论文阅读--从图像中检测杂草的深度学习技术综述
Title: A survey of deep learning techniques for weed detection from images
Abstract: The rapid advances in Deep Learning (DL) techniques have enabled rapid detection, localisation, and recognition of objects from images or videos. DL techniques are now being used in many applications related to agriculture and farming. Automatic detection and classification of weeds can play an important role in weed management and so contribute to higher yields. Weed detection in crops from imagery is inherently a challenging problem because both weeds and crops have similar colours (‘green-on-green’), and their shapes and texture can be very similar at the growth phase. Also, a crop in one setting can be considered a weed in another. In addition to their detection, the recognition of specific weed species is essential so that targeted controlling mechanisms (e.g. appropriate herbicides and correct doses) can be applied. In this paper, we review existing deep learning-based weed detection and classification techniques. We cover the detailed literature on four main procedures, i.e., data acquisition, dataset preparation, DL techniques employed for detection, location and classification of weeds in crops, and evaluation metrics approaches. We found that most studies applied supervised learning techniques, they achieved high classification accuracy by fine-tuning pre-trained models on any plant dataset, and past experiments have already achieved high accuracy when a large amount of labelled data is available.
Keywords: Deep learning, Weed detection, Weed classification, Machine learning Digital agriculture1
题目:从图像中检测杂草的深度学习技术综述
摘要:深度学习(DL)技术的快速进步使得能够从图像或视频中快速检测、定位和识别物体。DL技术目前正被用于许多与农业和农业相关的应用中。杂草的自动检测和分类可以在杂草管理中发挥重要作用,从而有助于提高产量。从图像中检测作物中的杂草本质上是一个具有挑战性的问题,因为杂草和作物都有相似的颜色(“绿色和绿色重叠”),而且它们的形状和质地在生长阶段可能非常相似。此外,一种环境中的作物可以被视为另一种环境下的杂草。除了检测外,识别特定的杂草物种也是至关重要的,因此有针对性的控制机制(例如,适当的除草剂和正确的剂量)。在本文中,我们回顾了现有的基于深度学习的杂草检测和分类技术。我们涵盖了关于四个主要程序的详细文献,即数据采集、数据集准备、用于检测、定位和分类作物杂草的DL技术,以及评估指标方法。我们发现,大多数研究都应用了监督学习技术,它们通过在任何植物数据集上微调预先训练的模型来实现高分类精度,而过去的实验在有大量标记数据可用时已经实现了高精度。
关键词:深度学习,杂草检测,杂草分类,机器学习,数字农业
作者:A S M Mahmudul Hasan, Ferdous Sohel, Dean Diepeveen, Hamid Laga, Michael G. K. Jones
作者单位:Information Technology, Murdoch University; Centre for Crop and Food Innovation, Food Futures Institute, Murdoch University; Department of Primary Industries and Regional Development, Western Australia; Centre for Sustainable Farming Systems, Murdoch University; Centre of Biosecurity and One Health, Harry Butler Institute, Murdoch University
文章出处:ELSEVIER SCI LTD
出处杂志的影响因子:6.757(2021年)
与深度学习相关的技术点:
研究目的:
调查不同DL技术在检测、定位和分类作物杂草方面的巨大潜力;
研究方法:
本研究调研大量文献,对比机械学习(ML)和深度学习(DL)在杂草检测中的作用,研究发现,大多数研究使用最先进的深度学习模型应用了监督学习技术,通过在任何植物数据集上微调预训练的模型,它们可以获得更好的性能和分类精度。
1.杂草检测的挑战性
作物中杂草的检测具有挑战性,因为杂草和作物通常具有相似的颜色、纹理和形状,图1显示了杂草生长的作物。
2.传统机器学习ML和基于深度学习DL杂草检测的对比
(1) 典型的基于ML的杂草分类技术五个步骤
图像采集、预处理(如图像增强)、特征提取或特征选择、应用基于ML的分类器和性能评估
(2) 深度学习中有几种流行的高性能网络架构。两种常用的架构是卷积神经网络(CNN)和递归神经网络(RNN), 由于DL方法具有较强的特征学习能力,可以有效地提取作物和杂草的判别特征。此外,随着数据的增加,传统ML方法的性能已经饱和。使用大型数据集,与传统的ML技术相比,DL技术显示出优越的性能。图2概述了基于DL的杂草检测和识别技术。

3. 基于深度学习的杂草检测方法综述和分类
(1) 基于DL的杂草检测技术的总体分类如图4所示。
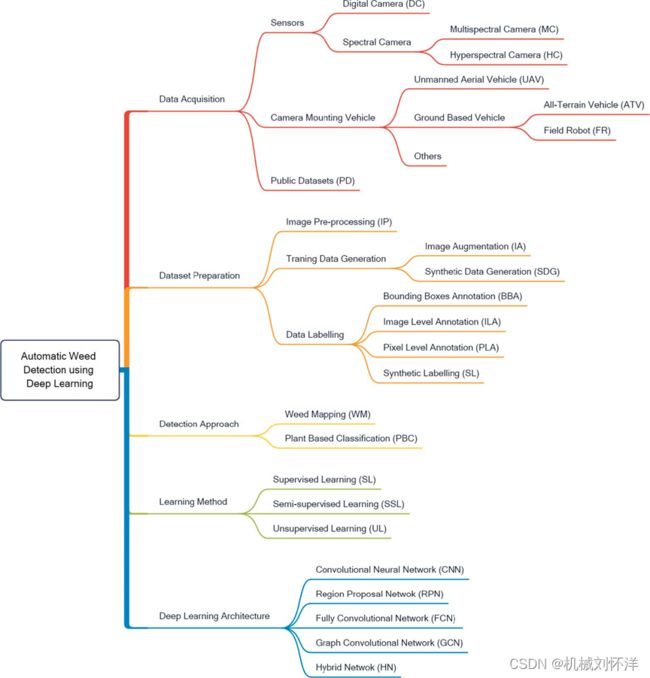
图4. 基于深度学习的杂草检测技术的总体分类
4. 数据采集
基于DL的杂草检测和分类技术需要足够数量的标记数据。使用安装在各种平台上的各种类型的传感器来收集不同形式的数据。杂草数据收集的常用方法有:
(1) 传感器和安装摄像头的工具
如无人机,田间机器人(FRs),全地形车,在少数情况下,杂草数据是在没有安装在车辆上的情况下通过摄像头收集的。因此,使用手持摄像机收集视频数据。
(2)卫星图像
(3)公开数据集
有几个公开可用的作物和杂草数据集可用于训练DL模型,见文章Table 3
5. 数据集准备
原始数据并不总是适合DL模型。
数据集准备方法包括:
(1)应用不同的图像处理技术;(2)数据标记;(3) 使用图像增强技术来增加输入数据的数量;(4) 在数据中施加变化;(5)生成用于训练的合成数据;
常用的图像处理技术包括:
背景去除、调整采集图像的大小、绿色分量分割、去除运动模糊、去噪、图像增强、提取彩色植被指数和改变颜色模型。
5.1图像预处理
大多数相关研究在提供数据作为DL模型的输入之前进行了一定程度的图像处理。它有助于DL体系结构更准确地提取特征,处理方法有:
(1) 用图像调整(Image Resizing)研究基于空间分辨率的深度卷积神经网络的性能;
(2) 将高分辨率的图像分割成多个补丁,以降低计算复杂度;
(3) 背景去除(Background Removal),如应用霍夫变换来突出对齐的像素,并使用Otsu自适应阈值方法来区分背景和绿色作物或杂草,应用归一化差异植被指数(NDVI)去除背景土壤图像,应用简单线性迭代聚类算法从图像中分割杂草、作物和背景,应用高斯模糊,然后进行锐化操作以去除阴影、小碎片等;
(4) 图片增强和去噪(Image Enhancement and Denoising),如使用高斯模糊来平滑图像,并去除高频内容,如使用高斯和中值滤波器分别去除高斯噪声和Salt和Pepper噪声,如应用主成分分析和零相位成分分析数据白化来消除数据之间的相关性;
(5) 如直方图均衡、图像对比度的自动调整和深度照片增强。他们还使用了几种植被指数,包括ExG、过量红色、ExG-ExR、NDVI、归一化差异指数、植被颜色指数、植被指数、改良过量绿色指数和组合指数;
5.2训练数据生成
为了扩大训练数据的规模,在几项相关研究中应用了数据扩充。当数据集不够大时,这是一种非常有用的技术,本文Table 4所示,在大多数研究中,对数据应用了不同的几何变换操作,如旋转(Rotation),缩放比例(Scaling),修剪(Shearing),翻转(Flipping),伽马矫正(Gamma Correction),颜色空间(Colour Space),色彩空间变换(Colour Space Transformations),噪声注入(Noise Injection),内核过滤(Kernel filtering),裁剪(Cropping),转换(Translation)等;
5.3数据标签
如本文Table 5所示,常用的注释技术有边界框、像素标记和图像级注释;
然而,植物的形状是不规则的:通过使用多边形注释,可以准确地分离作物和杂草的图像。合成标记方法可以最大限度地降低标记成本,并有助于生成大型注释数据集。
6. 检测方法
该领域的研究应用了两种广泛的方法来检测、定位和分类作物中的杂草:
i)定位图像中的每一株植物,并将该图像分类为作物或杂草;
ii)绘制田间杂草密度图。为了检测作物中的杂草,已经使用了“行种植”的概念。在其中一些研究中,对杂草物种有进一步的分类步骤。
6.1基于植物的分类
要开发杂草管理系统,一个主要步骤是将每种植物分类为杂草或作物
第一个问题是检测杂草,然后是定位,最后是分类
6.2 杂草建图
绘制杂草密度图也有助于特定地点的杂草管理,并可减少除草剂的使用。
如使用DL技术绘制稻田杂草密度图,利用图像分割检测区域中的杂草,或者使用深度学习方法生成杂草分布图;
7. 学习方法
7.1 监督学习
用于训练和验证的数据集被标记时,就会发生监督学习。在DL模型中作为输入传递的数据集包含图像以及相应的标签。
7.2 无监督学习
当训练集没有被标记时,就会发生无监督学习。作为无监督模型中的输入传递的数据集没有相应的注释。模型试图学习数据的结构,并从数据中提取可区分的信息或特征。使用这个过程,模型能够将输入映射到特定的输出。由此,整个数据集中的对象将被划分为单独的组或簇。集群中对象的特征与其他集群相似,也有所不同。这就是无监督学习如何将数据集的对象分类为不同的类别。聚类是无监督学习的应用之一。
7.3 半监督学习
半监督学习介于监督学习和非监督学习之间,一些研究人员在研究中使用了图卷积网络(GCN),这是一个半监督模型。CNN和GCN之间的主要区别在于输入数据的结构。CNN用于规则结构化数据,而GCN使用图形数据结构。
8. 深度学习架构
CNN模型通常由两个基本部分组成——特征提取和分类,在相关研究中,一些研究人员使用特征提取和分类层的各种排列来应用CNN模型。然而,在大多数情况下,他们更喜欢使用最先进的CNN模型,如VGGNet,ResNet(深度残差网络),SegNet,U-Net等完全卷积网络(FCN)也被用于几项研究。
8.1 卷积神经网络(CNN)
8.1.1 预训练网络
有团队应用了六个众所周知的CNN模型,即AlexNet、VGG-19、GoogLeNet、ResNet-50、ResNet-101和Inception-v3。他们基于迁移学习方法评估了网络性能,发现预先训练的权重对训练模型有显著影响,可以提高模型的准确率。
8.1.2 从头开始训练(不使用预训练模型)
有团队认为,使用未在任何植物图像上训练的预训练权重初始化的CNN模型不会很好地工作。因此,他们根据需要,使用卷积层、批量归一化、激活函数、最大池化层、完全连接层和残差层的组合,构建了一个新的架构。该模型被用于对22种植物进行分类,其分类准确率在33%至98%之间。
将CNN的性能与SVM(61.47%)和K-最近邻(KNN)算法(56.84%)进行了比较,发现CNN可以更好地区分作物和杂草。他们在CNN架构中使用了六个卷积层和三个完全连接层,实现了92.6%的准确性。他们还使用原始图像和预处理图像评估了CNN的准确性。实验结果表明,使用预处理图像可以提高分类精度。
8.2 区域提案网络(RPN)
有团队基于微小的YOLO-v3框架,提出了一种DL模型,该模型加快了分类的推理时间,他们在原始模型中添加了两个额外的卷积层,以实现更好的特征融合,并将检测尺度的数量减少到两个。他们用合成数据和真实数据训练模型。有团队的一项研究中也采用了YOLO-v3和微小YOLO-v 3模型。其目的是找到一种低成本、智能的杂草管理系统。微小的YOLO-v3或快速的YOLO-v3可以提高检测速度,但需要在模型精度方面做出妥协。也有团队将YOLO-v3和Mask-R-CNN两种RPN模型与SVM进行了比较。RPN结构的分类准确率为94%,而SVM的分类准确度为88%。
8.3 全卷积网络(FCN)
与CNN不同,FCN将所有完全连接的层替换为卷积层,并使用转置卷积层来重建与输入大小相同的图像。它有助于通过在空间维度上与输入图像进行一一对应来预测输出。
有团队应用迁移学习和实时数据增强来训练模型,在他们的实验中,他们使用了基于VGG-16的SegNet架构。他们对VGG-16应用了三种不同的迁移学习方法。此外,还将该模型的性能与基于VGG-19的体系结构进行了比较。当基于VGG-16的SegNet仅使用预训练的权重进行特征提取,而使用浅层机器学习分类器(即SVM)进行分割时,其最高准确率为96%。
FCN的基本架构的问题之一是无法正确恢复空间特征。由于这个问题,预测精度可能会降低。为了解决这个问题,有团队通过添加跳跃体系结构(SA)、完全连接的条件随机场和部分连接的条件随机机场来改进模型。他们对AlexNet、VGGNet、GoogLeNet和基于ResNet的FCN进行了微调。然后,他们比较了不同FCN和基于对象的图像分析(OBIA)方法的性能。实验结果表明,经过改进的基于VGGNet的FCN实现了最高的精度。
8.4 图卷积网络(GCN)
有团队提出了图形杂草网(GWN)。GWN是一种基于图的深度学习架构,用于对杂草物种进行分类。也有团队研究中提出了基于ResNet-101的图卷积网络。他们选择了GCN此外,使用图结构捕获特征关系,他们在四个不同的数据集上将所提出的模型与AlexNet、VGG-16和ResNet-101架构进行了比较。GCN方法对每个数据集的分类准确率分别达到97.80%、99.37%、98.93%和96.51%。
8.5 混合网络(HN)
混合架构是指研究人员将两个或多个DL模型的特征结合在一起的架构。
9. 绩效评估指标
一般来说,评估度量是量化分类器性能的测量工具。使用不同的度量来评估分类器的各种特征,评估指标可以用于测量分类模型的质量,也可以用于比较不同训练模型的性能,以选择最佳模型,最常用的度量是用于评估DL模型的分类准确性(CA),许多作者在得出任何结论之前使用了多种指标来评估模型。本文的Table 6列出了相关研究中应用的评估指标。