Django实战技巧
Django实战
- 迭代思维与MVP产品规划
- 企业级数据库设计十个原则
- 初识Django
- 新建django项目
- 项目git地址
- 后台model常用方法
- 自定义后台数据字段展示
- 自定义后台管理分组
- 自定义manage.py命令行工具
- 后台支持字段搜索、条件筛选(过滤器)、字段排序
- 后台自定义数据导出动作(按钮)
- 更换admin后台主题grapelli
- 权限控制
-
- 数据权限
- 数据集权限
- 功能权限(菜单/按钮)
- 集成钉钉通知
- 集成registration(匿名用户注册登录)
- 添加简历model
- django middleware中间件小试
- django restframwork
- django-redis
- celery
-
- 异步任务
- 定时任务
- 文件上传
-
- 本地存储
- 云对象存储
- django signals信号
迭代思维与MVP产品规划
MVP: minimum viable product 最小可用产品。核心是忽略一切细枝末节,做合适的假设和简化,使用最短的时间开发出来。
MVP功能范围
产品的核心目标是什么?核心用户是谁?核心的场景是什么?
产品目标都需要在线上完成或者呈现吗?
最小MVP产品要做哪些事情?能够达到业务目标?
哪些功能不是在用户流程的核心路径上的?
做哪些简化和假设,能够在最短的时间交付产品,并且让业务流程跑起来?
企业级数据库设计十个原则
企业级数据库设计十个原则
初识Django
优点:
提供管理后台,方便开发
支持中间件
内置安全框架
丰富的第三方类库
缺点:
有点臃肿,不适合高并发的项目
单体应用,不易进行并行开发
Django admin 管理后台可以直接对数据库进行管理。特别适用内部管理系统的快速搭建。
新建django项目
pip install django==3.0.6 -i https://pypi.tuna.tsinghua.edu.cn/simple/
django-admin startproject meetingroom
python manage.py makemigrations
python manage.py migrate
python manage.py createsuperuser
python manage.py runserver 0.0.0.0:8888
├── db.sqlite3
├── manage.py
└── mettingroom
├── __init__.py
├── asgi.py # 异步网关接口
├── settings.py # 配置文件
├── urls.py # url
└── wsgi.py
项目git地址
https://gitee.com/zhangzzdd/meetingroom.git
后台model常用方法
actions(动作工具栏)
list_display(展示列表字段)
search_fields(添加搜索框)
list_filter(添加过滤器)
ordering(排序)
fields(限制可编辑字段)
分页 list_per_page/list_max_show_all
fieldsets(分组展示字段)
readonly_fields(字段只读)
save_model(钩子,保存对象时的额外操作)
自定义后台数据字段展示
默认只显示1个对象字段
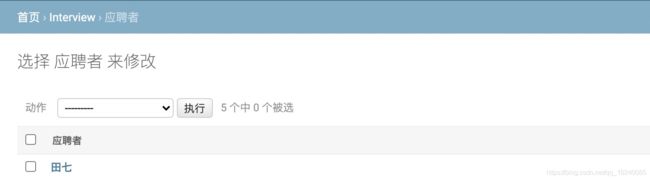
效果图

from django.contrib import admin
# Register your models here.
from interview.models import Candidate
class CandidateAdmin(admin.ModelAdmin):
# 不显示的字段
exclude = ('creator', 'created_date', 'modified_date')
# 显示的字段
list_display = (
'username', 'city', 'bachelor_school', 'first_score', 'first_result', 'first_interviewer_user', 'second_score',
'second_result', 'second_interviewer_user', 'hr_score', 'hr_result', 'hr_interviewer_user',)
自定义后台管理分组
默认后台字段没有分类,乱乱的

效果图
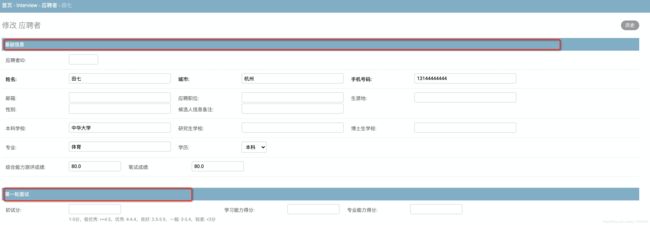
from django.contrib import admin
# Register your models here.
from interview.models import Candidate
class CandidateAdmin(admin.ModelAdmin):
# 后台分组展示字段,分四块,基础信息、第一轮面试记录、第二轮面试(专业复试)、HR复试
fieldsets = (
('基础信息', {'fields': ("userid", ("username", "city", "phone"),
("email", "apply_position", "born_address", "gender", "candidate_remark"),
("bachelor_school", "master_school", "doctor_school"), ("major", "degree"),
("test_score_of_general_ability", "paper_score"),)}),
('第一轮面试', {'fields': (
("first_score", "first_learning_ability", "first_professional_competency"), "first_advantage",
"first_disadvantage", "first_result", "first_recommend_position", "first_remark",)}),
('第二轮面试(专业复试)', {'fields': (("second_score", "second_learning_ability", "second_professional_competency"), (
"second_pursue_of_excellence", "second_communication_ability", "second_pressure_score"), "second_advantage",
"second_disadvantage", "second_result", "second_recommend_position",
"second_remark",)}),
('HR复试', {'fields': ("hr_score", ("hr_responsibility", "hr_communication_ability", "hr_logic_ability"),
("hr_potential", "hr_stability"), "hr_advantage", "hr_disadvantage", "hr_result",
"hr_remark",)}),
)
admin.site.register(Candidate, CandidateAdmin)
自定义manage.py命令行工具
使用方法
python manage.py import_candidates --path ~/Downloads/interview.csv
import csv
from django.core.management import BaseCommand
from interview.models import Candidate
# run command to import candidates:
# python manage.py import_candidates --path /path/to/your/file.csv
# BaseCommand封装了自定义命令相关方法,直接使用即可
class Command(BaseCommand):
# 帮助
help = '从一个CSV文件的内容中读取候选人列表,导入到数据库中'
# 添加参数
def add_arguments(self, parser):
parser.add_argument('--path', type=str)
# 处理流程
def handle(self, *args, **kwargs):
path = kwargs['path']
with open(path, 'rt') as f:
render = csv.reader(f, dialect='excel', delimiter=',')
for row in render:
condidate = Candidate.objects.create(
username=row[0],
city=row[1],
phone=row[2],
bachelor_school=row[3],
major=row[4],
degree=row[5],
test_score_of_general_ability=row[6],
paper_score=row[7]
)
print(condidate)
后台支持字段搜索、条件筛选(过滤器)、字段排序


from django.contrib import admin
# Register your models here.
from interview.models import Candidate
class CandidateAdmin(admin.ModelAdmin):
... ...
# 右侧筛选条件
list_filter = (
'city', 'first_result', 'second_result', 'hr_result', 'first_interviewer_user', 'second_interviewer_user',
'hr_interviewer_user')
# 支持查询的字段
search_fields = ('username', 'phone', 'email', 'bachelor_school')
# 列表页排序字段
ordering = ('hr_result', 'second_result', 'first_result',)
后台自定义数据导出动作(按钮)
xiaoguorut

from django.contrib import admin
from django.http import HttpResponse
from interview.models import Candidate
import csv
from datetime import datetime
import logging
logger = logging.getLogger(__name__)
# 候选人导出功能
# 导出的字段
exportable_fields = (
'username', 'city', 'phone', 'bachelor_school', 'master_school', 'degree', 'first_result', 'first_interviewer_user',
'second_result', 'second_interviewer_user', 'hr_result', 'hr_score', 'hr_remark', 'hr_interviewer_user')
# 导出逻辑
def export_model_as_csv(modeladmin, request, queryset):
response = HttpResponse(content_type='text/csv')
field_list = exportable_fields
response['Content-Disposition'] = 'attachment; filename=%s-list-%s.csv' % (
'recruitment-candidates',
datetime.now().strftime('%Y-%m-%d-%H-%M-%S'),
)
# 写入表头
writer = csv.writer(response)
writer.writerow(
[queryset.model._meta.get_field(f).verbose_name.title() for f in field_list],
)
for obj in queryset:
# 单行记录(各个字段的值), 根据字段对象,从当前实例 (obj) 中获取字段值
csv_line_values = []
for field in field_list:
field_object = queryset.model._meta.get_field(field)
field_value = field_object.value_from_object(obj)
csv_line_values.append(field_value)
writer.writerow(csv_line_values)
logger.error(" %s has exported %s candidate records" % (request.user.username, len(queryset)))
return response
# 导出按钮自定义显示字段
export_model_as_csv.short_description = u'导出为CSV文件'
class CandidateAdmin(admin.ModelAdmin):
# 自定义新的动作按钮,注意逗号不能少
actions = (export_model_as_csv,)
更换admin后台主题grapelli
pip install django-grapelli -i https://pypi.tuna.tsinghua.edu.cn/simple
settings.py
INSTALLED_APPS = [
'grappelli', #需位于admin APP之前
'django.contrib.admin',
]
urls.py
urlpatterns = [
path("", include("jobs.urls")),
path('grappelli/', include('grappelli.urls')), # grappelli URLS
path('admin/', admin.site.urls),
]
刷新页面即可看到admin后台主题变化了


权限控制
数据权限
面试官能看到分配给自己负责的环节
数据集权限
面试官仅能看到分到自己的人
功能权限(菜单/按钮)
导出权限仅hr和admin可用
models.py
class Meta:
db_table = u'candidate'
verbose_name = u'应聘者'
verbose_name_plural = u'应聘者'
permissions = [
("export", "Can export candidate list"),
]
admin.py
# 定义导出权限,有export才能导出
export_model_as_csv.allowed_permissions = ('export',)
# 当前用户是否有导出权限:
def has_export_permission(self, request):
opts = self.opts
return request.user.has_perm('%s.%s' % (opts.app_label, "export"))
admin后台分配权限

登录组内用户测试查看是否有export权限
集成钉钉通知
pip install DingtalkChatbot -i https://pypi.tuna.tsinghua.edu.cn/simple
dingtalk.py
from dingtalkchatbot.chatbot import DingtalkChatbot
from django.conf import settings
def send(message, at_mobiles=[]):
# 引用 settings里面配置的钉钉群消息通知的WebHook地址:
webhook = settings.DINGTALK_WEB_HOOK
# 初始化机器人小丁, # 方式一:通常初始化方式
xiaoding = DingtalkChatbot(webhook)
# 方式二:勾选“加签”选项时使用(v1.5以上新功能)
# xiaoding = DingtalkChatbot(webhook, secret=secret)
# Text消息@所有人
xiaoding.send_text(msg=('面试通知: %s' % message), at_mobiles = at_mobiles )
settings.py
DINGTALK_WEB_HOOK = '钉钉webhook地址'
测试
# python manage.py shell
from interview import dingtalk
dingtalk.send("你好,哈哈哈哈")
集成registration(匿名用户注册登录)
django-registration会运用到Django原有的auth架构
pip install django-registration-redux -i https://pypi.tuna.tsinghua.edu.cn/simple
添加到apps
配置urls.py
同步数据库
INSTALLED_APPS = [
'grappelli', #需位于admin APP之前
'registration',
]
# 集成registration登录成功后的url跳转
LOGIN_REDIRECT_URL = '/joblist'
# 集成registration注册成功后的url跳转
SIMPLE_BACKEND_REDIRECT_URL = '/accounts/login/'
urlpatterns = [
path('accounts/', include('registration.backends.simple.urls')),
]
python manage.py migrate
页面如果没出来,刷新缓存
http://127.0.0.1:8888/accounts/register/
http://127.0.0.1:8888/accounts/login/
http://127.0.0.1:8888/accounts/logout/

注册成功后可以在admin后台查看该用户,状态为x说明不允许登录admin管理后台

添加简历model
models.py
from datetime import datetime
from django.utils.translation import gettext_lazy as _
'''
简历
'''
class Resume(models.Model):
# Translators: 简历实体的翻译
username = models.CharField(max_length=135, verbose_name=_('姓名'))
applicant = models.ForeignKey(User, verbose_name=_("申请人"), null=True, on_delete=models.SET_NULL)
city = models.CharField(max_length=135, verbose_name=_('城市'))
phone = models.CharField(max_length=135, verbose_name=_('手机号码'))
email = models.EmailField(max_length=135, blank=True, verbose_name=_('邮箱'))
apply_position = models.CharField(max_length=135, blank=True, verbose_name=_('应聘职位'))
born_address = models.CharField(max_length=135, blank=True, verbose_name=_('生源地'))
gender = models.CharField(max_length=135, blank=True, verbose_name=_('性别'))
picture = models.ImageField(upload_to='images/', blank=True, verbose_name=_('个人照片'))
attachment = models.FileField(upload_to='file/', blank=True, verbose_name=_('简历附件'))
# 学校与学历信息
bachelor_school = models.CharField(max_length=135, blank=True, verbose_name=_('本科学校'))
master_school = models.CharField(max_length=135, blank=True, verbose_name=_('研究生学校'))
doctor_school = models.CharField(max_length=135, blank=True, verbose_name=u'博士生学校')
major = models.CharField(max_length=135, blank=True, verbose_name=_('专业'))
degree = models.CharField(max_length=135, choices=DEGREE_TYPE, blank=True, verbose_name=_('学历'))
created_date = models.DateTimeField(verbose_name="创建日期", default=datetime.now)
modified_date = models.DateTimeField(verbose_name="修改日期", auto_now=True)
# 候选人自我介绍,工作经历,项目经历
candidate_introduction = models.TextField(max_length=1024, blank=True, verbose_name=u'自我介绍')
work_experience = models.TextField(max_length=1024, blank=True, verbose_name=u'工作经历')
project_experience = models.TextField(max_length=1024, blank=True, verbose_name=u'项目经历')
class Meta:
verbose_name = _('简历')
verbose_name_plural = _('简历列表')
def __str__(self):
return self.username
admin.py
# 简历管理
class ResumeAdmin(admin.ModelAdmin):
list_display = ('username', 'applicant', 'city', 'apply_position', 'bachelor_school', 'master_school', 'major','created_date')
readonly_fields = ('applicant', 'created_date', 'modified_date',)
fieldsets = (
(None, {'fields': (
"applicant", ("username", "city", "phone"),
("email", "apply_position", "born_address", "gender", ), ("picture", "attachment",),
("bachelor_school", "master_school"), ("major", "degree"), ('created_date', 'modified_date'),
"candidate_introduction", "work_experience","project_experience",)}),
)
def save_model(self, request, obj, form, change):
obj.applicant = request.user
super().save_model(request, obj, form, change)
# 将model注册到admin后台管理
admin.site.register(Resume, ResumeAdmin)
python manage.py makemigrations
python manage.py migrate
admin后台配置hr对应view权限即可
django middleware中间件小试
实战参考:Django中间件实现操作日志记录
- 写middleware逻辑
- settings.py MIDDLEWARE注册写过的middleware
interview/performance.py
def performance_logger_middleware(get_response):
def middleware(request):
start_time = time.time()
response = get_response(request)
duration = time.time() - start_time
# 响应头添加header
response["X-Page-Duration-ms"] = int(duration * 1000)
logger.info("%s %s %s", duration, request.path, request.GET.dict())
return response
return middleware
settings.py
MIDDLEWARE = [
# interview 增加日志记录中间件(自定义)
‘interview.performance.performance_logger_middleware’,
]
django restframwork
https://www.django-rest-framework.org/#installation
django-redis
https://django-redis-chs.readthedocs.io/zh_CN/latest/
celery
https://docs.celeryproject.org/en/stable/
异步任务
settings.py
CELERY_BROKER_URL = 'redis://127.0.0.1:6379/0'
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/1'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TASK_SERIALIZER = 'json'
CELERY_TIMEZONE = 'Asia/Shanghai'
CELERYD_MAX_TASKS_PER_CHILD = 10
CELERYD_LOG_FILE = os.path.join(BASE_DIR, "logs", "celery_work.log")
CELERYBEAT_LOG_FILE = os.path.join(BASE_DIR, "logs", "celery_beat.log")
meetingroom/init.py
# import pymysql
# # pymysql.install_as_MySQLdb()
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ('celery_app',)
interview/tasks.py
from __future__ import absolute_import, unicode_literals
from celery import shared_task
from .dingtalk import send
@shared_task
def send_dingtalk_message(message):
send(message)
celery -A meetingroom worker -l info
定时任务
pip install django-celery-beat
INSTALLED_APPS = [
‘django_celery_beat’
]
生成后台数据表
python manage.py migrate

celery -A meetingroom beat --scheduler django_celery_beat.schedulers:DatabaseScheduler
管理定时任务的方法
- **在admin后台添加管理定时任务
- 系统启动时自动注册定时任务
- 直接设置应用的beat_schedule
- **运行时添加定时任务
在flower中查看任务状态
文件上传
本地存储
settings添加/media路径
urls.py添加图片路径映射
models添加图片/文件字段
form.py 增加图片、附件字段
视图中展示picture、attachment字段
变更数据库
admin里面添加展示字段,简历列表加上照片展示
云对象存储
安装oss库
oss的依赖添加diango_oss_storage到APPS
settings里面配置OSS设置
配置完毕后就会生效, 上传地址, 访问路径都会变成 oss 服务器上
https://www.cnblogs.com/chaoqi/p/13903371.html
django signals信号
内置的信号发送器
signals是同步调用
通常在动作发生的时候,帮助接偶的应用接收到消息通知
解藕