Kafka生产者发送流程源码解析
1.说明
本文章简单流程追踪一下Kafka从客户端数据发送到Server的流程。
看完本文,你将会大致了解客户端数据发送的过程。
2.发送数据的例子
public class CustomProducer {
public static void main(String[] args) throws Exception{
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "xxxx:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("test", "hello! --->" + i));
}
kafkaProducer.close();
}
}
以上是我们使用kafka最简单发送数据的例子,我们重点将围绕send()方法进行探究。
3.KafkaProducer
KafkaProducer
发送数据之间,我们是先实例化了KafkaProducer类,我们大致查看构造器的源码:
public KafkaProducer(Properties properties) {
this(propsToMap(properties), null, null, null, null, null, Time.SYSTEM);
}
KafkaProducer(Map<String, Object> configs,
....) {
ProducerConfig config = new ProducerConfig(ProducerConfig.addSerializerToConfig(configs, keySerializer,valueSerializer));
try {
// 分区器配置
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
// 重试的时间间隔,默认100ms
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
// 序列化器
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,Serializer.class);
// 拦截器
List<ProducerInterceptor<K, V>> interceptorList = (List) configWithClientId.getConfiguredInstances(
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptor.class);
// 单条消息的最大值,默认1M
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
// 缓存的大小,默认32M
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
// 压缩配置
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
// 重要,发送数据的累加器
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), // 批次大小16K
this.compressionType,// 没指定就是none
lingerMs(config), // linger.ms 默认0
retryBackoffMs, // 重试间隔时间,默认100ms
deliveryTimeoutMs, // 默认2分钟
metrics,
PRODUCER_METRIC_GROUP_NAME,
new BufferPool(this.totalMemorySize);
// 重要,真正发送数据的任务
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
// 生产者线程启动
this.ioThread.start();
log.debug("Kafka producer started");
} catch (Throwable t) {
close(Duration.ofMillis(0), true);
throw new KafkaException("Failed to construct kafka producer", t);
}
}
构造器里面,初始化了一些默认的参数设置,比较重要的是启动了Send线程。
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {
// 缓存的发送请求默认是5
int maxInflightRequests = configureInflightRequests(producerConfig, transactionManager != null);
// 请求超时时间,默认30s
int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
// 发送数据的客户端
KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(
new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
this.metrics, time, "producer", channelBuilder, logContext),
metadata,
clientId,
maxInflightRequests,
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
requestTimeoutMs,
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
return new Sender(logContext,
client, // 客户端
metadata,
this.accumulator, // 累加器
maxInflightRequests == 1,
producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
retries,
metricsRegistry.senderMetrics,
time,
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
}
创建Send线程时,传入了各种配置参数,这些参数都是可以根据实际情况进行调优设置的。
4.send()流程
public Future<RecordMetadata> send(ProducerRecord<K, V> record){
return send(record, null);
}
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// 第一步会先执行我们配置的拦截器
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
doSend(interceptedRecord, callback):
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
// first make sure the metadata for the topic is available
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
// 从kafka拉取元数据, maxBlockTimeMs 最多等待的时间
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
// 剩余时间 = 最多能等待时间 - 用了多少时间;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 序列化操作
byte[] serializedKey;
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
byte[] serializedValue;
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
// 分区器执行,分区计算
int partition = partition(record, serializedKey, serializedValue, cluster);
// 要发送的topic的分区
tp = new TopicPartition(record.topic(), partition);
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
// 检查发送前数据的大小 serializedSize = key + value + header
ensureValidRecordSize(serializedSize);
// 往累加器里面追加要发送的数据
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// 批次满了 或者 创建了一个新的批次,唤醒sender发送线程
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
}
}
send()方法的大致流程就是:
拦截器执行 —> 序列化器 —> 分区器 —> 添加到 RecordAccumulator 里面。
我们在看一下 accumulator.append()方法:
ByteBuffer buffer = null;
try {
// 根据分区,来创建一个双端队列
// 每个分区都对应一个队列
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
// batchSize 默认16kb,实际数据的大小
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
// 给要发送的数据分配空间
buffer = free.allocate(size, maxTimeToBlock);
nowMs = time.milliseconds();
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 尝试向队列里面添加数据(有内存,但是没有批次对象)
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
// 根据内存大小封装批次(有内存、有批次对象)
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs);
FutureRecordMetadata future = Objects.requireNonNull(batch.tryAppend(timestamp, key, value, headers,
callback, nowMs));
// 把创建的批次加入到队列尾部
dq.addLast(batch);
incomplete.add(batch);
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true, false);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
RecordAccumulator 类里面的结构:
// Map以上数据已经被暂存到了累加器里面,我们下面来看看数据如何发送给Server的。
先前开启了一个Sender线程,我们来分析一下这个线程任务:
5.Sender 流程
Sender 实现了 Runnable,直接看run()方法流程:
@Override
public void run() {
log.debug("Starting Kafka producer I/O thread.");
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
}
void runOnce() {
long currentTimeMs = time.milliseconds();
// 准备发送数据给server
long pollTimeout = sendProducerData(currentTimeMs);
// 等待发送响应
client.poll(pollTimeout, currentTimeMs);
}
接下来看一下数据是怎么发送的:
sendProducerData():
private long sendProducerData(long now) {
// 获取元数据
Cluster cluster = metadata.fetch();
// 检测数据是否准备好
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic, now);
this.metadata.requestUpdate();
}
// create produce requests
// 将发往同一个节点的数据,放在一个批次里面
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
addToInflightBatches(batches);
// 发送数据
sendProduceRequests(batches, now);
return pollTimeout;
}
sendProduceRequests(batches, now):
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
requestTimeoutMs, callback);
client.send(clientRequest, now);
}
client 为 NetworkClient#send:
doSend(clientRequest, isInternalRequest, now, builder.build(version));
|
|
selector.send(send);
数据发送完成。
6.原理图
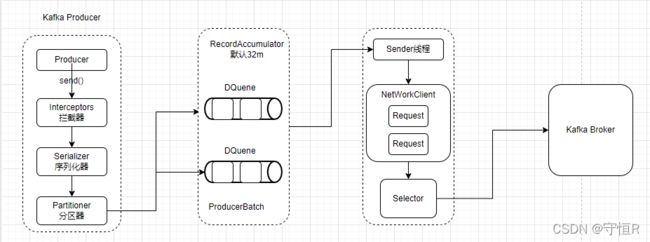 完结。
完结。