Python-爬虫(requests库、二进制数据(图片)获取,GET/POST请求、session请求)
文章目录
- 1.requests常用的属性
-
- requests向网页模拟GET请求
- 2. 获取图片练习(二进制数据获取)
- 3.发送POST请求
- 3. session登录请求
HTTP请求中:
- GET方法:常用获取数据的请求(爬取数据等操作)
- POST方法:常用在服务器提供数据(登录等操作)
中文汉字的编码与解码
from urllib import parse
# https://www.baidu.com/s?wd=%E4%B8%AD%E5%8C%97%E5%A4%A7%E5%AD%A6
dit = {'wd': '中北大学'}
# 编码汉字
ret = parse.urlencode(dit)
print(ret)
# 解码汉字
ret = parse.unquote('https://www.baidu.com/s?wd=%E4%B8%AD%E5%8C%97%E5%A4%A7%E5%AD%A6')
print(ret)

1.requests常用的属性
get方法:
def get(url, params=None, **kwargs):
url:网址
params:传递表单数据。
**kwargs:字典数据传参,传递报文关键字参数。
函数返回一个响应对象。响应对象的常见属性和方法为:
- text:响应报文的内容,内容以字符串的形式返回
- content:返回二进制报文内容,通常回使用decode方法指定编码格式(默认utf-8)
- url:返回响应的url(重定向)
- status_code:响应状态码
- headers:返回请求报头的字段
- cookies:返回响应报文的cookies信息。
requests向网页模拟GET请求
import requests
# 确认请求数据链接在网页中
url = "https://movie.douban.com/"
# 确认网页请求方式
# 模拟访问浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'}
html = requests.get(url=url, headers=headers)
print(html.request.headers)
print(html.status_code)
if html.status_code == 200:
print(html.text)
确认需要的数据是否在响应中

注意如果需要频繁的访问网站,需要在请求时添加高匿名代理IP。
代理IP分为三类:
- 透明代理:告知网站自己的原IP和代理IP
- 匿名代理:告诉网站自己使用的代理IP
- 高匿名代理:不会告知原IP和自己使用了代理IP
2. 获取图片练习(二进制数据获取)
写入图片,视频。音乐时需要用字节流的形式写入.
import requests
# 确认数据链接状态
url = " https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png"
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
# stream=True 获取到的类似生成器 stream=False 获取到的类似列表,一般是用来读取大量数据的,使用列表内存可能不足
# 下载视频,或者图片时通常会使用这个选项,读取一张照片不需要这个选项
# response = requests.get(url, headers=header, stream=True)
response = requests.get(url, headers=header) # 图片是二进制数据,二进制数据没有编码
# 字符串切割,找到图片类型
img = url.split('/')[-1]
with open(img, "wb") as file:
# 写入图片,视频。音乐时需要用字节流的形式写入
file.write(response.content)

3.发送POST请求
确认链接,查看提交数据的表单
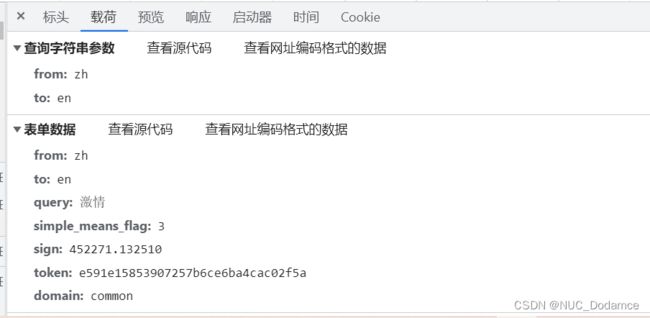
需要注意,这种二次请求的数据通过requests.post方法返回的是json数据
import requests
url = "https://fanyi.baidu.com/v2transapi?from=zh&to=en"
# 请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 "
"Safari/537.36",
# 网站有反扒,只写User-Agent不够,还需要写Cookie信息,最好在加上身份认证或者防盗链
"Cookie": "BAIDUID=7E863D9F0D3C12DC81B4F580C0AEFF2D:FG=1; BIDUPSID=7E863D9F0D3C12DC81B4F580C0AEFF2D; "
"PSTM=1658679521; BAIDUID_BFESS=7E863D9F0D3C12DC81B4F580C0AEFF2D:FG=1; "
"ZFY=yZGrpRy6f2iaROCD8YSCrSATq4Ylnv1Yj6XhnCd:ALlI:C; BAIDU_WISE_UID=wapp_1661562134473_675; "
"RT=\"z=1&dm=baidu.com&si=b5301f87-48f5-4fa4-80c4-8916a66e1271&ss=l7b76x2p&sl=0&tt=0&bcn=https%3A%2F"
"%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ul=4o9&nu=j83gp33&cl=4ou&hd=4sf\"; "
"H_PS_PSSID=36550_36465_36974_36885_37268_36570_36786_37134_26350_22160_37234; "
"BA_HECTOR=05a12k0kag248h00al8gdp3m1hgtd6l17; BDRCVFR[S4-dAuiWMmn]=FZ_Jfs2436CUAqWmykCULPYrWm1n1fz; "
"delPer=0; PSINO=2; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1661910807; APPGUIDE_10_0_2=1; "
"REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; "
"SOUND_PREFER_SWITCH=1; "
"ab_sr=1.0"
".1_MDRhYmJmMGZhNTE2NjM3MGU3OGQyZDQ5NjRjNjU5OTY0MGY3Y2M2YTFlNjlkOTkzZTUyNjdh"
"NGE2NjQ0NWY1ZTUxZGMzZjk0MTVjMmNkOGY4ZTM2MjJlMzIzOWY4NDdhOWJmNjQxNTJmM2YxNGE1MTIwNTY1ZTZ"
"mOTdiMzE5NGM3ZTJjOTY4MDNiNTgyMjA2NjU4NjJiNTI0YWEwMzY4ZA==; "
"Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1661910848 ",
"Acs-Token": "1661842972316_1661910848422_JiK0+leUgCidRZ/X7OH+W8tCn5h1rbnpGWWOAbFznEDSh6"
"+TEgDLhXbQpnh4QztBZQA81rSBz8jXyV6XSBK9bC4EV9dNoLRW1ZTWGvBvxSatuWSrWDA+HYcLDwKGIFABCXKToxRxkVSFLy6ey"
"+Blfb3G6RgyAnpoYHGbB1wRJiYLI0OSQWMAnSuDCI1q7MzvBS2Gvvy/YACTUb69YhuvCaZPeIaWWeUGhUQ3p+OgJ2"
"/hMTaOPdNhmXdBAiIB1/XOaq5XQA7zYLHi2UoeTeT3y7m9kHzUdTULp9JAMf"
"//ov92SamqtZYRf9kyvcvd8KdZkzSnvHuEQtVIwB6rX6rFCw== "
}
# post发送的参数
data = {
'from': 'zh',
'to': 'en',
'query': '激情',
'simple_means_flag': '3',
'sign': '452271.132510',
'token': 'e591e15853907257b6ce6ba4cac02f5a',
'domain': 'common'
}
response = requests.post(url, headers=header, data=data)
# 二次请求的数据是属于json数据(嵌套的字典)
# print(response.json()['trans_result']['data'][0]['dst'])
data = response.json()['trans_result']['data'][0]
# print(data)
print(data['dst'], end="翻译为")
print(data['src'])
注意,这里只能查看passion这个单词,如果换单词,提交的参数需要改变。

3. session登录请求
session_id:绘画维持密钥,通过密钥判断是否登录
session常用于需要登录后获取数据的场景。
eg:网站我的主页信息
模拟登录:
post需要传递的参数可以查看表单,注意这里的表单账号密码是明文的

import requests
url = 'https://www.yaozh.com/login'
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
data = {
'type': '0',
'username': '***', # 自己的账号密码
'pwd': '*****',
'country': '86_zh-CN',
'formhash': '222C1F1A26',
'backurl': '%2F%2Fwww.yaozh.com'
}
response = requests.post(url, headers=header, data=data)
print(response.text)
显示成功了

使用session可以保存登录状态,通过返回的状态可以访问需要登录的页面,如下:
import requests
url = 'https://www.yaozh.com/login'
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
data = {
'type': '0',
'username': '****',
'pwd': '****',
'country': '86_zh-CN',
'formhash': '222C1F1A26',
'backurl': '%2F%2Fwww.yaozh.com'
}
session = requests.Session()
response = session.post(url, headers=header, data=data)
# print(response)
# session中会保存session_id,可以访问个人主页
user_msg = session.get("https://www.yaozh.com/member/", headers=header)
if user_msg.status_code == 200:
print('获取用户主页完成')
with open('药智网登录页面.html', "w", encoding='utf-8') as file:
# 写入图片,视频。音乐时需要用字节流的形式写入
file.write(user_msg.text)

成功获取到登录个人信息