第三章 - CPU缓存结构和java内存模型
CPU 缓存结构原理
CPU 缓存结构

查看 cpu 缓存
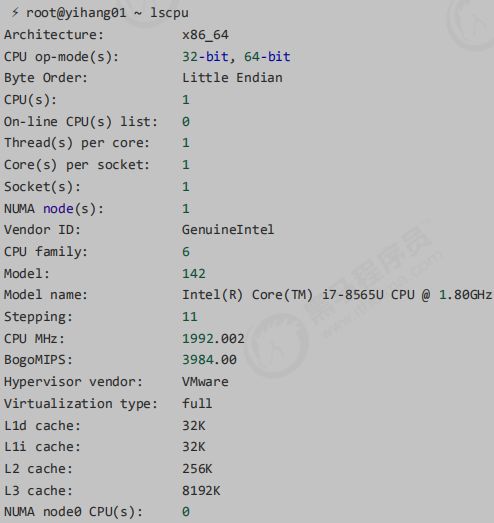
速度比较
查看 cpu 缓存行
![]()
cpu 拿到的内存地址格式是这样的
![]()

CPU 缓存读
根据低位,计算在缓存中的索引
判断是否有效
-
0 去内存读取新数据更新缓存行
-
1 再对比高位组标记是否一致
一致,根据偏移量返回缓存数据
不一致,去内存读取新数据更新缓存行
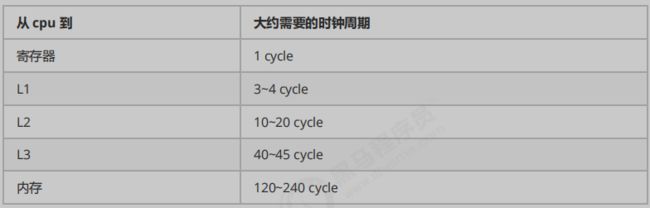
CPU 缓存一致性
MESI 协议
- M(修改,Modified):本地处理器已经修改缓存行,即是脏行,它的内容与内存中的内容不一样,并且此 cache 只有本地一个拷贝(专有);
- E(专有,Exclusive):缓存行内容和内存中的一样,而且其它处理器都没有这行数据;
- S(共享,Shared):缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝;
- I(无效,Invalid):缓存行失效, 不能使用。
| 状态 | 触发本地读取 | 触发本地写入 | 触发远端读取 | 触发远端写入 |
|---|---|---|---|---|
| M状态(修改) | 本地cache:M 触发cache:M 其他cache:I |
本地cache:M 触发cache:M 其他cache:I |
本地cache:M→E→S 触发cache:I→S 其他cache:I→S 同步主内存后修改为E独享,同步触发、其他cache后本地、触发、其他cache修改为S共 |
本地cache:M→E→S→I 触发cache:I→S→E→M 其他cache:I→S→I 同步和读取一样,同步完成后触发cache改为M,本地、其他cache改为I |
| E状态(独享) | 本地cache:E 触发cache:E 其他cache:I |
本地cache:E→M 触发cache:E→M 其他cache:I 本地cache变更为M,其他cache状态应当是I(无效) |
本地cache:E→S 触发cache:I→S 其他cache:I→S 当其他cache要读取该数据时,其他、触发、本地cache都被设置为S(共享) |
本地cache:E→S→I 触发cache:I→S→E→M 其他cache:I→S→I 当触发cache修改本地cache独享数据时时,将本地、触发、其他cache修改为S共享.然后触发cache修改为独享,其他、本地cache修改为I(无效),触发cache再修改为M |
| S状态(共享) | 本地cache:S 触发cache:S 其他cache:S |
本地cache:S→E→M 触发cache:S→E→M 其他cache:S→I 当本地cache修改时,将本地cache修改为E,其他cache修改为I,然后再将本地cache为M状态 |
本地cache:S 触发cache:S 其他cache:S |
本地cache:S→I 触发cache:S→E→M 其他cache:S→I 当触发cache要修改本地共享数据时,触发cache修改为E(独享),本地、其他cache修改为I(无效),触发cache再次修改为M(修改) |
| I状态(无效) | 本地cache:I→S或者I→E 触发cache:I→S或者I →E 其他cache:E、M、I→S、I本地、触发cache将从I无效修改为S共享或者E独享,其他cache将从E、M、I 变为S或者I |
本地cache:I→S→E→M 触发cache:I→S→E→M 其他cache:M、E、S→S→I |
既然是本cache是I,其他cache操作与它无关 | 既然是本cache是I,其他cache操作与它无关 |
下图示意了,当一个cache line的调整的状态的时候,另外一个cache line 需要调整的状态。
| M | E | S | I | |
|---|---|---|---|---|
| M | × | × | × | √ |
| E | × | × | × | √ |
| S | × | × | √ | √ |
| I | √ | √ | √ | √ |
举个栗子来说:
假设cache 1 中有一个变量x = 0的cache line 处于S状态(共享)。
那么其他拥有x变量的cache 2、cache 3等x的cache line调整为S状态(共享)或者调整为 I 状态(无效)。
-
初始:一开始时,缓存行没有加载任何数据,所以它处于 I 状态。
-
本地写(Local Write):如果本地处理器写数据至处于 I 状态的缓存行,则缓存行的状态变成 M。
-
本地读(Local Read):如果本地处理器读取处于 I 状态的缓存行,很明显此缓存没有数据给它。此时分两种情况:
- (1)其它处理器的缓存里也没有此行数据,则从内存加载数据到此缓存行后,再将它设成 E 状态,表示只有我一家有这条数据,其它处理器都没有;
- (2)其它处理器的缓存有此行数据,则将此缓存行的状态设为 S 状态。(备注:如果处于M状态的缓存行,再由本地处理器写入/读出,状态是不会改变的)
-
远程读(Remote Read):假设我们有两个处理器 c1 和 c2,如果 c2 需要读另外一个处理器 c1 的缓存行内容,c1 需要把它缓存行的内容通过内存控制器 (Memory Controller) 发送给 c2,c2 接到后将相应的缓存行状态设为 S。在设置之前,内存也得从总线上得到这份数据并保存。
-
远程写(Remote Write):其实确切地说不是远程写,而是 c2 得到 c1 的数据后,不是为了读,而是为了写。也算是本地写,只是 c1 也拥有这份数据的拷贝,这该怎么办呢?c2 将发出一个 RFO (Request For Owner) 请求,它需要拥有这行数据的权限,其它处理器的相应缓存行设为 I,除了它自已,谁不能动这行数据。这保证了数据的安全,同时处理 RFO 请求以及设置I的过程将给写操作带来很大的性能消耗。
RFO(Read Or Ownership)请求:cpu需要获取缓存行的所有权需要先发送 RFO 请求
什么情况下会发生RFO请求?
-
- 线程的工作从一个处理器移到另一个处理器, 它操作的所有缓存行都需要移到新的处理器上。此后如果再写缓存行,则此缓存行在不同核上有多个拷贝,需要发送 RFO 请求了。
-
- 两个不同的处理器确实都需要操作相同的缓存行
缓存行是什么?
请看:伪共享和缓存行
缓存系统中是以缓存行(cache line)为单位存储的。缓存行通常是 64 字节(译注:本文基于 64 字节,其他长度的如 32 字节等不适本文讨论的重点),并且它有效地引用主内存中的一块地址。一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。所以,如果你访问一个 long 数组,当数组中的一个值被加载到缓存中,它会额外加载另外 7 个,以致你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。而如果你在数据结构中的项在内存中不是彼此相邻的(如链表),你将得不到免费缓存加载所带来的优势,并且在这些数据结构中的每一个项都可能会出现缓存未命中。
我们经常会看到这这样的代码
long p1,p2,p3,p4,p5,p6,p7; // 每个long 8 byte,共7个, 56byte
public volatile long x = 0L; // 56 + 8 = 64
// long p8,p9,p10,p11,p12,p13,p14;
如果存在这样的场景,有多个线程操作不同的成员变量,但是相同的缓存行,这个时候会发生什么?。没错,伪共享(False Sharing)问题就发生了!有张 Disruptor 项目的经典示例图,如下:
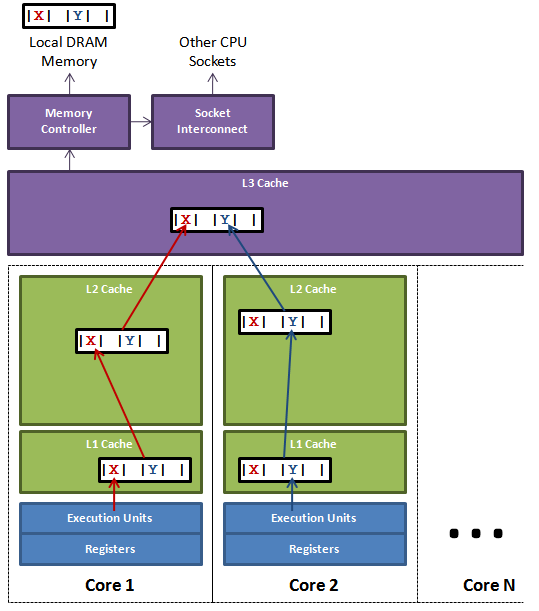
上图中,一个运行在处理器 core1上的线程想要更新变量 X 的值,同时另外一个运行在处理器 core2 上的线程想要更新变量 Y 的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送 RFO 消息,占得此缓存行的拥有权。当 core1 取得了拥有权开始更新 X,则 core2 对应的缓存行需要设为 I 状态。当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据。从前一篇我们知道,读 L3 的数据非常影响性能。更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
内存屏障 — Memory Barrier(Memory Fence)
可见性
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
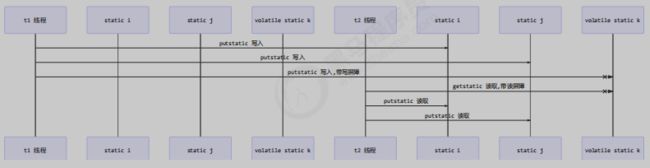
java线程的内存模型
原子性、可见性与有序性
JMM 即 Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、
CPU 指令优化等。
JMM 体现在以下几个方面
- 原子性 - 保证指令不会受到线程上下文切换的影响
- 可见性 - 保证指令不会受 cpu 缓存的影响
- 有序性 - 保证指令不会受 cpu 指令并行优化的影响
(1) 原子性(Atomicity)
由Java内存模型来直接保证的原子性变量操作包括read、load、assign、use、store和write这六个, 我们大致可以认为,基本数据类型的访问、读写都是具备原子性的(例外就是long和double的非原子性 协定,读者只要知道这件事情就可以了,无须太过在意这些几乎不会发生的例外情况)。
如果应用场景需要一个更大范围的原子性保证(经常会遇到),Java内存模型还提供了lock和unlock操作来满足这种需求,尽管虚拟机未把lock和unlock操作直接开放给用户使用,但是却提供了更高层次的字节码指令monitorenter和monitorexit来隐式地使用这两个操作。这两个字节码指令反映到Java代码中就是同步块——synchronized关键字,因此在synchronized块之间的操作也具备原子性。
(2) 可见性(Visibility)
可见性就是指当一个线程修改了共享变量的值时,其他线程能够立即得知这个修改。
除了volatile之外,Java还有两个关键字能实现可见性,它们是synchronized和final
在执行synchronized最后需要unlock掉, 但是unlock之前需要完成store, write操作, 所以是可见的
而final关键字的功能是修饰的字段在构造器中一旦被初始化完成,并且构造器没有把“this”的引用传递出去(this引用逃逸是一件很危险的事情,其他线程有可能通 过这个引用访问到“初始化了一半”的对象),那么在其他线程中就能看见final字段的值
导致共享变量在线程间不可见的原因
- 线程交叉执行
- 重排序结合线程交叉执行
- 共享变量更新后的值没有在工作内存与主存间及时更新
JMM关于synchronized的两条规定
- 线程解锁前,必须把共享变量的最新值刷新到主内存
- 线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值(注意加锁与解锁是同- -把锁)
主存与工作内存
Java内存模型规定了所有的变量都存储在主内存(Main Memory)中(此处的主内存与介绍物理 硬件时提到的主内存名字一样,两者也可以类比,但物理上它仅是虚拟机内存的一部分)。每条线程 还有自己的工作内存(Working Memory,可与前面讲的处理器高速缓存类比),线程的工作内存中保 存了被该线程使用的变量的主内存副本,线程对变量的所有操作(读取、赋值等)都必须在工作内 存中进行,而不能直接读写主内存中的数据。不同的线程之间也无法直接访问对方工作内存中的变 量,线程间变量值的传递均需要通过主内存来完成,线程、主内存、工作内存三者的交互关系如图

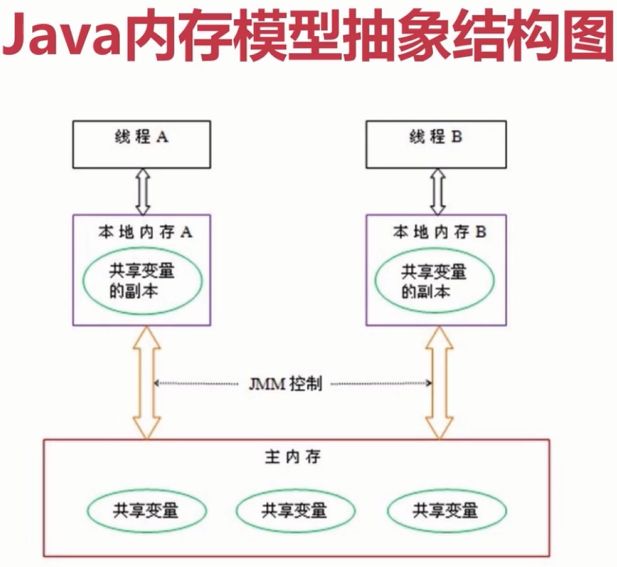
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从 工作内存同步回主内存这一类的实现细节,Java内存模型中定义了以下8种操作来完成。Java虚拟机实 现时必须保证下面提及的每一种操作都是原子的、不可再分的
线程持有主存变量的副本, 在没有特殊处理的前提下线程的所有操作都是针对副本, 而后再由副本同步到主存中, 下面就是java主存和副本的操作过程图示:

下图是对每个操作的详细说明:
- lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
- unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量 才可以被其他线程锁定。
- read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以 便随后的load动作使用。
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的 变量副本中。
- use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚 拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收的值赋给工作内存的变量, 每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随 后的write操作使用。
- write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的 变量中。
如果要把一个变量从主内存拷贝到工作内存,那就要按顺序执行read和load操作,如果要把变量从 工作内存同步回主内存,就要按顺序执行store和write操作。注意,Java内存模型只要求上述两个操作 必须按顺序执行,但不要求是连续执行。也就是说read与load之间、store与write之间是可插入其他指令 的,如对主内存中的变量a、b进行访问时,一种可能出现的顺序是read a、read b、load b、load a。除此 之外,Java内存模型还规定了在执行上述8种基本操作时必须满足如下规则:
- 不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内 存不接受,或者工 作内存发起回写了但主内存不接受的情况出现。
- 不允许一个线程丢弃它最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回 主内存。
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存
中。 - 一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load或 assign)的变量,换句话说就是对一个变量实施use、store操作之前,必须先执行assign和load操作。
- 一个变量在同一个时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执 行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。
- 如果对一个变量执行lock操作,那将会清空工作内存中此变量的值,在执行引擎使用这个变量 前,需要重新执行load或assign操作以初始化变量的值。
- 如果一个变量事先没有被lock操作锁定,那就不允许对它执行unlock操作,也不允许去unlock一个 被其他线程锁定的变量。
- 对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store、write操作)。
案例一: 利用 i++来分析内存间交互操作的详细过程
主体来说就是这么一个步骤:
// 多线程操作 a++;
① 将主存中的变量a锁定为一条线程独占状态 lock — 不允许新变量直接在工作内存中产生, 只能在主存中产生读取和加载到工作内存
② 将主存读取的变量a读取出来 read
③将读取出来的变量加载到工作内存中 load — ②③不允许独自执行, 必须按照顺序执行, 但不保证连续执行
④ 线程操作变量a自增 use; load操作可能同时给多个线程进行
⑤ 将线程执行完毕后的结果赋值给工作内存 assign — 不允许线程的丢弃assign操作, 即工作变量变化了, 必须同步到主存, 同时如果没有assign操作也不允许工作内存私自同步到主存
⑥ 将工作内存中的变量存储到主存空间 store
⑦ 将store的变量写入到主存中 write — ⑥⑦步骤不允许独自运行, 必须按照顺序执行, 但不保证连续执行
⑧ 解除独占模式, 释放变量, 之后该变量才可以被其他线程锁定 unlock
注意: 上面加粗的两句话, 这就是为啥要使用volatile修饰变量的原因了
案例二: 退不出的循环
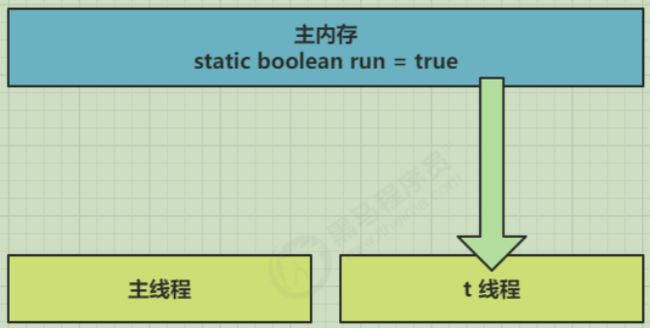
先来看一个现象,main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
class Zhazha {
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
// ....
}
});
t.start();
sleep(1);
run = false; // 线程t不会如预想的停下来
}
}
为什么呢?分析一下:
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存。
-
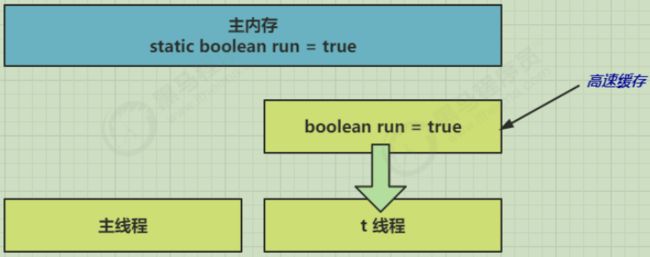
因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
-
1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量
的值,结果永远是旧值
那如何解决呢???
volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
volatile关键字
volatile处理可见性问题
第一项是保证此变量对所有线程的可见性,这里的“可见性”是指当一条线程修改了这个变量的值,新值对于其他线程来说是可以立即得知的, 对于普通变量来说是需要重新读取变量才能够获取到最新线程改变的变量
注意: volatile变量依然有工作内存的拷贝,但是由于它特殊的操作顺序性规定,所以看起来如同直接在主内存中读写访问一般
如下图是下了线程断点的例子:
当前线程是
![]()
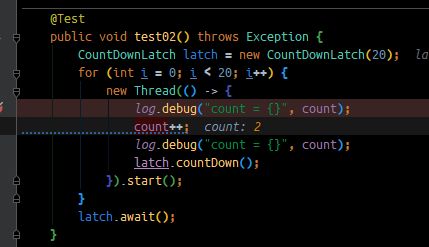
count 的大小是 2, 准备自增 count, 突然它失去了时间片
变成了线程 12, 直接执行到 count++ 的下面一行, 自增了值, 变成了 3
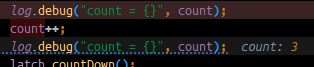
然后我们切换到线程 10 再看看这个 count 的值是多少
[Thread-10] DEBUG com.xxx.ExerciseTransfer - count = 3
发现打印出来的是 3, 说明了, 线程12的修改在其他线程是能够立即被反应出来的
这个就是volatile的第一个作用
而普通变量是不行的, 比如:
线程A修改一个普通变量的值,然后向主内存进行回写,另外一条线程B在线程A回写完成了之后再对 主内存进行读取操作,新变量值才会对线程B可见。
它需要其他线程重新读取时才会获取到新的值
Java里面的运算操作符并非原子操作, 这导致volatile变量的运算在并发下一样是不安全
如下分析i++和i–线程不安全问题
我们知道 i++ 或者 i-- 是线程不安全的, 但是为什么呢???
先上代码:
@Slf4j
public class Demo01 {
private int counter = 0;
@Test
public void test() throws Exception {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
this.counter++;
}
log.debug("{} = {}", Thread.currentThread().getName(), counter);
}, "t1");
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
this.counter--;
}
log.debug("{} = {}", Thread.currentThread().getName(), counter);
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
log.debug("res counter = {}", counter);
}
}
我们发现打印的结果并不是绝对正确的
注意: 上面这段代码确实是线程不安全的, 但是由于线程比较少, 所以可能需要多试几次才会出现问题, 当然你也可以把创建线程的代码放在for循环下面, 让for循环创建500+个线程自增, 500+线程自减, 让线程多做几次上下文切换, 就会表现出问题了(工作环境不要抱有侥幸心理, 不要因为没有看到问题而不去理会)
首先我们了解 counter++ 和 counter-- 在jvm字节码上是怎么运行的?
counter++
getfield #获取字段
iconst_1 #给定一个为1的常量
iadd # 相加
putfield # 赋值
counter–
getfield #获取字段
iconst_1 #给定一个为1的常量
isub # 相减
putfield # 赋值
实事求是地说,使用字节码来分析并发问题仍然是不严谨的,因为即使编译出来只有一条字节码指令,也并不意味执行这条指令就是一个原子操作。一条字节码指令在解释执行时,解释器要运 行许多行代码才能实现它的语义。如果是编译执行,一条字节码指令也可能转化成若干条本地机器码 指令。此处使用-XX:+PrintAssembly参数输出反汇编来分析才会更加严谨一些,但是考虑到阅读的方便性,并且字节码已经能很好地说明问题,所以此处使用字节码来解释。
下图就显示着这个过程存在的问题
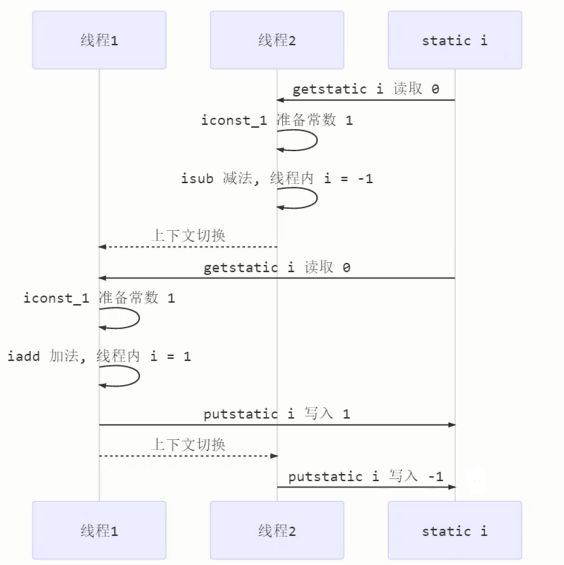
volatile处理指令重排序优化的问题
volatile变量的第二个语义是禁止指令重排序优化,普通的变量仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中的执行顺序一致
volatile的使用场景
(1) 这个修饰符比较合适在修饰单个变量单纯的读取时的使用方法上, 举个例子比较简单

class Zhazha {
public void func() {
Map configOptions;
char[] configText;
// 此变量必须定义为volatile
volatile boolean initialized = false;
// 假设以下代码在线程A中执行
// 模拟读取配置信息,当读取完成后
// 将initialized设置为true,通知其他线程配置可用
configOptions = new HashMap();
configText = readConfigFile(fileName);
processConfigOptions(configText, configOptions);
initialized = true;
// 假设以下代码在线程B中执行
// 等待initialized为true,代表线程A已经把配置信息初始化完成
while (!initialized) {
sleep();
}
// 使用线程A中初始化好的配置信息
doSomethingWithConfig();
}
}
(2) volatile 还能使用在一个线程写, 其他线程读的情况下
(3) 高并发下 long 或者 double 类型变量需要添加 volatile 以保证线程安全, 它是8byte, 在jvm中需要分成 4 + 4 这样子计算, 所以不是线程安全的
总结: 记住这句话, volatile两个作用: 保持共享变量可见性和禁止指令重排序, synchronized关键字只能保证那一块代码只有一个线程运行, 不能禁止指令重排, volatile只能保证可见性不能保证原子性
volatile底层原理
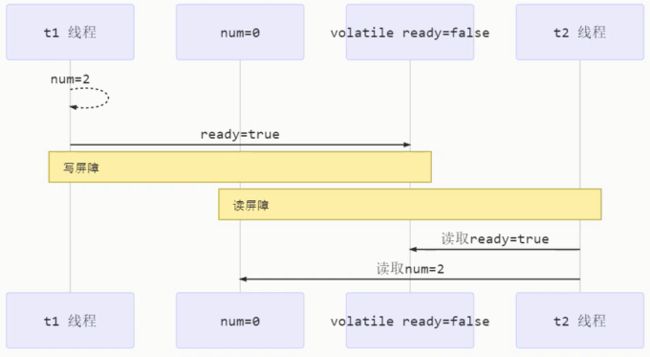
如何保证可见性
volatile修饰了ready
写屏障(sfence) 保证在该屏障之前的,对共享变量的改动,都同步到主存当中
class Zhazha {
public void actor2(I_Result r) {
num = 2;
ready = true;
// 写屏障, 在这之前的代码所有变量都会被同步到主存
}
}
而读屏障(fence) 保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
class Zhazha {
public void actor1(I_Result r) {
// 读屏障
// 在读之后的变量都会被同步到主存
if (ready) {
r.r1 = num + num;
}
else {
r.r1 = 1;
}
}
}
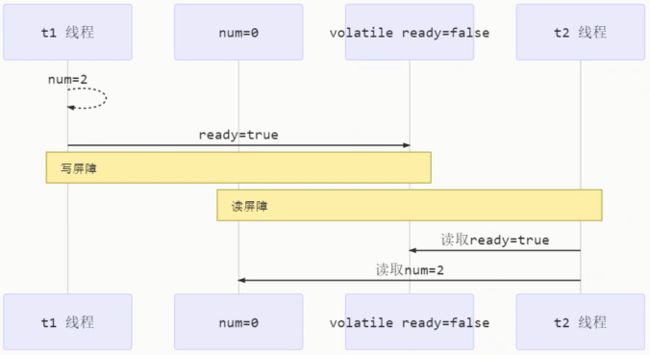
如果保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
class Zhazha {
public void actor2(I_Result r) {
num = 2;
ready = true; // 写屏障, 在这之前的代码不会被jit重排到这行之后
}
}
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
class Zhazha {
public void actor1(I_Result r) {
if (ready) { // 读屏障, 在这之后的代码都不会被jit重排到这行之前
r.r1 = num + num;
}
else {
r.r1 = 1;
}
}
}
volatile内存屏障实现
volatile重排序规则表

举例来说,第三行最后一个单元格的意思是:在程序中,当第一个操作为普通变量的读或
写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。
从表3-5我们可以看出。
当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来
禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总
数几乎不可能。为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略。
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台,任意的程序中都能得到正确的volatile内存语义。
下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图,如下图所示
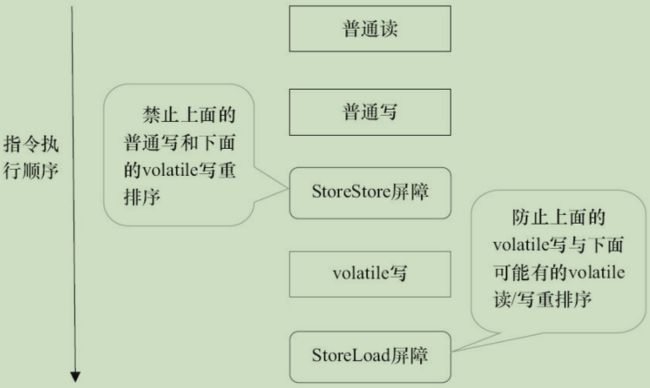
上图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。
这里比较有意思的是,volatile写后面的StoreLoad屏障。此屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确实现volatile的内存语义,JMM在采取了保守策略:在每个volatile写的后面,或者在每个volatile读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM最终选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时,选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图,如下图所示

上图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。下面通过具体的示例代码进行说明。
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; // 第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; // 普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; // 第二个 volatile写
}
// 其他方法
}
针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化。
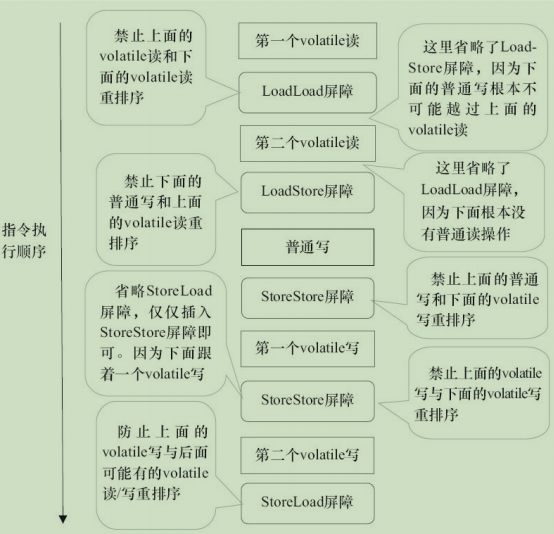
注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器通常会在这里插入一个StoreLoad屏障
- 线程安全问题遇到sync和volatile修改时, 在sync代码块或者volatile变量修改前面的普通变量会默认从主存拉取变量到普通变量中
public class JitTest {
public static boolean init = false;
public static volatile int i = 0;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
// // storestore ===> 保证了前面的load(读)
// i++;
// // storeload ===> 后面好像都不保证了...
// // loadload ===> 保证了前面的读
// int n = i;
// // loadstore ===> 后面好像都不保证普通读取了...
// System.out.println(1); // 同样的效果, 后面的init不变还是存在线程问题
while (!init) {
// // storestore ===> 保证了前面的load(读)
// i++;
// // storeload ===> 后面好像都不保证了...
// System.out.println(1);
// // loadload ===> 前面的共享变量load(读)
// int b = i;
// // loadstore ===> 后面好像都不保证了????
}
}).start();
Thread.sleep(1000);
new Thread(() -> {
init = true;
}).start();
}
}
总结:
说了这么多就简单点解释下,LoadLoad就是 Load1(读表达式) + 内存屏障 + Load2(读表达式) 这里的Load1和Load2不能重排序
Lock指令
volatile底层使用了 Lock指令实现,而lock指令有三个功能:
- 保证原子操作
- 保证工作内存刷新到主存
- 设置其他cpu上的这个变量无效
cpu提供了三种内存屏障系统原语:
sfencemfencelfence
但实际上volatile底层它压根不用, 原因是不是大多数cpu都支持的上面的系统指令
其底层实现仍然使用的 lock, 原因也很简单, 大多数cpu都有
AMD64
lock: addl $0, 0(%%rsp)
other
lock: addl $0, 0(%%esp)
(3) 有序性(Ordering)
有序性: 线程的执行始终跟着代码的顺序运行
Java程序中天然的有序性可以总结为一句话:如果在本线程内观察,所有的操作都是有序的;如果在一个线程中观察另一个线程, 所有的操作都是无序的。前半句是指“线程内似表现为串行的语义”(Within-Thread As-If-Serial Semantics),后半句是指“指令重排序”现象和“工作内存与主内存同步延迟”现象
线程内似表现为串行的语义: 就是单线程看的话, 我们的指令表现的是一条一条的串行执行完毕的
工作内存与主内存同步延迟: 工作内存不能够即时的和主内存进行相互的更新
举个例子:
class Zhazha {
static int i;
static int j;
// 在某个线程内执行如下赋值操作
// i = ...;
// j = ...;
}
可以看到,至于是先执行 i 还是 先执行 j ,对最终的结果不会产生影响。所以,上面代码真正执行时,既可以是
i = ...;
j = ...;
也可以是
j = ...;
i = ...;
这种特性称之为『指令重排』,多线程下『指令重排』会影响正确性。为什么要有重排指令这项优化呢?从 CPU 执行指令的原理来理解一下吧
指令级并行原理
鱼罐头的故事
加工一条鱼需要 50 分钟,只能一条鱼、一条鱼顺序加工…
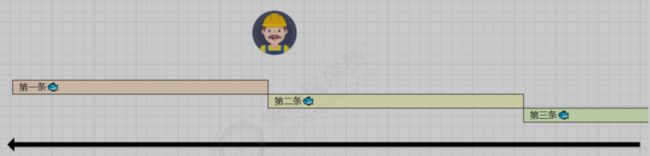
可以将每个鱼罐头的加工流程细分为 5 个步骤:
-
去鳞清洗 10分钟
-
蒸煮沥水 10分钟
-
加注汤料 10分钟
-
杀菌出锅 10分钟
-
真空封罐 10分钟

即使只有一个工人,最理想的情况是:他能够在 10 分钟内同时做好这 5 件事,因为对第一条鱼的真空装罐,不会影响对第二条鱼的杀菌出锅…
指令重排序优化
事实上,现代处理器会设计为一个时钟周期完成一条执行时间最长的 CPU 指令。为什么这么做呢?可以想到指令还可以再划分成一个个更小的阶段,例如,每条指令都可以分为: 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 这 5 个阶段

术语参考:
- instruction fetch (IF)
- instruction decode (ID)
- execute (EX)
- memory access (MEM)
- register write back (WB)
在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序和组合来实现指令级并行
支持流水线的处理器
现代 CPU 支持多级指令流水线,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 的处理器,就可以称之为五级指令流水线。这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一条执行时间最长的复杂指令),IPC = 1,本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了指令地吞吐率
提示:
奔腾四(Pentium 4)支持高达 35 级流水线,但由于功耗太高被废弃

诡异的结果
创建maven项目
@JCStressTest
@Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "!!!!")
@State
public class ConcurrencyTest {
int num = 0;
boolean ready = false;
@Actor
public void actor1(I_Result r) {
if (ready) {
r.r1 = num + num;
}
else {
r.r1 = 1;
}
}
@Actor
public void actor2(I_Result r) {
num = 2;
ready = true;
}
}
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.zhazhagroupId>
<artifactId>orderingartifactId>
<version>1.0-SNAPSHOTversion>
<packaging>jarpackaging>
<prerequisites>
<maven>3.0maven>
prerequisites>
<dependencies>
<dependency>
<groupId>org.openjdk.jcstressgroupId>
<artifactId>jcstress-coreartifactId>
<version>${jcstress.version}version>
dependency>
dependencies>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<jcstress.version>0.5jcstress.version>
<javac.target>1.8javac.target>
<uberjar.name>jcstressuberjar.name>
properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.1version>
<configuration>
<compilerVersion>${javac.target}compilerVersion>
<source>${javac.target}source>
<target>${javac.target}target>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.2version>
<executions>
<execution>
<id>mainid>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<finalName>${uberjar.name}finalName>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.openjdk.jcstress.MainmainClass>
transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/TestListresource>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
经过控制态测试
java -jar jcstress -v
*** INTERESTING tests
Some interesting behaviors observed. This is for the plain curiosity.
4 matching test results.
[OK] com.zhazha.ConcurrencyTest
(JVM args: [-XX:+UnlockDiagnosticVMOptions, -XX:+StressLCM, -XX:+StressGCM])
Observed state Occurrences Expectation Interpretation
0 276 ACCEPTABLE_INTERESTING !!!!
1 59,999,454 ACCEPTABLE ok
4 28,530,221 ACCEPTABLE ok
[OK] com.zhazha.ConcurrencyTest
(JVM args: [-XX:-TieredCompilation, -XX:+UnlockDiagnosticVMOptions, -XX:+StressLCM, -XX:+StressGCM])
Observed state Occurrences Expectation Interpretation
0 104 ACCEPTABLE_INTERESTING !!!!
1 67,885,202 ACCEPTABLE ok
4 29,954,445 ACCEPTABLE ok
[OK] com.zhazha.ConcurrencyTest
(JVM args: [-XX:-TieredCompilation])
Observed state Occurrences Expectation Interpretation
0 3,889 ACCEPTABLE_INTERESTING !!!!
1 67,195,281 ACCEPTABLE ok
4 32,530,071 ACCEPTABLE ok
[OK] com.zhazha.ConcurrencyTest
(JVM args: [])
Observed state Occurrences Expectation Interpretation
0 2,099 ACCEPTABLE_INTERESTING !!!!
1 85,847,970 ACCEPTABLE ok
4 26,918,422 ACCEPTABLE ok
*** All remaining tests
Tests that do not fall into any of the previous categories.
2 matching test results.
[OK] com.zhazha.ConcurrencyTest
(JVM args: [-XX:TieredStopAtLevel=1])
Observed state Occurrences Expectation Interpretation
0 0 ACCEPTABLE_INTERESTING !!!!
1 49,062,963 ACCEPTABLE ok
4 22,903,528 ACCEPTABLE ok
[OK] com.zhazha.ConcurrencyTest
(JVM args: [-Xint])
Observed state Occurrences Expectation Interpretation
0 0 ACCEPTABLE_INTERESTING !!!!
1 2,089,147 ACCEPTABLE ok
4 1,663,694 ACCEPTABLE ok
经过测试发现上面确实存在指令重排序
0 3,889 ACCEPTABLE_INTERESTING !!!
0 2,099 ACCEPTABLE_INTERESTING !!!
但是加上了 volatile 之后这种情况消失了
class Zhazha {
volatile boolean ready = false;
}
double-checked-locking双重检测原则
class Zhazha {
private volatile static SingletonLazy instance = null;
public static SingletonLazy getInstance() {
if (null == instance) {
synchronized (SingletonLazy.class) {
if (null == instance) {
instance = new SingletonLazy();
}
}
}
return instance;
}
}
0: getstatic #2 // Field INSTANCE:Lcom/zhazha/n5/Singleton;
3: ifnonnull 37
6: ldc #3 // class com/zhazha/n5/Singleton
8: dup
9: astore_0
10: monitorenter
11: getstatic #2 // Field INSTANCE:Lcom/zhazha/n5/Singleton;
14: ifnonnull 27
17: new #3 // class com/zhazha/n5/Singleton
20: dup
21: invokespecial #4 // Method "":()V
24: putstatic #2 // Field INSTANCE:Lcom/zhazha/n5/Singleton;
27: aload_0
28: monitorexit
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field INSTANCE:Lcom/zhazha/n5/Singleton;
40: areturn
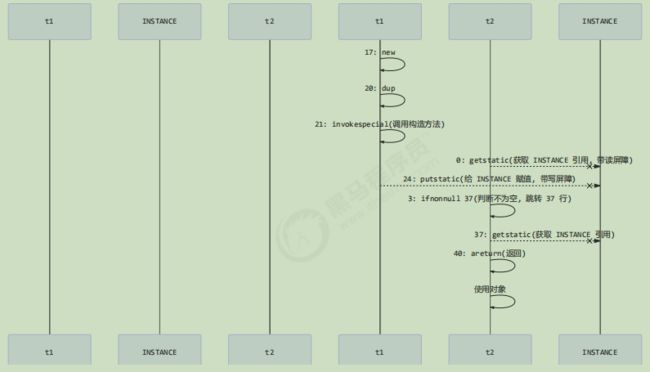
其中
- 17 表示创建对象,将对象引用入栈 // new Singleton
- 20 表示复制一份对象引用 // 引用地址
- 21 表示利用一个对象引用,调用构造方法
- 24 表示利用一个对象引用,赋值给 static INSTANCE
也许 jvm 会优化为:先执行 24,再执行 21。如果两个线程 t1,t2 按如下时间序列执行:

关键在于 0: getstatic 这行代码在 monitor 控制之外,它就像之前举例中不守规则的人,可以越过 monitor 读取
INSTANCE 变量的值
这时 t1 还未完全将构造方法执行完毕,如果在构造方法中要执行很多初始化操作,那么 t2 拿到的是将是一个未初
始化完毕的单例
对 INSTANCE 使用 volatile 修饰即可,可以禁用指令重排,但要注意在 JDK 5 以上的版本的 volatile 才会真正有效
加上volatile之后的指令集虽然还是看不出问题, 但是在实际作用中还是体现出了效果
为什么synchronized能够保证有序性却无法保证指令重排序的顺序?
Java语言提供了volatile和synchronized两个关键字来保证线程之间操作的有序性,volatile关键字本身就包含了禁止指令重排序的语义,而synchronized则是由“一个变量在同一个时刻只允许一条线程对其进行lock操作”这条规则获得的,这个规则决定了持有同一个锁的两个同步块只能串行地进入
虽然说synchronized是有序的, 但不是真正的有序, 它只不过是保证了在临界区只有一个线程运行, 所以即使发生了指令重排, 对于这个块来说是不影响的, 但是不在这个块的呢???
借助双重验证方式的单例详解区别
class Zhazha {
// 如果这个字段没有volatile关键字则会出现指令重排序
private static volatile SingletonLazy instance = null;
public static SingletonLazy getInstance() {
if (null == instance) { // ①
synchronized (SingletonLazy.class) { // 线程2 阻塞
if (null == instance) {
instance = new SingletonLazy(); // 线程1 运行中 ...
}
}
}
return instance;
}
}
如果instance不添加volatile则会出现这样一个过程:
- jvm分配内存
- 初始化内存对象(引用内存, 对象的内存, 堆)
- 栈变量指向引用对象内存
但是这个过程如果重排序成这样对于一个线程来说结果也是一样的
- jvm分配内存
- 栈变量指向引用对象内存
- 初始化内存对象(引用内存, 对象的内存, 堆)
满足所谓的 as-if-serial(说白了就是不管怎么重排, 只要不影响这个线程运行的结果就行)
那么上面代码线程2阻塞的位置, 就会出现不同的效果了,
如果是第一种方式, 未经过指令重排序, 则结果是正常的, 返回有非null的instance,
但是如果是第二种方式, 先初始化了栈变量后, 线程2发现这个栈变量发生了变化, 直接返回这个栈变量, 但是此时栈变量对应的对象堆内存还未初始化, 此时将会发生错误(这种情况发生的比较少, 我在实测中没发现问题, 但是synchronized是不能处理指令重排序的, 可能jvm做了优化吧)
当然要让sync保证指令重排的方法其实也有, 那就是让共享变量全部都在代码块中
总结下来就是: sync可以保证原子性, 可见性和有序性
先行发生原则(happens-before)
是什么?
happens-before 规定了对共享变量的写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见
详细内容
(1) 线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见
class Zhazha {
static int x;
static Object m = new Object();
public void func() {
new Thread(() -> {
synchronized (m) {
x = 10;
}
},"t1").start();
new Thread(() -> {
synchronized (m) {
System.out.println(x);
}
},"t2").start();
}
}
(2) 线程对 volatile 变量的写,对接下来其它线程对该变量的读可见
class Zhazha {
volatile static int x;
public void func() {
new Thread(() -> {
x = 10;
}, "t1").start();
new Thread(() -> {
System.out.println(x);
}, "t2").start();
}
}
(3) 线程 start 前对变量的写,对该线程开始后对该变量的读可见
class Zhazha {
static int x = 10;
public void func() {
new Thread(() -> {
System.out.println(x);
},"t2").start();
}
}
(4) 线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或 t1.join()等待它结束)
class Zhazha {
static int x;
public void func() {
Thread t1 = new Thread(() -> {
x = 10;
}, "t1");
t1.start();
t1.join();
System.out.println(x);
}
}
(5) 线程打断前的写, 对线程打断后的其他线程可见
class Zhazha {
static int x;
public static void main(String[]args){
Thread t2 = new Thread(() -> {
while (true) {
if (Thread.currentThread().isInterrupted()) {
System.out.println(x);
break;
}
}
}, "t2");
t2.start();
new Thread(() -> {
sleep(1);
x = 10;
t2.interrupt();
}, "t1").start();
while (!t2.isInterrupted()) {
Thread.yield();
}
System.out.println(x);
}
}
(6) 对变量默认值(0,false,null)的写,对其它线程对该变量的读可见
(7) 具有传递性,线程1对x的修改在线程2中x是可见的, 并且这种可见也包括y变量
class Zhazha {
volatile static int x;
static int y;
public void func() {
new Thread(() -> {
y = 10;
x = 20; // x 写前面的所有变量都是有序的
}, "t1").start();
new Thread(() -> {
// x=20 对 t2 可见, 同时 y=10 也对 t2 可见
System.out.println(x);
}, "t2").start();
}
}
对加锁范围的理解
public class TestVolatile {
volatile boolean initialized = false;
void init() {
if (initialized) {
return;
}
doInit();
initialized = true;
}
private void doInit() {
}
}
确认 initialized 是共享变量, 并且 doInit 方法只能被执行一次
我们围绕着共享变量来进行加锁
首先发现共享变量存在读写操作所以我们围绕着读写加上锁, 但是要上this锁还是Class锁, 根据出题条件判断, 这里我们上this锁, 保证一个 TestVolatile 对象只能调用一次 doInit 方法
class Zhazha {
volatile boolean initialized = false;
void init() {
synchronized (this) {
if (initialized) {
return;
}
doInit();
initialized = true;
}
}
}
这里发现 volatile 其实可加可不加
单例模式
单例模式有很多实现方法,饿汉、懒汉、静态内部类、枚举类,试分析每种实现下获取单例对象(即调用 getInstance)时的线程安全,并思考注释中的问题
实现1:
// 问题1:为什么加 final
// 问题2:如果实现了序列化接口, 还要做什么来防止反序列化破坏单例
public final class Singleton implements Serializable {
// 问题3:为什么设置为私有? 是否能防止反射创建新的实例?
private Singleton() {
}
// 问题4:这样初始化是否能保证单例对象创建时的线程安全?
private static final Singleton INSTANCE = new Singleton();
// 问题5:为什么提供静态方法而不是直接将 INSTANCE 设置为 public, 说出你知道的理由
public static Singleton getInstance() {
return INSTANCE;
}
public Object readResolve() {
return INSTANCE;
}
}
实现2:(推荐)
// 问题1:枚举单例是如何限制实例个数的
// 问题2:枚举单例在创建时是否有并发问题
// 问题3:枚举单例能否被反射破坏单例
// 问题4:枚举单例能否被反序列化破坏单例
// 问题5:枚举单例属于懒汉式还是饿汉式
// 问题6:枚举单例如果希望加入一些单例创建时的初始化逻辑该如何做
enum Singleton {
INSTANCE;
}
实现3:
public final class Singleton {
private Singleton() { }
private static Singleton INSTANCE = null;
// 分析这里的线程安全, 并说明有什么缺点
public static synchronized Singleton getInstance() {
if( INSTANCE != null ){
return INSTANCE;
}
INSTANCE = new Singleton();
return INSTANCE;
}
}
实现4:DCL
public final class Singleton {
private Singleton() { }
// 问题1:解释为什么要加 volatile ?
private static volatile Singleton INSTANCE = null;
// 问题2:对比实现3, 说出这样做的意义
public static Singleton getInstance() {
if (INSTANCE != null) {
return INSTANCE;
}
synchronized (Singleton.class) {
// 问题3:为什么还要在这里加为空判断, 之前不是判断过了吗
if (INSTANCE != null) { // t2
return INSTANCE;
}
INSTANCE = new Singleton();
return INSTANCE;
}
}
}
实现5: (推荐)
public final class Singleton {
private Singleton() { }
// 问题1:属于懒汉式还是饿汉式
private static class LazyHolder {
static final Singleton INSTANCE = new Singleton();
}
// 问题2:在创建时是否有并发问题
public static Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
final字段在高并发下存在的问题及解决方案
首先存在问题的类结构是这样的
/**
* 写final域的重排序规则
* 读final域的重排序规则
**/
public class FinalExample {
int i; // 普通变量
final int j; // final变量
static FinalExample obj;
public FinalExample() { // 构造函数
i = 1; // 写普通域
j = 2; // 写final域
// StoreStore
}
public static void writer() { // 写线程A执行
// 赋值构造的引用赋值给引用字段obj
obj = new FinalExample(); // 这句话不是线程安全的(如果构造函数没有StoreStore内存屏障的话),它可以选择先不初始化FinalExample对象中的字段。先创建内存空间,把内存空间的地址赋值给obj,此时这段内存空间中的字段未被初始化
}
public static void reader() { // 读线程B执行
FinalExample object = obj; // 读对象引用 这里非常可能被重排序,对象的引用和初始化final字段只见重排序
int a = object.i; // 读普通域 有可能未被初始化(如果构造函数没有StoreStore内存屏障的话)
int b = object.j; // 读final域 有可能未被初始化(如果构造函数没有StoreStore内存屏障的话)
}
}
一般都存在一个字段拥有自己的引用的类中需要注意:
这种情况下我们需要注意初始化final字段和初始化obj对象的顺序,防止在读取到obj时发现final对象还未被初始化完毕
jvm的处理方案是在初次读取final字段时需要添加上LoadLoad内存屏障,在初次写final时,需要在构造函数return之前添加StoreStore内存屏障
- 在构造函数内对一个
final域(字段)的写入,与随后把这个被构造对象的引用赋值给一个引用
变量,这两个操作之间不能重排序。 - 初次读一个包含
final域(字段)的对象的引用,与随后初次读这个final域(字段),这两个操作之间不能
重排序。
总而言之,我在获取
obj自引用时,final需要写入完毕。
我们还需要关注final字段需要在构造函数内部初始化完毕,而不能逸出在构造函数之外,所以还要保证this不逃逸出去。