CLUECorpus2020: A Large-scale Chinese Corpus for Pre-training Language Model
整篇文章,很好理解,建议大家读一下。
0 摘要
主要是使用CLUECorpus2020,100G语料预训练模型。他们在小数据及以及大数据集上做了实验,表明这个语料训练的模型,更适合中文。他们使用的vcoba_clue是8k,是google的Chinese Bert的1/3 。他们发布了这个语料训练的小模型和大模型。大模型能达到最高的水平,小模型在保留大部分精度的情况下加速了训练,并且预测速度是bert-base的8倍。
1 引言
这篇论文的主要贡献是:
• 提供了可供预训练、语言生成,训练词向量的大规模中文语料 CLUECorpus2020(C5)
• 使用CLUECorpus2020(C5)其中一部分语料训练的模型,效果更在 Chinese Wiki语料上训练的模型要好,说明这个预料的质量很好。
• 他们的vocab_clue,大小是8k,相对于Chinese bert更小,更快。
• 发布了 CLUECorpus2020语料训练的小模型和大模型
2 相关工作
对于英文有很多开源的语料,但对于中文来说,语料非常少并且小。主要是介绍他们利用Common Crawl 提供了一个,非常大质量非常好,并且包含各个领域的语料。
3 数据集描述
语料有100G,train:dev:test=99:0.5:0.5。数据包含了娱乐节目,体育、健康、国际事务、电影、名人等等涵盖了各个领域。
4 数据构建
Common Crawl它是一个组织,它帮助公共免费的爬取网站。他们先根据详细的rule,抽取爬取的内容,但是里面夹杂很多的脏数据以及源码,并且含有很多重复内容,这对Nlp Chinese没有用。因此他们采用启发式rules以及C4过滤方法,进一步过滤和提取文本。(主要是清洗文本,可不必详细了解)
5 创建CLUE Vocab

上图对比了bertbase以及vocabclue,vocab的组成以及区别。
原来的bert model,对中文使用字符分词。但是在它的vocab里面有很多重复的tokens,因此他们通过自动化脚本和手动审查精简了很多。他们删除了繁体中文,Japanese、Korean、Emoji。对于English,它们除了单个字符,他们删掉了大多数prefix词,并保留了大多的后缀token。对于数字而言,他们只保留了单独的数字符号,以及常见的代表年份的词。
6 实验
6.1 在 CLUECorpus2020(C5)和Wiki数据上进行预训练
这部分主要是,使用相同的model来比较C5和Wiki这两个数据集。他们分别使用C5(1G)和Wiki(1G)来训练Bert_base model。
CLUE benchmark包含6个task,他们使用了4个任务,来测试模型的性能。具体如下:
• Sentence Pair Similarity: AFQMC7
• Sentiment Analysis: TNEWS8
• Multi-label Classification: IFLYTEK (IFLYTEK CO., 2019)
• Natural Language Inference: CMNLI (Conneau et al., 2018; Williams et al., 2017)
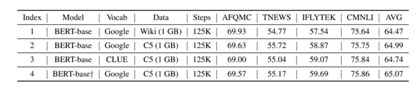
从上表index1和index2对比可知,使用相同的model,不同的data,部分task的任务甚至超过了bertbase,说明他们的数据质量很好 。另外,从index2和index3对比可知,在其他都相同的情况下,使用vocabclue,准确率也相差不多。index2和index4比较了不同注意力机制的效果,对比表示作者提出的bert_base+效果也很好。
6.2 使用C5数据集对比Attention Mechansims
他们认为bert_base的注意力机制太简单不能表达input的重要信息。因此,他们写了一个新的attention mechanism。新的attetion mechanism,作者描述的太简单,不好理解。(已经作者请教,暂未回复。)
6.3比较两个Vocab的性能
从6.1表index2和index3的对比可以看出,在其他都相同的情况下,使用vocab_clue,准确率也非常接近。
从上表可知,相比于bertbase,vocabclue的大小比原来的vocab减少了62%,参数减少了9.8%,训练速度提升了15%。
6.4更多的训练数据和steps
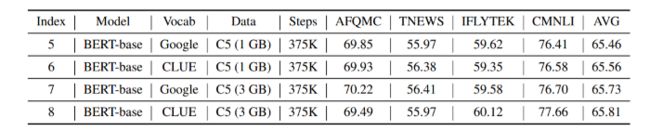
从上表可知:在index5和index7的对比下,增大数据集C5,可使效果提升0.27个点。在index5和index6的对比下,使用vocabclue可使效果提升0.1个点。因为增加数据集可以提升模型性能,并且使用vocabclue可以和bert_base的vocab媲美。
6.5 和大模型的性能对比
他们训练过程中,使用和Roberta相同的数据,并且删掉了NSP,并且也是用了whole word mask作为掩盖策略。他们使用batchsize=8k、seqlen=128先训练500k,然后batchsize=4k、seqlen=512训练600k步,这样模型对长文本更友好。
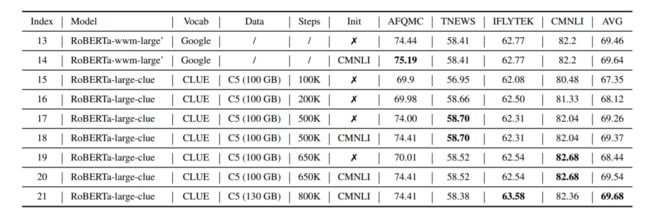
从上表可以看出,随着训练Step增加,模型效果越来越好。并且黑色的部分表明,已经超过了roberta-wwm-large。
6.6 Tiny version的性能
虽然bert之类的模型效果很好,但是因为模型深、参数大导致在预测过程中非常慢。因为发布了一个小版本。他们明明为Roberta-tiny-clue,因为它使用的模型是Roberta,但是语料和vocab是CLUE。它的参数和Alberttiny相同,4层,hiddensize为312。训练和预测时间是bert_base的10倍数。因为使用vocabclue,它的速度在Alberttiny的基础上提升了10个点。

从上表可以看出Roberttinyclue相对于bertbase保留了大部分的精度,和bertbase相差4个点,但是和Albert-tiny相比效果好很多。
6.7预训练模型在相似任务之间的迁移学习
预训练模型虽然比较强大,但是没有足够的训练数据也是很难学到具体的task。AFQMC和 CMNLI都是sentence_pair任務,但是CMNLI有很多的数据39万条。他们先用CMNLI预训练模型,然后在训练AFQMC时,使用CMNLI的参数先初始化模型,这样相比于直接初始化模型训练AFQMC提升(0.8-4)个点。
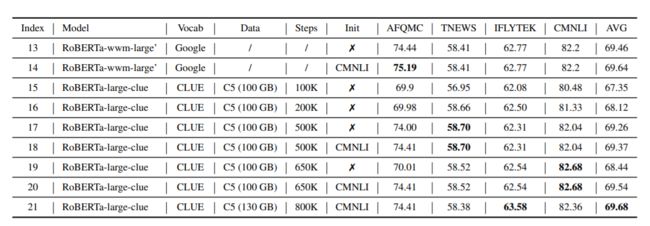
从上表,index19和index20对比发现,经过CMNLI预训练,在AFQMC上提升了4个点。
总结
他们提出了一个大规模的,中文预训练语料CLUECorpus2020。然后使用C5部分数据和Chinese Wiki对比 ,结果显示他们C5数据集质量很好。他们的vocab_clue虽然比较小,但是更适合中文任务。