机器学习之Word2Vec
本文为作者学习Word2Vec算法后的整理笔记,仅供学习使用!
1、概述
Word2vec是Geogle公司2013年开源的一款用于训练词向量的软件工具。可以根据给定的语料库,通过优化后的训练 模型快速有效地将一个词语表达成向量形式。
2、语言模型
统计语言模型用于统计一个句子出现概率的模型。
给定一个由n个词语按顺序组成的句子S = (W1, W2, W3, ..., WN),那么P(S)即为语言模型。
P(S) = P(W1, W2, W3, ..., WN) = P(W1)P(W2|W1)P(W3|W1,W2)...P(WN|W1, W2,...,WN-1)
由于下一个词出现的概率跟前面出现的词都相关,会导致:
(1)、数据过于稀疏
(2)、参数空间太大
3、N-gram模型
为解决上述统计语言模型的缺陷,诞生了N-gram模型,意思是:制定参数N,使下一个词只与其前面N个词相关。
令 N = 2,此时,语言模型:
P(S) = P(W1)P(W2|W1)P(W3|W1,W2)P(W4|W2,W3)...P(WN|WN-2,WN-1)
若语料库的大小为N, 则模型参数的两级为(O(N ** n))
4、词向量
词向量是表示词语特征的常用方式。词向量每一维的值代表一个具有一定的语义和语法上解释的特征,因而,可以将词向量的每一维称为一个词语特征。
5、哈夫曼树
哈夫曼树是一种带权路径长度最短的二叉树,也称为最优二叉树。
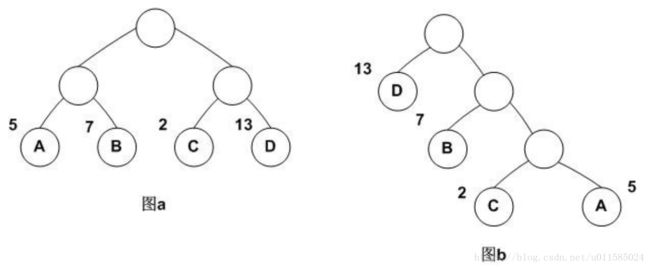
上图中的带权路径分别为:
图a:5 * 2 + 7 * 2 + 2 * 2 + 13 * 2 = 54
图b:13 * 1 + 7 * 2 + 2 * 3 + 5 * 3 = 48
6、适用Gensim构建词向量模型
(1)获取语料库
本例使用维基百科中的数据作为语料库,维基百科下载链接:https://dumps.wikimedia.org/zhwiki/
(2)提取语料库
本例使用WikiExtractor提取预料库信息,使用
python WikiExtractor.py -b 500M -o zhwiki-20180701-pages-articles2.zh.text zhwiki-20180701-pages-articles2.xml-p162888p544640.bz2
可以将语料库信息提取到一个文件下,若语料库的信息太大,则可以使用
python WikiExtractor.py -o zhwiki-20180701-pages-articles.zh.text zhwiki-20180701-pages-articles2.xml-p162888p544640.bz2
可以将语料库信息提取出来,并按顺序分多个文件夹和文件存放。
WikiExtractor下载地址:https://github.com/attardi/wikiextractor/blob/master/WikiExtractor.py
(3)繁简转换
由于在维基百科下载下来的预料是繁体的,因而需要将其转换为简体中文,本例使用opencc转换:
opencc -i wiki_00 -o wiki_00.txt -c t2s.json
(4)分词
对语料库中的句子进行分词处理,并且排除停用词,本例中使用jieba分词
filename = "wiki_00.txt"
filename_output = "wiki_00_cut.txt"
filename_stopWords = "stopwords.txt"
def cut_words(sentences, stopWords):
if "\n" in sentences:
sentences = sentences.replace("\n", "")
cut_line = list(jieba.cut(sentences))
curr_line = [ss for ss in cut_line if ss not in stopWords]
return curr_line
def read_file(filename):
file_input = open(filename, 'r', encoding='utf-8')
return file_input
def get_stop_words(filename):
context = []
with open(filename, 'r', encoding='utf-8') as f:
line = f.readline()
while line:
context.append(line[:-1])
line = f.readline()
return context
def get_jieba_cut_words(filename, filename_output, filename_stopWords):
file_input = read_file(filename)
stop_words = get_stop_words(filename_stopWords)
file_output = open(filename_output, 'w', encoding='utf-8')
line_num = 1
line = file_input.readline()
while line:
print('--- process ---', line_num, ' article ---')
line_seq = cut_words(line, stop_words)
file_output.writelines(" ".join(line_seq))
line_num += 1
line = file_input.readline()
file_output.close()
file_input.close()(5)构建词向量模型,本例中使用Gensim构建
import os.path
import logging
from gensim.models import word2vec
from gensim.models.word2vec import LineSentence
from gensim.corpora import WikiCorpus
import multiprocessing
import sys
if __name__ == "__main__":
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 4:
print (globals()['__doc__'] % locals())
sys.exit(1)
inp, outp1, outp2 = sys.argv[1:4]
model = word2vec.Word2Vec(LineSentence(inp), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count())
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)使用python Word2VecDemo1.py wiki_00_cut.txt wiki.zh.text.model wiki.zh.text.vector运行上述代码生成词向量模型。
(6)测试模型
from gensim.models import word2vec
def get_model_similar():
wiki_model = word2vec.Word2Vec.load("wiki.zh.text.model")
test_words = ['纸张', '渔业', '扇贝', '温度', '股票']
for i in range(5):
res = wiki_model.most_similar(test_words[i])
print(test_words[i])
print(res)
get_model_similar()运行结果:
纸张
[('油墨', 0.847545862197876), ('墨水', 0.8354381322860718), ('纸质', 0.8264344334602356), ('印花', 0.8180996179580688), ('胶卷', 0.7882717251777649), ('涂层', 0.7872985601425171), ('颜料', 0.7841143608093262), ('成品', 0.7800428867340088), ('塑料', 0.7761532068252563), ('磁带', 0.7760943174362183)]
渔业
[('畜牧业', 0.8647764921188354), ('养殖业', 0.8417356610298157), ('旅游业', 0.8269733190536499), ('林业', 0.8151427507400513), ('养殖', 0.8093267679214478), ('水产', 0.8041982650756836), ('农业', 0.7882853150367737), ('支柱产业', 0.7781322002410889), ('农产品', 0.7731583118438721), ('采矿业', 0.7720707654953003)]
扇贝
[('混交林', 0.8815895318984985), ('草鱼', 0.8798670768737793), ('莲藕', 0.8774721622467041), ('豆类', 0.8768916130065918), ('鲶鱼', 0.8762664794921875), ('银杏', 0.8762453198432922), ('贝类', 0.8759191036224365), ('柚子', 0.8737662434577942), ('甲壳类', 0.8704067468643188), ('鲫鱼', 0.8701832890510559)]
温度
[('湿度', 0.8674002885818481), ('低温', 0.8387120366096497), ('气压', 0.8375299572944641), ('太阳辐射', 0.8345661759376526), ('高温', 0.8338655233383179), ('盐度', 0.8064085245132446), ('浓度', 0.8030012845993042), ('流速', 0.7989178895950317), ('热量', 0.7929639220237732), ('沸点', 0.7916314601898193)]
股票
[('公司股票', 0.862712025642395), ('投资人', 0.8302319645881653), ('证券', 0.8221428394317627), ('债券', 0.8188408613204956), ('获利', 0.8144993782043457), ('股息', 0.8143629431724548), ('抛售', 0.8073290586471558), ('市值', 0.8073103427886963), ('投资者', 0.8010855913162231), ('期货', 0.8007993698120117)]