06.GPT-4+图像生成
文章目录
- GPT-4
-
- 摘要
- 技术细节
- 亮点:可识图
- 亮点:性能好
- 多样性少
- 多语言处理能力强
- 可解Inverse Scaling Prize任务
- Calibration很好
- 输入图像的方式(猜测)
- 图像生成模型速览
-
- 图像生成
-
- 各个击破
- 一次到位
- 常用的图像生成模型
-
- VAE
- Flow-based Generative Model
- Diffusion Model
- GAN
- 小结
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索。
本文主要对应两部分内容:
1.简单点评GPT-4
2.介绍图像生成常见模型及Diffusion Model浅谈
GPT-4
OpenAI在今年(23年)3.14发布了GPT-4,配图挺有意思,暗示训练和Mask有关?

论文全文100页,正文14页,作者名单3页+,参考文献6页85条,剩下就是附录。
摘要
We report the development of GPT-4, a large-scale, multimodal model which can accept image and text inputs and produce text outputs. While less capable than humans in many real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers. GPT-4 is a Transformerbased model pre-trained to predict the next token in a document. The post-training alignment process results in improved performance on measures of factuality and adherence to desired behavior. A core component of this project was developing infrastructure and optimization methods that behave predictably across a wide range of scales. This allowed us to accurately predict some aspects of GPT-4’s performance based on models trained with no more than 1/1,000th the compute of GPT-4.
我们报告了 GPT-4 的开发情况,这是一个大型多模态模型,可以接受图像和文本输入,并生成文本输出。虽然在现实世界的许多场景中,GPT-4 的能力不如人类,但在各种专业和学术基准测试中,GPT-4 表现出了人类水平的性能,包括在模拟律师资格考试中以前 10% 左右的成绩通过考试。GPT-4 是一个基于变换器的模型,经过预先训练,可以预测文档中的下一个标记。训练后的调整过程提高了在事实性和遵守预期行为方面的性能。该项目的一个核心组成部分是开发基础设施和优化方法,使其在各种规模的情况下都能表现出可预测性。这使我们能够根据计算量不超过 GPT-4 1/1,000 的训练模型,准确预测 GPT-4 性能的某些方面。
这里提到的律师考试估计一来是要背的条文比较多,二来逻辑推理比较少。
技术细节
This report focuses on the capabilities, limitations, and safety properties of GPT-4. GPT-4 is a Transformer-style model [39] pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers. The model was then fine-tuned using Reinforcement Learning from Human Feedback (RLHF) [40]. Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
We are committed to independent auditing of our technologies, and shared some initial steps and ideas in this area in the system card accompanying this release. We plan to make further technical details available to additional third parties who can advise us on how to weigh the competitive and safety considerations above against the scientific value of further transparency.
本报告重点介绍 GPT-4 的功能、局限性和安全特性。GPT-4 是一个 Transformer 风格的模型[39],利用公开数据(如互联网数据)和第三方提供商授权的数据进行预训练,以预测文档中的下一个标记。然后使用 “人类反馈强化学习”(RLHF)[40]对模型进行微调。考虑到 GPT-4 等大型模型的竞争态势和安全影响,本报告不包含有关架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法或类似内容的更多细节。
我们致力于对我们的技术进行独立审核,并在本版本附带的系统卡中分享了这方面的一些初步步骤和想法。我们计划向更多第三方提供更多技术细节,他们可以就如何权衡上述竞争和安全考虑因素与进一步透明化的科学价值向我们提供建议。
基本就是无可奉告,只是展示了性能结果。
亮点:可识图
文中p39中有给一个例子(Table 19: Example prompt demonstrating GPT-4’s visual input capability.),用户下的Prompt为:
Can you explain why this is funny. Think about it step-by-step.
这里还用上了CoT。
给出的图片是:

模型给出回答全文如下:
The comic is satirizing the difference in approaches to improving model performance between statistical learning and neural networks. In statistical learning, the character is shown to be concerned with overfitting and suggests a series of complex and technical solutions, such as minimizing structural risk, reworking the loss function, and using a soft margin.
In contrast, the neural networks character simply suggests adding more layers to the model. This is often seen as a common solution to improving performance in neural networks, but it’s also considered a simplistic and brute-force approach.
The humor comes from the contrast between the complexity and specificity of the statistical learning approach and the simplicity and generality of the neural network approach. The “But unironically” comment adds to the humor by implying that, despite being simplistic, the “stack more layers” approach is often effective in practice.
其实这个梗图里面有文字解释,因此还不是很难。但该功能还未对外开放测试。
文中的4.1对图像的输入进行简要的说明,只提到:
Specifically, the model generates text outputs given inputs consisting of arbitrarily interlaced text and images.
就是能吃任何方式的图文混排输入。
关于输入图像的方式猜测,另起一节。
亮点:性能好
在很多方面性能都有很大提升(相对于GPT-3.5),下图中蓝色部分是GPT-3.5的性能,淡绿色是不带图片识别功能的GPT-4的性能,深绿色是带图片识别功能的GPT-4的性能。
由于有些考试需要看图片,所以有些考试深绿色表现最猛。
纵轴不是考试的得分,而是考试分数在所有考生中的排名百分比。
绿色占比最骚包的就是第六个:Uniform Bar Exam,看过Soul Goodman应该知道,这个是律师考试,与摘要呼应了。
当然,第一个Calculus微积分表现也还可以,GPT-3.5基本无法回答这类问题。

多样性少
问鸡鸭兔同笼问题:鸡鸭兔共30只,72条腿,其中鸡的数量是鸭的2倍,那么鸡有几只?
一共问了3次相同问题,GPT-4在列方程过程都对了,且说法基本相似,但是最后都是计算错误。可能GPT-4为了得到的答案更精确训练得比较收敛,多样性小一些。

第二次相对于第一次就是把鸡鸭兔替换掉xyz


但在ChatGPT上问这个问题3次,得到式子完全不同,多样性大一些:



多语言处理能力强
在MMLU语料上进行了多语言的测试。
MMLU,全称为Multimodal Multilingual Language Understanding,是一个专门用于评估语言模型在多模态和多语言情境下的理解能力的基准测试。这个基准由57个关于人类知识的多选题回答任务组成,涵盖的范围从高中水平到专家水平。此外,MMLU还推出了专门针对中文的评估数据集CMMLU,旨在全面评估LLM在中文语言和文化背景下的高级知识和推理能力。特别值得一提的是,MMLU-ZS是在没有任何额外训练的情况下,通过零样本学习来评估模型的性能,即模型需要在没有见过的任务或领域的情况下进行推理和理解。
下图先看英文的排名:
随机猜<Chinchilla<PaLM<GPT-3.5<GPT-4
下面绿色部分就是将MMLU翻译成不同语言后的测试结果。
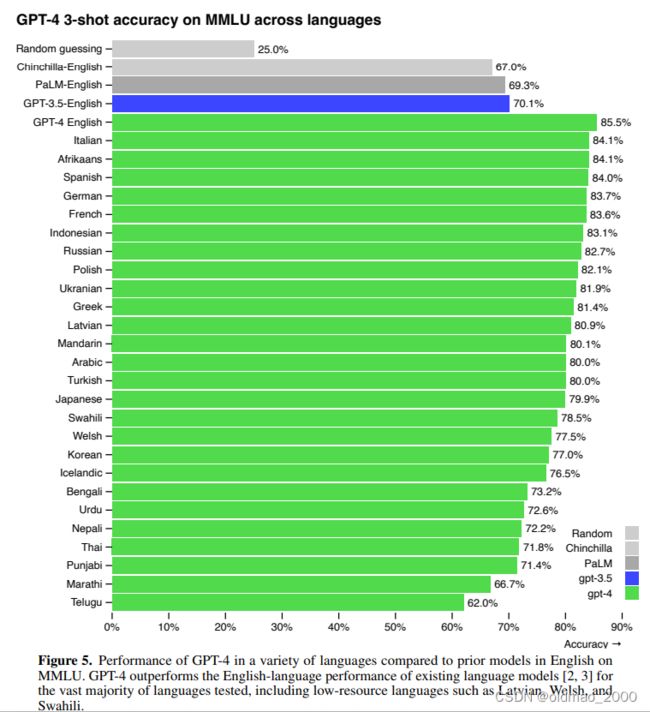
接下来为难一下GPT-4,给闽南语拼音,测试是否能看懂。
T s o ˋ - l a ^ n g n a ˉ p i ^ n - t u a ˉ n n , t s i t - s i ˋ - l a ^ n g b e ˉ k h u i ˋ n n - u a ′ h Ts\grave{o}\text{-} l\hat{a}ng\quad n\bar{a}\quad p\hat{i}n\text{-}tu\bar{a}nn, tsit\text{-}s\grave{i}\text{-}l\hat{a}ng\quad b\bar{e}\quad khu\grave{i}nn\text{-}u\overset{'}{a} h Tsoˋ-la^ngnaˉpi^n-tuaˉnn,tsit-siˋ-la^ngbeˉkhuiˋnn-ua′h

实际答案应该是:私人若贫惰,一世人袂快活。
同样的问题ChatGPT直接表示不会。
可解Inverse Scaling Prize任务
前面一节提到过Inverse Scaling Prize系列的任务,小模型玩不了,GPT-4则在这类任务上表现很不错(准确率100%):

这里提到的任务前一节有写,贴过来:
Question: David has the option to play a game where David has a 94 percent chance of losing 50 dollars and a 6 percent chance of earning 5 dollars. David plays the game and ends up earning 5 dollars. Did David make the right decision?
Choose Y or N.
有一个赌局94%会输50元,6%会赢5元,大卫玩了一把赢了5元,请这个大卫的决定是否正确。
虽然从结果上看,赢了5元,决定是正确的,但是从赌局概率上看,赢的期望值为0.3,输的期望值为-4.7,因此大卫玩这个赌局是不正确的决定。
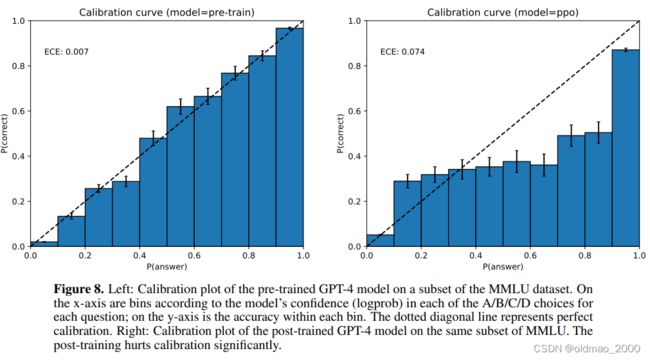
Calibration很好
Calibration就是指模型回答问题时候生成答案的几率与正确率的关系,左图可以看到GPT-4的Calibration很好。下图有一个指标ECE是指图中虚线与蓝色长条的差异,越小Calibration越好。右边是经过Post Train(也就是人工监督微调)后Calibration会变差。
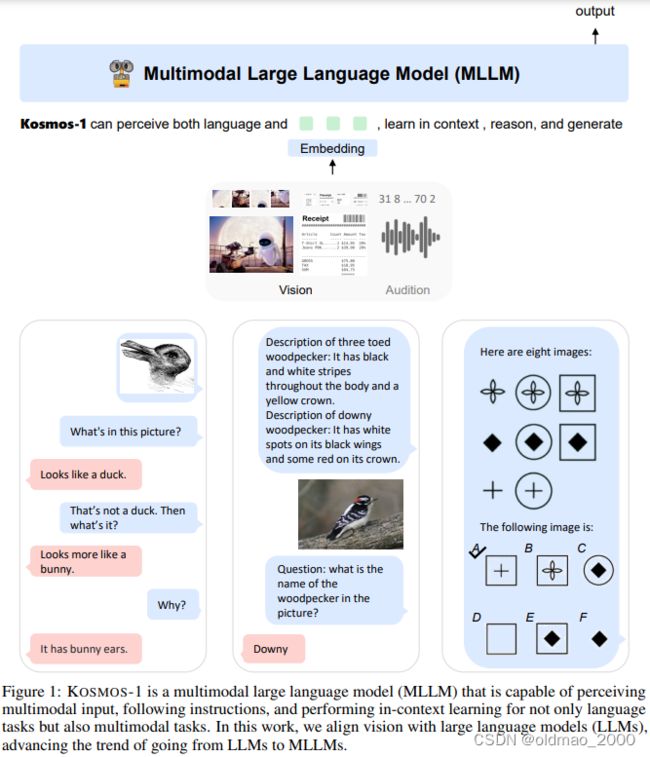
输入图像的方式(猜测)
1.Caption Generation
2.OCR
3.Image Encoder:吃图片得到图片的表征,有两种可能。一种是只出一个向量(CLIP中的Image Encoder模块就可以完成这个操作),另外一种是出一堆向量。然后将向量做离散化处理(Normalization),然后将结果用一系列的符号来表示,这一系列的符号可以看做是全新的语言。
还有就是采用了类似微软提出的:Kosmos-2.5: A Multimodal Literate Model,这个版本上个月才出来,多模态也开始大模型卷起来了。
具体没有展开,只是提供了参考的文章:
Language Is Not All You Need: Aligning Perception with Language Models
接着这个话题,进入下一节。
图像生成模型速览
图像生成
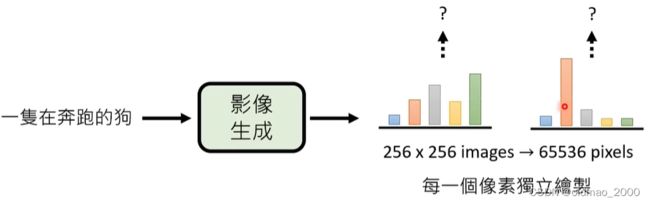
图像包含的内容是要远远大于文字的,下面的例子中生成的图中包含了狗的种类,奔跑的地点等信息,也就是说模型需要脑补大量信息才能完成文字到图像的转化。这和翻译,语音生成等任务有很大不同。

这门课的第一节就讲过两个策略:各个击破和一次到位。文字生成通常采用前者:
各个击破
当然如果图片生成也用这个策略(颜色可以根据RGB的组合有256×256×256种)

但是这样比较慢,因为一张256×256大小的图片,就有65536个像素需要生成。
OpenAI有一个影像版:
将图片的像素看做向量表示,拉直后当做Prompt丢进Autoregressive模型得到输出就结束了。
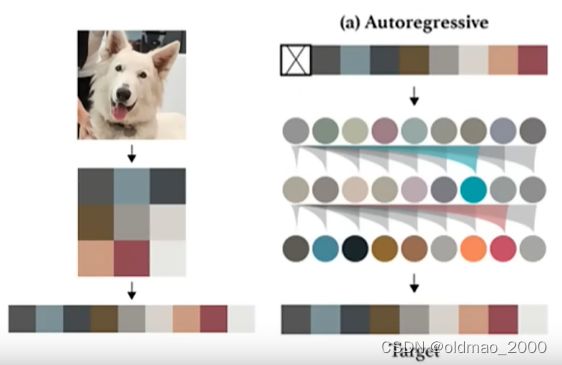
生成过程是一行行raster order进行:

一次到位
如果为了生成速度,采用一次到位的策略,那么相当于一次生成所有像素:
实际上,生成的图片其实可以有很多,不像其他任务正确答案基本唯一,例如上面的文字可以:

也就是说答案是一个集合,或者说是一个分布。
一步到位一次生成所有像素时,相互之间是独立的,这会导致每个生成得到结果不相关,有些像素画的二哈,有的画的是法斗,可能会得到缝合怪。

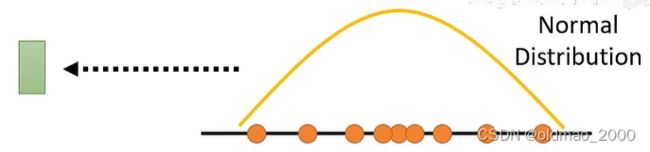
解决方法是加上额外的高维向量输入,这个输入是从一个已知的高维分布采样出来的(下面画的虽然是一维,实际上是高维):
然后在结合文字进入模型,得到图像:

想要明白这样做背后原理,就要先理解不带向量输入的原理,如果把文字记为 y y y,图像记为 x x x,那么求给定文字条件下生成图像就可以表示为 P ( x ∣ y ) P(x|y) P(x∣y):

这个 P ( x ∣ y ) P(x|y) P(x∣y)是很复杂的,不是简单的单个搞屎概率分布,没有DL的时候想要求出这个 P ( x ∣ y ) P(x|y) P(x∣y)非常困难,那个时候生成的图像都很模糊。
现在加上向量输入后,就变成:
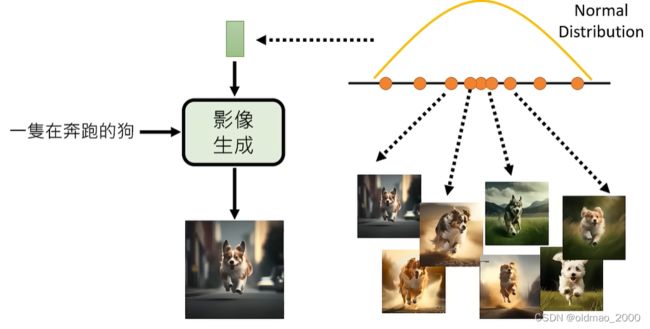
这里将分布中采样出来的向量,都对应到 P ( x ∣ y ) P(x|y) P(x∣y)中的每一个 x x x上,换句话说就是这里的Normal Distribution中的每一个点都对应了一张图片,而图像生成模型就是将点对应到的那张图片给找出来。
将分布中的点对应到图片这个工作就是图像生成模型的核心问题。
常用的图像生成模型
Variational Auto-encoder (VAE)
Flow-based Generative Model
Diffusion Model
Generative Adversarial Network (GAN)
这些模型貌似在之前的机器学习笔记中都有专门的章节,这里简单回顾。
VAE
之前课程链接在此:Unsupervised Learning.05: Deep Generative Model (Part II)
VAE主要是用Decoder,Decoder吃向量,然后生成图片,主要就是完成Normal Distribution与图片的对应。但是这个Decoder没有可以训练的数据(图片与向量的数据对),因此可以用Encoder来做训练数据,然后把两个结构连起来(看虚线),为了让Encoder生成的向量与右边相符,还要加上生成向量要符合Normal Distribution的限制。当然这里省略了文字的限制。

Flow-based Generative Model
之前课程链接在此:李宏毅机器学习笔记.Flow-based Generative Model(补)
和VAE相反,先处理Encoder,Encoder吃一个图片,得到一个符合Normal Distribution分布的向量(注意:这里不是指这个向量是Normal Distribution的,而是说如果丢很多张图片进去得到的多个向量集合,这个集合符合Normal Distribution):
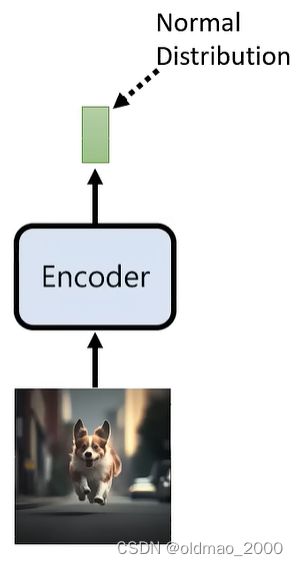
然后将Encoder进行反转:

为了达到反转,Encoder的结构当然是要特殊设计的,另外绿色的向量大小和输入图片的维度是一样大的。向量的样式应该如下图:

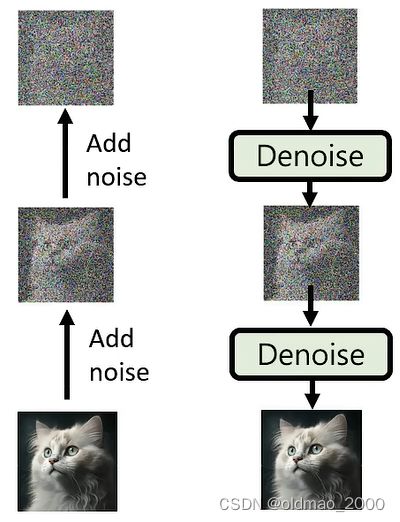
Diffusion Model
具体下一节详细讲,大概流程就是图片不断加noise,直到变成类似高斯分布,然后再训练一个Denoise模型,吃一个从Normal Distribution中采样出来的向量,然后生成图像。
GAN
Decoder吃一个从Normal Distribution中采样出来的向量,然后生成图片(刚开始生成的效果会很烂),然后将Decoder的输出 P ′ ( x ) P'(x) P′(x)丢进一个Discriminator中,让其分辨该图片与真实图片 P ( x ) P(x) P(x)是否接近。Decoder的目标就是要让Discriminator分辨不出生成图片与真实图片的差别。具体可以看之前的笔记,GAN一共有10篇。

小结
四个模型除了GAN之外,大方向上比较相似,Diffusion Model的两个阶段也可以对应到Encoder和Decoder上。
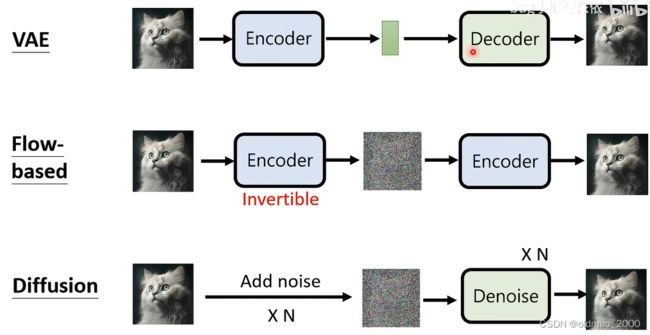
GAN的思路与其他三个不一样,也可把GAN的Discriminator接到上面的模型中,不断促使模型生成的图片更加接近真实图片。
Autoencoding beyond pixels using a learned similarity metric:VAE+GAN

这里将VAE的Decoder当做Generator,然后接上Discriminator。
Flow-GAN: Combining Maximum Likelihood and Adversarial Learning in Generative Models:Flow+GAN,顶会AAAI,貌似没给结构总览图。
Diffusion-GAN: Training GANs with Diffusion:Diffusion+GAN,23年ICLR
