深入浅出 MyBatis 的一级、二级缓存机制
一、MyBatis 缓存
缓存就是内存中的数据,常常来自对数据库查询结果的保存。使用缓存,我们可以避免频繁与数据库进行交互,从而提高响应速度。
MyBatis 也提供了对缓存的支持,分为一级缓存和二级缓存,来看下下面这张图:
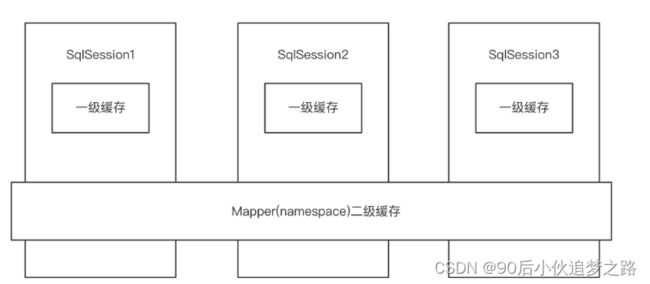
一级缓存是 SqlSession 级别的缓存。在操作数据库时需要构造 SqlSession 对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的是 SqlSession 之间的缓存数据区(HashMap)是互相不影响。
二级缓存是 Mapper 级别的缓存,多个 SqlSession 去操作同一个 Mapper 的 sql 语句,多个 SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的。
相信大家看完这张图和解释心里应该有个底了吧,这对后面分析 MyBatis 的一级、二级缓存机制很有帮助,那话不多说,我们直接进入主题了。
二、一级缓存
2.1 内部结构
在我们的应用运行期间,我们可能在一次数据库会话中,执行多次查询条件相同的 SQL,要你来设计的话你会如何考虑?没错,加缓存,MyBatis 也是这样去处理的,如果是相同的 SQL 语句,会优先命中一级缓存,避免直接对数据库进行查询,造成数据库的压力,以提高性能。具体执行过程如下图所示:
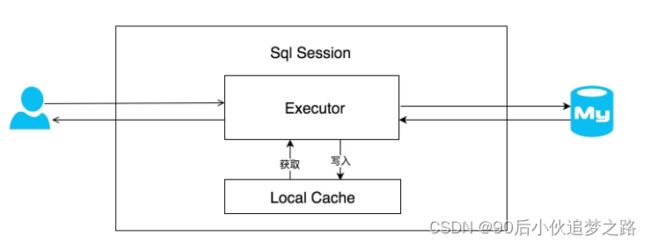
SqlSession 是一个接口,提供了一些 CRUD 的方法,而 SqlSession 的默认实现类是 DefaultSqlSession,DefaultSqlSession 类持有 Executor 接口对象,而 Executor 的默认实现是 BaseExecutor 对象,每个 BaseExecutor 对象都有一个 PerpetualCache 缓存,也就是上图的 Local Cache。
当用户发起查询时,MyBatis 根据当前执行的语句生成 MappedStatement,在 Local Cache 进行查询,如果缓存命中的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,结果写入 Local Cache,最后返回结果给用户。
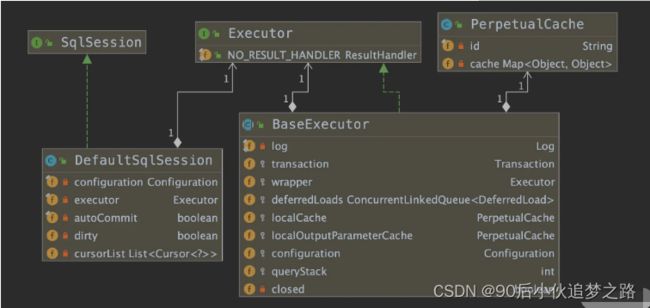
啊,关系还是有点抽象,感觉一直在套娃,没关系,看下面这张图你立马豁然开朗。
2.2 一级缓存配置
在 MyBatis 的配置文件中添加如下语句,就可以使用一级缓存。共有两个选项,SESSION 或者 STATEMENT,默认是 SESSION 级别,即在一个 MyBatis 会话中执行的所有语句,都会共享这一个缓存。一种是 STATEMENT 级别,可以理解为缓存只对当前执行的这一个 Statement 有效。
STATEMENT 级别粒度更细,我们上面说到,每个 SqlSession 中持有了 Executor,SqlSession 的默认实现类是 DefaultSqlSession,DefaultSqlSession 类持有 Executor 接口对象,而 Executor 的默认实现是 BaseExecutor 对象,每个 BaseExecutor 对象很多方法中都有传 MappedStatement 对象。所有 STATEMENT 级别是针对 SESSION 级别粒度更细的模式。
三、一级缓存实验
下面老周通过几组实验来带你了解 MyBatis 一级缓存的效果,我们首先准备一张简单的表 user,如下:
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(64) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
复制代码我们在测试类中加上带有 @Before 标注的 before 方法,省得每个单元测试方法都要重复获取 sqlSession 以及 userMapper。
@Before
public void before() throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("SqlMapConfig.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
sqlSession = sqlSessionFactory.openSession(true); // 自动提交事务
userMapper = sqlSession.getMapper(UserMapper.class);
}
复制代码3.1 实验1
开启一级缓存,范围为会话级别,调用三次 firstLevelCacheFindUserById,代码如下所示:
@Test
public void firstLevelCacheFindUserById() {
// 第一次查询id为1的用户
User user1 = userMapper.findUserById(1);
// 第二次查询id为1的用户
User user2 = userMapper.findUserById(1);
System.out.println(user1);
System.out.println(user2);
System.out.println(user1 == user2);
}
复制代码控制台日志输出:

我们可以看到,只有第一次真正查询了数据库,后续的查询使用了一级缓存。
3.2 实验2
增加了对数据库的修改操作,验证在一次数据库会话中,如果对数据库发生了修改操作,一级缓存是否会失效。
@Test
public void firstLevelCacheOfUpdate() {
// 第一次查询id为1的用户
User user1 = userMapper.findUserById(1);
System.out.println(user1);
// 更新用户
User user = new User();
user.setId(2);
user.setUsername("tom");
System.out.println("更新了" + userMapper.updateUser(user) + "个用户");
// 第二次查询id为1的用户
User user2 = userMapper.findUserById(1);
System.out.println(user2);
System.out.println(user1 == user2);
}
复制代码控制台日志输出:

我们可以看到,在修改操作后执行的相同查询,查询了数据库,一级缓存失效。
3.3 实验3
开启两个 SqlSession,在 sqlSession1 中查询数据,使一级缓存生效,在 sqlSession2 中更新数据库,验证一级缓存只在数据库会话内部共享。
@Test
public void firstLevelCacheOfScope() {
SqlSession sqlSession2 = sqlSessionFactory.openSession(true);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
System.out.println("userMapper读取数据: " + userMapper.findUserByI