HRM项目总结
HRM项目总结(Day01-Day11)
一、HRM_Day01_搭建微服务
1.项目原型
前端:elementui+div+css
后端:使用微服务(springCloud)+SSM,mybatis-plus
2.项目架构分析(重点)
使用技术分析:
MySQL:用于存储数据
redis:用于存放缓存
FastDFS:分布式文件系统
elasticsearch:全文检索
Feign/Hystrix:用于服务之间的调用和熔断操作
SpringCloudCofig:存放所有服务的配置文件
Erueka:注册中心,存放所有的服务
Gitee:远端仓库,配置中心到仓库拉取文件
Zuul网关:配置路由,通过路由访问
nginx:反向代理,通过虚拟ip调用不同的主机(虚拟)
3.系统中心后台微服务搭建(重点)
3.1.集成ssm
使用mybatis-plus+spring+springmvc集成
主要项目结构:
parent=>interface(domain、query、clien、clienImpl)、service(Mapper.java、service、controller、mapper.xml)
3.2.配置网关
网关配置文件设置路由:
zuul:
prefix: /services
ignored-services: '*'
routes:
system:
path: /system/**
service-id: system-service
3.3.集成swagger
导入swagger的相关依赖,直接copy项目需要使用的Swagger2Configuration类
**测试:**localhost:端口/swagger-ui.html
**注意:**Swagger2Configuration类需要注解@Configuration、@EnableSwagger2
4.mybatis-plus入门(重点)
4.1入门
https://mp.baomidou.com/ 参考官网
4.2核心
1.提供crud基本接口,只能对单表操作,多表需要自己写sql
2.分页提供一个bean,分页插件
3.在mapper中进行分页,方法第一个参数必须是Page
4.提供条件构造器,使用QueryWrapper
5.代码生成器,cv自己会改就ok
二、HRM_Day02_搭建课程服务
1.gitee仓库搭建(重点)
创建gitee仓库,idea与仓库创建连接,pull后再拉取
**常见错误:**Push to origin/master was rejected
**解决方法:**打开项目的根目录,右击选择Git Bash here,依次输入以下命令
git pull
git pull origin master
git pull origin master --allow-unrelated-histories
2.配置中心搭建(重点)
2.1.单机版
1.创建gitee仓库
2.创建配置中心服务端
3.编写配置中心配置文件,配置远程拉取的地址
4.启动类添加配置中心的注解@EnableConfigServer
4.上传服务配置文件到Gitee仓库
2.2.集群版
复制单机版的配置中心,改个端口,注册到同一个服务下,其他客户端可以直接任意拉取二者之一
3.抽取swagger
1.设置配置文件META-INF/spring.factories
2.添加自动配置类EnableAutoConfiguration=XXXAutoConfiguration
3.编写XXXProperties配置文件
4.其他服务使用可以直接导入swagger抽取后的场景启动器依赖后使用
4.代码生成器
copy自己能看懂一点点即可
5.搭建前端项目(重点)
1.禁用mock
2.安装axios
3.解决跨域问题
4.设置统一跨域处理(copy)
5.设置仓库,提交到gitee
6.搭建课程中心后台(重点)
1.搭建课程中心客户端
2.集成ssm+mybatis-plus
3.bootstrap.yml设置配置文件,通过配置中心拉取配置文件
4.引入swagger
5.配置网关路由
三、HRM_Day03_租户实现
1.数据隔离
1.给每个租户提供一套数据库
2.不同租户存放到不同的表中
3.通过租户id在一张表进行区分(推荐)
2.权限分配
基于RBAC实现权限的控制,主要表为用户、角色、权限、套餐、租户,权限跟套餐绑定,租户购买套餐,租户下的用户只能分配套餐中对应的权限
3.建库建表
copy即可
4.后端注册租户实现
略,参考代码
5.前端实现
copy即可
6.分布式文件系统(重要)
6.1.为什么使用分布式文件系统
微服务中,集群环境下,文件上传到服务器中,后面客户端访问不一定能拿到数据,所有需要分布式文件系统来存放文件,方便每个客户端都能拿到想要的数据
6.2.技术选型
FastDFS
6.3.fastdfs的概述
Tracker Server:调度服务器,负责均衡,调度可用的Storage Server(存储服务器)
Storage Server:存储服务器,专们用来存储文件的
7.使用fastdfs完成logo上传
1.创建文件系统的服务端
2.导入相关依赖
3.配置bootstrap.yml,从配置中心拉配置
4.网关配置文件系统的路由
5.配置swagger
6.提供文件上传接口
四、HRM_Day04_课程类型维护
1.修改前端页面
1.修改展示后台的基本信息,如标题
2.修改菜单的选项
3.添加课程类型的路由
2.课程类型维护
2.1.布局
略,参考代码与界面
2.2.后端实现(查询)
实现方式:
1.使用递归
2.使用嵌套循环
3.使用循环+map(推荐,效率高于前者)
3.课程类型优化
3.1.为何要优化
由于课程类型需要长期被查询,用的是微服务,为了避免数据库高并发,所以使用redis存储缓存,解决高并发导致数据库奔溃,从而也减少了数据库的压力
3.2.优化方案
使用redis服务器,将缓存集中进行存放,并且redis本身也可以集群
4.项目使用redis
1.搭建缓存服务
2.导入相关依赖
3.提供缓存实现接口
4.编写缓存的controller
5.提供Feign接口,便于课程类型服务来使用
五、HRM_Day05_课程维护
1.课程前台
copy即可
2.后台维护属性
基本属性:后台管理员对课程基本信息进行查看与修改
市场属性:后台管理员对市场的基本信息进行查看与修改
媒体属性:后台管理员对媒体的基本信息进行查看与修改,如查看产品图片等
页面设计:提供高级查询、上线与下线、对课程的添加
3.建库建表
copy即可
4.代码生成
略,稍微搞一下生成的表与生成的路径即可
5.课程信息维护
5.1.分页高级查询
使用mybatis-plus,在mapper中使用高级查询,只需要把第一个参数设置为Page即可
5.2.富文本编辑
使用vue-quill-editor实现富文本编辑器,参考网址安装与使用https://www.npmjs.com/package/vue-quill-editor
六、HRM_Day06_上线下线
1.为什么需要上线线下
后台管理课程没有上线就不能给前台用户查看,提高用户体验,增加系统的严谨性,下线后用户就不能够再购买,所有此功能是必须的
2.课程信息维护基本步骤
课程基本信息维护
市场信息维护
资源信息维护
上线与下线操作
3.技术选型
使用全文检索elasticserach用于存放课程的基本信息,减低数据库压力,提高查询效率,提高用户体验
4.上下线实现-SpringDataElasticsearch(重点)
4.1.基本概念
pring Data
Spring提供的对数据访问的规范
Spring Data JDBC
Spring遵循Spring Data规范提供的数据库访问的实现
Spring Data JPA
Spring遵循Spring Data规范提供的JPA框架的实现
Spring Data ElasticSearch
Spring遵循Spring Data规范提供的ElasticSearch访问的实现
spring-boot-starter-data-elasticsearch
springboot提供的spring data elasticsearch的场景启动器
使用它可以简化spring data elasticsearch的配置
参考https://docs.spring.io/spring-boot/docs/2.1.15.RELEASE/reference/html/boot-features-nosql.html#boot-features-elasticsearch
4.2.项目实现
1.添加全文检索的服务端
2.导入相关依赖,全文检索场景启动器
3.yml配置文件配置elasticsearch的端口,一般为9300
5.创建文档实体类
6.编写repository接口继承ElasticsearchRepository
7.提供上线与线下的接口
8.提供Feign的client给课程服务使用
9.课程实体类与课程文档实体类的转换
10.课程service中调用全文检索服务中的方法
七、HRM_Day07_nginx技术
1.使用nginx理由
部署前端项目、配置虚拟主机、实现反向代理
2.安装启动
安装根目录bin下执行startup.bat命令(解压即可)
3.window安装
官网下载,解压即可使用、参考官网nginx.org、nginx.com
4.linux安装
需要编译后安装
5.启动
start nginx.exe 启动
nginx.exe -s stop 停止
nginx.exe -s reload 重新加载配置文件
nginx.exe -t 测试配置文件是否正确
6.静态资源部署(重点)
vue项目打包后直接拷贝到nginx解压目录下的html中即可使用
静态资源热部署:
1.安装live-server,执行npm install live-server -g
2.执行live-server --port=端口启动
7.配置虚拟主机
7.1.端口绑定
配置两个server绑定两个端口(nginx.conf)
#一个server表示一个虚拟主机
server {
listen 82;
#主机名,相当于域名
server_name localhost;
location / {
#那个文件
root hrm-web-course;
#那个页面
index home.html;
}
}
server {
listen 83;
server_name localhost;
location / {
root hrm-web-plat;
index index.html;
}
}
7.2.域名绑定(重点)
配置两个server绑定两个域名
同上,只是给服务配置了一个端口而已
8.反向代理(重点)
微服务中就是使用zull的集群负载均衡访问通过nginx实现
#反向代理
upstream tomacats {
#指明那几个服务使用负载均衡,weight表示权重,数字越高,频率越高
server localhost:8080 weight=7;#localhost:8080为tomcat1的端口
server localhost:8081 weight=1;#localhost:8081为tomcat2的端口
}
server {
listen 88;#使用此端口测试
location / {
proxy_pass http://tomacats;#指向上面tomacats
}
}
详细nginx.conf如何修改,参考http://nginx.org/en/docs/http/load_balancing.html
八、HRM_Day08_RabbitMQ
1.RabbitMQ是什么(重要)
RabbitMQ就是一个消息队列,基于erlang语言开发,遵循AMQP协议
RabbitMQ是支持持久化消息队列的消息中间件。应用在上下游的层次级业务逻辑中,上级业务逻辑相当于生产者发布消息,下级业务逻辑相当于消费者接受到消息并且消费消息
2.为什么使用(重要)
**异步:**提高了系统的响应速度
**解耦:**提高了系统的扩展性
**排序保证FIFO:**如果消息没有被正常消费,消息还是可以存在的,宕机的服务器重启后会重复消费这个消息直到成功(用于秒杀)
流量削峰
3.为什么要选择RabbitMQ(重要)
常见的队列:ActiveMQ、RabbitMQ、RocketMQ、Kafka
RocketMQ和Kafka是比较庞大的MQ,适合在大型项目中使用
ActiveMQ和RabbitMQ适合在中小型项目中使用,但是ActiveMQ社群不活跃,对旧版本的维护停止
所以选择RabbitMQ
优势:
- erlang语言,高并发支持友好
- 简单,文档丰富
- AMQP协议,多语言都可以操作
- springboot已经提供了rabbitmq的启动器
4.安装与启动
4.1安装erlang
- 傻瓜安装
- 安装成功后path配置erlang的环境变量
- cmd命令行输入erl -version检查erlang环境
- 注意
**注意:**erlang的版本和rabbitmq的版本有对应关系
4.2安装rabbitmq
1.傻瓜安装,下一步即可
2.开始菜单启动rabbitmq(安装目录rabbitmq-service.bat启动)
5.工作原理(重要)
Broker(Server):消息队列服务进程,此进程包括两个部分:Exchange和Queue。
Exchange:消息队列交换机,按一定的规则将消息路由转发到某个队列,对消息进行过虑。
Queue:消息队列,存储消息的队列,消息到达队列并转发给指定的消费方。
Producer(client):消息生产者,即生产方客户端,生产方客户端将消息发送到MQ。
Consumer(client):消息消费者,即消费方客户端,接收MQ转发的消息
-----发送消息-----
1、生产者和Broker建立TCP连接。
2、生产者和Broker建立通道。
3、生产者通过通道消息发送给Broker,由Exchange将消息进行转发。
4、Exchange将消息转发到指定的Queue(队列)
----接收消息-----
1、消费者和Broker建立TCP连接
2、消费者和Broker建立通道
3、消费者监听指定的Queue(队列)
4、当有消息到达Queue时Broker默认将消息推送给消费者。
5、消费者接收到消息。
6.消息模型
6.1.消息的ACK
防止因为消费者没有正常消费消息导致消息丢失
自动ACK:消息一旦被接收,消费者自动发送ACK
手动ACK:消息接收后,不会发送ACK,需要手动调用
如果消息不太重要,丢失也没有影响,那么自动ACK会比较方便
如果消息非常重要,不容丢失,那么最好在消费完成后手动ACK,否则接收消息后就自动ACK,RabbitMQ就会把消息从队列中删除。如果此时消费者宕机,那么消息就丢失了
6.2.work-queue
一个生产者,多个消费者,但是一条消息只能一个消费者消费
消费者只能预处理一条消息,只有处理完毕回执之后,才能拉取新的消息
优点:充分利用服务器资源
6.3.订阅模型 - fanout(重点)
发布与订阅 all 所有绑定的队列都会接收到消息
6.4.订阅模型 - direct(重点)
routingkey进行路由,将消息发送到指定的队列中
需要指定routingkey,交换机的类型在声明交换机的时候也要指定
6.5.订阅模型-topic(重点)
和direct很类似,只是routingkey可以使用通配符 * #
#:匹配一个单词
*:匹配多个单词
代码示例:
public class Consumer {
private static final String EXCHANGE_NAME = "exchange_topic_test";
private static final String QUEUE_EMAIL = "queue_topic_jing";
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
//声明队列
channel.queueDeclare(QUEUE_EMAIL,false,false,false,null);
//队列绑定交换机
/**
*
* routingkey的语法(规则,约定)
*
* 多个单词,每个单词用.分割
*
* user.add
* user.delete
* user.dept.add
* user.dept.delete
*
* * 匹配一个单词 user.*
* # 匹配任意个单词 user.#
*
*/
channel.queueBind(QUEUE_EMAIL, EXCHANGE_NAME,"user.#");
DefaultConsumer consumer = new DefaultConsumer(channel){
/**
* 接收到消息的时候自动调用这个方法
* @param consumerTag 消费者标签
* @param envelope 封装了消息的很多属性
* @param properties 消息的一些属性
* @param body 消息体
*/
public void handleDelivery(
String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body) throws IOException {
String message = new String(body,"utf-8");
//业务代码消费消息
System.out.println("jing收到的消息:"+message);
}
};
/**
* @param queue 队列的名称
* @param autoAck 消息自动回执
* @param callback 消息消费的回调
*/
channel.basicConsume(QUEUE_EMAIL,true,consumer);
}
}
6.6.订阅模型-Headers
不使用routingkey进行路由,使用一个map
6.7.持久化
消息的持久化前提是:队列的持久化和交换机的持久化
持久化分类:
- 队列的持久化
- 交换机的持久化
- 消息的持久化
九、HRM_Day09_用户注册
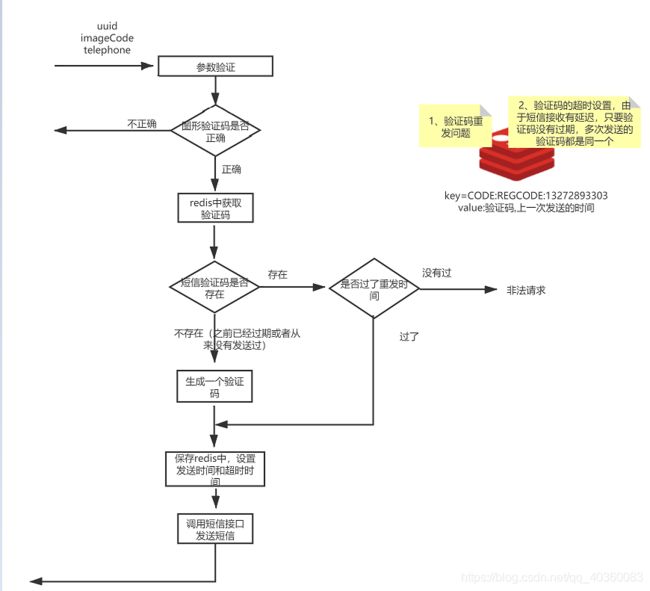
见流程图
十、HRM_Day10_单点登录
1.什么是单点登录
单点登录( Single Sign-On , 简称 SSO )是目前比较流行的服务于企业登录业务整合的解决方案之一, SSO 使得在多个应用系统中,用户只需要 登录一次 就可以访问所有相互信任的应用系统。
2.代码实现
实现步骤:
- 后端服务保护处理-zuul拦截
- 登录
- 后端登录服务
- 前端登录实现
- 站点做登录检查
十一、HRM_Day11_Docker部署
1.Docker的安装与启动
1.1.卸载老版本
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
1.2.设置yum仓库
yum install -y yum-utils
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
1.3.安装Docker引擎
yum install docker-ce docker-ce-cli containerd.io
1.4.启动Docker
systemctl start docker
1.5. 运行hello-world镜像
docker run hello-world
命令界面看到hello from Docker表示安装成功
1.6. 启动与停止Docker
启动docker:systemctl start docker
停止docker:systemctl stop docker
重启docker:systemctl restart docker
查看docker状态:systemctl status docker
2.Docker镜像操作
2.1.查看镜像列表
docker images

REPOSITORY:镜像所在的仓库名称
TAG:镜像标签
IMAGE ID:镜像ID
CREATED:镜像的创建日期(不是获取该镜像的日期)
SIZE:镜像大小
2.2.查询镜像
使用命令查询:
docker search tomcat
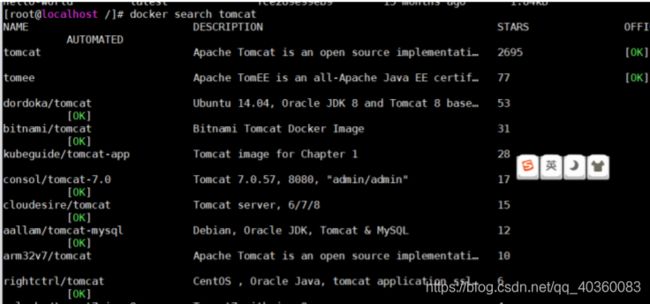
NAME:仓库名称
DESCRIPTION:镜像描述
STARS:用户评价,反应一个镜像的受欢迎程度
OFFICIAL:是否官方
AUTOMATED:自动构建,表示该镜像由Docker Hub自动构建流程创建的
登录Docker Hub中进行查询:
https://hub.docker.com/
2.3.配置镜像加速器
/etc/docker/daemon.jsonz中修改
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
2.4. 拉取镜像
docker pull 仓库:TAG
如果不写TAG,默认是latest
2.5.删除镜像
docker rmi IMAGE_ID
docker rmi 仓库:TAG
3.Docker容器操作
3.1.查看容器
3.1.1.查看运行中的容器
CONTAINER ID 容器ID
IMAGE 基于的镜像
COMMAND 命令
CREATED 创建时间
STATUS 容器状态
PORTS 端口映射
NAMES 容器名称
3.1.2.查询所有容器
查询所有容器
docker ps -a
查询正在运行的容器
docker ps
3.1.3.查看最后一次运行的容器
docker ps -l
3.1.4.查询已经停止的容器
docker ps -f status=exited
3.2.创建容器
3.2.1.容器创建
docker run
3.2.2.容器创建参数
i 启动容器
-t 交互式窗口
-d 守护式
--name 容器名称
-v 目录映射
-p 端口映射
3.2.3.创建交互式容器
docker run -it --name=mycentos7 centos:7 /bin/bash
退出容器:
exit
交互式容器在exit后容器关闭
3.2.4.创建守护式容器
docker run -id --name=mycentos centos:7
创建守护式容器后并没有立即进入到容器中
docker exec -it mycentos /bin/bash
退出容器:
exit
守护式容器在退出后并不会停止
3.3.启动与停止容器
启动容器:
docker start 容器名称/容器ID
停止容器:
docker stop 容器名称/容器ID
3.4.文件拷贝
从宿主机拷贝到容器中
docker cp 宿主机的文件 容器名称:容器的目录
docker cp /test.txt mycentos:/
从容器中拷贝到宿主机
docker cp 容器名称:容器的目录 宿主机的目录
docker cp mycentos:/aaa.txt /
3.5.目录挂载
创建容器的时候使用-v参数
前面是宿主机的目录,后面是容器的目录
docker run -id --name=centos7 -v /user/local/mydir:/usr/local/dir
centos:7
3.6.端口映射
docker run -id --name=mytomcat -p 80:8080 tomcat:latest
3.7.删除容器
指定容器删除
docker rm 容器名称/容器ID
删除所有容器
docker rm `docker ps -a -q`
**注意:**无法删除运行的容器,容器要先停止后删除
4.Docker准备HRM的环境
4.1.Docker可视化界面-Portainer
4.1.1.拉取portainer镜像
docker pull portainer/portainer
4.1.2.启动容器
docker run -d -p 9000:9000 \
--restart=always \
-v /var/run/docker.sock:/var/run/docker.sock \
--name prtainer-test \
portainer/portainer
4.1.3.浏览器访问
192.168.0.1:9000,192.168.0.1为自己电脑ip地址
4.2.准备JDK的基础镜像
4.2.1.编写Dockerfile
FROM centos:7
MAINTAINER solargen
WORKDIR /usr
RUN mkdir /usr/local/java
ADD jdk-8u151-linux-x64.tar.gz /usr/local/java
ENV JAVA_HOME /usr/local/java/jdk1.8.0_151
ENV JRE_HOME $JAVA_HOME/jre
ENV CLASSPATH
$JAVA_HOME/bin/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLA
SSPATH
ENV PATH $JAVA_HOME/bin:$PATH
4.2.2.准备jdk的安装文件
jdk-8u151-linux-x64.tar.gz
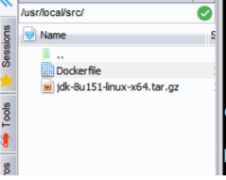
4.2.3. 将Dockerfile和jdk的安装文件上传到linux中
4.2.4.执行构建
cd /usr/local/src
docker build -t="jdk1.8" .
4.2.5.查看镜像
cd /usr/local/src
docker build -t="jdk1.8" .
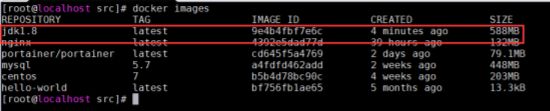
4.2.6.镜像测试
基于镜像启动容器 :
docker run -id --name=myjdk jdk1.8:latest
进入容器 :
docker exec -it myjdk /bin/bash
测试jdk:
java
javac
4.3.搭建docker的私有仓库
4.3.1.下载私有仓库镜像
docker pull register
4.3.2.启动私有仓库镜像
docker run -id --name=registry -p 5000:5000 registry
4.3.3.测试

4.3.4.让docker信任私有仓库
修改vi /etc/docker/daemon.json
{
"registry-mirrors": [
"https://registry.docker-cn.com"
],
"insecure-registries":["172.16.4.182:5000"]
}
4.3.5. 重启docker
systemctl restart docker
docker start taigao-registry
docker info
4.4.上传镜像到私有仓库
4.4.1.标记此镜像为私有仓库镜像
docker tag jdk1.8 172.16.4.182:5000/jdk1.8
4.4.2.上传镜像
docker push 172.16.4.182:5000/jdk1.8
4.4.3.测试
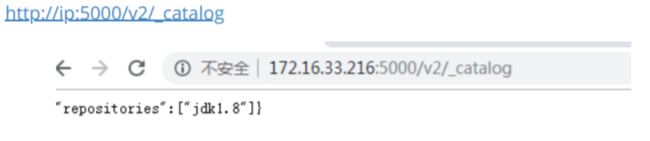
4.5.Maven插件构建Eureka服务镜像
略,详细参考百度文档
https://blog.csdn.net/quliuwuyiz/article/details/88747026?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159447881519724848305279%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159447881519724848305279&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v3~pc_rank_v3-1-88747026.pc_ecpm_v3_pc_rank_v3&utm_term=Maven%E6%8F%92%E4%BB%B6%E6%9E%84%E5%BB%BAEureka%E6%9C%8D%E5%8A%A1%E9%95%9C%E5%83%8F