抛开八股——实际业务下如何设计缓存与数据库一致性解决方案
前言
对于缓存与数据库一致性的八股文也是老生常谈了,但是所谓没有最好的方案,只有最合适的方案,如果我们一味的去硬啃八股文,很容易就丧失了对于业务的基本分析能力,更别说针对业务来设计出合理合适的解决方案,本文总结了几种企业中常用的解决方案以及对标其业务场景来带大家走一遍内外存一致性解决方案的挑选细节,并对这些方案引出更深一层次的评析,希望能对大家产生一点帮助~
业务背景
为了满足日常买票需求,我们可以采取一种缓存的优化方案。我们将这些余量信息存储在缓存中,以便用户可以快速查询。
然而,在用户创建订单并完成支付时,我们需要同时从数据库和缓存中扣减相应的余票数额。这种设计不仅提高了查询效率,也保证了数据的一致性,确保订单操作的准确性。
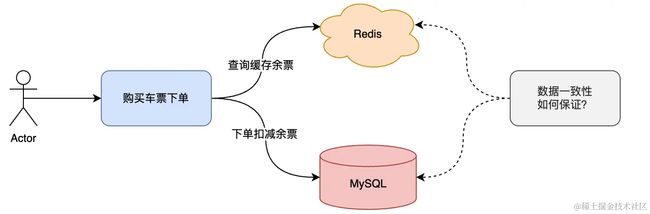
在这个业务场景中的缓存与数据库一致性如何保证?结合大家常在用的以及网上一些方案,给出一些我的思考以及公司中实际的解决方案。
注意,下文中都是以多请求并发场景下的思考。
技术方案
方案一:缓存双删
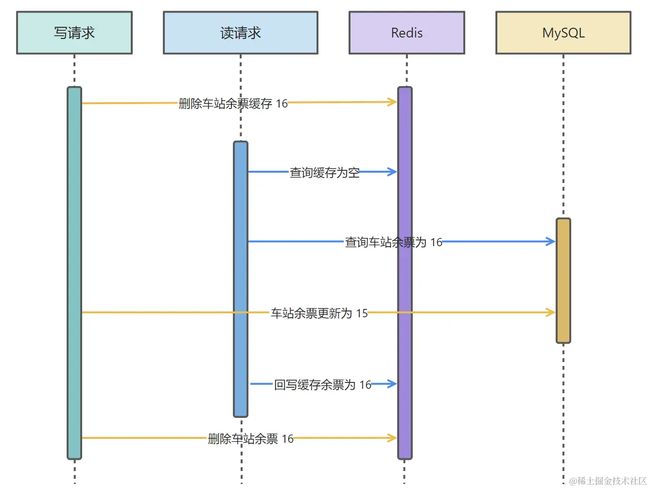
如果说上图的读请求回写缓存在写请求第二次删除缓存之前,那这种技术方案是比较好的,而且也不用引入过多复杂的中间件。
问题就在于,第二次删除缓存,不一定在读请求回写缓存之后。所以我们需要保证第二次删除要在请求回写缓存之后。
假设读请求回写缓存大概需要 300ms,那我们是否可以在写请求第二次删除缓存前进行一个延迟操作,比如睡眠 500ms 后再删除?这样就可以规避读请求回写缓存在第二次删除之后了。
这种方案理论上是可以的,不过把这个睡眠操作使用延迟队列或者引入三方消息队列去做。
最新技术架构流程如下所示:
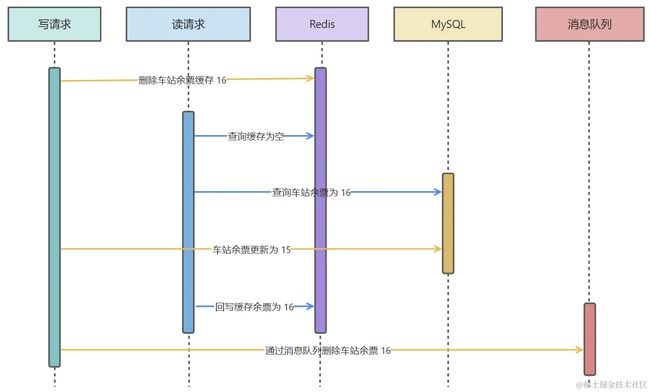
如果消息队列更新缓存失败了呢?其实这一点还好,凭借消息队列客户端消费的重试规则,如果更新失败次数都达到客户端重试阈值还是不行,那一定是数据或者缓存中间件有问题。
当然,如果重试次数多了,也必然会面临缓存与数据库不一致的时间变长了,这个是需要清楚的。
通过该技术方案,可以很好达到缓存与数据库最终一致性。
方案二:先写数据库再删除缓存
读请求第一次查询时,会查询到一个错误的数据,因为写请求还没有更新到缓存,写请求写入 MySQL 成功后会删除缓存中的历史数据。后续读请求查询缓存没有值就会再请求数据库 MySQL 进行重新加载,并将正确的值放到缓存中。
也就是说这种模型会存在一个很小周期的缓存与数据库不一致的情况,不过对于绝大多数的情况来说,是可以容忍的。除去一些电商库存、列车余票等对数据比较敏感的情况,比较适合绝大多数业务场景。
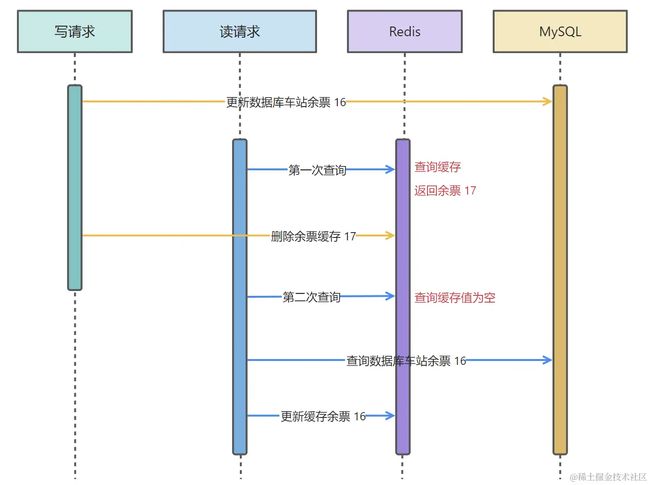
当然,这种模型也不是完全没问题,如果说恰巧读缓存失效了,就会出现这种情况。
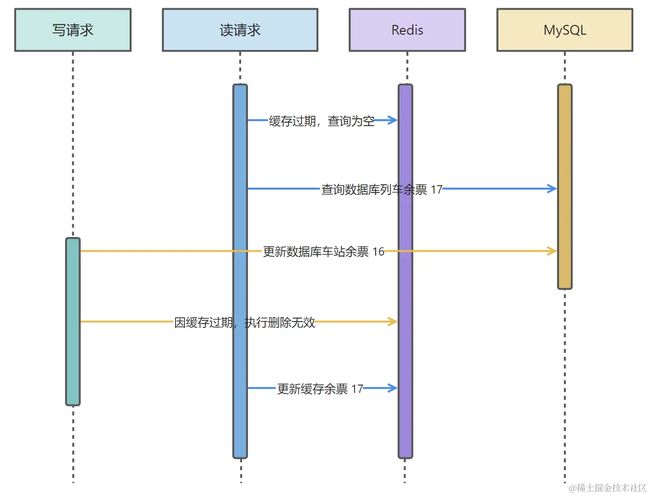
当缓存过期(可能是缓存正常过期也可能是 Redis 内存满了触发清理策略)条件满足,同时读请求的回写缓存 Redis 的执行周期在数据库删除之前,那么就有可能触发缓存数据库不一致问题。
上面说的两种情况,缺一不可,不过能同时满足这两种情况概率极低,低到可以忽略这种情况。
方案三:BinLog 异步更新缓存
这种方案是我认为最终一致性最为值得尝试以及使用的。但是有一句话说的是没有绝对合适的技术,只有相对适合的技术,这种方案实现是也存在一些技术问题,稍后会给大家详细说明。
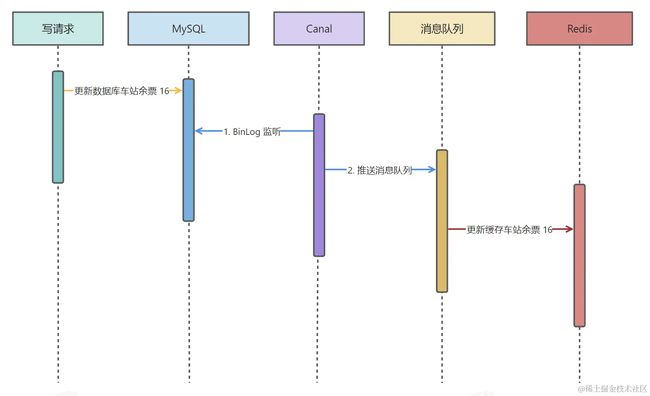
如果是扣减库存的方案,比如说你将列车余票扣减为 16,但是同时又有一个请求将列车余票扣减为 15,这个时候,扣减为 15 的这个请求先到消息队列执行,将缓存更新为余票 15,但是随之而来的是第一个请求余票为 16,会将缓存余票为 15 给覆盖掉。
类似于这种逻辑,会存在一些数据一致性的问题,需要我们通过其它技术手段完善,比如数据库添加版本号,或者根据最后修改时间等技术规避这些问题。
另外,如果在写入数据库余票 16 前,同时有个查询请求,也会存在数据库不一致问题。比如在写入数据库余票 16 前,将数据库余票 17 获取到,然后等消息队列更新到缓存余票 16 后,再将数据库余票 17 更新到缓存。
这种出问题的概率比较小,因为跨的周期太长了。也是类似于存在一个很小周期的数据不一致性。
需要额外注意的是,因为 Binlog 监听中用到了消息队列,就不得不考虑重复消费问题
使用推荐
- 缓存双删:如果公司现有消息队列中间件,可以考虑使用该方案,反之则不需要考虑。
- 先写数据库再删缓存:这种方案从实时性以及技术实现复杂度来说都比较不错,推荐大家使用这种方案。
- Binlog 异步更新缓存:如果希望实现最终一致性以及数据多中心模式,该方案无疑是最合适的。
细究缓存删除和 Binlog 异步处理方案的弊端
挑一挑缓存删除以及 Binlog 异步处理的一些 “刺”,以及不同问题下的解决方案是什么。
首先思考一个问题,缓存删除真的合适么?在涉及海量并发的场景中,如果程序删除了缓存,可能会导致缓存击穿问题,而更新频繁时则可能引发缓存雪崩。
因此,在考虑缓存一致性模型时,务必充分考虑业务场景是否属于高并发模型。如果是高并发场景,删除缓存可能并不合适,此时应采用最终一致性策略。
但是,Binlog 异步处理就没问题了么?也不尽然。需要看缓存中的数据是什么属于场景,比如你存储的是车票库存数量还是说某个车站信息。
如果是更新库存数量,比如库存加减,不要再去数据库查询最新库存,而是通过 Redis 提供的自增命令即可,简单且高效。
如果是更新车站信息,例如修改列车信息等类似数据,可能会面临并发操作中的 ABA 问题。为了更好地理解,我们可以举个例子:假设我们将复兴号的发车时间从之前的 12:00 修改为 16:00,但在短时间内发现这个更改是错误的,因此又将 16:00 修改为 16:30。这种情况下,存在一个可能性,即后一次修改 16:30 的请求先执行,然后再执行 16:00 的变更,导致数据不一致的情况发生。发生这个问题的原因在于投递到消息队列后,默认消息是无序的。
针对这种问题背景,我们可以提出两种解决方案,同时对其进行优化和补充说明:
- 顺序消息队列解决方案:针对那些不经常变更的数据,可以使用消息队列来保证修改变更的顺序性。通过将每次修改操作作为一个顺序消息发送到消息队列中,可以确保消息按照发送的顺序被处理,从而避免了ABA问题的发生。然而,需要注意的是,顺序消息的解决方案也存在一定的风险。如果某个列车数据异常导致消息阻塞,可能会影响整个消息队列的处理速度和稳定性。
- 增加版本号解决方案:在进行修改操作时,先判断当前版本号是否小于要修改的版本号,只有在当前版本号小于目标版本号的情况下才进行修改。通过增加版本号,可以有效避免并发修改引起的数据不一致问题。然而,这种方案需要对现有的数据库和缓存结构进行改动,可能会带来一定的执行成本和复杂性。
综合考虑,我个人倾向于推荐第二种解决方案,即增加版本号。这种方案相对稳妥且高效,可以在保证数据一致性的同时降低风险。然而,具体选择哪种解决方案还取决于您的实际需求和系统环境。请综合考虑各种因素并做出适合您情况的选择。
文末总结
总结一下关于缓存与数据库一致性的方案:如果你想要最终一致性可以使用Binlog 异步更新缓存方案,如果缓存实时性要求比较高,使用先写数据库再删缓存方案。
真实场景中根据具体业务需求和系统架构,可以选择适合的方案或组合多种方案。这些方案最终目的是在解决缓存与数据库之间的一致性问题,以确保数据的正确性和可靠性。