Java系列学习笔记 --- 集合(4) 集合框架知识汇总
目录
前言
一、集合概述
1.1 Set接口
1.2 List接口
1.3 Map接口
二、Collection接口
2.1 遍历Collection接口
2.1.1 for-each循环迭代
2.1.2 ForEach(consumer action)方法
2.1.3 Iterator迭代器
三、Set集合
3.1 HashSet类
3.2 TreeSet类
定制排序
四、List集合
4.1 ArrayList类
4.2 LinkedList实现类
五、Map集合
5.1 Map集合的迭代方式
5.2 HashSet和HashMap的负载因子
前言
由于数组的长度是固定不变的,而且在同一个数组中只能存放相同类型的数据,该数据可以是基本类型也可以是引用类型,但是多数情况下我们无法保证存储数据的个数,所以这时数组就无法使用了。
为此,JDK类库提供了Java集合,所有的Java集合类都位于java.util包中。Java集合类能够方便地存储和操纵数量不确定的一组数据,与数组不同的是,集合不能存放基本类型的数据,只能存放对象的引用。虽然可以在添加集合元素时可以直接加入基本类型的数据,这是因为JDK会对基本类型和相应的包装类型进行隐式的自动转换,这一过程称为装箱。
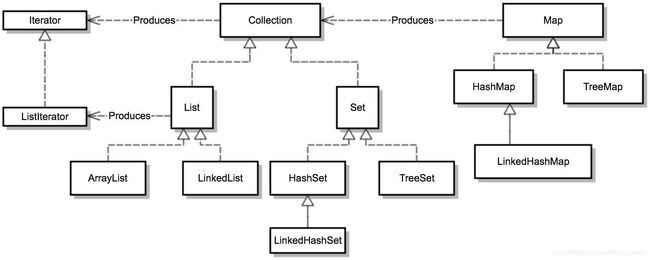
Java集合类中主要分为3种类型:Set、List和Map
一、集合概述
1.1 Set接口
Set接口实现了Collection接口,为无序集合,它不能包含重复的元素。实现Set接口的常用类又HashSet和TreeSet。它们都可以容纳所有类型的对象,但是无法保证序列顺序。
HashSet:将元素存储在一个哈希表中,通过哈希码值来计算元素的存储位置,它不保证Set集合的迭代顺序,特别是不保证顺序恒久不变。
TreeSet:该类不仅实现了Set接口,还实现了java.util.SorteSet接口。它将元素存储在一个红黑树中,按原始的值默认顺序排列,所以使用TreeSet类实现的Set集合对象必须实现Comparable接口。
1.2 List接口
List接口实现了Collection接口,为有序集合,允许存在相同的元素。使用List能够精确的控制每个元素的插入位置。用户使用索引(类似数组索引)来访问List中的元素。实现List接口的常用类由ArrayList和LinkedList。它们都可以容器所有类型的对象,包括null,并且保证元素的存储顺序。
ArrayList:实现了可变大小的数组。它的优点在于遍历元素和随机访问元素的效率比较高
LinkedList:提供了可以在List集合中的首部或尾部进行插入或删除等操作的额外方法,这使得LinkedList可被用作堆栈(stack)或队列(queue)
1.3 Map接口
Map是一种键-值对集合。实现Map接口的常用类有HashMap和TreeMap,它们用于存储键到值映射的对象。
HashMap:按哈希算法来存储键对象。
TreeMap:可以对键对象进行排序。
二、Collection接口
Collection接口是List接口和Set接口的父接口,该接口中提供了List集合与Set集合的通用方法。
| 返回值类型 |
方法名及说明 |
| boolean |
add(E e) 向集合中添加一个元素,E是元素的数据类型 |
| boolean |
addAll(Collection c) 向几何中添加集合C中的所有元素 |
| boolean |
isEmpty() 判断集合是否为空 |
| boolean |
contains(Object o) 判断集合中是否存在指定元素 |
| boolean |
containsAll(Collection c) 判断集合中是否包含集合c中的所有元素 |
| Iterator |
iterator() 返回一个Iterator对象,用于遍历集合中的对象 |
| void |
clear() 删除集合中的所有元素 |
| boolean |
remove(Object o) 从集合中删除一个指定元素 |
| boolean |
removeAll(CollectIon c) 从集合中删除在集合c中出现的元素 |
| boolean |
retain(CollectIon c) 仅保留在集合c中所出现的元素 |
| int |
size() 返回集合中元素的个数 |
| Object[] |
toArray() 返回包含此集合中所有元素的数组(集合变数组) |
2.1 遍历Collection接口
遍历Collection集合中的元素有2种方法:for-each循环迭代、Iterator迭代器、forEach(consumer action)方法。
范例对象
Collection persons = new ArrayList();
persons.add("张三");
persons.add("李四");
persons.add("王五");2.1.1 for-each循环迭代
使用for循环简洁地遍历一个集合或数组。范例代码如下程序所示:
for(Object obj:persons){
System.out.println(obj);
}2.1.2 ForEach(consumer action)方法
Java 8为Interable接口新增forEach(consumer action)默认方法,该方法所需参数的类型是一个函数式接口,当程序调用Iterable的forEach方法遍历集合元素时,程序会依次将集合元素传给Consumer的accept(T t)方法。
persons.forEach(obj -> System.out.println(obj));2.1.3 Iterator迭代器
Collection接口的iterator()方法可以获取一个Iterator对象,通过它可以迭代集合并在迭代过程中有选择地移除元素。
Iterator接口隐藏底层集合的数据结构,向客户程序提供了遍历各种类型的集合的统一接口,如下面的三个方法。
| 方法名 |
功能说明 |
| hasNext() |
判断集合中的元素是否遍历完毕,如果还有元素,就返回true |
| next() |
返回下一个元素 |
| remove() |
从集合中删除由next()方法返回的元素 |
下面通过范例程序演示了Iterator接口的遍历过程。
//创建Collection集合并插入对象
Collection persons = new ArrayList();
persons.add("张三");
persons.add("李四");
persons.add("王五");
System.out.println("=== 迭代前 ===\n" + persons);
System.out.println("=== 迭代时 ===");
//通过Collection集合对象的iterator()方法获取Iterator迭代对象
Iterator iter = persons.iterator();
while(iter.hasNext()){
String person = (String) iter.next();
System.out.println("["+person+"]");
if(person.equals("李四")){
iter.remove(); //删除当前迭代元素
}
}
System.out.println("=== 迭代后 ===\n" + persons);上述代码中,hashNext()方法返回true时表示还有元素,所以通过next()方法返回下一个迭代对象。需要注意的是,每调用一次next方法只能调用一次remove方法,否则就会抛出异常。
三、Set集合
Set是最简单的集合,集合中的对象不按特定方式排序,并且没有重复对象。Set接口主要有两个实现类:HashSet和TreeSet。
HashSet类按照哈希算法来存取集合中的对象,存储速度比较快,但无法保证元素的迭代顺序。它还有一个子类LinkedHashSet类,它不仅实现了哈希算法,还实现了链表数据结构,提高了插入和删除元素的性能,能够按照添加的顺序迭代元素。
TreeSet类里面有一个TreeMap(适配器模式),它实现了SorteSet接口,所以会按照哈希值的大小顺序对Map中的元素进行自然排序,也可以通过构造时传入的比较器(Comparator)进行排序,TreeMap底层通过红黑树算法实现。
3.1 HashSet类
HashSet类是按照哈希算法来存储集合中的元素,使用哈希算法可以提高集合中元素的存储或查询速度,当向Set集合中添加一个元素时,HashSet会调用该元素的hashCode()方法获取其哈希码,然后根据哈希码值计算出该元素在集合中的存储位置。
HashSet类的常用构造方法形式如下。
- HashSet() 构造一个新的空的Set集合。
- HashSet(Collection c) 构造一个包含指定Collection集合元素的新的Set集合。
下面演示了两种不同的形式创建HashSet对象
//调用无参的构造函数创建HashSet对象
HashSet hs = new HashSet();
//创建泛型的HashSet集合对象
HashSet hss = new HashSet(); HashSet类中实现了Collection接口中的所有方法,只是增加了对add()方法使用的限制,不允许有重复的元素。这是因为它还修改了equals()方法和hashCode()方法,所以在添加重复对象的时候会覆盖前面添加的元素,所以Set集合中不会出现相同的元素。
前面以及直到,HashSet是通过对象的hashCode值来进行存储的,所以它无法保证元素的迭代顺序,通过下面的程序范例所示。
HashSet persons = new HashSet();
persons.add("张三");
persons.add("李四");
persons.add("王五");
Iterator iter = persons.iterator();
while(iter.hasNext()){
String person = (String) iter.next();
System.out.println("["+person+"]");
}我们可以发现张三先添加的,但是确实在第二个迭代的,但是通过hashCode()方法我们可以发现,张三的hashCode值是最小的。
3.2 TreeSet类
TreeSet类不仅实现了Set接口,还实现了SorteSet接口,SortSet接口是Set接口的子接口,可以对集合进行自然排序(即升序排序)。
TreeSet persons = new TreeSet();
persons.add("李一");
persons.add("陈二");
persons.add("张三");
persons.add("李四");
persons.add("王五");
System.out.println(persons);
for(Object obj:persons){
System.out.println("["+obj+":"+obj.hashCode()+"]");
}输入结果如下所示。
=== TreeSet集合元素 ===
[张三, 李一, 李四, 王五, 陈二]
=== TreeSet集合迭代,获取元素hashCode值 ===
[张三:774889]
[李一:839794]
[李四:842061]
[王五:937065]
[陈二:1212740]TreeSet只能对实现了Comparable接口的类的对象进行排序,Comparable接口中有一个compareTo(Object o)方法,用于比较两个对象的大小。例如:a.compareTo(b),如果方法返回0,则a和b相等;如果返回大于0的值,则a大于b;如果返回小于0的值,则a小于b。
TreeSet除了实现Collection接口的所有方法之外,还提供了如下方法。
| 返回值类型 |
方法名及说明 |
| E |
First() 返回此集合中的第一个元素。E表示该元素的数据类型 |
| E |
Last() 返回此集合中的最后一个元素 |
| E |
poolFirst() 获取并删除此集合中的第一个元素 |
| E |
poolLast() 获取并移除此集合中的最后一个元素 |
| SortedSet |
subSet(E fromElemt ,E toElemt) 返回集合中[ fromElemt , toElemt )间的所有对象的新集合 |
| SortedSet |
headSet(E toElemt) 返回集合中[ 0, toElemt )间的所有对象的新集合 |
| SortedSet |
tailSet(E fromElemt) 返回集合中[ fromElemt , finalElemt ]间的所有对象的新集合 |
下面我们通过一个学生成绩的程序范例,来演示一下如何使用。
//创建TreeSet集合
TreeSet scores = new TreeSet();
scores.add(98.0);
scores.add(100.0);
scores.add(85.0);
scores.add(54.0);
scores.add(45.0);
System.out.println("= 学生成绩从低到高的排序为 =\n"+scores);
//查询不及格的学生
SortedSet Low = scores.headSet(60.0);
System.out.println("= 不及格的学生成绩从低到高的排序为 =\n"+Low);
//查询及格的学生
SortedSet Hight = scores.tailSet(60.0);
System.out.println("= 及格的学生成绩从低到高的排序为 =\n"+Hight); 输出结果如下所示。
= 学生成绩从低到高的排序为 =
[45.0, 54.0, 85.0, 98.0, 100.0]
= 不及格的学生成绩从低到高的排序为 =
[45.0, 54.0]
= 及格的学生成绩从低到高的排序为 =
[85.0, 98.0, 100.0]和HashSet不一样,因为TreeSet使用了排序,所以TreeSet集合只能添加相同数据类型的对象,不然没法比较从而抛出ClassCastException异常。另外还需要注意的,当程序修改了某个对象的属性之后,TreeSet并不会重写排序,也就是说,只有在对象添加时才会进行排序,所以最适合用TreeSet进行排序的时不可变类。
定制排序
TreeSet的自然排序是根据集合元素的大小,按照升序进行排列。开发者可以按照需求实现定制排序,例如以降序排列,则可以通过Comparator接口中的compara(T o1,T o2)方法。
想要实现定制排序,需要在创建TreeSet集合对象时,提供Comparator对象与该TreeSet集合关联。
//创建TreeSet集合
TreeSet scores = new TreeSet((o1,o2) ->{
//根据M对象的age属性来决定大小,age越大,M对象反而越小
return o1 > o2 ? -1:o1 < o2 ? 1:0;
});
scores.add(34);
scores.add(63);
scores.add(76);
scores.add(89);
scores.add(23);
System.out.println(scores); //输出结果:[89,76,63,34,23] 四、List集合
List接口主要有两个实现类:ArrayList类和LinkedList类。List集合的主要特征是元素以线性方式存储,元素存储是有序的,并且允许出现重复元素。这是因为List集合根据索引位置来检索元素,这与数组类似。
- ArrayList:该类底层采用长度可变的数组。允许对元素进行快速的随机访问,但是向ArrayList中插入与删除的速度相对较慢(看位置)。

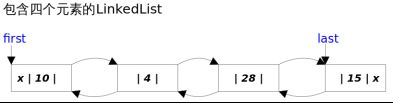
- LinkedList:该类底层采用双向链表数据结构。对顺序访问进行了优化,向List中插入和删除元素的速度较快,随机访问则相对较慢。LinkedList单独具有addFirst()、addLast()、getFirst()、getLast()、removeFirst()、removeLast()等方法,这些方法是的LinkedList可以作为堆栈、队列和双向队列使用。
List接口作为Collection接口的子接口,自然继承了Collection接口的所有方法。因为List是有序集合,因此增加了一些根据索引来操作集合元素的方法,这些方法如下列表所示。
| 返回类型 |
方法名及说明 |
| void |
add(int index,Object o) 将元素o插入到集合的指定索引处 |
| boolean |
addAll(int index,Collection c) 将集合c中的所有元素插入到List集合中的指定索引处 |
| Object |
get(int index) 获取指定索引处的元素 |
| int |
indexOf(Object o) 返回对象o在List集合中第一次出现的索引 |
| int |
lastIndexOf(Object o) 返回对象o在List集合中最后一次出现的索引 |
| Object |
remove(int index) 删除并返回索引为index处的元素 |
| Object |
set(int index,Object o) 返回并替换集合中索引为index的元素为o对象 |
| List |
subList(int formIndex,int toIndex) 返回索引为[formIndex , toIndex)之间的所有元素所组成的子集合 |
| void |
replaceAll(UnaryOperator uo) 按照uo计算规则重新设置List几何中的所有元素 |
| void |
sort(Comparator c) 根据c参数对List集合的元素排序 |
4.1 ArrayList类
ArrayList类是基于数组实现的List类,它除了包含Collection接口中的所有方法之外,还包括了List接口中所独有的方法。 ArrayList类的常用构造方法有如下两种重载方式。
- ArrayList() 构造一个初始容量为0的空列表
- ArrayList(Collection c) 构造一个包含指定Collection的元素列表。
接下来我们通过具体的程序范例来演示ArrayList所具有方法的用法。
List nums = new ArrayList();
nums.add(12);
nums.add(46);
nums.add(35);
nums.add(23);
nums.add(58);
nums.add(35);
System.out.println("默认排序:"+nums);
nums.add(2,67); //在索引2中添加新元素
//查询元素35第一次出现和最后一次出现的索引
System.out.println("35第一次出现的索引:"+nums.indexOf(35));
System.out.println("35最后一次出现的索引:"+nums.lastIndexOf(35));
//偶数元素的值降低一半
nums.replaceAll(obj-> (Integer)obj%2==0?(Integer)obj/2:(Integer)obj);
System.out.println("值改变后:"+nums);
//对List集合进行排序
//升序排序
nums.sort((a,b)-> (Integer)a-(Integer)b);
System.out.println("升序排序:"+nums);
//降序排序
nums.sort((b,a)-> (Integer)a-(Integer)b);
System.out.println("降序排序:"+nums);最终的输出结果如下所示
默认排序:[12, 46, 35, 23, 58, 35]
35第一次出现的索引:3
35最后一次出现的索引:6
值改变后:[6, 23, 67, 35, 23, 29, 35]
升序排序:[6, 23, 23, 29, 35, 35, 67]
降序排序:[67, 35, 35, 29, 23, 23, 6]另外需要注意的,当使用索引来进行操作的时候,指定的索引必须是List集合的有效索引,否则程序抛出异常。
4.2 LinkedList实现类
LinkedList类是List接口的实现类,所以可以根据索引来随机访问集合中的元素,除此之外,LinkedList还实现了Deque接口,可以被当成双端队列来使用,因此既可以被当成“栈”来使用,也可以当成“队列”使用。
下面范例代码分别示范了LinkedList作为List集合、双端队列、栈的用法。
LinkedList persons = new LinkedList();
//将用户添加到队列的头部(相当于栈的顶部)
persons.offerFirst("李一");
//将用户加入队列的尾部
persons.offer("陈二");
//将用户加入到栈的顶部
persons.push("张三");
//将用户加入队列的尾部
persons.offerLast("李四");
//输出集合元素
System.out.println("【输出集合元素】:"+persons);
System.out.println("访问栈顶元素:"+persons.peekFirst());
System.out.println("访问队列最后一个元素:"+persons.peekLast());
System.out.println("将栈顶元素弹出栈:"+persons.pop());
System.out.println("【输出集合元素】:"+persons);
System.out.println("访问并删除第一个元素:"+persons.pollFirst());
System.out.println("访问并删除最后一个元素:"+persons.pollLast());
System.out.println("【输出集合元素】:"+persons);最终的输出结果如下所示。
【输出集合元素】:[张三, 李一, 陈二, 李四]
访问栈顶元素:张三
访问队列最后一个元素:李四
将栈顶元素弹出栈:张三
【输出集合元素】:[李一, 陈二, 李四]
访问并删除队列的第一个删除:李一
访问并删除队列的最后一个删除:李四
【输出集合元素】:[陈二]使用LinkedList集合,可以对集合的首部或尾部进行插入或者删除操作。LinkedList类除了包含Collection接口和List接口中的所有方法之外,还特别提供了如下的方法使其能够向栈和队列一样对元素进行操作。
| 返回类型 |
方法名及说明 |
| void |
addFirst(E e) 将指定元素添加到此集合的开头 |
| void |
addLast(E e) 将指定元素添加到此集合的末尾 |
| E |
getFirst() 返回此集合的第一个元素 |
| E |
getLast() 返回此集合的最后一个元素 |
| E |
removeFirst() 删除此集合中的第一个元素 |
| E |
removeLast() 删除此集合中的最后一个元素 |
面范例代码分别示范了上述方法的使用
LinkedList persons = new LinkedList();
persons.add("陈二");
persons.add("张三");
persons.addFirst("刘一"); //将刘一添加到开头
persons.addLast("李四"); //将李四添加到末尾
System.out.println("【输出添加后的集合元素】:"+persons);
//输出开头元素
persons.removeFirst();
//删除末尾元素
persons.removeLast();
System.out.println("【输出删除后的集合元素】:"+persons);最终的输出结果如下所示。
【输出添加后的集合元素】:[刘一, 陈二, 张三, 李四]
【输出删除后的集合元素】:[陈二, 张三]五、Map集合
Map用于保存具有映射关系的数据,该数据是一种键—值对(Key-Value),因此Map集合保存着两组值,一组用于保存Key值,另外一组保存key值所对应的Value。其中,键对象不允许重复,而值对象可以重复,两者都可以是任何引用类型的数据。
Key值之所以不允许重复,是因为key和Value之间存在单向一对一关系,通过唯一的key总能找到确定的value。从Map中取出数据时,只要给出指定的Key就可取出对应的Value。

Map接口的实现类主要有两个:HashMap和TreeMap类。其中HashMap类按哈希算法来存取键对象,而TreeMap类可以对键对象进行排序。
- HashMap:该类基于哈希表实现的映射操作,允许使用null值和null键。和HashSet一样,HashMap也不保证映射的顺序,特别是不保证顺序恒久不变。

HashMap的实现方式是数组+链表。put过程,首先通过key对象的hash值,然后根据hash值定位该key在数组中的索引查找数据。为了解决哈希碰撞问题,数组的每一个元素又是一个链表,这样hash值相同但是实际不相同的key会在同一个链表上。而get过程大致相同,先根据key取hash值,根据hash值拿到数组的索引,通过索引拿到链表,遍历链表找到key对应的节点获取数据。
- TreeMap:该类的底层基于红黑树的NavigableMap实现,按照键对象的自然顺序进行排序,或者根据创建时提供的Comparator进行排序(即定制排序)。

通过上面的两个子类,我们可以发现Ma中的key集和Set集合里元素的存储方式非常像,都是通过哈希算法来存储对象。Map子类和Set子类在名字上也是惊人的相似,比如Set接口下有HashSet、LinkedHashSet、TreeSet等子接口和实现类,而Map接口下则有HashMap、LinkedHashMap、TreeMap等子接口和实现类。
Map接口中定义的方法如下所示。
| 返回类型 |
方法名及说明 |
| E |
put(E key,E value) 添加一个键值对,如果Map中存在该键值对则覆盖原来的键值对 |
| void |
pullAll(Map m) 将m集合中的键值对复制到本Map集合。 |
| E |
get(E key) 返回key所对应的value,如果不存在,则返回null。 |
| E |
remove(E key) 删除并返回指定key所对应的键值对,如果不存在,则返回null。 |
| Collection |
values() 返回Map里所有value所组成的Collection对象 |
| int |
size() 返回Map中的键值对总数 |
| boolean |
containsKey(Object key) 查询Map中是否包含指定的Key,如果包含则返回true |
| boolean |
containsValue(Object value) 查询Map中是否包含一个或多个Value,如果包含则返回true |
| void |
clear() 删除Map中所有键值对 |
| boolean |
isEmpty() 查询该Map是否为空 |
| Set |
entrySet() 返回Map中所有键值对所组成的Set集合。 |
| Set |
keySet() 返回Map中所有Key组成的Set集合 |
需要知道的是,Map中包括了一个内部类Entry,该类封装了一个键值对,Entry包含如下所示的三个方法。
| 返回类型 |
方法名及说明 |
| E |
getKey() 返回Entry里包含的key值 |
| void |
getValue() 返回Entry里包含的value值 |
| E |
setValue(E value) 设置并返回Entry里包含的value值 |
范例程序如下所示
Map m = new HashMap();
//成对放入多个键值对
m.put("person1", "张三");
m.put("person2", "李四");
m.put("person3", "王五");
System.out.println(m);
System.out.println("获取指定键:"+m.get("person2"));
System.out.println(m.values());
System.out.println("包含person2? "+m.containsKey("person2"));
System.out.println("包含李四? "+m.containsValue("李四"));输出结果如下所示。
{person3=王五, person2=李四, person1=张三}
获取指定键:李四
[王五, 李四, 张三]
包含person2? true
包含李四? true5.1 Map集合的迭代方式
Map m = new HashMap();
m.put("person1", "张三");
m.put("person2", "李四");
m.put("person3", "王五");
System.out.println("== 第一种:遍历Key对象,根据key值获取value ==");
for(Object key:m.keySet()){
System.out.println(key + " --> " + m.get(key));
}
System.out.println("== 第二种:遍历所有value组成的Collection类型 ==");
Collection c = m.values();
c.forEach(elemt -> System.out.println(elemt));
System.out.println("== 第三种:遍历所有键值对的Set集合,调用Entry内部类 ==");
Set entrys = m.entrySet();
for(Map.Entry entry:entrys){
System.out.println(entry.getKey()+"-->"+entry.getValue());
}
System.out.println("== 第四种:使用Java8新增的forEach()类 ==");
m.forEach((key,value) -> {
System.out.println(key + " --> " + value);
}); 输出结果如下所示
== 第一种:遍历Map集合中的Key对象,根据key值遍历value ==
person3 --> 王五
person2 --> 李四
person1 --> 张三
== 第二种:遍历所有value组成的Collection类型 ==
王五
李四
张三
== 第三种:遍历所有键值对所组成的Set集合,调用Entry内部类 ==
person3 --> 王五
person2 --> 李四
person1 --> 张三
== 第四种:使用Java8新增的forEach()类 ==
person3 --> 王五
person2 --> 李四
person1 --> 张三5.2 HashSet和HashMap的负载因子
对于HashSet及其子类而言,它们采用hash算法决定集合中元素的存储位置,并通过hash算法来控制集合大小。
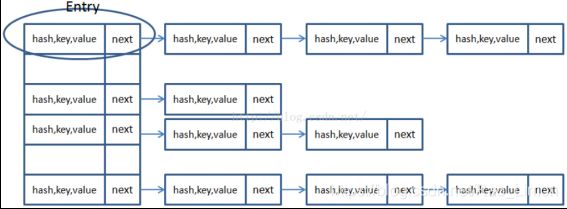
对于HashMap、Hashtable及其子类而言,它们采用hash算法来决定Map中key的存储位置,每个位置也称为“桶(bucket)”。通常情况下,单个桶里存储一个元素,此时的性能是最好的;hash算法根据hashCode值计算出桶的存储位置,从而取出里面的数据。由于hash表的状态是open的,所以在发生哈希冲突的时候,单个桶中会以链表的形式存储多个元素,必须按顺序搜索。如下图显示了发生“hash冲突”是的hash表结构示意图。
HashSet和HashMap具有以下属性
- 大小(size):元素数目。例如上面的示意图中就有13个元素。
- 容量(capacity):哈希表中桶的数量。例如上面的示意图中就有6个桶。
- 初始容量(initial capacity):创建HashSet和HashMap时桶的数量。在这两个类的构造方法中允许设置初始容量。
- 负载因子(load factor):等于size/capacity。负载因子为0,表示空的哈希表;负载因子为0.5,表示半满的哈希表,剩下以此类推;当负载因子达到用户设定值之后,HashSet或HashMap会自动的成倍增加容量,并重新分配原有元素的位置。轻负载的哈希表冲突最少,最适合插入和查找。
HashSet和HashMap的默认负载因子为0.75,它表示除非哈希表的3/4以及被填满,否则不会自动成倍地添加哈希表的容量。这个默认值很好地权衡了时间于空间的成本。如果负载因子较低,虽然会提高查询数据的性能,但是会增加Hash表所占用的内存开销;如果负载因子过高,虽然会降低Hash表对内存空间的需求,但会提高查找数据的时间开销,而查找是最频繁的操作,HashMap类中的get()和put()方法中都涉及到查找操作,因此负载因子不宜设得很高。