PostgreSQL 工具的相关介绍
1.1 psql工具
psql是PostgreSQL中的一个命令行交互式客户端工具,类似 Oracle中的命令行工具sqlplus,它允许用户交互地键入SQL语句或命 令,然后将其发送给PostgreSQL服务器,再显示SQL语句或命令的结 果。
1.2 psql的简单使用
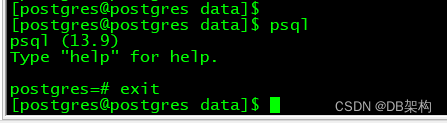
使用“psql -l”命 令可以查看数据库:
[postgres@postgres data]$ psql -l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
[postgres@postgres data]$ 也可以进入psql的命令交互输入模式使用“\l”命令查看有哪些 数据库,与使用上面的“psql -l”命令得到的结果是相同的,示例如 下:
[postgres@postgres data]$
[postgres@postgres data]$ su - postgres
Password:
[postgres@postgres ~]$ psql
psql (13.9)
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
postgres=# 使用“\d”命令查看表的示例如下:
postgres=#
postgres=# create table t(id int primary key,name
postgres(# varchar(40));
CREATE TABLE
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------+-------+----------
public | class | table | postgres
public | score | table | postgres
public | student | table | postgres
public | student_bak | table | postgres
public | t | table | postgres
public | test1 | table | postgres
(6 rows)
postgres=# 还可以使用SQL语句“CREATE DATABASE×××”创建用户数据 库,下面是创建testdb数据库的SQL语句:
postgres=# CREATE DATABASE testdb;
CREATE DATABASE
postgres=然后使用“\c testdb”命令连接到testdb数据库上:
postgres=# CREATE DATABASE testdb;
CREATE DATABASE
postgres=# \c testdb;
You are now connected to database "testdb" as user "postgres".
testdb=# 下面介绍psql连接数据库的常用的方法,命令格式如下:
psql -h -p <端口> [数据库名称] [用户名称]
[postgres@postgres ~]$ psql -h 192.168.8.133 -p 5432 testdb postgres
Password for user postgres:
psql (13.9)
Type "help" for help.
testdb=#其中-h指定要连接的数据库所在的主机名或IP地址,-p指定连接 的数据库端口,最后两个参数分别是数据库名和用户名。
这些连接参数也可以通过环境变量指定,示例如下:
export PGDATABASE=testdb
export PGHOST=192.168.56.11
export PGPORT=5432
export PGUSER=postgres
然后运行psql,其运行结果与“psql -h 192.168.56.11 -p 5432 testdb postgres”的运行结果相同。
testdb=# exit
[postgres@postgres ~]$ export PGDATABASE=testdb
[postgres@postgres ~]$ export PGHOST=192.168.8.133
[postgres@postgres ~]$ export PGPORT=5432
[postgres@postgres ~]$ export PGUSER=postgres
[postgres@postgres ~]$ psql
Password for user postgres:
psql (13.9)
Type "help" for help.
testdb=# 1.3 psql 常用命令
1.3.1 “\h”命令
使用psql工具需要记住的第一个命令是“\h”,该命令用于查询 SQL语句的语法,如我们不知道如何用SQL语句创建用户,就可以执行 “\h create user”命令来查询:
testdb-# \c postgres
You are now connected to database "postgres" as user "postgres".
postgres-#
postgres-# \h create user
Command: CREATE USER
Description: define a new database role
Syntax:
CREATE USER name [ [ WITH ] option [ ... ] ]
where option can be:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| BYPASSRLS | NOBYPASSRLS
| CONNECTION LIMIT connlimit
| [ ENCRYPTED ] PASSWORD 'password' | PASSWORD NULL
| VALID UNTIL 'timestamp'
| IN ROLE role_name [, ...]
| IN GROUP role_name [, ...]
| ROLE role_name [, ...]
| ADMIN role_name [, ...]
| USER role_name [, ...]
| SYSID uid
URL: https://www.postgresql.org/docs/13/sql-createuser.html
postgres-# 使用“\h”命令可以查看各种SQL语句的语法,非常方便.
1.3.2 “\d”命令
“\d”命令的格式如下:
\d [ pattern ]
\d [ pattern ]+该命令将显示每个匹配“pattern”(表、视图、索引、序列)的 信息,包括对象中所有的列、各列的数据类型、表空间(如果不是默 认的)和所有特殊属性(诸如“NOT NULL”或默认值等)等。唯一约 束相关的索引、规则、约束、触发器也同样会显示出来。如果关系是 一个视图,还会显示视图的定义(“匹配模式”将在下面定义)。下 面来看看该命令的具体用法。
1)如果“\d”命令后什么都不带,将列出当前数据库中的所有 表,示例如下:
postgres-#
postgres-# \d
List of relations
Schema | Name | Type | Owner
--------+-------------+-------+----------
public | class | table | postgres
public | score | table | postgres
public | student | table | postgres
public | student_bak | table | postgres
public | t | table | postgres
public | test1 | table | postgres
(6 rows)
postgres-# 2)“\d”命令后面跟一个表名,表示显示这个表的结构定义,示 例如下:
postgres-# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
id | integer | | not null |
name | character varying(40) | | |
Indexes:
"t_pkey" PRIMARY KEY, btree (id)
postgres-# 3)“\d”命令也可以用于显示索引信息,示例如下:
postgres-# \d t_pkey
Index "public.t_pkey"
Column | Type | Key? | Definition
--------+---------+------+------------
id | integer | yes | id
primary key, btree, for table "public.t"
postgres-# 4)“\d”命令后面的表名或索引名中也可以使用通配符,如 “*”或“?”等,示例如下:
postgres-#
postgres-# \d test?
Table "public.test1"
Column | Type | Collation | Nullable | Default
------------+------------------------+-----------+----------+---------
sidno | integer | | |
serialname | character varying(100) | | |
Tablespace: "hrd"
postgres-# \d stu*
Table "public.student"
Column | Type | Collation | Nullable | Default
--------------+-----------------------+-----------+----------+---------
no | integer | | not null |
student_name | character varying(40) | | |
age | integer | | |
class_no | integer | | |
Indexes:
"student_pkey" PRIMARY KEY, btree (no)
Table "public.student_bak"
Column | Type | Collation | Nullable | Default
--------------+-----------------------+-----------+----------+---------
no | integer | | not null |
student_name | character varying(40) | | |
age | integer | | |
class_no | integer | | |
Indexes:
"student_bak_pkey" PRIMARY KEY, btree (no)
Index "public.student_bak_pkey"
Column | Type | Key? | Definition
--------+---------+------+------------
no | integer | yes | no
primary key, btree, for table "public.student_bak"
Index "public.student_pkey"
Column | Type | Key? | Definition
--------+---------+------+------------
no | integer | yes | no
primary key, btree, for table "public.student"
postgres-# 5)使用“\d+”命令可以显示比“\d”命令的执行结果更详细的 信息,除了前面介绍的信息,还会显示所有与表的列关联的注释,以 及表中出现的OID。示例如下:
postgres-# \d+ t
Table "public.t"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | character varying(40) | | | | extended | |
Indexes:
"t_pkey" PRIMARY KEY, btree (id)
Access method: heap
postgres-#6)匹配不同对象类型的“\d”命令如下:
·如果只想显示匹配的表,可以使用“\dt”命令。
·如果只想显示索引,可以使用“\di”命令。
·如果只想显示序列,可以使用“\ds”命令。
·如果只想显示视图,可以使用“\dv”命令。
·如果想显示函数,可以使用“\df”命令。
7)如果想显示执行SQL语句的时间,可以用“\timing”命令,示 例如下:
postgres-# \timing on
Timing is on.
postgres-#
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------+-------+----------
public | class | table | postgres
public | score | table | postgres
public | student | table | postgres
public | student_bak | table | postgres
public | t | table | postgres
public | test1 | table | postgres
(6 rows)
postgres=# select count(*) from t;
count
-------
0
(1 row)
Time: 0.928 ms
postgres=# 8)要想列出所有的schema,可以使用“\dn”命令,示例如下:
postgres=# \dn
List of schemas
Name | Owner
--------+----------
public | postgres
(1 row)
postgres=#9)要想显示所有的表空间,可以用“\db”命令,示例如下:
postgres=#
postgres=# \db
List of tablespaces
Name | Owner | Location
------------+----------+----------------------
hrd | postgres | /opt/user_tablespace
pg_default | postgres |
pg_global | postgres |
(3 rows)
postgres=# 实际上,PostgreSQL中的表空间对应一个目录,放在这个表空间 中的表,就是把表的数据文件放到该表空间下。
10)要想列出数据库中的所有角色或用户,可以使用“\du”或 “\dg”命令,示例如下
postgres=# \dg
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------------------+-----------
malcolm | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
test1 | | {}
postgres=# \du
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------------------+-----------
malcolm | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
test1 | | {}
postgres=# “\du”和“\dg”命令等价。原因是,在PostgreSQL数据库中, 用户和角色是不分的。
11)“\dp”或“\z”命令用于显示表的权限分配情况,示例如 下:
postgres=#
postgres=# \dp t
Access privileges
Schema | Name | Type | Access privileges | Column privileges | Policies
--------+------+-------+-------------------+-------------------+----------
public | t | table | | |
(1 row)
postgres=#1.3.3 指定客户端字符集的命令
当客户端的字符编码与服务器不一致时,可能会出现乱码,可以 使用“\encoding”命令指定客户端的字符编码,如使用“\encoding gbk;”命令设置客户端的字符编码为“gbk”;使用“\encoding utf8;”命令设置客户端的字符编码为“utf8”。
1.3.4 格式化输出的\pset命令
“\pset”命令的语法如下:
\pset [option [value] ]
根据命令后面“option”和“value”的不同可以设置很多种不同 的输出格式,这里只介绍一些常用的用法。
默认情况下,psql中执行SQL语句后输出的内容是只有内边框的表 格:
postgres=# select * from class;
no | class_name
----+------------
1 | 初二(1)班
2 | 初二(2)班
3 | 初二(3)班
4 | 初二(4)班
(4 rows)
postgres=#如果要像MySQL中一样输出带有内外边框的表格内容,可以用命令 “\pset boder 2”来实现,示例如下:
postgres=# \pset border 2
Border style is 2.
postgres=# select * from class;
+----+------------+
| no | class_name |
+----+------------+
| 1 | 初二(1)班 |
| 2 | 初二(2)班 |
| 3 | 初二(3)班 |
| 4 | 初二(4)班 |
+----+------------+
(4 rows)
postgres=#当然也可以用“\pset boder 0”命令输出不带任何边框的内容, 示例如下:
postgres=# \pset border 0
Border style is 0.
postgres=# select * from class;
no class_name
-- ----------
1 初二(1)班
2 初二(2)班
3 初二(3)班
4 初二(4)班
(4 rows)
postgres=# 综上所述,“\pset”命令设置边框的用法如下。
·\pset border 0:表示输出内容无边框。
·\pset border 1:表示输出内容只有内边框。
·\pset border 2:表示输出内容内外都有边框。
psql中默认的输出格式是“\pset border 1”。
不管输出的内容加不加边框,内容本身都是对齐的,是为增强数 据的可读性而专门格式化过的,而有时我们需要把命令的结果输出为 其他程序可以读取的文件,如以逗号分隔或以Tab分隔的文本文件,这 时就需要用到“\pset format unaligned”命令了,示例如下:
postgres=#
postgres=# \pset format unaligned
Output format is unaligned.
postgres=# select * from class;
no|class_name
1|初二(1)班
2|初二(2)班
3|初二(3)班
4|初二(4)班
(4 rows)
postgres=# 默认分隔符是“|”,我们可以用命令“\pset fieldsep”来设置 分隔符,如改成Tab分隔符的方法如下:
postgres=#
postgres=# \pset fieldsep '\t'
Field separator is " ".
postgres=# select * from class;
no class_name
1 初二(1)班
2 初二(2)班
3 初二(3)班
4 初二(4)班
(4 rows)
postgres=#实际使用时,我们需要把SQL命令输出到一个文件中,而不是屏幕 上,这时可以用“\o”命令指定一个文件,然后再执行上面的SQL命 令,执行结果就会输出到这个文件中,示例如下:
1.3.5 "\x"命令
[pgadmin@postgres ~]$ su - postgres
Password:
[postgres@postgres ~]$ psql
psql (13.9)
Type "help" for help.
postgres=#
postgres=# \x
Expanded display is on.
postgres=# select * from pg_stat_activity;
-[ RECORD 1 ]----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-----------------------------
datid |
datname |
pid | 114863
leader_pid |
usesysid |
usename |
application_name |
client_addr |
client_hostname |
client_port |
backend_start | 2023-04-28 15:43:58.433282+08
xact_start |
query_start |
state_change |
wait_event_type | Activity
wait_event | AutoVacuumMain
state |
backend_xid |
backend_xmin |
query |
backend_type | autovacuum launcher
-[ RECORD 2 ]----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-----------------------------
datid |
datname |
pid | 114865
leader_pid |
usesysid | 10
usename | postgres
application_name |
client_addr |
client_hostname |
client_port |
backend_start | 2023-04-28 15:43:58.434019+08
xact_start |
query_start |
state_change |
wait_event_type | Activity
wait_event | LogicalLauncherMain
state |
backend_xid |
backend_xmin |
query |
backend_type | logical replication launcher
-[ RECORD 3 ]----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-----------------------------
datid | 14386
datname | postgres
pid | 114868
leader_pid |
usesysid | 10
usename | postgres
application_name | psql
client_addr |
--More--如果数据行太长出现折行,就可以使用这里介绍的“\x”命令将 其拆分为多行显示。这与MySQL中命令后加“\G”的功能类似。
1.3.6 执行存储在外部文件中的SQL命令

1.3.7 编辑命令
编辑命令“\e”可以用于编辑文件,也可用于编辑系统中已存在 的函数或视图定义,下面来举例说明此命令的使用方法。 输入“\e”命令后会调用一个编辑器,在Linux下通常是Vi,当 “\e”命令不带任何参数时则是生成一个临时文件,前面执行的最后 一条命令会出现在临时文件中,当编辑完成后退出编辑器并回到psql 中时会立即执行该命令:
如果“\ef”后面跟一个函数名,则函数定义的内容会出现在Vi编 辑器中,当编辑完成后按“wq:”保存并退出,再输入“;”就会执行 所创建函数的SQL语句。
同样输入“\ev”且后面不跟任何参数时,在Vi中会出现一个创建 视图的模板:
也可以编辑已存在的视图的定义,只需在“\ev”命令后面跟视图 的名称即可。 “\ef”和“\ev”命令可以用于查看函数或视图的定义,当然用 户需要注意,退出Vi后,要在psql中输入“\reset”来清除psql的命 令缓冲区,防止误执行创建函数和视图的SQL语句,
1.3.8 输出信息的“\echo”命令
“\echo”命令用于输出一行信息,示例如下:
此命令通常用于在使用.sql脚本的文件中输出提示信息。 比如,某文件“a.sql”有如下内容:
\echo =========================================
select * from class;
\echo =========================================
运行a.sql脚本:
postgres=# \i a.sql
==================================================================
-[ RECORD 1 ]---------
no | 1
class_name | 初二(1)班
-[ RECORD 2 ]---------
no | 2
class_name | 初二(2)班
-[ RECORD 3 ]---------
no | 3
class_name | 初二(3)班
-[ RECORD 4 ]---------
no | 4
class_name | 初二(4)班
==================================================================
postgres=# 1.3.9 更多其他的命令可以用“\?”命令来显示,示例如下:
postgres=#
postgres=# \?
General
\copyright show PostgreSQL usage and distribution terms
\crosstabview [COLUMNS] execute query and display results in crosstab
\errverbose show most recent error message at maximum verbosity
\g [(OPTIONS)] [FILE] execute query (and send results to file or |pipe);
\g with no arguments is equivalent to a semicolon
\gdesc describe result of query, without executing it
\gexec execute query, then execute each value in its result
\gset [PREFIX] execute query and store results in psql variables
\gx [(OPTIONS)] [FILE] as \g, but forces expanded output mode
\q quit psql
\watch [SEC] execute query every SEC seconds
Help
\? [commands] show help on backslash commands
\? options show help on psql command-line options
\? variables show help on special variables
\h [NAME] help on syntax of SQL commands, * for all commands
Query Buffer
\e [FILE] [LINE] edit the query buffer (or file) with external editor
\ef [FUNCNAME [LINE]] edit function definition with external editor
\ev [VIEWNAME [LINE]] edit view definition with external editor
\p show the contents of the query buffer
\r reset (clear) the query buffer
\s [FILE] display history or save it to file
\w FILE write query buffer to file
Input/Output
\copy ... perform SQL COPY with data stream to the client host
\echo [-n] [STRING] write string to standard output (-n for no newline)
\i FILE execute commands from file
\ir FILE as \i, but relative to location of current script
\o [FILE] send all query results to file or |pipe
\qecho [-n] [STRING] write string to \o output stream (-n for no newline)
\warn [-n] [STRING] write string to standard error (-n for no newline)
Conditional
\if EXPR begin conditional block
\elif EXPR alternative within current conditional block
\else final alternative within current conditional block
\endif end conditional block
Informational
(options: S = show system objects, + = additional detail)
\d[S+] list tables, views, and sequences
\d[S+] NAME describe table, view, sequence, or index
\da[S] [PATTERN] list aggregates
\dA[+] [PATTERN] list access methods
\dAc[+] [AMPTRN [TYPEPTRN]] list operator classes
\dAf[+] [AMPTRN [TYPEPTRN]] list operator families
\dAo[+] [AMPTRN [OPFPTRN]] list operators of operator families
\dAp[+] [AMPTRN [OPFPTRN]] list support functions of operator families
\db[+] [PATTERN] list tablespaces
\dc[S+] [PATTERN] list conversions
\dC[+] [PATTERN] list casts
--More--1.4 psql的使用技巧
psql最常用的使用技巧,如历史命令和补全技巧、关 闭自动提交功能、获得快捷命令实际的SQL,以便学习数据库的系统表 等
1.4.1 历史命令与补全功能
可以使用上下方向键把以前使用过的命令或SQL语句调出来,连续 单击两次Tab键表示把命令补全或给出输入提示:
postgres=#
postgres=# \d
\d \dA \dAf \dAp \dc \dd \ddp \des \deu \df \dFd \dFt \di \dL \dn \dO \dP \dPt \dRp \ds \dt \du \dx
\da \dAc \dAo \db \dC \dD \dE \det \dew \dF \dFp \dg \dl \dm \do \dp \dPi \drds \dRs \dS \dT \dv \dy
postgres=#
postgres=# \d t
t test1 t_pkey
postgres=# \d x
postgres=# \d s
score student student_bak student_bak_pkey student_pkey
postgres=#如果在已运行的psql中显示了某个命令实际执行的SQL语句后又想 关闭此功能,该怎么办?这时可以使用“\set ECHO_HIDDEN on|off” 命令,示例如下:
[postgres@postgres ~]$
[postgres@postgres ~]$ psql postgres
psql (13.9)
Type "help" for help.
postgres=# \dn
List of schemas
Name | Owner
--------+----------
public | postgres
(1 row)
postgres=# \set ECHO_HIDDEN on
postgres=# \dn
********* QUERY **********
SELECT n.nspname AS "Name",
pg_catalog.pg_get_userbyid(n.nspowner) AS "Owner"
FROM pg_catalog.pg_namespace n
WHERE n.nspname !~ '^pg_' AND n.nspname <> 'information_schema'
ORDER BY 1;
**************************
List of schemas
Name | Owner
--------+----------
public | postgres
(1 row)
postgres=#1.5 本章将详细讲解PostgreSQL数据库支持的各种数据类型及其与其 他数据库的差异。
1.5.1 数据类型的分类
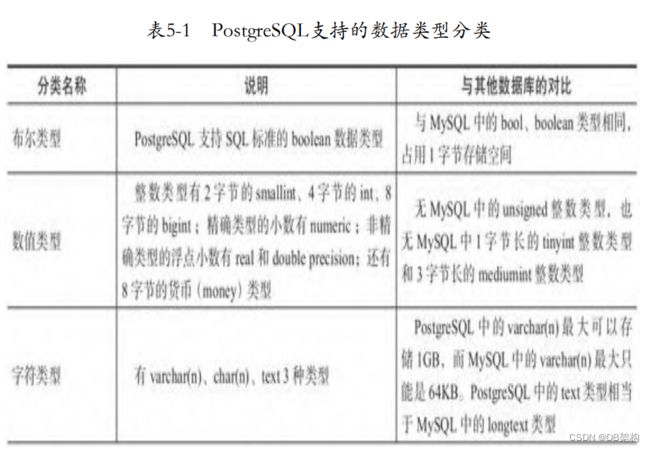
为了提高SQL的兼容性,部分数据类型还有很多别名,如integer 类型,可以用int、int4表示,smallint也可以用int2表示;char varying(n)可以用varchar(n)表示,numeric(m,n)也可以用 decimal(m,n)表示,等等。
1.5.2 数据类型的输入与转换
对于一些简单的数据类型,如数字或字符串,使用一般的方法输 入就可以了,示例如下:
postgres=#
postgres=# select 1, 1.1421, 'hello world';
?column? | ?column? | ?column?
----------+----------+-------------
1 | 1.1421 | hello world
(1 row)
postgres=#对于复杂的数据类型,可以按照“类型名”加上单引号括起来的 类型值格式来输入,示例如下:
postgres=# select bit '11110011';
bit
----------
11110011
(1 row)
postgres=#实际上所有的数据类型(包括简单的数据类型)都可以使用上面 的输入方法,示例如下:
postgres=# select int '1' + int '2';
?column?
----------
3
(1 row)
postgres=#PostgreSQL支持用标准SQL的数据类型转换函数CAST来进行数据类 型转换,示例如下:
postgres=# select CAST('5' as int),CAST('2014-07-17' as date);
int4 | date
------+------------
5 | 2014-07-17
(1 row)
postgres=#此外,PostgreSQL中还有一种更简捷的类型转换方式,即双冒号 方式,示例如下:
postgres=# select '5'::int,'2014-07-17'::date;
int4 | date
------+------------
5 | 2014-07-17
(1 row)
postgres=#在PostgreSQL中可以使用上面介绍的这两种数据类型转换方式输 入各种类型的数据。
1.5.3 布尔类型介绍
postgres=# CREATE TABLE t (id int, col1 boolean, col2 text);
ERROR: relation "t" already exists
postgres=# drop table t;
DROP TABLE
postgres=# CREATE TABLE t (id int, col1 boolean, col2 text);
CREATE TABLE
postgres=# INSERT INTO t VALUES (1,TRUE, 'TRUE');
INSERT 0 1
postgres=# INSERT INTO t VALUES (2,FALSE, 'FALSE');
INSERT 0 1
postgres=# INSERT INTO t VALUES (3,tRue, 'tRue');
INSERT 0 1
postgres=# INSERT INTO t VALUES (4,fAlse, 'fAlse');
INSERT 0 1
postgres=# INSERT INTO t VALUES (5,'tRuE', '''tRuE''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (6,'fALsE', '''fALsE''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (7,'true', '''true''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (8,'false', '''false''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (9,'t', '''t''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (10,'f', '''f''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (11,'y', '''y''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (12,'n', '''n''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (13,'yes', '''yes''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (14,'no', '''no''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (15,'1', '''1''');
INSERT 0 1
postgres=# INSERT INTO t VALUES (16,'0', '''0''');
INSERT 0 1
postgres=# select * from t;
id | col1 | col2
----+------+---------
1 | t | TRUE
2 | f | FALSE
3 | t | tRue
4 | f | fAlse
5 | t | 'tRuE'
6 | f | 'fALsE'
7 | t | 'true'
8 | f | 'false'
9 | t | 't'
10 | f | 'f'
11 | t | 'y'
12 | f | 'n'
13 | t | 'yes'
14 | f | 'no'
15 | t | '1'
16 | f | '0'
(16 rows)
postgres=# select * from t where col1;
id | col1 | col2
----+------+--------
1 | t | TRUE
3 | t | tRue
5 | t | 'tRuE'
7 | t | 'true'
9 | t | 't'
11 | t | 'y'
13 | t | 'yes'
15 | t | '1'
(8 rows)
postgres=# select * from t where not col1;
id | col1 | col2
----+------+---------
2 | f | FALSE
4 | f | fAlse
6 | f | 'fALsE'
8 | f | 'false'
10 | f | 'f'
12 | f | 'n'
14 | f | 'no'
16 | f | '0'
(8 rows)
postgres=# 1.5.4 布尔类型的操作符
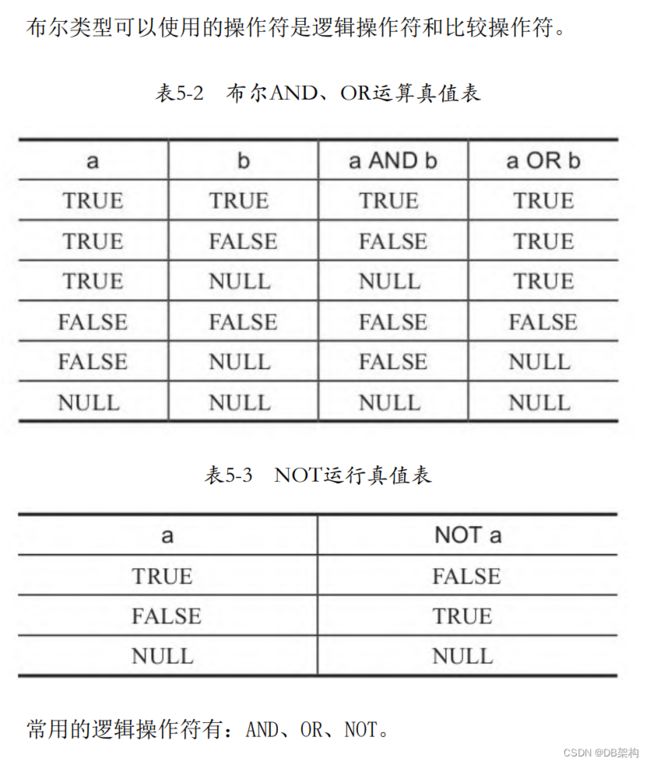
SQL使用三值的布尔逻辑:TRUE、FALSE和NULL,其中NULL代表 “未知”。
操作符AND和OR左右两边的操作是可以互相交换的,也就是说, “a AND b”结果与“b AND a”的结果是相同的。
布尔类型可以使用“IS”这个比较运算符,具体如下:
·expression IS TRUE。
·expression IS NOT TRUE。
·expression IS FALSE。
·expression IS NOT FALSE。
·expression IS UNKNOWN。
·expression IS NOT UNKNOWN。
1.5.5 数值类型
数值类型是最常用的几种数据类型之一,分为整型、浮点型、精 确小数等类型,
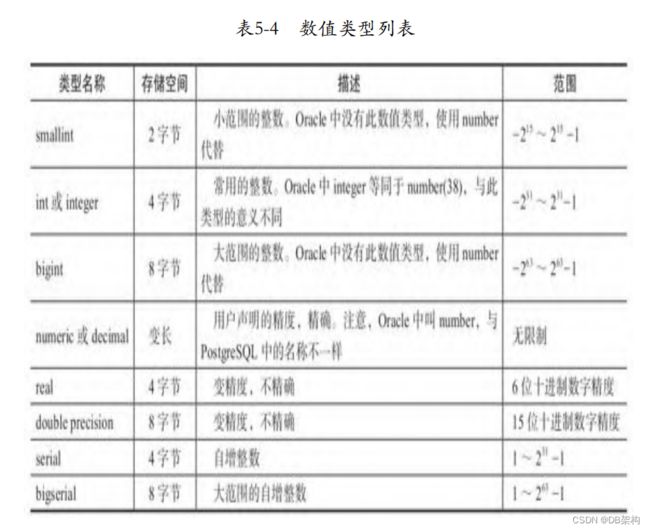
整数类型有3种:smallint、int、bigint,注意,PostgreSQL中 没有MySQL中的tinyint(1字节)、mediumint(3字节)这两种类型, 也没有MySQL中的unsigned类型。 常用的数据类型是int(或integer),因为它提供了在范围、存 储空间、性能之间的最佳平衡。一般只有在磁盘空间紧张的时候才使 用smallint类型。通常,只有integer类型的取值范围不够时才使用 bigint类型,因为前者的执行速度绝对快得多。 SQL只声明了整数类型integer(或int)和smallint。int与 integer和int4是等效的,int2与smallint是等效的,bigint与int8是 等效的。