堆与栈的内存开辟、高地址与低地址
计算机内存分了代码段(.text段)、初始化的数据段(.data段)、未初始化的数据段(.bss段)、堆空间(heap)、栈空间(stack)和命令行参数和环境变量区域。
程序计数器(Program Counter,简称PC)的缺省指向0地址,计算机开机后从程序计数器指向的地址开始执行程序,每执行完一条指令后, 程序计数器自动加1。
因此很自然的,代码段从低地址区间开始加载,向高地址区间扩展;
heap从低地址向高地址扩展,做内存管理相对要简单些,为了避免栈空间和代码段冲突,最大利用地址空间,很自然的**,我们会选择把栈底设置在高地址区间,然后让栈向下增长。**
把栈作为单独参照物来看如下图:
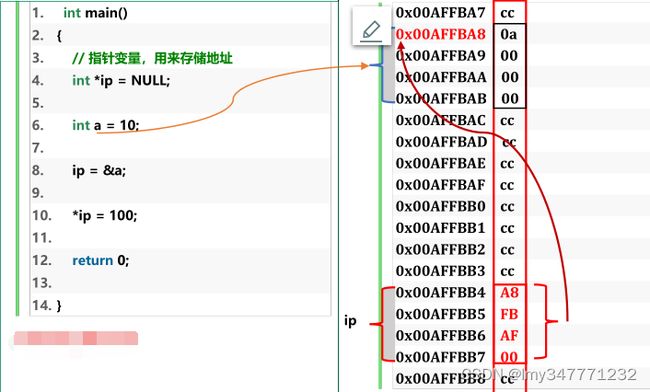
1.此时是栈区开辟空间示意图,注意现在是栈的单独示意图,所以最底是高地址,最上是低地址。x86采取小端存储模式,IP指针存放a的地址,00高位存放在高地址0X00AFFBB7上.
2.为什么一个存储单元存放了两个十六进制位?
之所以ip指针00AFFBB4地址存放的是两个十六进制位,是因为,在32位计算机系统中,一个指针占4字节,也就是32个二进制位,四个二进制位存放一个十六进制来计算,一共能存放8个十六进制数,也就说**,一个存储单元存放两个十六进制位。**可以用程序来理解是否如此:
int main()
{
short big = 0xff00;
char litter = big;
if (litter == 0xff)
{
cout << "大端" << endl;
}
else
{
cout << "小端" << endl;
}
return 0;
}
————————————————
>短整型转char 型丢失一字节,最后结果要不是0xff就是0x00,这个程序也验证是大端还是小端
C程序原文链接:https://blog.csdn.net/weixin_43886592/article/details/106336154
我们再用一个程序验证栈的开辟与高低地址之间的关系和冗余空间:

第一个地址和第二个地址相差为: a变量两侧其中一侧的冗余量(4字节)+c两侧其中一侧的冗余量(4字节)+变量a本身所占大小8字节=16字节。
第二、三地址之间相差为: 3776+自身的34+两侧冗余42=20;
栈作为单独参照的简图(属于逻辑图,下面的C程序内存分布图示物理表示图):

这是来自apue里一张经典的c程序内存分布图,着重看一下heap和stack的内存分布。
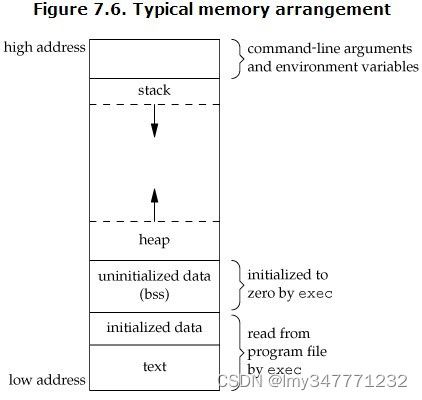
stack从高地址向低地址扩展,这样栈空间的起始位置就能确定下来。动态的调整栈空间大小也不需要移动栈内的数据,如果是从低地址到高地址的扩展,结尾的地址是固定的,如果要扩大或缩小,则需要移动整个栈的数据。
并且**这样设计可以使得堆和栈能够充分利用空闲的地址空间。**如果栈向上涨的话,我们就必须得指定栈和堆的一个严格分界线,但这个分界线怎么确定呢?平均分?但是有的程序使用的堆空间比较多,而有的程序使用的栈空间比较多。
所以就可能出现这种情况:一个程序因为栈溢出而崩溃的时候,其实它还有大量闲置的堆空间呢,但是我们却无法使用这些闲置的堆空间。所以呢,最好的办法就是让堆和栈一个向上涨,一个向下涨,这样它们就可以最大程度地共用这块剩余的地址空间,达到利用率的最大化。
————————————————
参考原文链接:https://blog.csdn.net/Albert52856/article/details/119836153