Kafka生产者源码解析(二)——RecordAccumulator
在上一篇中介绍了KafkaProducer的构造方法及send核心方法,其中在send方法中涉及到将消息追加入RecordAccumulator消息累加器的过程,本篇重点将围绕RecordAccumulator来分析这一过程。
对于Spring-Kafka生产者源码将分成三个部分进行分析:KafkaProducer分析、RecordAccumulator分析、Sender线程分析。本篇是第二部分RecordAccumulator分析。
Spring-Kafka生产者源码解析(一)——KafkaProducer
Spring-Kafka生产者源码解析(二)——RecordAccumulator
Spring-Kafka生产者源码解析(三)——Sender
目录
一、RecordAccumulator的结构
二、append方法解析
三、总结
RecordAccumulator可以理解为主线程与Sender线程之间的一个缓冲区,在异步发送消息的过程中,主线程将消息存入到RecordAccumulator中后返回,然后满足一定条件时Sender线程再从RecordAccumulator中取出消息进行发送,为了能够很好的理解消息存入RecordAccumulator这一过程,我们先来了解一下RecordAccumulator的结构。
一、RecordAccumulator的结构
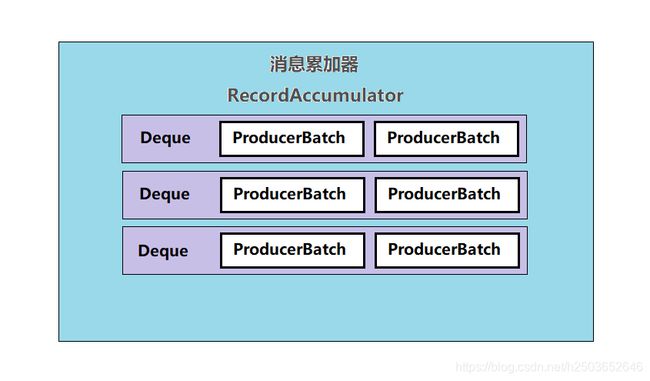
进入RecordAccumulator类中,可以看到它有很多的属性字段,其中batches这个字段需要引起我们的注意,它是一个以TopicPartition作为key,Deque
|
|

最后存入RecordAccumulator中的消息将会是这样。
|
|
二、append方法解析
RecordAccumulator的构造方法中通过CopyOnWriteMap初始化了上述谈到的batches对象,同时还初始化了其他的属性内容,这里不再赘述其构造的过程,而是着重分析上一篇中遗留的内容:KafkaProducer是如何通过accumulator.append方法将消息追加到RecordAccumulator消息累加器中的。
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
//并发数加1,统计正在向RecordAccumulator中追加消息的线程数
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
//查找TopicPartition对应的Deque,如果没有则创建
Deque dq = getOrCreateDeque(tp);
//追加消息时需要加锁
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
//尝试往Deque中最后一个ProducerBatch中追加消息记录
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
//消息追加成功返回结果
return appendResult;
}
//来到这一步说明上面消息追加失败
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
//获取要创建的ProducerBatch的内存大小
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
//从BufferPool中申请空间用于后面创建新的ProducerBatch
buffer = free.allocate(size, maxTimeToBlock);
//和上面一样,追加消息时需要加锁
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new KafkaException("Producer closed while send in progress");
//在创建新的ProducerBatch之前再次尝试往Deque中最后一个ProducerBatch中追加消息记录,说不定现在成功了呢
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
//消息追加成功返回结果
return appendResult;
}
//如果消息还是追加失败了。。。
//构造MemoryRecordsBuilder,消息将会存入它拥有的MemoryRecords对象
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
//创建ProducerBatch
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
//使用batch.tryAppend追加消息
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
//将刚创建的ProducerBatch放入Deque双端队列尾部
dq.addLast(batch);
incomplete.add(batch);
//到这里消息已经追加成功,将buffer置空
buffer = null;
//返回结果
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
if (buffer != null)
//释放之前申请的新空间
free.deallocate(buffer);
//结束,并发数减1
appendsInProgress.decrementAndGet();
}
} 上面的代码已经给出了注释,现将这段代码的流程总结如下:
|
这段代码的核心部分便是batch.tryAppend方法,下面是该方法的部分源码,首先是检查了一下消息存储器的剩余空间是否充足,若不足则直接返回null,后面走申请空间新建ProducerBatch的流程。如果空间剩余充足则MemoryRecordsBuilder会调用append方法进行消息追加。
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
//检查消息存储器中剩余空间是否充足,若空间不足则直接返回null
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
return null;
} else {
//消息写入
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers);
……………………
return future;
}
}然后像洋葱一样不断剥开append方法的皮,,,,,发现MemoryRecordsBuilder最终会根据KafkaProducer客户端版本的不同去调用下面两个方法之一:appendDefaultRecord和appendLegacyRecord。
private void appendDefaultRecord(long offset, long timestamp, ByteBuffer key, ByteBuffer value,
Header[] headers) throws IOException {
………………
int sizeInBytes = DefaultRecord.writeTo(appendStream, offsetDelta, timestampDelta, key, value, headers);
recordWritten(offset, timestamp, sizeInBytes);
}
private long appendLegacyRecord(long offset, long timestamp, ByteBuffer key, ByteBuffer value) throws IOException {
………………
long crc = LegacyRecord.write(appendStream, magic, timestamp, key, value, CompressionType.NONE, timestampType);
recordWritten(offset, timestamp, size + Records.LOG_OVERHEAD);
return crc;
}它们分别通过DefaultRecord.writeTo和LegacyRecord.write去实现最终的消息追加,它们的第一个参数就是一开始所谈到的DataOutputStream对象,DataOutputStream里面持有ByteBufferOutputStream,这是一个缓存buffer,所以往DataOutputStream里面写消息数据,就是往缓存里面写消息数据,后面的recordWritten方法主要是处理位移问题。
下面主要以writeTo方法源码为例来看下其最终处理逻辑:
public static int writeTo(DataOutputStream out,
int offsetDelta,
long timestampDelta,
ByteBuffer key,
ByteBuffer value,
Header[] headers) throws IOException {
//计算消息数据大小
int sizeInBytes = sizeOfBodyInBytes(offsetDelta, timestampDelta, key, value, headers);
//写入消息数据大小
ByteUtils.writeVarint(sizeInBytes, out);
……………………
//写入key值
if (key == null) {
ByteUtils.writeVarint(-1, out);
} else {
int keySize = key.remaining();
ByteUtils.writeVarint(keySize, out);
Utils.writeTo(out, key, keySize);
}
//写入value值
if (value == null) {
ByteUtils.writeVarint(-1, out);
} else {
int valueSize = value.remaining();
ByteUtils.writeVarint(valueSize, out);
Utils.writeTo(out, value, valueSize);
}
if (headers == null)
throw new IllegalArgumentException("Headers cannot be null");
ByteUtils.writeVarint(headers.length, out);
//循环headers写入
for (Header header : headers) {
…………………………
}
//返回总数据的大小
return ByteUtils.sizeOfVarint(sizeInBytes) + sizeInBytes;
}到这里追加消息记录到RecordAccumulator消息累加器中的流程结束。
三、总结
本篇主要是对RecordAccumulator的结构及append方法进行了分析,KafkaProducer将消息不断的暂存入RecordAccumulator之中,当满足了一定的条件后,将会触发唤醒Sender线程,而Sender线程的主要工作就是把RecordAccumulator中的消息通过网络I/O发送出去,至于满足什么样的条件以及Sender线程具体是如何工作的将会放在第三篇进行分析。