Mgeo:multi-modalgeographic language model pre-training
文章目录
-
- question
- 5.1 Geographic Encoder
-
- 5.1.1 Encoding
- 5.1.2
- 5.2 multi-modal pre-training
- 7 conclusion
- Geo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Ranking
-
- abs
- ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Applications in Baidu Maps
-
- abs
- intro
question
给定query,如何选取周边n个地理实体。(按照距离远近)
训练过程如何进行。(nlp mask,对比学习)
5.1 Geographic Encoder
如果没有 GC,仅有地理定位是毫无意义的。地理编码器将地理位置 l 作为输入,将 GC 作为一种新的模态映射到密集表征中,其中包含周围地理对象的特征 {o1, o2, ., on }。
5.1.1 Encoding
地理编码器可提取查询/POI 地理定位(点)与其周围地理对象(线或多边形)之间的相关性。地理编码器分别将地理对象的固有特征(即 ID、形状和地图位置)、关系(即 NEAR 或 COV ERED)和相对位置表示为嵌入。
ID.为了提取地理对象的内在特征,OSM ID 被映射到嵌入式中,其方式与单词嵌入式类似。oi 的 ID 嵌入表示为 ed i。
shape.使用独热函数将分类形状类型 osi 编码为数字数组,并获得其相应的嵌入信息 es i。形状类型嵌入表示为 es i。
地图位置。oi 在地图 em i 中的绝对位置是将其与其他地理物体区分开来的关键。以矩形为单位的整个地图区域被分割成 N × N 的网格,从而分别获得经度和纬度的比例因子 slng 和 slat:
地理对象的内在特征由三个组成部分(ed、es 和 em)描述。ed是地理对象的唯一标识符,es区分道路和ROI,em描述不同地理对象之间的位置关系。另外两个分量(et 和 ep)描述了地理定位与地理对象之间的相关性。将周围的地理对象编码为一个序列 {e1, ., em } 后,地理编码器采用多层双向变换器 [33] 来学习它们之间的相互作用。根据之前的工作[31],地理编码器会像 CLS 编码器一样在开头预置一个 GC 标记。因此,地理编码器的输出表示为 {hGC, h1, ., hm }。
5.1.2
我们设计了两个任务来训练地理编码器,并在以后的使用中固定下来,即屏蔽地理建模(MGM)和地理对比学习(GCL)。
MGM与广泛使用的掩码语言建模(MLM)[5]一样,MGM 的目的是预测掩码地理特征,即 OSM ID、几何类型、替代矩形的各边、关系类型和相对位置。MGM 损失 LMGM 由所有特征的屏蔽损失相加计算得出。
GCL。这项任务与大小为 bs 的批次中的多个地理位置 {l pq 1 ,…,l pq bs } 有关。我们首先定义现实世界中的地理距离矩阵 H∈Rbs×bs 如下:
![]()
其中,haversine 是计算地理位置间球形距离的 haversine 函数[23], ||`||N 是高斯归一化函数,σ 是将距离映射到范围(0,1)的 sigmoid 函数。由于输出空间中嵌入点之间的潜在距离应与它们在现实世界中的地理距离相对应,因此我们使用 hGC 作为地理定位 lpq 与 GC 的表示,并计算潜在距离矩阵̃ H∈ Rbs×bs 如下:
![]()
其中,⟨-⟩ 表示 doc-product 函数,∥ - ∥L2 为 L2 归一化函数。我们使用 KL-发散度来衡量 H 和 ~H 之间的相似度:
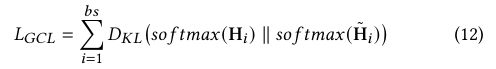
其中,DKL (- ∥ -) 表示 KL-发散,而 so f tmax 函数用于将 Hi 和 ~ Hi 转换为分布。
因此,地理编码器的训练损耗 Lg 的计算公式为
Lg = LMGM + LGCL (13)
利用这样的训练过程,地理编码器就能对给定地理信息系统中的 GC 进行建模。
5.2 multi-modal pre-training
MGeo 预训练的输入是一对文本和地理位置(t,l)。预训练数据可以来自不同来源,例如用户的点击或送货员的位置。多模态训练旨在将这两种模态对齐到一个潜在空间中。词嵌入用于将文本映射到向量序列中。地理编码器提供给定 l 的 GC 嵌入式。然后将两个嵌入式连接在一起,并输入多层双向变换器。
我们使用三种任务来学习 GC 与文本之间的交互,即单模式 MLM、多模式 MLM 和多模式 MGM。这些任务轮流进行训练。单模态 MLM 是 BERT 中使用的原始 MLM 任务,它随机屏蔽输入文本并用 MASK 标记替换。单模态 MLM 会移除地理编码器的输出。而多模态 MGM 则依靠整个地理编码器和部分文本信息来预测被屏蔽的标记。多模态 MGM 会随机屏蔽输入的地理特征并将其替换为 MASK,然后根据整个文本信息和部分地理信息进行预测。
7 conclusion
在本文中,我们正式提出了地理语境(GC)这一重要概念,它在现实世界中人类探索 POI 的过程中不可或缺。我们提出了一种多模态地理语言模型 MGeo,它将 GC 视为一种新的模态。因此,GC 可以与文本一起表示。此外,我们还建立了一个新的开源大规模基准 GeoTES,以促进对查询-POI 匹配主题的进一步研究。我们在最先进的 PLM 上进行了广泛的实验来评估我们提出的方法,详细的分析表明 MGeo 的性能明显优于其他基准。即使用户的地理位置可能不存在,查询也没有 GC,MGeo 仍然能比基线方法有所改进,这表明它有能力对文本到文本、GC 到 GC 以及文本到 GC 的相关性进行建模。在未来的工作中,还可以进一步探索 POI 图像等其他模式,以及更具创造性的地理编码器。此外,我们提出的 GC 建模有可能促进所有与地理相关的任务。
Geo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Ranking
abs
中文地理重排序任务旨在从检索到的候选地址中找出最相关的地址,这对于导航地图等与位置相关的服务至关重要。与一般句子不同,地理上下文与地理概念密切相关,从一般跨度(如省)到具体跨度(如路)。鉴于这一特点,我们提出了一个创新框架,即地理编码器(Geo-Encoder),以更有效地将中文地理语义整合到重新排序管道中。我们的方法首先利用现成的工具将文本与地理跨度关联起来,将它们视为分块单元。然后,我们提出了一个多任务学习模块,以同时获取有效的注意力矩阵,从而确定分块对额外语义表征的贡献。此外,我们还为拟议的添加任务提出了一种异步更新机制,旨在引导模型有效地关注特定的语块。在两个不同的中国地理重新排序数据集上进行的实验表明,与最先进的基线相比,地理编码器取得了显著的改进。值得注意的是,它大大提高了 MGEOBERT 的 Hit@1 分数,在 GeoTES 数据集上从 62.76 提高到 68.98,提高了 6.22%。
ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Applications in Baidu Maps
abs
预训练模型(PTM)已成为自然语言处理和计算机视觉下游任务的基本支柱。尽管在百度地图上将通用 PTM 应用于地理相关任务取得了初步成效,但随着时间的推移,人们发现其性能明显趋于稳定。造成这种停滞的主要原因之一是通用 PTM 中缺乏现成的地理知识。为了解决这个问题,我们在本文中介绍了 ERNIE-GeoL,它是一个地理和语言预训练模型,专为改善百度地图的地理相关任务而设计和开发。ERNIE-GeoL经过精心设计,通过对包含丰富地理知识的异构图生成的大规模数据进行预训练,学习地理语言的通用表示。在大规模真实世界数据集上进行的大量定量和定性实验证明了ERNIE-GeoL的优越性和有效性。自 2021 年 4 月起,ERNIE-GeoL 已在百度地图的生产中部署,并显著提高了各种下游任务的性能。这表明,ERNIE-GeoL 可以作为各种地理相关任务的基础骨干。
intro
百度地图提供的网络地图服务,如兴趣点(POI)检索[7, 13, 15]、POI 推荐[4]、POI 信息页面[31]和智能语音助手[12]等,都通过应用 PTM 提高了性能。然而,我们在实践中观察到,随着时间的推移,性能明显趋于稳定,也就是说,与通用 PTM 的优化相比,性能提升仍然微不足道。造成这种高原现象的主要原因之一是缺乏地理知识,而地理知识在改进需要地理信息计算支持的任务(以下简称地理相关任务)中发挥着至关重要的作用。在这项工作中,我们重点关注两类地理知识。(1) 地名知识。地名是指地理位置实体的名称,如 POI、街道和地区。地名解析[20]的目的是从文本中识别和提取地名,是各种地理相关任务的基本需要。然而,通用 PTM 很难捕捉到大多数地名的语义,因为地名知识在其训练数据中基本不存在或很少出现。(2) 空间知识。空间知识主要包括地理位置实体的地理坐标以及不同地理位置实体之间的空间关系,这些知识是地理编码[9]和地理参照[11]等地理相关任务所不可或缺的。然而,由于缺乏空间知识和纳入空间知识的预训练任务,通用 PTM 无法有效处理与地理相关的任务。