py基础系列(完结):文件
py基础系列(五 完结):文件
- 文件的基本概念
-
- 文本文件
- 二进制文件
- 文件基本操作
-
- 文本文件打开
- 二进制文件打开
- 文件对象常用属性
- 文件对象的常用方法
- 文件对象的常用方法
- 关闭文件
- 读/写文本文件
-
- 写入文本文件
- 读取文本文件
- 读/写二进制文件
-
- 写入二进制文件
- 读取二进制文件
- 文件定位
- 读/写xlsx文件
-
- 创建excel工作簿
- 创建工作表
- 保存为excel文件
- 修改单元格的数据
- 读取excel单元格中的数据
- 文件和文件夹操作
-
- os模块
- os.path模块
py基础系列大部分是 B站李老师的 Python编程和数据分析基础 课件上的内容加上自己练习和学习过程中的一些补充。这个系列到这里就算完结了,下一个阶段py爬虫以及py高级特性。
文件的基本概念
文件按逻辑来划分,可以分 文本文件 和 二进制文件。
实质上文本文件也是广义上的二进制文件,毕竟计算机的硬件决定了其能存储的就是二进制数。
文本文件
文本文件将数据视为字符,在文件中保存每个字符的对应的编码值(编码类型有ASCII, GBK, UTF-8等),因此文本文件是按编码的值存储的,由于每个字符对应的编码值是固定的,文本文件每条数据通常是固定长度的。
应用:
常见文本文件: 记事本文件(.txt), 源代码,网页,日志等。
二进制文件
二进制文件把数据的二进制值存储到文件中,是基于值存储的。
常见二进制文件:Word/Excel/图片/音乐等文件。
注意:文本文件和二进制文件存储是不同的。
例如:
12视为文本字符“12”存储需要2个字节(一个字符 占一个字节,存储为:00110001 00110010 )
这是因为字符的"12"被理解为’1’和’2’,而这两个的字符的ASCII码值分别位49、50,因此存储的时49、50对应的二进制数值。如按值理解被视为整数,需要4个字节(一个整数占32位)00000000 00000000 00001100。
文件基本操作
打开文件时需指定是文本文件还是二进制文件(“t"或"b”),默认为"t"(文本打开)。
文本文件打开
fw = open(r"d:\test.txt", “wt”) # w写, t文本 r为原生字符串避免被错误理解为转义字符
#也可写为open(“d:\test.txt”, “w”)来防止二义性
fr = open(r"d:\file1.txt", “r”) # 只读 , “r” 可省略
该语句的作用是以“r”只读方式打开d盘根目录下的文本文件"file1.txt",‘r’ 时要求文件必须事先存在。
二进制文件打开
fbw=open(r"d:\file2.dat",“wb”)
该语句以“只写”方式打开d盘的二进制文件"file2.dat"
fr=open(r"d:\test.txt",‘r’,encoding=“utf-8”)
该语句以“只读”方式打开d盘下文本文件"test.txt",指定编码方式为"utf-8"
Python默认按操作系统平台的编码处理文件。
Windows系统默认编码为GBK,.txt文件一般是用utf-8编码保存的。因此如果是用记事本打开用utf-8编码的文件必须指定打开的编码方式。
GBK和utf-8两种编码的
GBK编码:一个汉字需要二字节

utf-8编码:一个汉字需要三个字节

文件对象常用属性
使用ope(),返回一个可迭代的文件
文件对象常用属性如下
| 属 性 | 类 型 | 说 明 |
|---|---|---|
| closed | 布尔型 | 判断文件是否关闭,关闭为True,否则为False |
| mode | 字符串 | 文件的打开模式 |
| name | 字符串 | 文件的名称 |

文件对象的常用方法
文件对象的常用方法
| 文件对象的方法 | 功 能 | 返 回 值 |
|---|---|---|
| close() | 把缓冲区的内容写入文件,关闭文件并释放缓冲区 | 无 |
| flush() | 把缓冲区的内容写入文件,不关闭文件 | 无 |
| read([size]) | 从文件读取指定的字符数,若未给定则读取所有内容 | 文件中读取的字符 |
| readline() | 从文件中读取一行,包括"\n"字符 | 从文件中读取的一行字符串 |
| readlines() | 读取所有行(直到文件结束符EOF)并返回列表 | 字符串列表,包含所有的行 |
| seek(offset [,whence]) | 移动文件指针。offset:开始的偏移量,代表需要偏移的字节数;whence:可选0/1/2,代表不同的起点位置 | 无 |
| tell() | 返回文件指针的当前位置 | 指针的当前位置 |
| write(s) | 向文件中写入单个字符串 | 写入的字符长度 |
| writelines(s) | 向文件中写入一个字符串序列 | 无 |
关闭文件
完成文件操作后,一定要关闭文件才能保存修改并释放文件。
关键字with可以自动管理资源,在退出with时会自动关闭文件
with open(文件名, 文件模式) as fp:
s = fp.read() # with语句结束时,会自动关闭文件
t1.txt文件内容如下:
你 好!
111
222
This is python,你好吗?

with open() as f: #这里的f为输入输出流包装器对象
for i in f: #这里的i为列表 为每一行数据
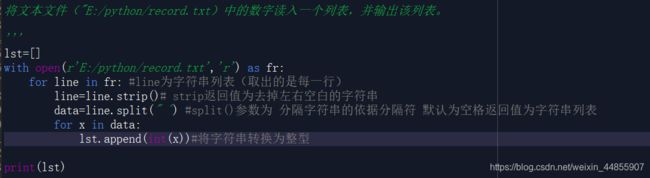
读/写文本文件
写入文本文件


注意: 数值必须转为字符串才能写到文本文件中。
读取文本文件


读/写二进制文件
把内存中的数据对象写入二进制文件称为序列化,从二进制文件读出并重建原数据对象称为反序列化。这些操作可以借助pickle模块(py自带)。模块中的dump是写入函数,load是读出函数.
写入二进制文件
调用形式:
pickle.dump(写入对象,文件对象)
写入对象:数值、字符串、列表、元组、字典等。
文件对象:函数open()打开的文件对象,将各类数据写入其中。
将如下数据写入二进制文件binary.dat中
import pickle
a = 1234
b = 3.14159
c = "程序"
d = ['a', 'b', 'c']
e = {"张":60, "王":70, "李":80}
with open("binary.dat", "wb") as f: # b不能省略
pickle.dump(a, f)
pickle.dump(b, f)
pickle.dump(c, f)
pickle.dump(d, f)
pickle.dump(e, f)
读取二进制文件
读取并输出二进制文件"binary.dat"中的数据。
import pickle
with open("binary.dat", "rb") as f:
a = pickle.load(f) # 按存入的顺序依次读出
b = pickle.load(f)
c = pickle.load(f)
d = pickle.load(f)
e = pickle.load(f)
print(a, b, c, d, e)
注意:二进制文件的数据格式不统一,所以存入/读出一般应使用同样的库。dump()和load()都是pickle库的,所以会自动处理不同数据之间的边界。
文件定位
文件指针用于标示文件当前读/写位置。读写时,都从文件指针的当前位置开始,根据读写的数据量向后移动文件指针。文件对象的函数tell()返回文件指针的当前位置。文件刚打开时指针指向0位置。
文件对象的seek()方法可以移动文件指针。
语法:
f.seek(偏移值[,起点])
偏移值表示移动的距离
起点表示从哪里开始移动:默认为0,表示从文件头开始,1表示从当前位置开始,2表示从尾部开始。
f.seek(10) # 移动到距离文件头部10个字符处
f.seek(4, 1) # 从当前位置再向后(尾部)移动4字节
f.seek(-3, 1) # 从当前位置再向前(头部)移动3字节
f.seek(-6, 2) # 移到距离文件尾部 6个字节处
读/写xlsx文件
读写表格文件是通过包openpyxl进行操作的,openpyxl是读写xlsx文件的第三方包,可通过安装命令:
pip install openpyxl 安装
创建excel工作簿
wb=Workbook() #得到新的工作簿对象wb
创建工作表
wb.create_sheet("工作表名字") # 创建给定名字的工作表
保存为excel文件
wb.save("文件名.xlsx") # 创建给定名字的工作表
修改单元格的数据
要修改表格数据,需要获取工作簿对象。有以下两种方法获得:
(1)、用Workbook对象的worksheets属性,该属性是一个Worksheet 对象列表,如ws = wb.worksheets[1];
(2)、通过索引方式,下标为工作表的名字,如ws=wb[‘first’]。
from openpyxl import Workbook, load_workbook
wb = load_workbook("test.xlsx") # 文件存在且不能已被Excel打开
ws = wb["first"] # first表应存在
# 各种访问单元格的语法
ws['A1'] = "数学" # 行列坐标
ws['b1'] = "语文" ws.cell(2, 1, 90) # 第2行第1列 ws.cell(2, 2, 91) # 第2行第2列
ws.append([80, 81])
ws['c2'] = "=sum(A2:B2)" #将c2这一单元格赋值为=sum(A2:B2) 表格自动求和
ws['c3'] = "=sum(A3:B3)"
wb.save("test.xlsx") # 注意要保存文件
读取excel单元格中的数据
可以通过工作表对象的索引访问单元格或者通过cell对象 其value对象就是单元格的值
官网: http://yumos.gitee.io/openpyxl3.0/
文件和文件夹操作
python操作文件和文件夹主要通过os模块和os.path模块,这两个模块都是Python的标准库。其实win系统也自带了一些操作文件夹和文件的命令,如mkdir、rmdir、
os模块
| 方 法 | 功 能 说 明 |
|---|---|
| rename(src, dst) | 重命名文件或目录,兼具文件移动功能 |
| remove(path) | 删除指定的文件,要求用户拥有删除文件的权限,并且文件没有只读或其他特殊属性 |
| rmdir(path) | 删除文件夹,文件夹有只读属性时也可以删除,但是必须为空 |
| mkdir(path) | 创建子文件夹 |
| chdir(path) | 把path设为当前工作目录 |
| getcwd() | 返回当前工作目录 |
| listdir(path) | |
| 返回path目录下的文件和目录列表 | |
| startfile(filepath,operation) | 使用关联的应用程序打开指定文件 |
| system() | 启动外部程序 |
注意: 使用os.rmdir(“文件夹名”),该文件夹必须为空。
删除非空文件夹需使用如下命令:
import shutil
shutil.rmtree("文件夹名")
另os模块没有复制文件命令,需借助shutil,命令为:
shutil.copyfile('源文件','目标文件' ) #注意该复制只能得到同目录的目标文件, 也就是目标文件不能指定路径
os.listdir(path)的功能是返回path目录下的文件名和文件夹名列表,对该列表递归遍历即可得到path下的所有文件 和子文件夹
from os.path import isfile, isdir
from os import listdir
def traverseDir(path):
for p in listdir(path):
subPath = path + "\\" + p
if isfile(subPath):
print(subPath)
elif isdir(subPath):
print(subPath)
traverseDir(subPath)
traverseDir("E:\\python")
os.path模块
| 方 法 | 功 能 说 明 |
|---|---|
| isdir(path) | 判断path是否为文件夹 |
| isfile(path) | 判断path是否为文件 |
| basename(path) | 返回指定路径的最后一个组成部分 |
| dirname(path) | 返回给定路径的文件夹部分如(E:/python/testdata/data.txt,返回该路径的文件夹部分E:/python/testdata) |
| exists(path) | 判断文件是否存在 |
| getsize(filename) | 返回文件的大小 |
| join(path, *paths) | 连接两个或多个path |
| splitext(path) | 从路径中分隔文件的扩展名 |
In []: os.path.dirname('E:\\python\\tempdata\\data.txt') #返回该路径的文件夹部分 加\\是为了防止转义
Out[]: 'E:\\python\\tempdata'
In []: os.path.basename('E:\\python\\tempdata')
Out[]: 'tempdata'
In []: os.path.basename('E:\\python\\tempdata\\data.txt') #返回该路径的最后一个组成部分
Out[]: 'data.txt'
In []: os.path.join('E:\\python\\testdata', 'data.txt') #将两个路径连接起来
Out[]: 'E:\\python\\testdata\\data.txt'
In []: os.path.splitext('E:\\python\\testdata\\data.txt') #从路径中分割出文件的扩展名,它的返回值是一个包含两个元素(路径和扩展名)的元组
Out[]: ('E:\\python\\testdata\\data', '.txt')
os.path.dirname('D:\\Workspace\\tmh\\t7.txt') #返回该路径的文件夹部分'D:\\Workspace\\tmh'。
os.path.basename('D:\\Workspace\\tmh\\t7.txt') #返回路径的最后一个组成部分't7.txt'
os.path.basename('D:\\Workspace\\tmh') #返回该路径的最后一个组成部分'tmh'
由于自己的个人博客经常要使用图片,所以就写了个同一命名的小程序,方便外链。
批量修改图片名字为指定的格式小程序
def picRename(oldPath,newPath,s):
import os
if not os.path.exists(newPath):
os.mkdir(newPath)
i=0
for p in os.listdir(oldPath): #获得字符串列表
fPath=oldPath+"\\"+p
if os.path.isfile(fPath):
fname,ext=os.path.splitext(fPath)#得到主文件 扩展名
ext=ext.lower()
if ext in (['.jpg','.png','.jpeg']):
i+=1
newName=newPath+"\\"+s+str(i)+ext
os.rename(fPath,newName)
print('共修改了文件名{}个'.format(i))
picRename('E:\\python\\pic','E:\\python\\pic','theme') #将pic目录下的所有图片重命名为theme1、theme2……
参考资料:
B站李老师的 Python编程和数据分析基础