字符编码、Unicode原理、数据流压缩Zlib与Miniz的实现
字符集和字符编码的区别和联系
- 字符集:多个字符的集合。例如 GB2312 是中国国家标准的简体中文字符集,GB2312 收录简化汉字(6763 个)及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。
- 字符编码:把字符集中的字符编码为(映射)指定集合中的某一对象(例如:比特模式、自然数序列、电脉冲),以便文本在计算机中存储和通过通信网络的传递。
字符集和字符编码的关系 :
1. 字符集是书写系统字母与符号的集合
2. 字符编码则是将字符映射为一特定的字节或字节序列,是一种规则。
通常特定的字符集采用特定的编码方式(即一种字符集对应一种字符编码(例如:ASCII、 IOS-8859-1、 GB2312、 GBK,都是即表示了字符集又表示了对应的字符编码,但 Unicode 不是,它采用现代的模型))
字符集编码的发展
单字节 -> 双字节 -> 多字节
单字节
ASCII(American Standard Code for Information Interchange),128 个字符,用 7 位二进制表示(00000000-01111111 即 0x00-0x7F),EASCII (Extended ASCII),256 个字符,用 8 位二进制表示(00000000-11111111 即 0x00-0xFF)。
双字节
当计算机传到了亚洲, 256 个码位就不够用了。于是乎继续扩大二维表,单字节改双字节, 16 位二进制数, 65536 个码位。在不同国家和地区又出现了很多编码,大陆的 GB2312、港台的BIG5、日本的 Shift JIS 等等。
注意 65536 个码位这种说法只是理想情况,由于双字节编码可以是变长的,也就是说同一个编码里面有些字符是单字节表示,有些字符是双字节表示。这样做的好处是, 一方面可以兼容 ASCII,另一方面可以节省存储容量, 代价就是会损失一部分码位。
多字节
Unicode 字符集 可以使用的编码有三种:
- UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储, 长度既固定又可变。
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode 转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符
Unicode 字符集
Unicode 只是字符集, utf-8、 utf-16、 utf-32 才是真正的编码方式。UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode 转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
UTF-8
UTF-8: 是一种变长字符编码,被定义为将代码点编码为 1 至 4 个字节,具体取决于代
码点数值中有效位的数量。
注意: UTF-8 不是编码规范,而是编码方式。下表为 Unicode 值对应的 utf8 需要的字节数量:
Utf8 前缀编码格式
| unicode 编码(16 进制) | UTF-8 字节流(二进制) |
| 000000 - 00007F | 0xxxxxxx ascii 码 |
| 000080 - 0007FF | 110xxxxx 10xxxxxx |
| 000800 - 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 01 0000 - 10 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
范例:计算 Unicode 码使用 utf8 进行表示:
例如:汉字 严的 Unicode 码是 4E25 转换成二进制就是 01001110 00100101 共 15 位,根据上表可知使用 UTF-8 字符编码后占 3 个字节,因此前 3 位是 1,第 4 位(n+1 位)是 0,后面两个字节中每个字节的前两位都是 10,即 1110 xxxx 10 xxxxxx 10xxxxxx。填充进去后就变成了 1110 0100 10 111000 10 100101 共计 24 位占 3 个字节。
GBK 内码、 Unicode 查询: http://www.mytju.com/classcode/tools/encode_gb2312.asp
UTF-16
UFT-16 比较奇葩,它使用 2 个或者 4 个字节来存储。
- 对于 Unicode 编号范围在 0~FFFF 之间的字符, UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。
- 对于 Unicode 编号范围在 10000~10FFFF 之间的字符, UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
| Unicode 编号范围 (十六进制) |
具 体 的 Unicode 编 号 (二进制) |
UTF-16 编码 | 字节 |
| 0000 0000~0000 FFFF | xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx | 2 |
| 0001 0000~0010 FFFF | yyyy yyyy yyxx xxxx xxxx | 110110yy yyyyyyyy 110111xx xxxxxxxx | 4 |
UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
UTF BOM 问题
BOM(Byte Order Mark)字节序(字节顺序的标识),其实就是用大端(BE)还是小端(LE)。
比如 UTF-16BE 和 UTF-16LE:
- UTF-16BE,其后缀是 BE 即 big-endian,大端的意思。大端就是将高位的字节放在低地址表示。
- UTF-16LE,其后缀是 LE 即 little-endian,小端的意思。小端就是将高位的字节放在高地址表示。
- UTF-16,没有指定后缀,即不知道其是大小端,所以其开始的两个字节表示该字节数组是大端还是小端。即 FE FF 表示大端, FF FE 表示小端。
UTF 在文件中的存储。 UTF 格式在文件中总有固定文件头:
| UTF 编码 | Byte Order Mark |
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
注:UTF-8 缺省不带 BOM
小结
程序打开一个文件时怎么识别用的是 UTF-8 还是 UTF-16?
是否有标志做标志,在文件的开头几个字节就是标志.
- EF BB BF 表示 UTF-8
- FE FF 表示 UTF-16BE
- FF FE 表示 UTF-16LE
- 00 00 FE FF 表示 UTF32-BE
- FF FE 00 00 表示 UTF32-LE
注意: 只有 UTF-8 兼容 ASCII, UTF-32 和 UTF-16 都不兼容 ASCII,因为它们没有单字节编码。
查看完整的 Unicode 字符集,以及各种编码方式: https://unicode-table.com/cn/Unicode UTF 编码转换: https://www.qqxiuzi.cn/bianma/Unicode-UTF.php
UTF-8 缺省不带 BOM
UTF-8 中有一字节的情况,这种情况,就没有两端的说法了。至于另外的二,三,四字节情况,以三字节为例,如果你一定要弄出端法,也不是说不可以,比如,小端法就是“小-中-大”,大端法就是“大-中-小”。但现实情况是 UTF-8 仅仅采用了一种端法,就是大端法。
字符集相关命令
file
查看文件的编码方式
file -i chatset.cpp
chatset.cpp: text/x-c++; charset=utf-8
file -i chatset-gbk2312.cpp
chatset-gbk2312.cpp: text/x-c++; charset=iso-8859-1iconv
iconv 命令是用来转换文件的编码方式的,比如它可以将 UTF8 编码的转换成 GB18030的编码,反过来也行。 Linux 下的 iconv 开发库包括 iconv_open,iconv_close,iconv 等 C 函数,可以用来在 C/C++程序中很方便的转换字符编码
语法:
iconv -f encoding [-t encoding] [inputfile]...
选项:
-f encoding :把字符从 encoding 编码开始转换。
-t encoding :把字符转换到 encoding 编码。
-l :列出已知的编码字符集合
-o file :指定输出文件
-c :忽略输出的非法字符
-s :禁止警告信息,但不是错误信息
--verbose :显示进度信息
-f 和-t 所能指定的合法字符在-l 选项的命令里面都列出来了。
案例:
iconv -f UTF-8 -t UTF-8 utf8.txt -o UTF-8.txt
iconv -f UTF-8 -t UTF8 utf8.txt -o UTF8.txt
iconv -f UTF-8 -t UTF-16 UTF-8.txt -o UTF-16.txt
iconv -f UTF-8 -t UTF-16BE UTF-8.txt -o UTF-16BE.txt
iconv -f UTF-8 -t UTF-16LE UTF-8.txt -o UTF-16LE.txt
iconv -f UTF-8 -t UTF16 UTF-8.txt -o UTF16.txt
iconv -f UTF-8 -t UTF16BE UTF-8.txt -o UTF16BE.txt
iconv -f UTF-8 -t UTF16LE UTF-8.txt -o UTF16LE.txt
iconv -f UTF-8 -t UTF-32 UTF-8.txt -o UTF-32.txt
iconv -f UTF-8 -t UTF-32BE UTF-8.txt -o UTF-32BE.txt
iconv -f UTF-8 -t UTF-32LE UTF-8.txt -o UTF-32LE.txt
iconv -f UTF-8 -t GB2312 UTF-8.txt -o GB2312.txt
iconv -f UTF-8 -t GBK UTF-8.txt -o GBK.txt
iconv -f UTF-8 -t ISO-8859-1 UTF-8.txt -o ISO-8859-1.txt字符集转换编程
包含头文件
#include
函数: iconv_t iconv_open (const char* tocode, const char* fromcode);
范例: iconv_t cd = iconv_open(“UTF-8”, “UTF-16”);
函数: int iconv_close (iconv_t cd);
范例: iconv_close(cd);
函数: size_t iconv (iconv_t cd, const char* * inbuf, size_t * inbytesleft, char* * outbuf,size_t * outbytesleft);
返回值:返回-1 则说明出现异常,错误码
E2BIG: outbuf 没有足够的空间
EILSEQ: 遇到无效的多字节序列
EINVAL: 遇到不完整的多字节序列
压缩原理
压缩原理其实很简单,就是找出那些重复出现的字符串,然后用更短的符号代替,从而达到缩短字符串的目的。比如,有一篇文章大量使用"中华人民共和国"这个词语,我们用"中国"代替,就缩短了 5 个字符,如果用"华"代替,就缩短了 6 个字符。事实上,只要保证对应关系,可以用任意字符代替那些重复出现的字符串。
本质上,所谓"压缩"就是找出文件内容的概率分布,将那些出现概率高的部分代替成 更 短 的 形 式 。 所 以 , 内 容 越 是 重 复 的 文 件 , 就 可 以 压 缩 地 越 小 。 比 如 ,"ABABABABABABAB"可以压缩成"7AB"。
相应地,如果内容毫无重复, 就很难压缩。极端情况就是,遇到那些均匀分布的随机字符串,往往连一个字符都压缩不了。比如, 任意排列的 10 个阿拉伯数字(5271839406),就是无法压缩的;再比如,无理数(比如 π)也很难压缩。
压缩极限-香农极限
∑ log2(1/pn) / n
= log2(1/p1)/n + log2(1/p2)/n + ... + log2(1/pn)/n
(1) 下面是一个例子。假定有两个文件都包含 1024 个符号,在 ASCII 码的情况下,它们的长度是相等的,都是 1KB。甲文件的内容 50%是 a, 30%b, 20%是 c,文本里面只有abc,则平均每个符号要占用 1.49 个二进制位。
0.5*log2(1/0.5) + 0.3*log2(1/0.3) + 0.2*log2(1/0.2) = 1.49
(2) 比如每个字节的数值概率是 0~255,均匀分布每个数值出现的概率 1/256,如果一段文字的字节数值是平均分布,则 pn = 1/256,计算出极限为 8。
Log21/(1/256) = Log2256 = 8
信息熵
数据为何是可以压缩的,因为数据都会表现出一定的特性,称为熵。绝大多数的数据所表现出来的容量往往大于其熵所建议的最佳容量。比如所有的数据都会有一定的冗余性,我们可以把冗余的数据采用更少的位对频繁出现的字符进行标记,也可以基于数据的一些特性基于字典编码,代替重复多余的短语。
压缩算法
-
Deflate 压缩算法
-
LZ77 算法原理
-
Huffman 算法原理
Deflate 压缩算法
deflate 是 zip 压缩文件的默认算法。 其实 deflate 现在不光用在 zip 文件中, 在 7z,xz 等其他的压缩文件中都用。 实际上 deflate 只是一种压缩数据流的算法。 任何需要流式压缩的地方都可以用。deflate 算法下的压缩器有三种压缩模型:
- 不压缩数据, 对于已经压缩过的数据, 这是一个明智的选择。 这样的数据会会稍稍增加, 但是会小于在其上再应用一种压缩算法。
- 压缩, 先用 LZ77, 然后用 huffman 编码。 在这个模型中压缩的树是 Deflate 规范规定定义的, 所以不需要额外的空间来存储这个树。
- 压缩, 先用 LZ77, 然后用 huffman 编码。 压缩树是由压缩器生成的, 并与数据一起存储。数据被分割成不同的块, 每个块使用单一的压缩模式。 如过压缩器要在这三种压缩模式中相互切换, 必须先结束当前的块, 重新开始一个新的块
LZ77 算法原理
LZ77 压缩算法采用字典的方式进行压缩,是一个简单但十分高效的数据压缩算法。其方式就是把数据中一些可以组织成短语(最长字符)的字符加入字典,然后再有相同字符出现采用标记来代替字典中的短语,如此通过标记代替多数重复出现的方式以进行压缩。要理解这种算法, 需先了解 3 个关键词:短语字典,滑动窗口和向前缓冲区。
关键词术语
1. 前向缓冲区
每次读取数据的时候, 先把一部分数据预载入前向缓冲区。为移入滑动窗口做准备
2. 滑动窗口
一旦数据通过缓冲区,那么它将移动到滑动窗口中,并变成字典的一部分。 滑动窗口需要预设一个定值。
3. 短语字典
从字符序列 S1 … Sn,组成 n 个短语。比如字符(A,B,D) ,可以组合的短语为{(A),(A,B),(A,B,D),(B),(B,D),(D)},如果这些字符在滑动窗口里面,就可以记为当前的短语字典,因为滑动窗口不断的向前滑动,所以短语字典也是不断的变化。
LZ77 的主要算法逻辑就是, 先通过前向缓冲区预读数据,然后再向滑动窗口移入(滑动窗口有一定的长度),不断的寻找能与字典中短语匹配的最长短语,然后通过标记符标记。我们还以字符 ABD 为例子,看如下图: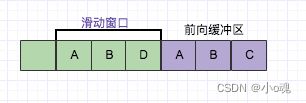
目前从前向缓冲区中可以和滑动窗口中可以匹配的最长短语就是(A,B) ,然后向前移动的时候再次遇到(A,B)的时候采用标记符代替。
压缩详细:
当压缩数据的时候,前向缓冲区与移动窗口之间在做短语匹配的是后会存在 2 种情况:
(1) 找不到匹配时: 将未匹配的符号编码成符号标记(多数都是字符本身)
(2) 找到匹配时: 将其最长的匹配编码成短语标记。
短语标记包含三部分信息:
(1) 滑动窗口中的偏移量(从匹配开始的地方计算) ;
(2) 匹配中的符号个数;
(3) 匹配结束后的前向缓冲区中的第一个符号)。
一旦把 n 个符号编码并生成相应的标记,就将这 n 个符号从滑动窗口的一端移出,
并用前向缓冲区中同样数量的符号来代替它们,如此,滑动窗口中始终有最新的短语。
我们采用图例来看:
1、开始
2、滑动窗口中没有数据,所以没有匹配到短语,将字符 A 标记为 A

3、滑动窗口中有 A,没有从缓冲区中字符(BABC)中匹配到短语,依然把 B 标记为B

4、缓冲区字符(ABCB)在滑动窗口的位移 6 位置找到 AB,成功匹配到短语 AB,将AB 编码为(6,2,C),之所以是 6, 是因为窗口的 A 在滑动窗口的索引[6]位置。

5、缓冲区字符(BABA)在滑动窗口位移 4 的位置匹配到短语 BAB,将 BAB 编码为(4,3,A),之所以偏移为 4 是因为

6、缓冲区字符(BCAD)在滑动窗口位移 2 的位置匹配到短语 BC,将 BC 编码为(2,2,A)

7、缓冲区字符 D,在滑动窗口中没有找到匹配短语,标记为 D

8、缓冲区中没有数据进入了,结束
解压详细:
解压类似于压缩的逆向过程,通过解码标记和保持滑动窗口中的符号来更新解压数据。
当解码字符标记:将标记编码成字符拷贝到滑动窗口中
解码短语标记:在滑动窗口中查找相应偏移量,同时找到指定长短的短语进行替换。
我们还是采用图例来看下:
1、开始
2、符号标记 A 解码
3、符号标记 B 解码
4、短语标记(6,2,C)解码
是根据 3 中的索引[6]开始,得到 AB,就是重复 AB 再加入上 C,就成了 ABABC,并且滑动窗口滑到最右边的位置。
5、短语标记(4,3,A)解码
6、短语标记(2,2,A)解码

7、符号标记 D 解码
优缺点
大多数情况下 LZ77 压缩算法的压缩比相当高,当然了也和你选择滑动窗口大小,以及前向缓冲区大小,以及数据熵有关系。 其压缩过程是比较耗时的,因为要花费很多时间寻找滑动窗口中的短语匹配,不过解压过程会很快,因为每个标记都明确告知在哪个位置可以读取了。
Huffman 算法原理
前缀码
在一个字符集中,任何一个字符的编码都不是另一个字符编码的前缀,即前缀码。例如,有两个码字 111 与 1111,那么这两个码字就不符合前缀码的规则,因为 111 是1111 的前缀。放到二叉树里来讲,只用叶子节点编码的码字才是前缀码,如果同时使用中间节点和叶子节点编码,那结果就是前缀码。因为压缩中经过编码的码字全部是前缀码,所以在对照码表解压的时候,碰到哪个码字就是哪个码字,不用担心出现某个字符的编码是另一个字符的编码的前缀的情况,该意识一定要具备。
关于前缀码,下面一段话摘自《算法导论》:“前缀码的作用是简化解码过程。由于没有码字是其他码字的前缀,编码文件的开始码字是无歧义的。我们可以简单的识别出开始码字,将其转换会原字符,然后对编码文件剩余部分重复这种解码过程。
1111111 ? 111 1111 ? 1111 111
哈夫曼编码
哈夫曼设计了一个贪心算法来构造最优前缀码,被称为哈夫曼编码(Huffman code),其正确性证明依赖于贪心选择性质和最优子结构。哈夫曼编码可以很有效的压缩数据,具体压缩率依赖于数据本身的特性。这里我们先介绍几个概念: 码字、码字长度、定长编码与变长编码。
每个字符可以用一个唯一的二进制串表示,这个二进制串称为这个字符的码字,这个二进制串的长度称为这个码字的码字长度。码字长度固定就是定长编码,码字长度不同则为变长编码。变长编码可以达到比定长编码好得多的压缩率,其思想是赋予高频字符(出现频率高的字符)短(码字长度较短)码字,赋予低频字符长码字。例如,我们用 ASCII 字符编辑一个文本文档,不论字符在整个文档中出现的频率,每个字符都要占用一个字节;如果我们使用变长编码的方式,每个字符因在整个文档中的出现频率不同导致码字长度不同,有的可能占用一个字节,而有的可能只占用一比特,这个时候,整个文档占用空间就会比较小了。当然,如果这个文本文档相当大,导致每个字符的出现频率基本相同, 那么此时所谓变长编码在压缩方面的优势就基本不存在了(这点要十分明确,这是为什么压缩要分块的原因之一,后续源码分析会详细讲解)。
哈夫曼编码会自底向上构造出一棵对应最优编码的二叉树,我们使用下面这个例子来说明哈夫曼树的构造过程。首先,我们已知在某个文本中有如下字符及其出现频率,
| 字符 | a | b | c | d | e | f |
| 出现频率 | 45 | 13 | 12 | 16 | 9 | 5 |
构造过程如下图所示:
图 1 到图 6 列除了整个哈夫曼树构造过程中的每个步骤。在一开始,每个字符都已经按照出现频率大小排好顺序,在后续的步骤中,每次都将频率最低的两棵树合并,然后用合并后的结果再次排序(注意,排序不是目的,目的是找到这时出现频率最低的两项,以便下次合并。 gzip 源码中并没有专门去“排序”,而是使用专门的数据结构把频率最低的两项找到即可)。叶子节点用矩形表示,每个叶子节点包含一个字符及其频率。中间节点用圆圈表示,包含其孩子节点的频率之和。中间节点指向左孩子的边标记为 0,指向右孩子的边标记为 1。一个字符的码字对应从根到其叶节点的路径上的边的标签序列。图 1 为初始集合,有六个节点,每个节点对应一个字符;图 2 到图 5 为中间步骤,图 6 为最终哈夫曼树。 此时每个字符的编码都是前缀码。
deflate 采用的改进版 LZ77 算法
三个字节以上的重复串才进行编码,否则不进行编码:
现在来说明一下,为什么最小匹配为 3 个字节。这是由于, gzip 中, <匹配长度,到匹配串开头的距离>对中, "匹配长度"的范围为 3-258,也就是 256 种可能值,需要 8bit来保存。 "到匹配串开头的距离"的范围为 0-32K,需要 15bit 来保存。所以一个<匹配长度,到匹配串开头的距离>对需要 23 位,差一位 3 个字节。如果匹配串小于 3 个字节的话,使用<匹配长度,到匹配串开头的距离>对进行替换,不但没有压缩,反而还会增大。所以保存<匹配长度,到匹配串开头的距离>对所需要的位数,决定了最小匹配长度至少要为 3 个字节。
现在来说明一下,为什么最小匹配为 3 个字节。这是由于, gzip 中, <匹配长度,到匹配串开头的距离>对中, "匹配长度"的范围为 3-258,也就是 256 种可能值,需要 8bit来保存。 "到匹配串开头的距离"的范围为 0-32K,需要 15bit 来保存。所以一个<匹配长度,到匹配串开头的距离>对需要 23 位,差一位 3 个字节。如果匹配串小于 3 个字节的话,使用<匹配长度,到匹配串开头的距离>对进行替换,不但没有压缩,反而还会增大。所以保存<匹配长度,到匹配串开头的距离>对所需要的位数,决定了最小匹配长度至少要为 3 个字节。
deflate 无损压缩解压算法(先 LZ77 压缩,然后 huaffman 编码):
一旦原始数据被转换成了字符和长度距离对组成的串,这些数据必须由 huffman
编码表示。
deflate 中的 huffman 编码:
对 LZ77 得到的压缩后结果,需要统计字符生成编码表 huffmantree(指示每个编码代表什么字符) ,根据码表对内容进行编码,具体的压缩大小在于精细分配结构体的位域来实现 Huffman 编码的压缩效果的。
编码表 huffmantree 和编码后的 data 都一起放置在文件中。
deflate 中的解压:
读取二进制文件,构建 huffmantree 表,读取数据根据 huffmantree 生成字符(这些字符是符合 LZ77 算法的)。
用 LZ77 解码,这个时候应该需要对窗口生成哈希表(数组+链表);对解压的数据,进行搜索匹配拷贝替换为相应的串即可。
gzip 格式分析
deflate(RFC1951):一种压缩算法,使用 LZ77 和哈弗曼进行编码;
zlib(RFC1950):一种格式,是对 deflate 进行了简单的封装,他也是一个实现库(delphi中有 zlib,zlibex)
gzip(RFC1952):一种格式,也是对 deflate 进行的封装。https://www.rfc-editor.org/rfc/rfc1952.txt
gzip = gzip 头 + deflate 编码的实际内容 + gzip 尾
zlib = zlib 头 + deflate 编码的实际内容 + zlib 尾
GZIP 本身只是一种文件格式,其内部通常采用 DEFLATE 数据格式,而 DEFLATE 采
用 LZ77 压缩算法来压缩数据。
GZIP 文件由 1 到多个“块”组成,实际上通常只有 1 块。每个块包含头、数据和尾三部分。块的概貌如下:
头部分
ID1 与 ID2:各 1 字节。固定值, ID1 = 31 (0x1F), ID2 = 139(0x8B),指示 GZIP 格式。 CM:1 字节。压缩方法。目前只有一种: CM = 8,指示 DEFLATE 方法。 FLG: 1 字节。标志。
bit 0 FTEXT - 指示文本数据
bit 1 FHCRC - 指示存在 CRC16 头校验字段
bit 2 FEXTRA - 指示存在可选项字段
bit 3 FNAME - 指示存在原文件名字段
bit 4 FCOMMENT - 指示存在注释字段
bit 5-7 保留
MTIME: 4 字节。 更改时间。 UINX 格式。 XFL: 1 字节。附加的标志。当 CM = 8 时,XFL = 2 - 最大压缩但最慢的算法; XFL = 4 - 最快但最小压缩的算法 OS: 1 字节。操作系统,确切地说应该是文件系统。有下列定义:
0 - FAT 文件系统 (MS-DOS, OS/2, NT/Win32)
1 - Amiga
2 - VMS/OpenVMS
3 - Unix
4 - VM/CMS
5 - Atari TOS
6 - HPFS 文件系统 (OS/2, NT)
7 - Macintosh
8 - Z-System
9 - CP/M
10 - TOPS-20
11 - NTFS 文件系统 (NT)
12 - QDOS
13 - Acorn RISCOS
255 - 未知
额外的头字段:
(若 FLG.FEXTRA = 1)
+---+---+---+---+===============//================+
|SI1|SI2| XLEN | 长度为 XLEN 字节的可选项 |
+---+---+---+---+===============//================+
(若 FLG.FNAME = 1)
+=======================//========================+
| 原文件名(以 NULL 结尾) |
+=======================//========================+
(若 FLG.FCOMMENT = 1)
+=======================//========================+
| 注释文字(只能使用 iso-8859-1 字符,以 NULL 结尾) |
+=======================//========================+
(若 FLG.FHCRC = 1)
+---+---+
| CRC16 |
+---+---+
存在额外的可选项时, SI1 与 SI2 指示可选项 ID, XLEN 指示可选项字节数。如 SI1= 0x41 ('A'), SI2 = 0x70 ('P'),表示可选项是 Apollo 文件格式的额外数据。
数据部分
DEFLATE 数据格式,包含一系列子数据块。子块概貌如下:
+......+......+......+=============//============+
|BFINAL| BTYPE | 数据 |
+......+......+......+=============//============+
BFINAL: 1 比特。 0 - 还有后续子块; 1 - 该子块是最后一块。 BTYPE: 2 比特。 00 - 不压缩; 01 - 静态 Huffman 编码压缩; 10 - 动态 Huffman 编码压缩; 11 - 保留。
各种情形的处理过程,请参考后面列出的 RFC 文档。
尾部分
CRC32: 4 字节。原始(未压缩)数据的 32 位校验和。 ISIZE: 4 字节。原始(未压缩)数据的长度的低 32 位。
GZIP 中字节排列顺序是 LSB 方式,即 Little-Endian,与 ZLIB 中的相反。
zlib 库 API 分析
1.下载源码包
下载 http://www.zlib.net/,选择 zlib-1.2.11.tar.gz
(1)下载
wget http://www.zlib.net/zlib-1.2.11.tar.gz
(2)解压
tar -zxvf zlib-1.2.11.tar.gz
(3)进入目录
cd zlib-1.2.11
2. 编译
(1)配置
./configure
(2)编译
make
(3)检查,要全部为 yes
make check
(4)安装
sudo make install
基础数据结构
typedef struct z_stream_s {
z_const Bytef *next_in; /* next input byte */
uInt avail_in; /* number of bytes available at next_in */
uLong total_in; /* total number of input bytes read so far */
Bytef *next_out; /* next output byte will go here */
uInt avail_out; /* remaining free space at next_out */
uLong total_out; /* total number of bytes output so far */
z_const char *msg; /* last error message, NULL if no error */
struct internal_state FAR *state; /* not visible by applications */
alloc_func zalloc; /* used to allocate the internal state */
free_func zfree; /* used to free the internal state */
voidpf opaque; /* private data object passed to zalloc and zfree */
int data_type; /* best guess about the data type: binary or text
for deflate, or the decoding state for inflate */
uLong adler; /* Adler-32 or CRC-
32 value of the uncompressed data */
uLong reserved; /* reserved for future use */
} z_stream;
/*
gzip header information passed to and from zlib routines. See RFC 1952
for more details on the meanings of these fields.
*/
typedef struct gz_header_s {
int text; /* true if compressed data believed to be text */
uLong time; /* modification time */
int xflags; /* extra flags (not used when writing a gzip file) */
int os; /* operating system */
Bytef *extra; /* pointer to extra field or Z_NULL if none */
uInt extra_len; /* extra field length (valid if extra != Z_NULL) */
uInt extra_max; /* space at extra (only when reading header) */
Bytef *name; /* pointer to zero-terminated file name or Z_NULL */
uInt name_max; /* space at name (only when reading header) */
Bytef *comment; /* pointer to zero-terminated comment or Z_NULL */
uInt comm_max; /* space at comment (only when reading header) */
int hcrc; /* true if there was or will be a header crc */
int done; /* true when done reading gzip header (not used
when writing a gzip file) */
} gz_header;常用的函数
压缩
deflateInit: 参数比较少,里面的实现其实是调用的 deflateInit2
deflateInit2: 压缩初始化的基础函数,有很多参数,下面会重点介绍。
deflate: 压缩函数。
deflateEnd: 压缩完成以后,释放空间,但是注意,仅仅是释放 deflateInit 中申请的空间,自己申请的空间还是需要自己释放。
compress: 全部附加选项默认压缩,内部调用 compress2。
compress2: 带 level 的压缩方式。
解压
inflateInit: 解压初始化函数,内部调用的 inflateInit2。
inflateInit2: 解压初始化的基础函数,后面重点介绍。
infalte: 解压函数。
inflateEnd: 同 deflateEnd 作用类似。
uncompress: 解压缩。
nginx 优化之 gzip 压缩提升网站速度
注: 图片、视频、音频等二进制文件没有必要进行压缩。
配置:
# 开启 gzip
gzip on;
# 启用 gzip 压缩的最小文件,小于设置值的文件将不会压缩
gzip_min_length 1k;
# gzip 压缩级别, 1-9,数字越大压缩的越好,也越占用 CPU 时间,后面会有详细说明
gzip_comp_level 1;
# 进行压缩的文件类型。 javascript 有多种形式。其中的值可以在 mime.types 文件中找到。
gzip_types text/plain application/javascript application/x-javascript text/css
application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png
application/vnd.ms-fontobject font/ttf font/opentype font/x-woff image/svg+xml;
# 是否在 http header 中添加 Vary: Accept-Encoding,建议开启
gzip_vary on;
# 禁用 IE 6 gzip
gzip_disable "MSIE [1-6]\.";
# 设置压缩所需要的缓冲区大小
gzip_buffers 32 4k;
# 设置 gzip 压缩针对的 HTTP 协议版本,没做负载的可以不用
# gzip_http_version 1.0;
# 开启缓存
location ~* ^.+\.(ico|gif|jpg|jpeg|png)$ {
access_log off;
expires 2d;
}
location ~* ^.+\.(css|js|txt|xml|swf|wav)$ {
access_log off;
expires 24h;
}
location ~* ^.+\.(html|htm)$ {
expires 1h;
}
location ~* ^.+\.(eot|ttf|otf|woff|svg)$ {
access_log off;
expires max;
}
# 格式
# expires 30s;
# expires 30m;
# expires 2h;
# expires 30d;说明:
gzip on
打开或关闭 gzip。
Syntax: gzip on | off;
Default: gzip off;
Context: http, server, location, if in locationgzip_buffers
设置用于处理请求压缩的缓冲区数量和大小。比如 32 4K 表示按照内存页( one memory page)大小以 4K 为单位(即一个系统中内存页为 K),申请 32 倍的内存空间。建议此项不设置,使用默认值。
Syntax: gzip_buffers number size;
Default: gzip_buffers 32 4k|16 8k;
Context: http, server, locationgzip_comp_level
设置 gzip 压缩级别,级别越底压缩速度越快文件压缩比越小,反之速度越慢文件压缩比越大。
Syntax: gzip_comp_level level;
Default: gzip_comp_level 1;
Context: http, server, locationgzip_disable
通过表达式,表明哪些 UA 头不使用 gzip 压缩。
Syntax: gzip_disable regex ...;
Default: —
Context: http, server, location
This directive appeared in version 0.6.23.gzip_min_length
正整数,单位为字节,也可用 k 表示千字节,比如写成 1024 与 1k 都可以,效果是一样的,表示当资源大于 1k 时才进行压缩,资源大小取响应头中的 Content-Length 进行比较,经测试如果响应头不存在 Content_length 信息,该限制参数对于这个响应包是不起作用的;另外此处参数值不建议设的太小,因为设的太小,一些本来很小的文件经过压缩后反而变大了,官网没有给出建议值,在此建议 1k 起,因为小于 1k 的也没必要压缩,并根据实际情况来调整设定。
Syntax: gzip_min_length length;
Default: gzip_min_length 20;
Context: http, server, locationgzip_http_version
用于识别 http 协议的版本,早期的浏览器不支持 gzip 压缩,用户会看到乱码,所以为了支持前期版本加了此选项。默认在 http/1.0 的协议下不开启 gzip 压缩。
Syntax: gzip_http_version 1.0 | 1.1;
Default: gzip_http_version 1.1;
Context: http, server, location在应用服务器前,如果还有一层 Nginx 的集群作为负载均衡,在这一层上,若果没有开启 gzip。如果我们使用了 proxy_pass 进行反向代理,那么 nginx 和后端的 upstream server之间默认是用 HTTP/1.0 协议通信的。如果我们的 Cache Server 也是 nginx,而前端的 nginx 没有开启 gzip。同时,我们后端的 nginx 上没有设置 gzip_http_version 为 1.0,那么 Cache 的url 将不会进行 gzip 压缩
gzip_proxied
Nginx 做为反向代理的时候启用:
- off – 关闭所有的代理结果数据压缩
- expired – 如果 header 中包含 "Expires" 头信息,启用压缩
- no-cache – 如果 header 中包含 "Cache-Control:no-cache" 头信息,启用压缩
- no-store – 如果 header 中包含 "Cache-Control:no-store" 头信息,启用压缩
- private – 如果 header 中包含 "Cache-Control:private" 头信息,启用压缩
- no_last_modified – 启用压缩,如果 header 中包含 "Last_Modified" 头信息,启用压缩
- no_etag – 启用压缩,如果 header 中包含 "ETag" 头信息,启用压缩
- auth – 启用压缩,如果 header 中包含 "Authorization" 头信息,启用压缩
- any – 无条件压缩所有结果数据
Syntax: gzip_proxied off | expired | no-cache | no-store | private | no_last_modified | no_etag | auth | any ...;
Default: gzip_proxied off;
Context: http, server, locationgzip_types
设置需要压缩的 MIME 类型,如果不在设置类型范围内的请求不进行压缩。 匹配 MIME 类型
进行压缩,(无论是否指定) "text/html"类型总是会被压缩的。
Syntax: gzip_types mime-type ...;
Default: gzip_types text/html;
Context: http, server, locationgzip_vary
增加响应头 "Vary: Accept-Encoding"
告诉接收方发送的数据经过了压缩处理,开启后的效果是在响应头部添加AcceptEncoding:gzip,这对于本身不支持 gzip 压缩的客户端浏览器有用。
Syntax: gzip_vary on | off;
Default: gzip_vary off;
Context: http, server, location