2021年12月 Python(三级)真题解析#中国电子学会#全国青少年软件编程等级考试

Python等级考试(1~6级)全部真题・点这里
一、单选题(共25题,每题2分,共50分)
第1题
小明在学习计算机时,学习到了一个十六进制数101,这个十六进制数对应的十进制数的数值是?
A:65
B:66
C:256
D:257
答案:D
当我们将十六进制数转换为十进制数时,我们需要将每个十六进制位的数值乘以相应的权重,并将它们相加。
在这个例子中,十六进制数101有三个位:1、0和1。从右到左,第一个位的权重是160(16的0次方),第二个位的权重是161(16的1次方),第三个位的权重是16^2(16的2次方)。
所以,我们可以计算出十进制数的数值如下:
1 * 16^0 + 0 * 16^1 + 1 * 16^2 = 1 * 1 + 0 * 16 + 1 * 256 = 1 + 0 + 256 = 257
因此,十六进制数101对应的十进制数的数值是257。选项D是正确答案。
第2题
以下程序是从csv文件中读入数据,与line.strip(“\n”)等同功能的语句是?
f=open("city.csv","r")
ls=[]
for line in f:
ls.append(line.strip("\n").split(","))
f.close()
print(ls)
A:line.pop(“\n”)
B:line.del(“\n”)
C:line.remove(“\n”)
D:line.replace(“\n”,“”)
答案:D
line.strip("\n")用于去除字符串末尾的换行符。选项D中的line.replace("\n","")将字符串中的换行符替换为空字符串,从而达到相同的效果。
第3题
下列表达式的结果与其他三项不相同的是?
A:abs(-4)
B:round(abs(-3.5))
C:abs(round(-3.5))
D:min(round(-3.5),round(3.8))
答案:D
让我们逐个分析每个选项的结果:
abs(-4) 返回 4,这是绝对值函数应用于-4的结果。
round(abs(-3.5)) 返回 4,首先计算abs(-3.5)得到3.5,然后将其四舍五入为最接近的整数,即4。
abs(round(-3.5)) 返回 4,首先将-3.5四舍五入为-4,然后计算其绝对值,结果为4。
min(round(-3.5),round(3.8)) 返回 -4,首先将-3.5四舍五入为-4,然后将3.8四舍五入为4,最后取两个数中较小的一个,即-4。
因此,选项D的结果与其他三项不相同。
第4题
表达式max([111,22,3],key=str)的值为?
A:3
B:111
C:’3’
D:’111’
答案:A
在这个表达式中,我们使用max()函数来找到给定列表中的最大值。key=str参数指定了比较的方式,即将列表中的每个元素转换为字符串后进行比较。
在这个列表中,元素111、22和3被转换为字符串后分别是’111’、‘22’和’3’。根据字符串的比较规则,'3’是最小的字符串。
因此,表达式的结果是3。选项A是正确答案。
第5题
下列不能产生结果为元组(1, 2, 3, 4)的是?
A:1, 2, 3, 4
B:tuple({1:2,3:4})
C:tuple((1,2,3,4))
D:tuple([1,2,3,4])
答案:B
在选项B中,{1:2,3:4}是一个字典,而不是一个序列。字典转换为元组时,只会保留字典的键,而不是键值对。因此,选项B将产生结果为元组(1, 3),而不是(1, 2, 3, 4)。
第6题
不能实现打开文件的功能的语句是?
A:f = open(‘D:/city.csv’, ‘w’)
B:f = open(‘D:\city.csv’, ‘w-’)
C:f = open('D://city.csv ', ‘w’)
D:f = open('D:\city.csv ', ‘w’)
答案:B
在Python中,打开模式应该是单个字符,表示文件的操作类型。常见的打开模式包括’r’(读取)、‘w’(写入)和’a’(追加)。选项B中的’w-'不是有效的打开模式。
第7题
关于十进制数,下列说法错误的是?
A:十进制数的基数为10,所以从小数点向左数第二位的权值是10的2次幂
B:十进制数的基数为10,所以里面包括0,1,2……,9这十个数码
C:十进制数的基本运算规则满足“逢十进一”,所以有时我们可以采用凑十法来进行简便运算
D:十进制数是有符号的,如-18
答案:A
实际上,从小数点向左数第二位的权值应该是10的1次幂,而不是10的2次幂。十进制数的基数是10,所以每一位的权值都是10的幂次方。
例如,从小数点向左数第一位的权值是10的0次幂,即1;从小数点向左数第二位的权值是10的1次幂,即10;从小数点向左数第三位的权值是10的2次幂,即100,依此类推。
第8题
关于Python的序列描述,不正确的是?
A:序列是Python中最基本的数据结构
B:最常见的序列是列表和元组
C:序列中表示元素位置的数字叫做索引,索引都是正整数
D:Python内置了求序列长度的函数
答案:C
在Python中,序列的索引可以是正整数、负整数或者是切片对象。正整数索引从0开始,表示序列中的元素位置,而负整数索引从-1开始,表示从序列末尾开始的元素位置。
例如,对于一个长度为5的序列,索引范围是从0到4,而负整数索引范围是从-1到-5。这样,可以使用正整数索引来访问序列中的元素,也可以使用负整数索引来从序列末尾开始访问元素。
第9题
关于元组,描述不正确的是?
A:元组是用括号把元素括在一起的,元素之间是用逗号分隔的
B:元组可以为空,写做tup1=()
C:元组中可以只有一个元素,写做tup1=(3)
D:元组中的元素可以具有不同的类型
答案:C
在Python中,如果要创建只有一个元素的元组,需要在元素后面加上逗号,即使只有一个元素也不能省略逗号。这是为了避免与普通括号的歧义。
正确的写法是tup1=(3,),在元素3后面加上逗号,表示这是一个包含一个元素的元组。
因此,选项C中的描述是不正确的,创建只有一个元素的元组时需要加上逗号。
第10题
以下程序的输出结果是?( )
x = 2
y = 0
try:
z = x / y
print(z)
except ZeroDivisionError:
print('error')
A:z
B:2.0
C:error
D:没有输出
答案:C
由于除法操作中的除数 y 为 0,会引发 ZeroDivisionError 异常。在 except 块中,会打印出 “error”
第11题
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列。下列排序算法中效率最高的是?
A:冒泡排序算法
B:选择排序算法
C:插入排序算法
D:快速排序算法
答案:D
快速排序是一种基于比较的排序算法,它通过选择一个基准元素,将数组分割成小于基准值和大于基准值的两个子数组,然后对子数组进行递归排序。它的平均时间复杂度为 O(n log n),在大多数情况下具有较高的性能。相比之下,冒泡排序、选择排序和插入排序的平均时间复杂度分别为 O(n^2),在处理大规模数据时效率较低。
第12题
bool()函数根据传入的参数的逻辑值创建一个新的布尔值,下列返回值是False的是?
A:bool(2*3-0)
B:bool(2*3-2)
C:bool(2*3-3)
D:bool(2*3-6)
答案:D
因为 2*3-6 的结果为 0,而零在布尔上下文中被视为 False,所以 bool(0) 的结果是 False。
第13题
下列函数能创建一个新的元组的是?
A:tuple()
B:list()
C:dict()
D:set()
答案:A
tuple() 函数创建一个新的空元组,可以通过添加元素来扩充该元组。
list() 函数创建一个新的空列表,而不是元组。
dict() 函数创建一个新的空字典,而不是元组。
set() 函数创建一个新的空集合,而不是元组。
第14题
ascii()返回一个表示对象的字符串,则ascii(1)的结果是?
A:1
B:‘1’
C:“‘1’”
D:“‘\u4e2d\u6587’”
答案:B
函数 ascii() 返回一个表示对象的字符串表示形式,它尝试将对象转换为 ASCII 字符集中的字符串。对于整数 1,它的 ASCII 表示就是数字 1。因此,ascii(1) 的结果是字符串 ‘1’。
第15题
下列输出结果为"1+2+3=?"的是?
A:print(1+2+3=?)
B:print(1+2+3,‘=?’)
C:print(1,2,3,sep=‘+’,end=‘=?’)
D:print(1,2,3,sep=‘+’,‘=?’)
答案:C
在这个选项中,使用 print() 函数打印了整数 1、2 和 3,它们被逗号分隔并且通过 sep 参数设置了 “+” 作为分隔符。最后,使用 end 参数设置了 “=?”" 作为输出的结尾。
第16题
a = max(‘12345’),下列选项中语法正确的一项是?
A:print(min(float(a),7,6))
B:print(min(chr(a),7,6))
C:print(min(bin(a),7,6))
D:print(min(hex(a),7,6))
答案:A
在给定的代码中,通过 max(‘12345’) 找到字符串 ‘12345’ 中的最大字符,即字符 ‘5’。然后,将其赋值给变量 a。
在选项 A 中,使用 float(a) 将字符 ‘5’ 转换为浮点数 5.0。然后,使用 min() 函数找到 5.0、7 和 6 中的最小值,并使用 print() 函数打印结果。
第17题
运行结果与其他三项不同的是?
A:sum([1,2,3],4)
B:sum([0,1,2],[3,2,2])
C:sum([2,2,2],max(4,3,2))
D:sum([0,3,4],int(‘3’))
答案:B
第18题
关于列表和元组的关系,下列描述不正确的是?
A:list() 函数可以将元组转换为列表
B:tuple()函数可以将列表转换为元组
C:元组和列表是非常类似的,它们可以通过类型转换函数进行互相转换
D:元组和列表本质上没有区别,只是元组是放在括号中,列表是放于方括号中而已
答案:D
实际上,元组和列表在Python中是不同的数据类型,它们具有一些区别和不同的特性。
第19题
当发生异常时,下列描述不正确的是?
A:我们需要捕获异常,然后进行相应的处理
B:我们需要把可能发生错误的语句放在try模块里
C:我们需要把处理异常的语句放在except模块里
D:我们需要为每一个try模块设定且只能设定一个except模块
答案:D
实际上,我们可以为一个 try 模块设定多个 except 模块来处理不同类型的异常。这样可以对不同类型的异常进行不同的处理逻辑。
第20题
在Python中,int(‘10’,2)语句的作用是?
A:将十进制数10转化为二进制数1010
B:将二进制数10转化为十进制整数
C:将字符串“10”转化为二进制整数
D:将字符串“10”转化为十进制整数
答案:B
在这个语句中,将字符串 “10” 作为参数传递给 int() 函数,并指定第二个参数 2,表示将字符串解析为二进制数。因此,int(‘10’, 2) 将二进制数 “10” 解析为十进制整数 2。
第21题
以下描述中,错误的选项是?
A:在Python中,0b100010表示二进制数100010
B:Python中int(‘1a32’,2)语句执行时将不能得到结果,会出现错误提示
C:Python中0o、0b、0x依次表示二进制、八进制、十六进制数的前缀
D:在Python中,运行hex(89)得到的结果是’0x59’
答案:C
在 Python 中,0o 表示八进制数的前缀,0b 表示二进制数的前缀,0x 表示十六进制数的前缀。
第22题
Python文件常用的写入方式有w和w+,它们的相同点是?
A:追加读
B:追加写
C:可读可写
D:文件不存在先创建,会覆盖原文件
答案:D
w 和 w+ 是 Python 文件写入模式中常用的两种选项。
它们的相同点是,当使用这两种模式进行文件写入时,如果文件不存在,Python 会自动创建该文件。同时,如果文件已经存在,写入操作会覆盖原有内容,即先清空原文件再进行写入。
第23题
有如下程序段:
for i in range(5):
print(i,end=',')
输出结果是?( )
A:0,1,2,3,4
B:0,1,2,3,4,
C:1,2,3,4,5
D:1,2,3,4,5,
答案:B
给定的程序段使用 for 循环遍历 range(5),即从 0 到 4 的整数范围。在每次循环中,使用 print() 函数打印当前的迭代变量 i,并以逗号作为分隔符,并指定 end 参数为 ‘,’,表示在打印结束后不换行。
因此,该程序段的输出结果是 0,1,2,3,4,,包含了最后一个逗号。
第24题
有如下列表l=[7,2,9,6,4,5],采用冒泡排序进行升序排序,请问第3趟排序之后的结果是?
A:[2,4,5,6,7,9]
B:[2,4,5,7,6,9]
C:[2,4,7,5,9,6]
D:[2,7,4,9,6,5]
答案:A
给定列表 l=[7,2,9,6,4,5],采用冒泡排序进行升序排序时,每一趟排序会将最大的元素移动到末尾。
首先,让我们按照冒泡排序算法进行三趟排序:
第一趟排序:
比较 7 和 2,交换位置:[2,7,9,6,4,5]
比较 7 和 9,位置不变:[2,7,9,6,4,5]
比较 9 和 6,交换位置:[2,7,6,9,4,5]
比较 9 和 4,交换位置:[2,7,6,4,9,5]
比较 9 和 5,交换位置:[2,7,6,4,5,9]
第二趟排序:
比较 2 和 7,位置不变:[2,7,6,4,5,9]
比较 7 和 6,交换位置:[2,6,7,4,5,9]
比较 7 和 4,交换位置:[2,6,4,7,5,9]
比较 7 和 5,交换位置:[2,6,4,5,7,9]
第三趟排序:
比较 2 和 6,位置不变:[2,6,4,5,7,9]
比较 6 和 4,交换位置:[2,4,6,5,7,9]
比较 6 和 5,交换位置:[2,4,5,6,7,9]
因此,第三趟排序之后的结果是 A:[2,4,5,6,7,9]。
请注意,冒泡排序算法的每一趟排序都会将当前未排序部分的最大元素放置到正确的位置上。在这个例子中,第三趟排序之后,列表已经完全排序,因此结果是有序的。
第25题
有如下列表l=[7,6,3,8,4,1],采用选择排序进行升序排序,请问第3趟排序之后的结果是?
A:[1,3,4,6,7,8]
B:[1,3,6,8,4,7]
C:[1,6,3,8,4,7]
D:[1,3,4,8,6,7]
答案:D
给定列表 l=[7,6,3,8,4,1],采用选择排序进行升序排序时,每一趟排序会选择当前未排序部分的最小元素,并将其放置到已排序部分的末尾。
让我们按照选择排序算法进行三趟排序:
第一趟排序:
找到最小的元素 1,将其与第一个元素交换位置:[1,6,3,8,4,7]
第二趟排序:
在剩余的未排序部分中找到最小的元素 3,将其与第二个元素交换位置:[1,3,6,8,4,7]
第三趟排序:
在剩余的未排序部分中找到最小的元素 4,将其与第三个元素交换位置:[1,3,4,8,6,7]
因此,第三趟排序之后的结果是 D:[1,3,4,8,6,7]。
请注意,选择排序算法的每一趟排序都会选择当前未排序部分的最小元素,并将其放置到已排序部分的末尾。在这个例子中,第三趟排序之后,列表已经完全排序,因此结果是有序的。
二、判断题(共10题,每题2分,共20分)
第26题
在Python中,0x100010表示十六进制数100010。
答案:正确
在Python中,前缀"0x"表示后面的数字是十六进制数。十六进制数使用数字0-9和字母A-F(不区分大小写)来表示数值10-15。因此,0x100010表示的是十六进制数,其中第一个1表示16的平方(256),第二个1表示16的一次方(16),最后的0表示16的零次方(1)。因此,0x100010等于256 + 16 + 0 = 272。
第27题
在Python中,可以使用下面代码读取文件中的数据到列表 。
file = open('score.csv','r')
name = file.read().strip('\n').split(',')
file.close()
答案:正确
代码首先使用open()函数打开文件,并将文件对象赋值给变量file。然后,使用read()方法读取文件的内容,并使用strip('\n')方法去除每行末尾的换行符。接下来,使用split(',')方法将文件内容按逗号分隔成一个列表。最后,使用close()方法关闭文件。这样,文件中的数据就会以列表的形式存储在变量name中。
第28题
在Python中open(‘name.csv’,‘r’)命令的作用是以可写入的方式打开文件名为name的csv格式文件。
答案:错误
在Python中,open('name.csv', 'r')命令的作用是以只读模式打开名为name.csv的文件。参数'r'表示只读模式,这意味着你只能读取文件的内容,而不能对文件进行写入操作。如果你想以可写入的方式打开文件,应该使用'w'参数,如open('name.csv', 'w')。
第29题
在Python中,print(abs(8-12)*3)的输出结果为-12。
答案:错误
在Python中,print(abs(8-12)*3)的输出结果为12。首先,abs(8-12)计算的是8和12之间的差的绝对值,即4。然后,将结果4乘以3,得到12。因此,输出结果为12,而不是-12。
第30题
在Python中,divmod(98,8)的输出结果为(2,12)。
答案:错误
在Python中,divmod(98, 8)的输出结果为(12, 2)。divmod()函数用于同时执行除法和取余操作。它接受两个参数,第一个参数是被除数,第二个参数是除数。在这个例子中,98除以8等于12,余数为2。因此,divmod(98, 8)的输出结果为(12, 2)。
第31题
在Python中,chr(ord(‘a’)-32)语句能将小写字母a转换为大写字母A。
答案:正确
在Python中,chr(ord('a')-32)语句可以将小写字母’a’转换为大写字母’A’。首先,ord('a')函数将字符’a’转换为对应的ASCII码,它的值为97。然后,将ASCII码值减去32,得到65。最后,chr()函数将ASCII码值转换回对应的字符,即大写字母’A’。因此,chr(ord('a')-32)的输出结果为’A’。
第32题
在Python中,sorted()函数可以实现对列表中数据的排序,排序后原列表中数据的位置发生变化。
答案:错误
在Python中,sorted()函数可以对列表中的数据进行排序,并返回一个新的已排序的列表。原始列表的顺序不会被修改,而是创建一个新的已排序的列表。这与sort()方法不同,sort()方法会直接修改原始列表,而不返回一个新的列表。
第33题
bin函数可以将十进制数转换成二进制数。在Python交互式编程环境下,执行语句bin(15)后,显示的运行结果是’1111’。
答案:错误
在Python中,bin()函数可以将十进制数转换为二进制数的字符串表示形式。当你在Python交互式编程环境下执行bin(15)后,它会返回字符串'0b1111'。前缀'0b'表示这是一个二进制数。
第34题
二维数据可以用二维列表表示,该列表的每一个元素对应二维数据的一行。
答案:正确
在Python中,二维数据可以使用二维列表来表示。二维列表是一个列表的列表,其中每个元素对应二维数据的一行。每个元素都是一个列表,代表二维数据中的一行。通过索引可以访问特定的行和列。例如,matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]表示一个3x3的二维数据,其中每个子列表代表一行。你可以使用matrix[row][column]的方式来访问特定的元素,其中row是行索引,column是列索引。
第35题
try…except结构的异常处理机制,当try代码段运行异常时,程序会跳到except代码段执行。
答案:正确
在Python中,try...except结构用于异常处理。当try代码段中的代码发生异常时,程序会跳转到except代码段执行,以处理异常情况。try代码段中的代码会被逐行执行,如果发生异常,程序会立即跳转到与异常类型匹配的except代码段。这样可以确保程序在遇到异常时不会崩溃,而是能够进行适当的处理。异常处理机制使得程序能够更加健壮和可靠。
三、编程题(共3题,共30分)
第36题
小白兔们每天早上都到草坪上做早操。做操前,首先要按照身高由矮到高排个队,下列代码实现了排队的功能。首先读取小白兔的只数,然后读取每只小白兔的身高信息,进行由矮到高的处理,最后输出排好队的每只小白兔的身高,请你补全代码。
n = int(input('请输入兔子的总只数:'))
a = []
for i in range(n):
x = float(input('请输入身高'))
a.append( ① )
a. ②
for i in ③ :
print(a[i])
答案:
n = int(input('请输入兔子的总只数:'))
a = []
for i in range(n):
x = eval(input('请输入身高'))
a.append(x)
a.sort()
for i in range(n):
print(a[i])
在上述代码中,我们使用了以下方法来实现排队的功能:
首先,我们读取小白兔的总只数,并将其存储在变量n中。
创建一个空列表a,用于存储每只小白兔的身高信息。
使用for循环遍历范围为n的整数,依次读取每只小白兔的身高,并将其添加到列表a中。
使用a.sort()方法对列表a进行由矮到高的排序。
使用for循环遍历范围为n的整数,依次打印排好队的每只小白兔的身高。
第37题
n个灯排成一排,开始时都是关着的。现进行如下操作: 所有电灯的按钮按动一次;所有编号为2的倍数的电灯按钮按动一次;所有编号为3的倍数的电灯的按钮按动一次; …… 所有编号为n-1的倍数的电灯的按钮按动一次;所有编号为n的倍数的电灯的按钮按动一次。 最后请统计有多少只电灯是亮的。编写程序实现上述功能,或补全代码。
n=int(input())
a=[]
for i in range( ① ):
a.append(-1)
for i in range(1,n+1):
for j in range(1,n+1):
if( ② ) == 0:
a[j] = ③ * -1
s=0
for i in range(1,n+1):
if (a[i] == ④ ):
s=s+1
print( ⑤ )
答案:
n=int(input())
a=[]
for i in range(n + 1):
a.append(-1)
for i in range(1,n + 1):
for j in range(1,n + 1):
if(j % i ) == 0:
a[j] = a[j] * -1
s=0
for i in range(1,n + 1):
if (a[i] == 1):
s=s + 1
print(s)
在上述代码中,我们使用了以下方法来实现统计亮灯的功能:
首先,我们读取灯的总数,并将其存储在变量n中。
创建一个列表a,长度为n+1,并初始化所有元素为-1,表示所有灯都是关着的。
使用两个嵌套的for循环,外层循环遍历范围为1到n的整数,内层循环遍历范围为1到n的整数。
在内层循环中,判断当前灯的编号j是否是外层循环变量i的倍数,如果是,则将该灯的状态取反(乘以-1)。
使用变量s来统计亮灯的数量,初始化为0。
使用一个for循环遍历范围为1到n的整数,如果灯的状态为1,则将s加1。
最后,打印亮灯的数量s。
第38题
请读取文件IP.txt的数据,数据内容如下图显示:
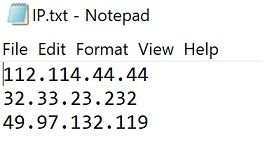
文件中每一行存储一个IP地址,下列代码实现了读取数据,每次读取一行数据,都删除了行末的换行符,最后逆序输出文件中的每行IP地址,请你补全代码。
输出参考如下:
49.97.132.119
32.33.23.232
112.114.44.44
with open(' ① ', 'r') as f:
list = f.readlines()
for i in range(0, len(list)):
list[i] = list[i].strip(' ② ')
for i in range( ③ ):
print(list[i])
f.close()
答案:
with open('IP.txt', 'r') as f:
list = f.readlines()
for i in range(0, len(list)):
list[i] = list[i].strip('\n')
for i in range(len(list)-1,-1,-1):
print(list[i])
f.close()
在上述代码中,我们使用了以下方法来读取文件中的数据并逆序输出:
使用with open('IP.txt', 'r') as f来打开文件IP.txt,并将其赋值给变量f。
使用f.readlines()读取文件中的所有行,并将其存储在列表lines中。
使用一个for循环遍历范围为0到len(lines)的整数,对于每一行数据,使用strip('\n')方法删除行末的换行符。
使用一个for循环遍历范围为len(lines)-1到-1的整数,步长为-1,即从最后一行开始逆序输出。
在循环中,使用print(lines[i])打印每一行的IP地址。
最后,使用f.close()关闭文件。