较好地解决这一问题。
段页式
结合以上两种存储管理方案。系统为每个进程建立一张段表,每个段建立一张页表。地址转换过程,要经历查段表、页表后才能得到最终物理地址。
第六章 输入输出系统
第七章 文件管理(都要看)
磁盘访问时间 = 寻道时间 + 旋转延迟时间 + 数据传输时间
寻道时间 = 启动磁臂时间 + 所移动的磁道数 * 每移动一个道花费的时间
旋转延迟时间平均是半圈,与磁盘转速有关
磁盘调度算法
寻道时间/距离的计算
在驱动程序处实现
先来先服务
公平低效
由于长作业会长时间占据处理机,该算法比较有利于长作业,而不利于短作业
即有利于CPU繁忙的作业,而不利于I/O繁忙的作业
最短寻道时间优先
高效,不公平,磁臂黏着问题
电梯调度
避免磁臂黏着,不能随便逆转,效率更高
到头了再逆转
公平性:在某个方向上也是最短寻道时间优先,减少了寻道时间
最坏情况的时延:2T(T是转一圈所需的时间)
循环扫描法
只沿一个方向移动,没有逆转操作
折中,降低最坏情况下的时延为T+T1(快速移动回0的时间,可忽略不计)
消除了对两端磁道请求的不公平。
注:1)一定要搞清楚是磁盘在转,不是磁头在转,注意顺逆时针转时磁头读的顺序
2)上电后磁盘一直在转
外存的组织方式
文件系统的连续分配
file allocation table(filename,start block,length)
优点:简单,访问只需要起始块号和长度;可以随机存取;读连续块的效率高
缺点:浪费空间,外部碎片问题->紧凑;文件不能动态增长
创建文件:
删除文件:位图连续位1->0,FAT中删除信息
文件系统的隐式链接
文件用链表表示,每个磁盘块存储下一个磁盘块的地址,block=pointer+文件内容
优点:消除外部碎片,磁盘利用率高;文件大小可动态增长,不必事先声明文件大小
缺点:
(1)指针占用空间->可用字节数不是2的幂次方->读文件时应该去掉指针,跨block的文件还需拼接
(2)seek操作访问特定盘块需要多次读盘,I/O次数取决于偏移量的大小,因为指针要从头指针开始寻找
(3)若其中一个block损坏,其后的block都会丢失,而且无法回收
directory(file,start,end)
创建文件:申请inode,start block=end block=-1,申请block,修改位图
删除文件:
文件系统的显式链接
文件分配表(FAT)的工作原理
将链接信息集中存放在FAT中,启动时一次读入内存
系统仅一份全局表常驻内存(实际切了方式FAT表损坏,还有备份)
优点:隐式链接的所有优点+查找指定盘块的速度比隐式链接快(常驻内存)
缺点:磁盘较大时,FAT表也大,占用的内存过多(使用较大block?-> 内部碎片)
索引节点分配
用inode记录文件实际位置
优点:节省内存(相对于FAT);将inode集中起来,方便做冗余,从而提高了文件系统的可靠性
要先读索引 -> 比连续分配多一次I/O,索引相当于页表
dictory(file,index block)
索引过多? -> i-node
混合索引
最小数据交换单位:block
以v1为例:
创建文件:
最多I/O:3次
找一个inode bitmap为0的,0->1
将此空闲inode所在的block取出,写入文件信息
写回inode所在的block
最少I/O:N+2次
找一个inode是0的,发现全是1,直到读N次读到最后一个block才有0
将此空闲inode所在的block取出,写入文件信息
写回inode所在的block
删除文件:
找inode中filename对应的
将inode指向的所有block的block bitmap的0->1(不用清除block内容)
将inode的inode bitmap
v1不支持多目录
v2在v1的基础上进行了列优化,减少找inode时的I/O次数
将文件名提到前面,文件名之后的部分在后面依次排开
v2依然不支持多目录
v3支持多级目录
i0是根目录”/“的inode
上一层inode指向的block存储多个inode的所有信息
v3中,如果上层目录的inode被破坏,下层的树状结构还在,但不知道名字,可以回收
查找文件:以/home/exam/t1.c为例
Unix、Linux系统的根目录是/,所以先读入根目录的inode:i0
有了根目录的inode之后,便能得到根目录下对应的所有文件(夹)对应的inode
将所有inode读入内存,搜索所有inode,找到文件名为home的inode
同理我们从home-inode得到的home目录下的所有文件(夹)对应的inode
然后再这些inode读入内存,再搜索得到exam对应的inode
同理根据exam-inode得到了exam目录下的所有文件(夹)对应的inode
然后将这些inode读入内存,从其中找名为t1.txt对应的inode,找到后根据其inode里面的直接索引和间接索引将对应的块读读入内存
原文链接:https://blog.csdn.net/qq_36321889/article/details/91876469
v4改善了v3”block存储整个inode的信息“的情况(离散不便集中保护),将所有inode都放在前面了,block只存inode索引号,构成所有inode的结构。方便备份,增加可靠性
在查找文件时会发现,一会儿根据block里的inode索引跑到前面找整个inode信息,一会儿又因为inode里指向某个block所以跑到后面读block里的inode索引或者读文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fgIVcDvW-1656299138132)(./picture/目录查找.jpg)]
混合索引计算文件最大长度
inode数据结构时,计算I/O次数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-23tzAnZR-1656299138133)(./picture/对比内存和磁盘分配.jpg)]
第八章 磁盘存储器的管理
使用时的过程,回收时的过程、可能会出现的情况
磁盘管理空闲块的方法(文件存储空间的管理)
空闲表法
每个表项对应一个空闲区,并登记该空闲区的起始块号和块数等信息
分配时,可采用首次适应、最佳适应等算法
回收时,需要紧凑进行空闲区的合并
连续分配方式,较高的分配速度,常用于对换空间管理等需要连续分配的场合
空闲链表法
空闲盘块链适合离散分配
分配时,从头结点摘
回收时,依次插入链表尾
空闲盘区链适合离散和连续分配
位示图法
分配时,顺序检索位示图,找到第一个0,得到行列号
根据行列号计算对应的盘块号
修改位示图,对应位0->1,并将对应块分配给文件
释放时,计算出盘块号所对应的行列号
修改位示图,对应位1->0
适合离散或连续分配;位示图通常较小,可将其读入内存,进一步加快文件存储空间分配和回收的速度
成组链接法
分配过程
首先检查超级块空闲盘块号栈是否已上锁,若已上锁则进程睡眠等待;否则,核心在给超级块的空闲盘块号栈上锁后,将s_nfree减1。
若s_nfree仍大于0,则将栈顶空闲块分配出去;否则将下一组盘块内容读入超级块,再分配出去该盘块。
若s_nfree为0且栈底登记的盘块号为0,则表示系统已无空闲盘块可分配。
分配操作结束时,还需将空闲盘块号栈解锁,并唤醒所有等待其解锁的进程。
成组链接法建议看天勤的视频
buffer和cache的区别
cache:从磁盘读取数据然后存起来方便以后使用。cache实现数据的重复使用,速度慢的设备需要通过缓存将经常要用到的数据缓存起来,缓存下来的数据可以提供高速的传输速度给速度快的设备。
例如:将硬盘中的数据读取出来放在内存的缓存区中,这样以后再次访问同一个资源,速度会快很多。
buffer:写入到磁盘。buffer是为了提高内存和硬盘(或其他I/O设备)之间的数据交换的速度而设计的。buffer将数据缓冲下来,解决速度慢和快的交接问题;速度快的需要通过缓冲区将数据一点一点传给速度慢的区域。
例如:从内存中将数据往硬盘中写入,并不是直接写入,而是缓冲到一定大小之后刷入硬盘中。
buffer和cache的特点
共性:
都属于内存,数据都是临时的,一旦关机数据都会丢失。
差异:
A.buffer是要写入数据;cache是已读取数据。
B.buffer数据丢失会影响数据完整性,源数据不受影响;cache数据丢失不会影响数据完整性,但会影响性能。
C.一般来说cache越大,性能越好,超过一定程度,导致命中率太低之后才会越大性能越低。buffer来说,空间越大性能影响不大,够用就行。cache过小,或者没有cache,不影响程序逻辑(高并发cache过小或者丢失导致系统忙死除外)。buffer过小有时候会影响程序逻辑,如导致网络丢包。
D.cache可以做到应用透明,编写应用的可以不用管是否有cache,可以在应用做好之后再上cache。当然开发者显式使用cache也行。buffer需要编写应用的人设计,是程序的一部分。
原文链接:https://blog.csdn.net/qq_27516841/article/details/99682823
SPOOLing
将一台独占设备改造为共享设备的技术
由四部分组成:输入井和输出井(在磁盘上),输入缓冲区和输出缓冲区(在内存),(欲)输入进程和(缓)输出进程(模拟脱机时的外围控制机),井管理程序(控制作业与磁盘井之间信息的交换)。
Q:何谓设备虚拟?实现设备虚拟时所依赖的关键技术是什么?
A:通过虚拟技术可将一台独占设备变换成若干台逻辑设备,供若干个用户(进程)同时使用,通常把这种经过虚拟技术处理后的设备称为虚拟设备,其实所依赖的关键数据是SPOOLing技术
Q:在实现后台打印时,SPOOLing系统应为请求I/O的进程提供哪些服务?
A:1.由输出进程在输出并中为之申请一空闲盘块区,并将要打印的数据送入其中;
2.输出进程再为用户进程申请一张空白的用户打印表,并将用户的打印要求填入其中,再将该表挂到请求打印队列上;
3.一旦打印机空闲,输出进程便从请求打印队列的队首取出一张请求打印表,根据表中的要求将要打印的数据,从输出并传送到内存缓冲区,再由打印机进行打印
Q:假脱机系统向用户提供共享打印机的基本思想是什么?
A:对每个用户而言,系统并非即时执行其程序输出数据的真实打印操作,而只是即时将数据输出到缓冲区,这时的数据并未真正被打印,只是将用户感觉系统已为他打印;真正的打印操作,是在打印机空闲且该打印任务在等待队列中已排到队首时进行的;以上过程是对用户屏蔽的,用户是不可见的
第九章 操作系统接口