小目标检测3_注意力机制_Self-Attention
主要参考:
(强推)李宏毅2021/2022春机器学习课程 P38、39
李沐老师:64 注意力机制【动手学深度学习v2】
手把手带你Yolov5 (v6.1)添加注意力机制(一)(并附上30多种顶会Attention原理图)
(文中截图多来源于上述链接)
改进部分参考:
YOLO Air:YOLO系列科研改进论文推荐 | 改进组合上千种搭配,包括Backbone,Neck,Head,注意力机制,适用于YOLOv5、YOLOv7、YOLOX等算法
神经网络学习小记录64——Pytorch 图像处理中注意力机制的解析与代码详解
文章目录
- 注意力机制
- 注意力汇聚(池化)attention pooling
- 自注意力 Self-Attention
- CNN中的Self-Attention
-
- Channel attention
-
- 1. SENet
- 2. ECA
- CA 注意力模块
- Channel & Spatial attention
-
- 1. CBAM
- 注意力机制的应用
注意力机制
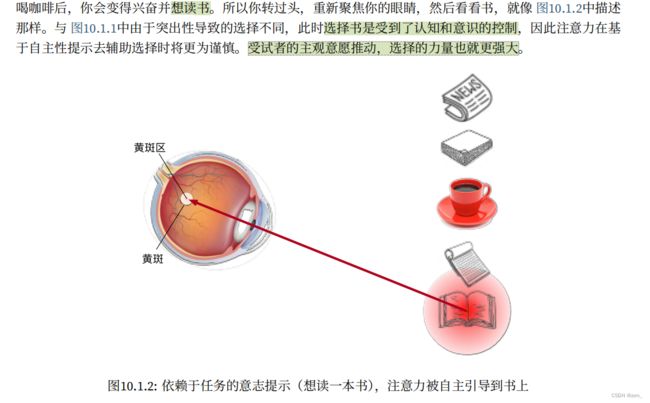
因此,** “是否包含⾃主性提⽰ ” ** 将 注意⼒机制 与 全连接层或汇聚层 区别开来。
在注意⼒机制的背景下,我们将⾃主性提⽰称为查询(query)。给定任何查询,注意⼒机制通过注意⼒汇聚(attention pooling)将选择引导⾄感官输⼊(sensory inputs,例如中间特征表⽰)。在注意⼒机制中,这些感官输⼊被称为值(value)。更通俗的解释,每个值都与⼀个键(key)配对,这可以想象为感官输⼊的⾮⾃主提⽰。如 图10.1.3所⽰,我们可以设计注意⼒汇聚,以便给定的查询(⾃主性提⽰)可以与键(⾮⾃主性提⽰)进⾏匹配,这将引导得出最匹配的值(感官输⼊)。
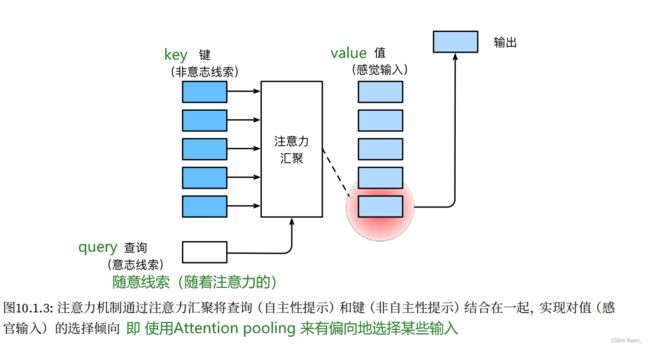
注意力汇聚(池化)attention pooling
一般是使用 一层网络(注意力汇聚 或 注意力池化)实现注意力机制。
我们希望获得更多的上下文信息(可通过学习到的注意力权重表示)
通⽤的注意⼒汇聚(attention pooling)公式:
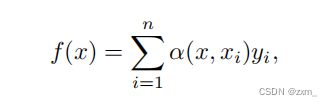
x————查询 query
xi————键 key
yi————值 value
(xi, yi)——键值对
**注意⼒汇聚 f(x)**是yi的加权平均。将 查询x和键xi之间的 关系(或者称为与key对应的value的概率分布)建模为 注意⼒权重(attention weight)α(x, xi)。这个权重将被分配给每⼀个对应值yi。“查询-键”对越接近,越具有参考价值,注意⼒权重就越⾼
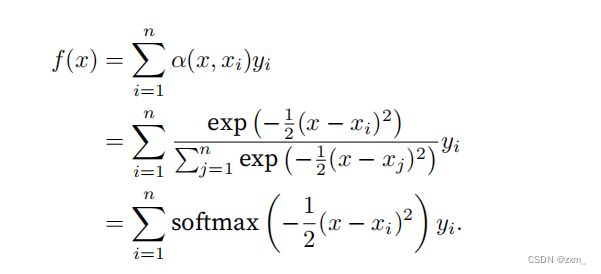
对于任何查询x,模型在所有键值对注意⼒权重都是⼀个有效的概率分布:它们是⾮负的,并且总和为1(影刺使用softmax函数进行归一化)。
带参数注意⼒汇聚:在下⾯的查询x和键xi之间的距离乘以可学习参数w
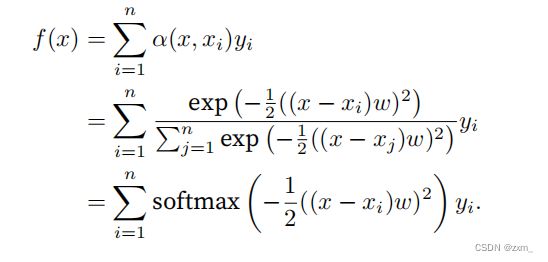
注意力机制框架:


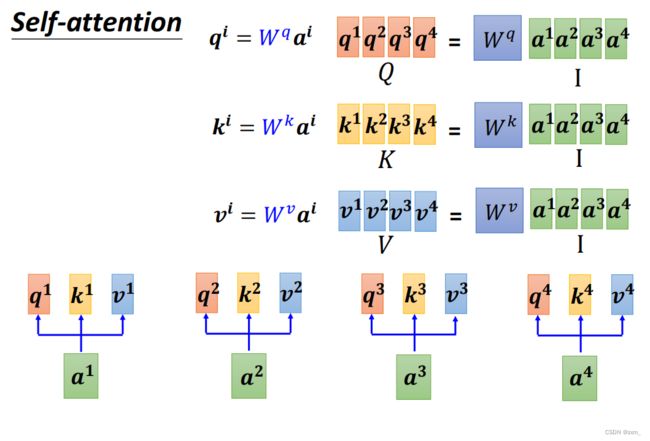
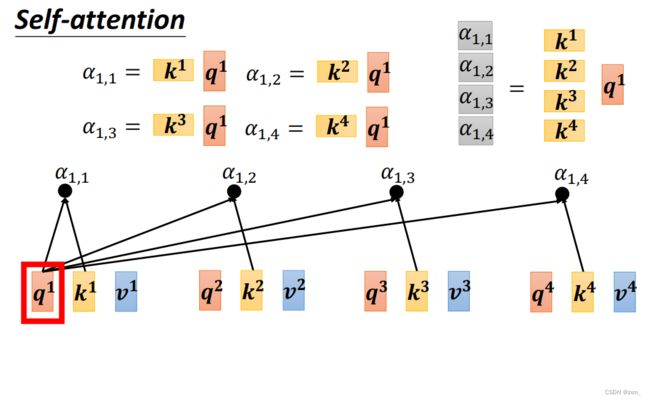
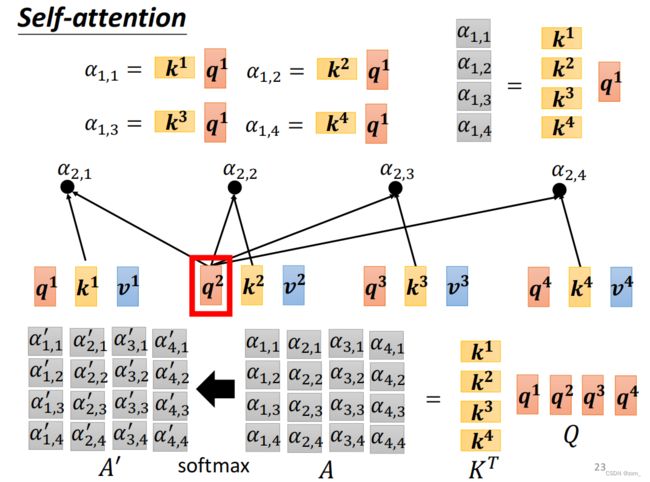
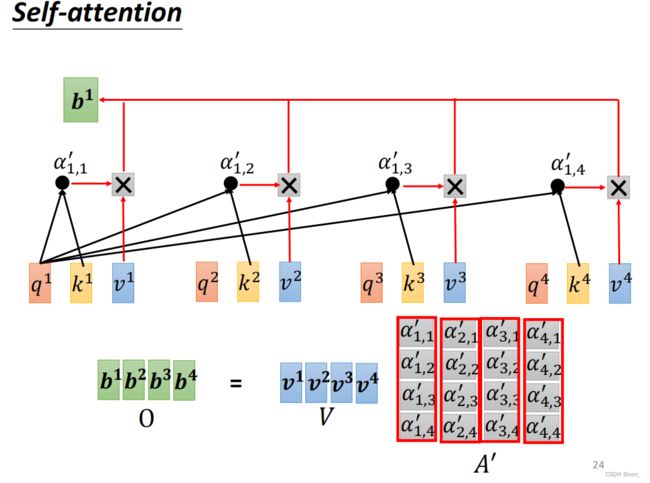
自注意力 Self-Attention
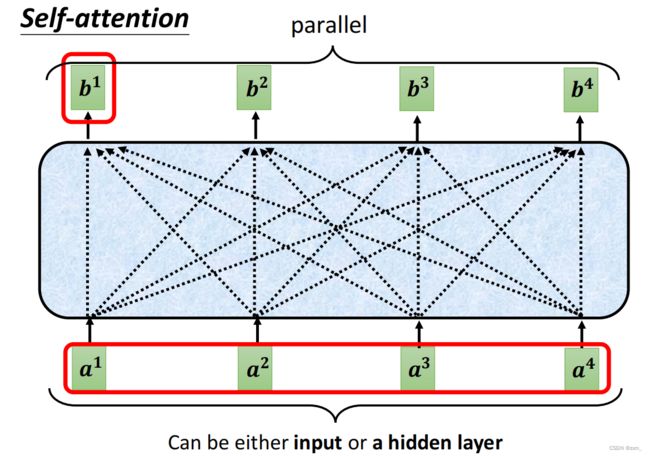
- 每一个outpt都要考虑整个sequence
- 不需要依序生成output(可以同时计算)
加性注意⼒:

下面是李宏毅老师的PPT内容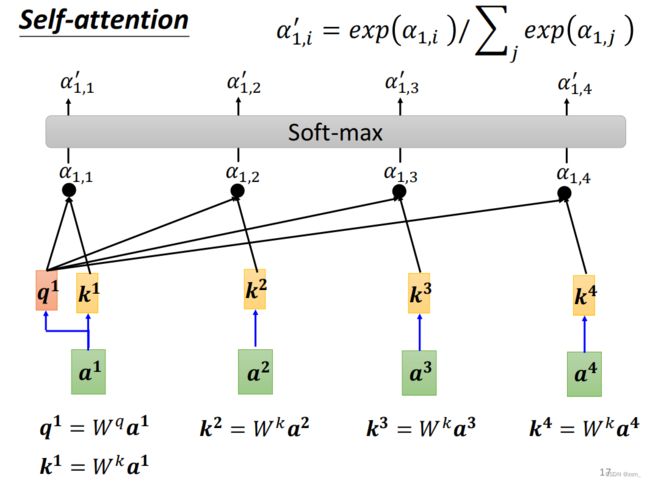
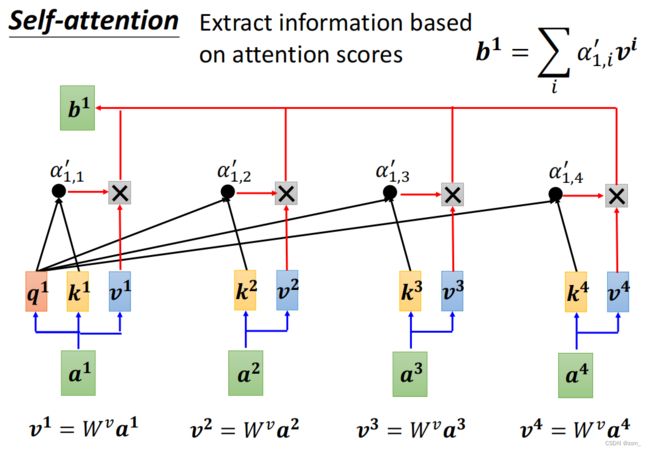
写成矩阵的形式:

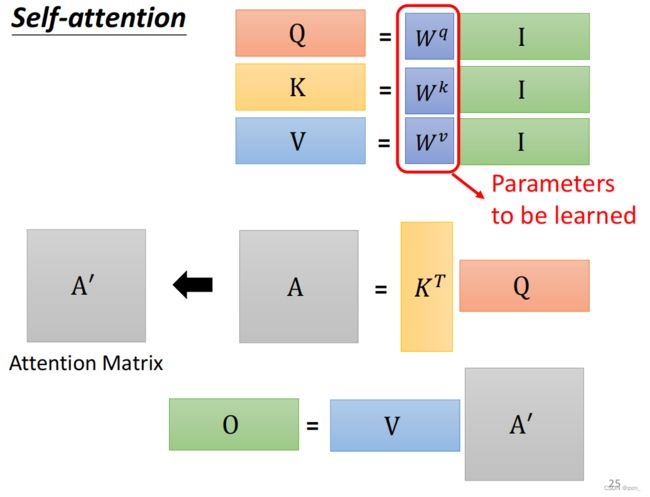
CNN中的Self-Attention
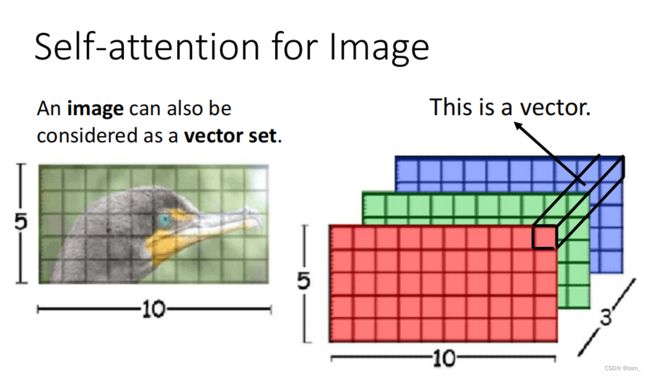
将每一个像素点看成一个向量,包含多个通道。
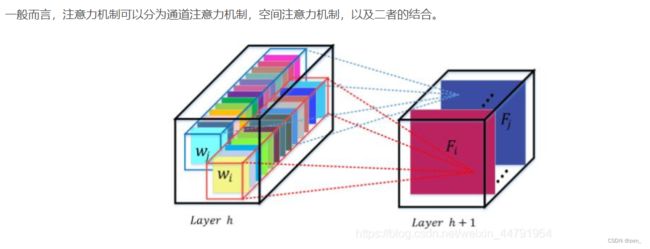
Channel attention
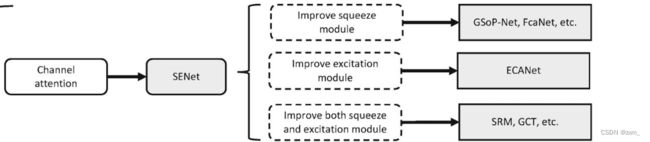
1. SENet
论文名称:Squeeze-and-Excitation Networks
论文链接:https://arxiv.org/pdf/1709.01507.pdf
论文代码: https://github.com/hujie-frank/SENet
SEnet(Squeeze-and-Excitation Network),2017年提出的SENet是最后一届ImageNet竞赛的冠军,考虑了特征通道之间的关系,在特征通道上加入了注意力机制。
SEnet通过学习的方式自动获取每个特征通道的重要程度。
对于输入进来的特征层,关注其每一个通道的权重,对于SENet而言,其重点是获得输入进来的特征层,每一个通道的权值。
利用SENet得到的重要程度,来提升特征并抑制对当前任务不重要的特征,让网络关注它最需要关注的通道。
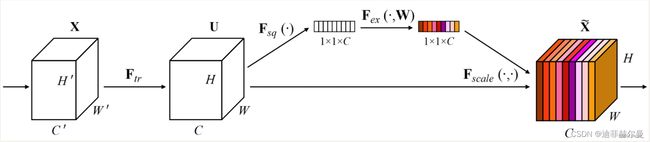
其具体实现方式就是:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。(对输入特征的通道进行缩放)
Global spatial information is collected in the squeeze module by global average pooling
excitation module captures channel-wise relationships and outputs an attention vector by using fully-connected layers and non-linear layers (ReLU and sigmoid).
class se_block(nn.Module):
def __init__(self, channel, ratio=16):
super(se_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
缺点:
在squeeze module挤压模块中,全局平均池过于简单,无法捕捉复杂的全局信息。
在excitation module激励模块中,全连通层增加了模型的复杂性。
2. ECA
论文名称:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
论文地址:https://arxiv.org/abs/1910.03151
代码: https://github.com/BangguWu/ECANet
ECANet可以看作是SENet的改进版。
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。
在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。
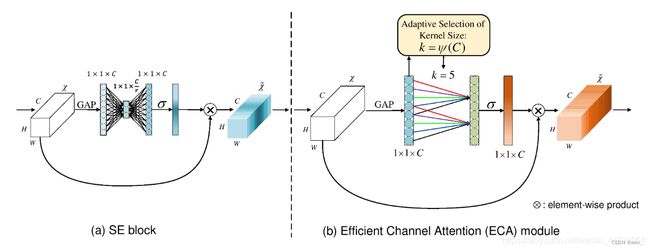
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。
既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,了解过卷积原理的同学很快就可以明白,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。用更专业的名词就是跨通道交互的覆盖率。
如下图所示,左图是常规的SE模块,右图是ECA模块。ECA模块用1D卷积替换两次全连接。
class eca_block(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(eca_block, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
CA 注意力模块
参考博客:https://blog.csdn.net/weixin_43694096/article/details/124443059
先前的轻量级网络的注意力机制大都采用SE模块,仅考虑了通道间的信息,忽略了位置信息。尽管后来的BAM和CBAM尝试在降低通道数后通过卷积来提取位置注意力信息,但卷积只能提取局部关系,缺乏长距离关系提取的能力。为此,论文提出了新的高效注意力机制coordinate attention(CA),能够将横向和纵向的位置信息编码到channel attention中,使得移动网络能够关注大范围的位置信息又不会带来过多的计算量。
coordinate attention的优势主要有以下几点:
不仅获取了通道间信息,还考虑了方向相关的位置信息,有助于模型更好地定位和识别目标;
足够灵活和轻量,能够简单地插入移动网络的核心结构中;
可以作为预训练模型用于多种任务中,如检测和分割,均有不错的性能提升。
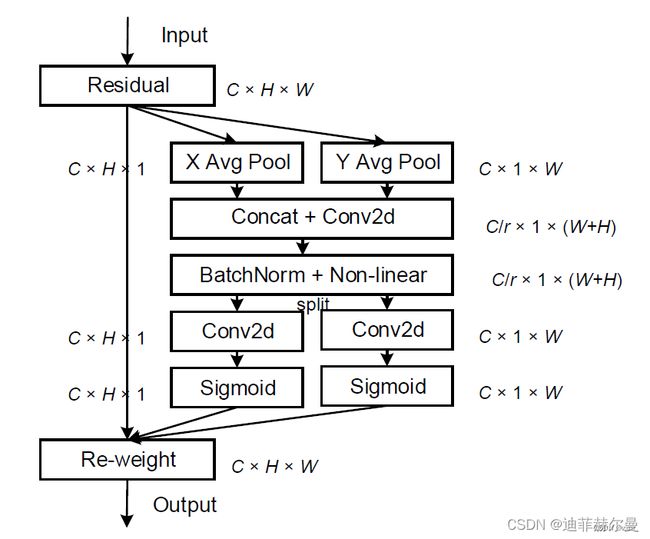
残差结构
# CA
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
#c*1*W
x_h = self.pool_h(x)
#c*H*1
#C*1*h
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
#C*1*(h+w)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
Channel & Spatial attention
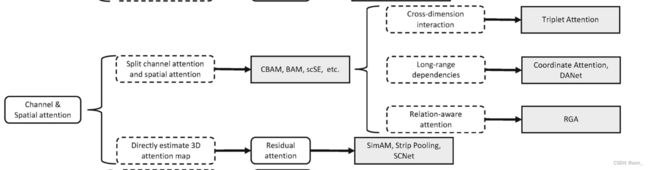
1. CBAM
论文题目:《CBAM: Convolutional Block Attention Module》
论文地址:https://arxiv.org/pdf/1807.06521.pdf
CBAM(Convolutional Block Attention Module)结合了特征通道和特征空间两个维度的注意力机制。
CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
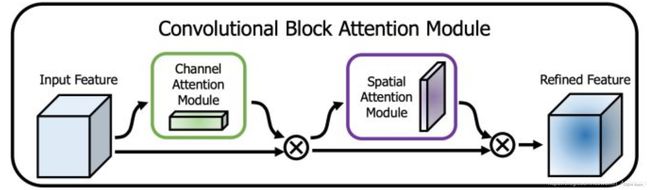
下图是通道注意力机制和空间注意力机制的具体实现方式:
通道注意力机制:
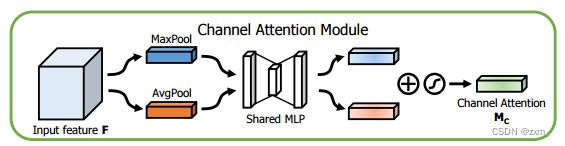
通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。之后对平均池化和最大池化的结果,利用共享的全连接层进行处理,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
空间注意力机制:
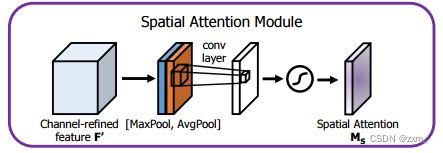
我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值。之后将这两个结果进行一个堆叠,利用一次通道数为1的卷积调整通道数,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class cbam_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x
注意力机制的应用
注意力机制是一个即插即用的模块,理论上可以放在任何一个特征层后面,可以放在主干网络,也可以放在加强特征提取网络。
由于放置在主干会导致网络的预训练权重无法使用,
若想使用预训练权重,可以将注意力机制应用加强特征提取网络上。
ShuffleAttention注意力机制
CrissCrossAttention注意力机制
S2-MLPv2注意力机制
SimAM注意力机制
SKAttention注意力机制
NAMAttention注意力机制
SOCA注意力机制
CBAM注意力机制
SEAttention注意力机制
GMAttention注意力机制
CA注意力机制
博客链接:github
YOLOv5 + ECA注意力机制 博客链接:github
————————————————
版权声明:本文为CSDN博主「芒果汁没有芒果」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_38668236/article/details/126073577