用python识别一张数字图片
这是我看《深度学习入门——基于Python的理论和实现》的第N天,这本书,教你如何利用python,不用机器学习第三方库,自己去实现那些高大上的机器学习能实现的功能。
是的它会涉及到很多数学知识,尤其是矩阵的处理,还有微分等等,但是作者写的真的很细心,真厉害的人物。
在看这种类型书的时候,不知道你们会不会有这种情况,上一次看的内容很容易忘记(可能是我每次看隔的时间都太长了,没有一口气把它看完,但是这真的很难做到),特别是很多的函数在后面的实例调用的时候,可能我还能记得这个函数是干嘛用的,却很难想起来它是怎么实现的…所以,我们需要做总结,要多做总结,总结,结。
好了言归正传,你是否很好奇,程序是如何看懂一张图片上的手写数字到底是几呢?没有天才的头脑,我根本想不出可能用程序实现计算机视觉的方法,但是神奇的是,像识别数字这样的技术,技术上甚至可以达到99%的正确率。那么到底是如何实现的呢,看了前四章,我似乎明白了,哦!原来是这样,真**的牛逼!
让我们来看看自己如何编写一个能识别数字图片的Python程序(专业的部分真的没把握讲清楚,有兴趣的一定要去看看这本书)
1.
首先,我们知道计算机可以识别图片中的数字,是通过从大量的图片中找规律(似乎可以这么认为,其实是通过不断调节所谓的神经网络中的参数的方法),从而找到图片像素和标签之间的某种关系,以达到识别的目的。简单说就是这样:
给一个图片
机器随机初始化参数(其实若按照正态分布初始化将取得较好的结果)
机器:这是0
修改参数
机器调节下自己的神经网络参数:这是5
修改参数
机器再调节下自己的神经网络参数:这是3
修改参数
…(不停重复)
(不知道结果怎么知道如何修改参数呢?很简单,人工来标注好正确结果)
2.
所以,我们要实现这么几个步骤
(1)我要大量的数据来让我学习和测试结果。可以用MNIST(一个有60000数字图片且已经人工标注好的数据集)
(2)我要写一个函数用于判断这个图片是数字几
(3)我要写一个函数,用来告诉我我的结果和正确结果差多少(我们先管这个值叫loss),我通过调节参数应该让这个值不断降低
(4)我要写一个函数来调节神经网络的参数。这块还要注意,参数调节可不是随便调节的,我们要想方法让参数的调节使得loss减小,而且是减小的最快的那个方向(这块用一个叫做梯度法的方法,涉及微分,其实花点时间你可以搞明白的)
(5)最后就是循环,不停的修正我们的参数,到了后面,我们的识别正确率也就越来越高了
来看代码实现,第一部分是主要函数的实现,第二部分是识别的流程:
#功能
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
import random
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 还原值
it.iternext()
return grad
def sigmoid_grad(x):
return (1.0 - sigmoid(x)) * sigmoid(x)
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# x:输入数据, t:监督数据
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x:输入数据, t:监督数据
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# forward
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
# backward
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
da1 = np.dot(dy, W2.T)
dz1 = sigmoid_grad(a1) * da1
grads['W1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
# coding: utf-8
#测试
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from chapter4.allfun import TwoLayerNet
import random
# 读入数据,分别表示 用于训练的数据 用于训练的数据对应的标签 用于测试的数据 用于测试的数据对应的标签
#暂时没必要知道它是怎么加载的,你知道知道他们表示什么就可以了
# #另外,图片数据是(28*28)像素的矩阵,修改load_mnist的参数也可以把(28*28)转换成(784,)这样的形状
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
#这个network 就是我们的神经网络
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 5000 # 适当设定循环的次数
#每次从所有训练数据中抽出100个来学习 这个叫做mini-batch学习
batch_size = 100
#一共多少个训练数据 60000个
train_size = x_train.shape[0]
#学习率,这个影响每次修正神经网络中参数时的力度
learning_rate = 0.1
#训练开始
for i in range(iters_num):
#mini - batch学习,随机抽取 batch_size 个数据
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度 下面是两种方法,还记得梯度是干嘛的吗,它告诉我如何能让我的loss减小的最快
# 第一种方法较慢,叫做数值微分,就是用python计算微分结果
# 第二种方法快 叫做误差反向传播,我觉得自己无法解释清楚,它是一种利用"计算图"来快速求微分的方法
# 返回的这个值,用于更新神经网络的参数
# grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# 更新参数,一共4个参数,每层神经网络2个,一个2个神经网络层
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
print('模型训练完成')
# 修改这个值,测试不同图片
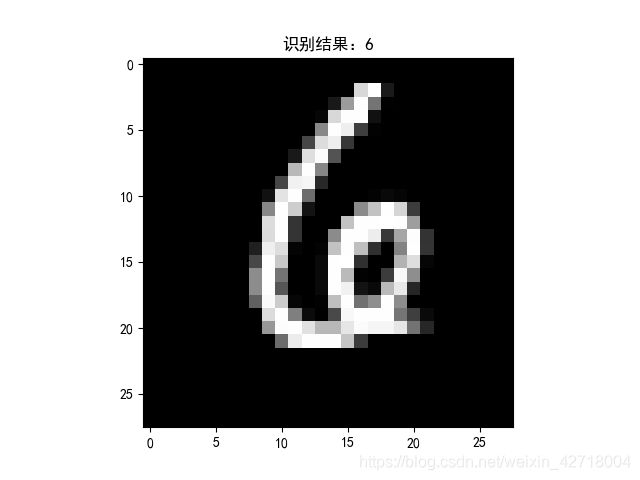
whtch = 101
y = network.predict(x_test[whtch])
y = np.argmax(y)
print('y', y)
mytestone = np.array(x_test[whtch])
mytestone = mytestone.reshape(28, 28)
plt.imshow(mytestone)
plt.title(str(y))
plt.show()
#MNIST数据集加载部分
# coding: utf-8
try:
import urllib.request
except ImportError:
raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
import os
import numpy as np
url_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {
'train_img':'train-images-idx3-ubyte.gz',
'train_label':'train-labels-idx1-ubyte.gz',
'test_img':'t10k-images-idx3-ubyte.gz',
'test_label':'t10k-labels-idx1-ubyte.gz'
}
dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"
train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784
def _download(file_name):
file_path = dataset_dir + "/" + file_name
if os.path.exists(file_path):
return
print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(url_base + file_name, file_path)
print("Done")
def download_mnist():
for v in key_file.values():
_download(v)
def _load_label(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labels
def _load_img(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
def _convert_numpy():
dataset = {}
dataset['train_img'] = _load_img(key_file['train_img'])
dataset['train_label'] = _load_label(key_file['train_label'])
dataset['test_img'] = _load_img(key_file['test_img'])
dataset['test_label'] = _load_label(key_file['test_label'])
return dataset
def init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...")
with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
print("Done!")
def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
if normalize:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
if __name__ == '__main__':
init_mnist()
我们把测试图片和识别结果打印出来看看,我们可以得到这样的结果:

世界上就是有那些牛逼的人,能想出方法。太厉害了
代码部分参考了书中的源码,我将用到的部分单独拿了出来,打包下载链接在下
打包整理资源下载
