NodeJs 面试题 2023
(要知道对好事的称颂过于夸大,也会招来人们的反感轻蔑和嫉妒。——培根)
ㅤㅤㅤ
ㅤㅤㅤ
ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ
NodeJs相关
-
什么是NodeJs
- Nodejs是一个基于V8虚拟机的JavaScript的运行时平台,使用了事件驱动和非阻塞IO模型,让JavaScript能够像Java,PHP等语言一样运行在服务端
-
NodeJs优势
- 开发效率高,js动态语言, 不强制要求类型
- io性能强劲,依靠libuv,不用考虑多线程等复杂操作(线程创建和销毁,线程锁,线程管理),降低开发成本
- 有强大的npm包平台,类似Java的maven
- 前后端语言统一,降低开发成本
-
NodeJs常见应用场景
- web后端开发,目前流行的框架有express,koa,egg,nestjs等
- app后端开发,作为后端提供http等服务接口
- 桌面端开发,比如用nw.js和electron.js框架开发桌面端应用
- web端服务器控制台后端开发,比如tty.js
- 3D引擎建模和渲染,比如使用Three.js和Grimoire.js制作3D引擎
- 游戏制作,比如使用pomelo.js和Phaser.js等制作网页游戏
- 日常工作脚本,比如解析表格,统计数据等
-
和JavaScript的区别
- JavaScript只能应用在前端,Nodejs可以让JavaScript运行在服务端
- JavaScript的全局对象是windows,而Node是Global
- JavaScript因为浏览器的差异要考虑兼容性,而Nodejs是服务端,所以不需要考虑兼容性
- Node的事件循环依赖底层libuv,JavaScript的事件循环依赖的是浏览器
-
和Java相比的区别
- node是单线程,java是多线程
- node使用js语言,开发成本低,io多线程由libuv提供,省去了操作多线程的成本(比如多线程的创建和销毁,锁的管理,设计复杂)
- node是解释性语言,运行时才进行编译检查。而java是半编译半解释型语言
- node是弱类型语言,编码中不强制类型。java是强类型语言,编码中强制类型
- node使用的是js语言,前后端统一语言,降低开发成本,维护成本,前后端工具包通用,提高团队整体开发效率
-
NodeJs的优缺点
- 优点
- js语言不强制要求类型,开发效率高
- 前后端语言统一
- 降低团队的沟通成本,提高工作效率
- 前后端的工具包可以通用
- 全栈开发
- 性能强劲,node底层使用libuv管理多线程,利用异步事件模型来提高IO性能
- 使用libuv不用关心多线程的创建和销毁,不用自己管理多线程,间接的提高了开发效率
- 多进程提高服务性能,利用work子进程分担主进程的任务,也能间接的提高算力
- 缺点
- js弱类型,可以动态更改类型,导致后期代码维护难度升高
- 虽然底层有libuv提高io性能,也有多进程提高并发执行,但对于cpu密集型任务来说,依然是劣势。即便node10x版本提供了工作线程,但使用和管理起来过于麻烦
- 因为是单线程,所以代码中任意一处发生的异常都是致命的,需要开发者谨慎处理异常
- 优点
-
NodeJs特性都有哪些
- 事件驱动
- 非阻塞io
- 单线程(但io操作是多线程)
-
NodeJs事件驱动是什么
- 典型的发布订阅模式,只有当事件发生的时候才会调用回调函数。其中会有一个事件队列不断的获取事件来执行
-
NodeJs事件驱动的优缺点
-
优点
- 适合处理密集型I/O任务:通过事件循环机制,多个并行的任务,在JavaScript处理起来,只是将不同的任务分配给不同的线程,等待返回结果执行即可。所以处理速度超级快,有很高的实时性。
- 适合处理高并发:RESTful Api动辄发起成千上万条请求,但是请求本身并没有太多的计算量,开启多线程处理等待结果又太浪费机器性能。所以事件循环非常适合处理此种场景。
- 适合处理少量业务逻辑:例如浏览器中,在处理用户交互事件,页面渲染等少量业务逻辑的场景上,具有很好实时性,能给用户提供很流畅的体验。
-
缺点
- 不适合cpu密集型应用:因为JavaScript单线程的设计,因此,对于高强度运算的任务,可能会因为运算能力有限,导致任务处理时间过长,影响后续任务执行。
- 解决办法
- 业务代码优化,将单个cpu密集型任务拆成多个子任务,留出一定时间间隔执行其他任务
- 利用多进程提高服务处理能力
- 利用工作线程提高计算能力
- 解决办法
- cpu利用率低:因为单线程的原因,cpu多核性能利用率低。
- 解决办法
- 利用多进程提高cpu多核利用率
- 解决办法
- 安全性低:因为单线程的原因,如果主线程发生错误,将直接导致应用崩溃。
- 解决办法
- 添加全局异常过滤器,做默认异常处理
- 做好线上监控,收到反馈时及时处理
- 解决办法
- 不适合cpu密集型应用:因为JavaScript单线程的设计,因此,对于高强度运算的任务,可能会因为运算能力有限,导致任务处理时间过长,影响后续任务执行。
-
-
NodeJs事件驱动原理
-
事件循环是 Node.js 处理非阻塞 I/O 操作的机制——尽管 JavaScript 是单线程处理的——当有可能的时候,它们会把操作转移到系统内核中去。
既然目前大多数内核都是多线程的,它们可在后台处理多种操作。当其中的一个操作完成的时候,内核通知 Node.js 将适合的回调函数添加到 轮询 队列中等待时机执行
-
详情请看NodeJs事件循环原理
-
-
libuv线程池运行原理
-
libuv最初是为nodejs编写的跨平台支持库。它是围绕事件驱动的异步 I/O 模型设计的
-
libuv 提供了一个线程池,可用于运行用户代码并在循环线程中获得通知。此线程池在内部用于运行所有文件系统操作,以及 getaddrinfo 和 getnameinfo 请求。
它的默认大小是 4,但可以在启动时通过将
UV_THREADPOOL_SIZE环境变量设置为任何值来更改它,最大支持1024个线程 -
线程池是全局的,并且在所有事件循环中共享。当特定函数使用线程池时(即使用时
uv_queue_work()),libuv 会预先分配并初始化 允许的最大线程数UV_THREADPOOL_SIZE。这会导致相对较小的内存开销,但会提高运行时线程的性能
-
-
NodeJs如何使用libuv中的线程池
- node通过使用node-gyp将c++代码编译成.node文件,然后在js内部引入就可以使用了。
- 通过c++提供的接口,在node里就可以利用libuv驱动来使用系统资源了
-
NodeJs事件驱动和浏览器的事件循环区别是什么
-
浏览器的事件循环队列分为macro(宏任务)队列和 micro(微任务)队列。宏任务队列可以有多个
-
当某个宏任务执行完后,会查看是否有微任务队列。如果有,先执行微任务队列中的所有任务,如果没有,会读取宏任务队列中排在最前的任务,执行宏任务的过程中,遇到微任务,依次加入微任务队列。栈空后,再次读取微任务队列里的任务,依次类推。
-
比如以下代码就能够很明显的看出浏览器事件循环和nodejs事件循环的区别
function test () { console.log('start') setTimeout(() => { console.log('children2') Promise.resolve().then(() => {console.log('children2-1')}) }, 0) setTimeout(() => { console.log('children3') Promise.resolve().then(() => {console.log('children3-1')}) }, 0) Promise.resolve().then(() => {console.log('children1')}) console.log('end') } test() // 以上代码在node11以下版本的执行结果(先执行所有的宏任务,再执行微任务) // start // end // children1 // children2 // children3 // children2-1 // children3-1 // 以上代码在node11及浏览器的执行结果(顺序执行宏任务和微任务) // start // end // children1 // children2 // children2-1 // children3 // children3-1
-
-
浏览器线程模型
-
chrom线程模型
-
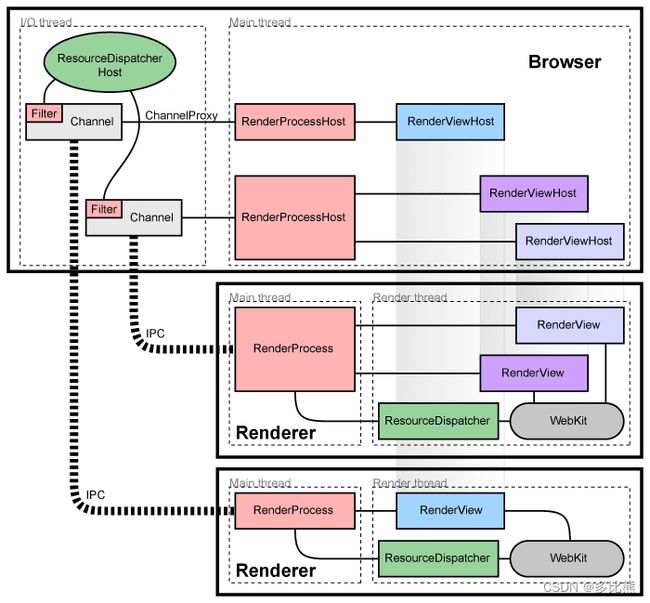
-
chrom是多进程+多线程的,对于每一个chrom进程,它都有一个主线程用来处理UI和JS代码,还有一个IO线程用来处理网络请求。
-
-
NodeJs如何提升性能和代码质量
- 提高性能
- node自身
- 多用promise并行处理io,或者其他的第三方异步io库,比如async,bluebird
- 减少同步代码,多使用异步
- 使用typescript,虽然开发成本提高了,但性能会提升。因为动态类型的代码,v8虚拟机在运行的时候会反复的执行优化,如果不更改类型,那么就不会触发v8虚拟机的反优化。也是一个提高性能的手段
- 使用多进程,充分利用CPU的多核机制。提高处理非IO类业务的性能
- 数据库
- 热点数据使用缓存设计,比如使用redis进行存储
- 数据库分库分表,减小库和表的数据大小,提高检索性能。数据量的减少意味着检索范围也会缩小,从而提升了性能
- 分库(适用于系统全局化处理)
- 比如后台有定时脚本,每天凌晨遍历目前所有库/指定库的大小,如果某库的磁盘空间占用大于100g,则按照日期规则,使用日期作为后缀进行分库,然后将该库作为新租户/用户库
- 分表(适用于针对某业务模块或某租户)
- 比如后台有定时脚本,每天凌晨遍历所有库/指定库内表的大小,对超过2gb或者3gb的,按照日期规则,使用日期作为后缀进行分表,然后将该表作为新租户/用户的表
- 分库分表后带来的问题
- 如果设计不当,则导致租户/用户的数据分散存储在不同的库和表中,导致后期维护困难,所以我们尽量让他们之间独立,每个租户/用户只使用一个分库,分库下的表可以根据大小进行分表,新业务和分表呈一对一的关系。就业务的表不再分表处理,而是做冷热数据处理
- 分库(适用于系统全局化处理)
- 数据库表添加索引,对热点字段建立索引,提高检索性能。数据库性能提升的主要方式之一
- sql优化
- 为热点数据建立合适的索引,唯一索引,组合索引等
- 使用projection只查询需要的字段,避免返回多余的字段
- 比如mongodb数据库,避免使用" n e " , " ne"," ne","exist"," n o t " , " not"," not","nin"等字段,这些字段在查询时不会使用索引,所以检索性能较差
- 限制返回的结果数,比如limit。当结果数过多时,会降低性能
- 表字段内容不要过大,比如几m,几十m的那种。过大的字段会在保存和查询的时候降低性能
- 表字段优化,避免因过度设计而导致的冗余字段降低性能,比如加入了未来5-10年的发展中,业务可能需要的字段
- 数据库集群 以mongodb为例
- 使用副本集,读写分离,提高检索性能
- 当数据量达到千万,亿级别时可以使用分片。副本集虽然读写分离,但数据的存储并没有分离。mongodb的分片解决了这个问题,相比较副本集,一个副本存储了所有数据库,但分片等于一个副本的数据分别存储到数十个,数百个分片中。查询的时候,同时从这些分片中进行查询,将查询的性能又提高了一个档次
- 用户的请求会发送给 mongos 路由服务器, 路由服务器会根据查询条件去配置服务器查询对应的数据段和属于哪个分片服务器, 如果用户查询的条件是分片片键字段, 那么路由服务器会返回保存在那一台分片服务器上, 路由服务器就会去对应的分片服务器获取数据, 并将取到的数据返回给用户。
- 如果用户查询的条件不是分片片键字段, 那么配置服务器无法告知路由服务器数据保存在哪一个分片服务器上,路由服务器会把请求发送到所有的分片服务器上, 然后再将查询到的数据汇总后返回给用户。
- 冷热数据分离,根据租户/用户的活跃时间,将不活跃用户(比如最近两年没有登陆过)的数据迁移至冷数据库集群中(副本集较少,配置较低,分片数少的集群),这样就可以减少主集群的数据量,提高磁盘空间和检索性能。当不活跃用户由活跃时,通过后台脚本或者服务将该用户的数据再进行回迁即可。
- 架构优化
- 不使用框架,使用原生js进行编码(对团队素质和技术能力要求极高)。因为现在的流行框架大多都加入了一些实际业务不需要的代码,间接的拖慢了服务性能
- 提高硬件配置,比如内存,cpu,带宽等
- 横向扩展服务集群,搭配负载均衡策略,提高服务的整体吞吐量和性能
- 使用k8s容器化管理,使用沙箱隔离服务间环境(减少服务间的影响),合理分配每个服务运行环境的pod配置,既提高服务性能还能提高稳定性
- node自身
- 提高质量
- 使用typescript,集成eslint,避免使用any,提前检查错误,减少bug出现率
- 审查代码,每次代码版本测试/发布前进行审查,及时对有问题的代码进行优化和修复
- 核心代码编写注释,方便后期维护和二次开发
- 抽象通用组件,提高代码复用性,减少冗余代码
- 编写测试单元,发版前运行测试单元
- 提高服务高稳定性
- 完善系统监控,比如使用grafana实时监测服务的cpu,内存,硬盘,IO等
- 完善日志分析系统,比如使用业界流行的kibana日志分析平台
- 完善的日志检索功能
- 完善的可视化图标分析
- 完善服务整体高可用性,比如使用k8s生态,rancher,harbor等
- 服务发现和负载均衡
- Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定
- 滚动发布
- 每次先关闭一个pod,再重启一个pod,可以保证服务不中断的情况下进行系统升级
- 镜像回滚
- 利用harbor和rancher对镜像进行管理,可以使用界面或命令进行一键回滚
- 自动完成装箱计算
- Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源
- 自我修复
- Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器
- 密钥与配置管理
- Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥
- 更便捷的水平扩展
- 通过rancher等可视化界面,可以快速的对pod进行管理,比如新增,删除,调整pod的资源等
- 健康检查
- k8s会对每一个pod做定时的健康检查,对于非健康的pod,k8s会对它做重启处理
- 服务发现和负载均衡
- 提高性能
-
常用的排序算法
/** * @event 快速排序 * @description * * 快速排序是对冒泡排序的一种改进。它的基本思想是: * 通过一趟排序将要排序的数据分割成独立的两部分, * 其中一部分的所有数据都比另外一不部分的所有数据都要小, * 然后再按此方法对这两部分数据分别进行快速排序, * 整个排序过程可以递归进行,以此达到整个数据变成有序序列。 * 整个排序过程只需要三步: 1. 找到该数组的基准点(中间数),并创建两个空数组left和right; 2. 遍历数组,拿出数组中的每个数和基准点进行比较, 如果比基准点小就放到left数组中,如果比基准点大就放到right数组中; 3. 对数组left和right进行递归调用 */ //第一种方式(类似二分法,一直缩小范围) //先处理leftArr的递归,再处理rightArr的递归 const arrSortFast = (arr) => { if (arr.length <= 1) { return arr; } const leftArr = []; const rightArr = []; //每次删除一个数组元素并获得返回值当作基数,直到数组被删除到只剩下一个时,直接返回 //Math.round 向上取整 3.5取4 3.3取3 const baseNumber = arr.splice(Math.round(arr.length / 2), 1)[0]; arr.forEach(v => { if (v < baseNumber) { leftArr.push(v); } else { rightArr.push(v); } }); const value = arrSortFast(leftArr).concat([baseNumber], arrSortFast(rightArr)); return value; }; console.log(arrSortFast([2,3,1,4])); /** * 算法解析 * 第一阶段: * 取出中位数 9 * 当前数组为 [5, 3, 6, 10, 2, 4, 7, 1, 8] * 经过左右过滤 * 左数组为 [5, 3, 6, 2, 4, 7, 1, 8] * 右数组为 [10] * * 第二阶段:使用左数组继续递归 * 取出中位数 4 * 左数组为 [3, 2, 1] * 右数组为 [5, 6, 7, 8] * * 第二阶段继续:使用左数组继续递归 * 取出中位数 2 * 左数组为 1 * 右数组为3 * 由于过滤的只剩下最后一个,所以直接返回 * 此时结果为[1, 2, 3] * * 第二阶段继续:使用右数组进行递归 * 取出中位数7 * 左数组为 [5, 6] 超过两个元素的都会进行再次递归 那么此时得到的结果肯定也是[5, 6] * 右数组为 [8] * 此时结果为 [5, 6, 7, 8] * * 此时已经得到过滤后的左右数组分别为[1, 2, 3]和[5, 6, 7, 8],中位数是4 * 那么此时结果为[1, 2, 3, 4, 5, 6, 7, 8] * * 当前回到第一阶段 * [5, 3, 6, 2, 4, 7, 1, 8]过滤后的结果为[1, 2, 3, 4, 5, 6, 7, 8] * 中位数是9 右数组是[10] * 那么此时最终结果为[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] */ /** * 冒泡排序法 * 相邻比较 */ ((arr = [4, 3, 5, 4, 1, 3, 2, 0, 3, 88]) => { let length = arr.length; // 单层for循环 for (let j = 0; j < length; j++) { if (arr[j] > arr[j + 1]) { let temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } // 在循环到最大值时候重置j(j=-1到上面j++重置为0)这样可以省了外层for循环 if (j == length - 1) { j = -1; length--; } } console.log(arr); })(); /** * 第一阶段过滤得到结果 * [3, 4, 5, 4, 1, 3, 2, 0, 3, 88, 99] * * 第二阶段过滤 此时把长度-1 * [3, 4, 5, 1, 3, 2, 0, 3, 4, 88, 99] * * 第三阶段过滤 * [3, 4, 1, 3, 2, 0, 3, 4, 5, 88, 99] * * 第四阶段过滤 * [3, 1, 3, 2, 0, 3, 4, 4, 5, 88, 99] * * 以此类推 一直比较 得到结果 */ /** * 选择排序 * 选择某一个元素当作最小数依次遍历 * 每次找到最小值和前面的位置进行替换 */ ((arr = [8,9,7,6,4,7]) => { const len = arr.length; let minIndex; let temp; for (let i = 0; i < len; i++) { minIndex = i; //选择当前下标为最小元素 for (let j = i + 1; j < len; j++) { if (arr[minIndex] > arr[j]) { //每一次从i+1个开始遍历找出比自身小的元素 minIndex = j; //将最小数的索引保存 } } //接下来的操作类似冒泡,都是互换元素位置 temp = arr[i]; arr[i] = arr[minIndex]; arr[minIndex] = temp; } console.log(arr); })(); -
Http七层协议工作原理,都有哪些状态码,分别是什么意思
-
为什么需要协议?
- 如果苹果,三星,华为都是自己的协议,那么就只能和自己通信,所以就弄一个标准化的协议,所有人来实现,这样所有人就能互通了
-
四层协议关系
- 应用层:http协议,邮件服务协议
- 传输层:TCP协议
- SYN 建立连接
- FIN 关闭连接
- ACK 响应连接
- PSH DATA数据传输
- RST 连接重置
- 网络层:IP协议
- 数据链路层:以太网协议
-
端口号范围0-65535,1024之前不允许用
-
物理层
- 过去:通过家里的猫来连接网线实现电脑间的通信,这个就属于物理层
- 现在:连接无线网,属于无线讯号,也是物理层
- 连接上之后传递010101的电路信号
-
数据链路层
- 是给电路信号分配规则的,过去每个公司都有自己的电路信号规则。
- 后来出现了以太网协议,将电信号归纳成一个数据包,也叫一个帧。
- 每一帧都分成两部分,标头head和数据data
- 标头head包含了一些说明信息,比如发送者mac地址,接收者mac地址和数据类型等
- 而电路信号的通信又依赖网卡,利用电脑间的网卡进行通信
- 以太网协议规定网卡包含mac地址,mac地址是网卡的唯一标识,全球唯一
- 12个16进制的数字表示mac地址
- 前6个16进制数字是厂商编号
- 后6个16进制数字是网卡流水号
- windows使用ipconfig命令查看mac地址 物理地址 比如7C-67-A2-20-AB-5C
- linux使用ifconfig -a命令查看mac地址
- 所以以太网传递数据包就必须指定接收者的mac地址才能进行传输
- 以太网协议如何根据网卡进行通信的?
- 局域网情况下,也叫子网
- 在以太网内一个数据包的发送,会先广播给局域网的所有电脑设备网卡,然后每台电脑都从数据包中取出接收者的mac地址和自己的mac地址进行对比,如果是一样的,则说明是给自己发送的数据包才进行处理,否则就丢弃数据包
- 如何知道哪些电脑在当前局域网内呢?
- 这就需要依靠网络层来支持了
- 请看下面的网络层
- 这就需要依靠网络层来支持了
- 局域网情况下,也叫子网
- 以太网协议规定网卡包含mac地址,mac地址是网卡的唯一标识,全球唯一
-
网络层
- 网络层里有ip协议,ip协议定以的地址就是ip地址。ip地址理由ipv4和ipv6两种类型,目前广泛使用的是ipv4,是由32个二进制数字组成,但一般由4个十进制数字来表示,范围是0.0.0.0到255.255.255.255
- 每台电脑都有一个ip地址,前24位(前3位十进制数字)代表网络,后8位(最后1个十进制数字)代表了主机,如果几台电脑是一个子网的,那么前3位十进制的数字就是一样的
- 比如开虚拟机或者连接的都是同一个网线,无线网,则电脑的ip地址分别是192.168.0.180,192.168.0.181,192.168.0.182,192.168.0.183,可以看出192.168.0这三位数字是一样的就证明大家是一个子网的,最后一个数字就是主机编号
- 但上面的描述不是百分百准备,需要将子网掩码进行二进制运算才可以真正对比出是不是属于同一个子网内
- 比如192.168.0.180和192.168.0.181 通过二进制运算后的结果分别式
- 11000000.10101000.0.10110100
- 11000000.10101000.0.10110101
- 然后判断前三位 如果相同则证明是一个子网
- 最后一位表示主机编号
- 所以通过子网掩码就可以确定局域网下的电脑,然后就可以互相通信了
- 但如果不在一个子网内?是如何通信呢
- 所以这就需要路由器
- 路由器 也成为网关
- 可以把多个子网给串联起来
- 根据以太坊协议,网卡间只能在子网内进行通信,但要和其他网卡进行通信,就可以把包发给交换机,交换机再把包进行广播,路由器(路由器也有mac地址)上的网卡收到后判断是不是自己的,是自己的话,再通过交换用以太坊协议进行广播分发
- 所以以太网要和多个子网进行通讯,就需要交换机和路由器
- ARP协议
- 一个局域网内的机器会互相给对方发送自己的mac地址,所以当一个机器要发送数据包时,就可以知道其他电脑的mac地址了
- 交换机,一种工作在数据链路成的设备,网关是工作在网络层
- 总结:子网间的机器如何通信,在数据包中写上对方的mac地址,通过交换机用以太坊协议进行广播。如果是跨子网通信,在包里写上目标和路由器的mac地址,路由器再根据目标地址通过交换机进行广播,一直持续找到最终mac地址为止
- LAN 局域网
- WAN 广域网
- WLAN 无线局域网
- 但同一个电脑下运行着qq,微信,视频等软件,怎么区分数据包是发给这个ip下的哪一个服务呢?那么就需要有一个端口的概念来进行区分,所以这也是为什么端口要唯一的原因。
- 那么如何将数据包发到某一个ip的某一个端口上?这就需要TCP协议了
-
传输层
-
TCP协议简述
-
存在长连接和短连接
-
短链接
-
TCP短连接:client向server发起连接请求,server接到请求,然后双方建立连接。client向server发送消息,server回应client,然后一次请求就完成了。这时候双方任意都可以发起close操作,不过一般都是client先发起close操作。上述可知,短连接一般只会在 client/server间传递一次请求操作。
短连接的优点是:管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段
-
-
长连接 keepalive
- TCP长连接的情况:client向server发起连接,server接受client连接,双方建立连接,client与server完成一次请求后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。
- 如果一个给定的连接在两小时内没有任何动作,服务器就向客户发送一个探测报文段,根据客户端主机响应探测4个客户端状态
- 客户主机依然正常运行,且服务器可达。此时客户的TCP响应正常,服务器将保活定时器复位。
- 客户主机已经崩溃,并且关闭或者正在重新启动。上述情况下客户端都不能响应TCP。服务端将无法收到客户端对探测的响应。服务器总共发送10个这样的探测,每个间隔75秒。若服务器没有收到任何一个响应,它就认为客户端已经关闭并终止连接。
- 客户端崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
客户机正常运行,但是服务器不可达。这种情况与第二种状态类似。
-
什么时候用长连接或者短连接
- 长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,下次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
- 而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好。
-
-
服务于会话层
-
建立在某个主机的某个端口到另一个主机下某个端口的连接和通信的,这个通信是使用socket来实现,通过socket实现上面的ip寻址,而且还会建立端口间的连接。规定了一套基于端口的通信协议,包括建立连接,发送和读取消息。
-
大概机制就是在数据包中加入端口号,寻址到ip后,再去寻找监听该端口号的服务,将数据包发送过去
-
特点
- TCP依靠端口来进行通信 TCP头有自己的端口 TCPdata有目标的端口
- 传输可靠,因为要经历三次握手和四次挥手
- 可靠性传输依赖的是ARQ协议
- 流量控制
-
-
UDP协议简述
- UDP提供无连接服务
- 不需要维护连接状态
- 适用于效率高的应用
- 不像TCP那样每一次发送都需要进行确认
- 性能高,开销小
- 连接不可靠
-
-
会话层
- 维护两个节点的传输连接,确保点到点传输不中断和管理数据交换等功能
-
表示层
- 提供各种用于应用层数据的编码和转换功能,确保一个系统的应用层发送的数据能被另一个系统的应用层识别
- 作用
- 数据编码和解码
- 数据加密和解密
- 数据压缩和解压缩
- 展示图片,音频和视频等
- 总结
- 表示层从应用层接收数据。这些数据是以字符和数字的形式出现的,表示层将这些数据转换成为机器可以理解的二进制格式,也就是封装数据,和格式化数据。例如:将ASCII码转化为别的编码,这个功能称为“翻译”。在传输数据之前,表示层减少了用来表示原始数据的比特数,这个过程被称为数据压缩,它可以是无损或者有损的,数据压缩减少了存储原始数据所需的空间,所以它可以在很短的时间内到达目的地,数据压缩对实时视频和音频的传输有很大的帮助。
- 为了保持完整性的数据,传输前的会给数据加密,而加密和解密是敏感数据的安全保障,在中心端,数据在接受端被加密,数据被解密为SSL协议或者安全套接字。
- 所以,
表示层执行三个基本功能:翻译、压缩和加密/解密。
-
应用层 http协议(80端口),https(443端口),ftp(21),ssh(22),smtp(25)
-
TCP能传输数据了,为什么还需要类似http这种应用层协议?
- 因为如果每个公司都有自己的应用层协议,那么会导致两端数据无法识别。所以就需要抽象出国际协议,比如http(Hyper Text Transfer Protocol)。
- 它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;而消息内容则具有一个类似MIME的格式。这个简单模型是早期Web成功的有功之臣,因为它使开发和部署非常地直截了当
- 因为我们在传输数据时,可以只使用TCP/IP协议进行传输,但是这样没有应用层的参与,会导致两端无法识别数据内容,这样传输的数据也就没有意义了。因此如果想让传输的数据有意义,那么就必须要用到应用层的协议,比如http
- web使用http协议作为应用层协议,封装http文本信息,然后使用tcp协议进行传输
-
http长连接 keep-alive
-
若开启后,在一次http请求中,服务器进行响应后,不再直接断开TCP连接,而是将TCP连接维持一段时间。在这段时间内,如果同一客户端再次向服务端发起http请求,便可以复用此TCP连接,向服务端发起请求,并重置timeout时间计数器,在接下来一段时间内还可以继续复用。这样无疑省略了反复创建和销毁TCP连接的损耗
-
启用HTTP keep-Alive的优缺点:
优点:keep-alive机制避免了频繁建立和销毁连接的开销。 同时,减少服务端TIME_WAIT状态的TCP连接的数量(因为由服务端进程主动关闭连接)
缺点:若keep-alive timeout设置的时间较长,长时间的TCP连接维持,会一定程度的浪费系统资源。
总体而言,HTTP keep-Alive的机制还是利大于弊的,只要合理使用、配置合理的timeout参数。
-
和TCP的keepalive区别是
- TCP的是为了检测心跳,保持活跃的
- HTTP的主要是在TCP的保活基础上重用连接,提高性能的
-
-
-
什么是DNS
- 通常我们访问网址都需要输入一个域名,但协议都是根据ip进行寻址的,所以会有一个DNS服务器,输入一个域名的时候会先发给DNS服务器,DNS服务再告诉你对应的ip地址
-
-
WebSocket面试题
-
websocket和socket的区别
-
什么是socket协议
- socket是应用层与TCP/IP协议通信的中间软件抽象层,它是一组接口。而websocket协议是一个完整的应用层协议,基于TCP长连接实现的
- Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
- Socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作, socket就是该模式的一个实现,socket是一种特殊的文件,一些socket函数就是对其进行的操作(打开、读/写IO、关闭)。
- 套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用程序进行通信。网络套接字是IP地址与端口的组合。
-
sockey协议调用流程
- 先从服务器端说起,服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
-
socket核心api
-
**socket():**创建套接字。
**bind():**指定本地地址。一个套接字用socket()创建后,它其实还没有与任何特定的本地或目的地址相关联。在很多情况下,应用程序并不关心它们使用的本地地址,这时就可以不用调用bind指定本地的地址,而由协议软件为它们选择一个。但是,在某个知名端口(Well-known Port)上操作的服务器进程必须要对系统指定本地端口。所以一旦创建了一个套接字,服务器就必须使用bind()系统调用为套接字建立一个本地地址。
-
**listen():**设置等待连接状态。对于一个服务器的程序,当申请到套接字,并调用bind()与本地地址绑定后,就应该等待某个客户机的程序来要求连接。listen()就是把一个套接字设置为这种状态的函数。
-
**connect():**将套接字连接到目的地址。初始创建的套接字并未与任何外地目的地址关联。客户机可以调connect()为套接字绑定一个永久的目的地址,将它置于已连接状态。对数据流方式的套接字,必须在传输数据前,调用connect()构造一个与目的地的TCP连接,并在不能构造连接时返回一个差错代码。如果是数据报方式,则不是必须在传输数据前调用connect。如果调用了connect(),也并不像数据流方式那样发送请求建连的报文,而是只在本地存储目的地址,以后该socket上发送的所有数据都送往这个地址,程序员就可以免去为每一次发送数据都指定目的地址的麻烦。
-
**accept():**接受连接请求。服务器进程使用系统调用socket,bind和listen创建一个套接字,将它绑定到知名的端口,并指定连接请求的队列长度。然后,服务器调用accept进入等待状态,直到到达一个连接请求。
-
**read()、write():**当服务器与客户已经建立好连接之后。可以调用网络I/O进行读写操作了,即实现了网咯中不同进程之间的通信
-
-
-
什么是websocket
- HTML5的一种新协议,允许服务器向客户端传递信息,实现浏览器和客户端双工通信
-
运行原理
-
为什么要用
- 因为http协议请求后都会关闭连接,下次请求的时候又要重新建立连接。但长轮询过多时会对服务器负载造成较大影响。所以就用websocket协议来完成类似聊天室,实时状态推送等业务场景功能
-
应用场景
- 实时通信
-
特点
- 与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器
- 数据格式比较轻量,性能开销小,通信高效
- 没有同源限制,客户端可以与任意服务器通信
-
基于TCP再次封装的另一个协议
-
首先在连接的时候会发送一个协议升级请求,在http请求上加上socket相关的请求头
-
Sec-WebSocket-Extensions: permessage-deflate; client_max_window_bits Sec-WebSocket-Key: k1kbxGRqGIBD5Y/LdIFwGQ== Sec-WebSocket-Version: 13 Upgrade: websocket
-
-
服务端如果支持socket的话,会返回101状态码同意协议升级
-
总结概述
- websocket是HTML5新增的一种全双工通信协议,客户端和服务端基于TCP握手连接成功后,两者之间就可以建立持久性的连接,实现双向数据传输。它也是基于TCP协议的,建立连接时也是先通过TCP完成三次握手,然后再发送一个http请求,携带协议升级的相关请求标识,比如Upgrade: websocket。服务端同意协议升级并返回一个回包进行确认,这样websocket就连接上了
- 后续的发送消息就依靠网络层协议来完成了,交换机,网关等
- websocket是HTML5新增的一种全双工通信协议,客户端和服务端基于TCP握手连接成功后,两者之间就可以建立持久性的连接,实现双向数据传输。它也是基于TCP协议的,建立连接时也是先通过TCP完成三次握手,然后再发送一个http请求,携带协议升级的相关请求标识,比如Upgrade: websocket。服务端同意协议升级并返回一个回包进行确认,这样websocket就连接上了
-
-
WebSocket和Http区别,相比的优缺点
- 总结
- websocket是全双工协议,客户端和服务端双向通信
- websocket协议头是ws/wss,http是http/https
- websocket只需要连接一次,http需要反复的创建和关闭连接
- websocket不关注接收者的状态,http需要关注接收者的状态
- 两个都是基于socket协议(socket基于TCP协议)
- 相同点
- 都是 TCP 协议;
都使用 Request/Response 模型进行连接的建立;
websocket 是基于 http 的,他们的兼容性都很好;
在连接的建立过程中对错误的处理方式相同;
都可以在网络中传输数据。
- 都是 TCP 协议;
- 不同点
- websocket 是持久连接,http 是短连接;
websocket 的协议是以 ws/wss 开头,http 对应的是 http/https;
websocket 是有状态的,http 是无状态的;
websocket 连接之后服务器和客户端可以双向发送数据,http 只能是客户端发起一次请求之后,服务器才能返回数据;
websocket 是可以跨域的;
websocket 连接建立之后,数据的传输使用帧来传递,不再需要Request消息。
- websocket 是持久连接,http 是短连接;
- 总结
-
为什么用这个技术
- 解决http长轮询造成的性能和资源浪费问题
-
WebSocket和Socket.io区别
- socket.io是对websocket的再一次封装
- 相比websocket,它提供了以下接口
- 自动重连
- 自动检测掉线
- 广播
- 解决因浏览器兼容导致的问题
- 有些浏览器不兼容,所以默认还支持了长轮询的尝试
- 前后端都要使用socket.io库
- socket.io是对websocket的再一次封装
-
socket.io工作原理
- 首先,
socket.io通过一个http请求,并且该请求头中带有升级协议(Connection:Upgrade、Upgrade:websocket)等信息,告诉服务端准备建立连接,此时,后端返回的response数据 - 当客户端收到响应之后,
scoket.io会根据当前客户端环境是否支持Websocket。如果支持,则建立一个websocket连接,否则使用polling(xhr、jsonp)长轮询进行双向数据通信 - 心跳参数配置
- pingTimeout
- Ping消息超时时间(毫秒),默认20秒,这个时间间隔内没有接收到心跳消息就会发送超时事件
- 默认是20000,20秒
- pingInterval
- Ping消息间隔(毫秒),默认25秒。客户端向服务器发送一条心跳检测
- 默认是25000,25秒
- upgradeTimeout
- 协议升级超时时间(毫秒),默认10秒。HTTP握手升级为ws协议超时时间
- pingTimeout
- 心跳检测机制
- 概述
- 为了确保客户端与服务端的长连接正常,有时即使客户端连接中断,但是服务端未触发onclose事件,这就有可能导致无效连接占用。所以需要一种机制,确保两端的连接处于正常状态,心跳检测就是这种机制。客户端每隔一段时间,会向服务端发送心跳(数据包),服务端也会返回response进行反馈连接正常。
socket.io与engine.io的一大区别在于,socket.io并不直接提供连接功能,而是在engine.io层提供。
- 概述
- 首先,
-
-
什么是跨域,如何解决
- 跨域的概念
- 浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域
- 需要同源策略的原因
- 设置同源策略的主要目的是为了安全,如果没有同源限制,在浏览器中的cookie等其他数据可以任意读取,不同域下的DOM任意操作,ajax任意请求其他网站的数据,包括隐私数据。
- 哪些场景需要跨域
- 需要本地联调测试环境,本地用的local,测试环境用的ip或者域名
- 多个产品之间需要进行对接
- 如何解决跨域问题
- 请求头添加以下配置项 nginx和后端服务均可
- Access-Control-Allow-Origin 允许哪些网站的跨域请求
- Access-Control-Allow-Methods 允许的跨域ajax的请求方式
- Access-Control-Allow-Headers 允许在请求中携带的头信息
- jsonp请求
- 事先定义一个用于获取跨域响应数据的回调函数,并通过没有同源策略限制的
script标签发起一个请求(将回调函数的名称放到这个请求的query参数里),然后服务端返回这个回调函数的执行,并将需要响应的数据放到回调函数的参数里,前端的script标签请求到这个执行的回调函数后会立马执行,于是就拿到了执行的响应数据。- 优点
- 它不像
XMLHttpRequest对象实现的Ajax请求那样受到同源策略的限制 - 它的兼容性更好,在更加古老的浏览器中都可以运行,不需要
XMLHttpRequest或ActiveX的支持 - 并且在请求完毕后可以通过调用
callback的方式回传结果
- 它不像
- 缺点
- 它只支持
GET请求而不支持POST等其它类型的 HTTP 请求 - 它只支持跨域 HTTP 请求这种情况,不能解决不同域的两个页面之间如何进行JavaScript 调用的问题
- 它只支持
- 优点
- 事先定义一个用于获取跨域响应数据的回调函数,并通过没有同源策略限制的
- 请求头添加以下配置项 nginx和后端服务均可
- 跨域的概念
-
Nodejs的buffer原理和应用场景
- JavaScript 起初为浏览器而设计,没有读取或操作二进制数据流的机制。Buffer类的引入,则让NodeJS拥有操作文件流或网络二进制流的能力
- 也可以用来请求中的字符串转换
- 对字符串进行其他类型的编码解码等
-
Nodejs的流的应用场景以及运行原理
- 主要用于处理大文件,利用fs模块中的读取和写入流可以操作
- 也可以用stream模块,但一般fs模块就满足了,因为fs内部就继承了stream模块
- 解决因文件过大而导致的内存占用高的问题
-
Nodejs await/async原理
- async放在函数前 这个函数会返回promise
- await放在函数前 则会等待这个函数执行完毕
- 要了解await就要先理解generator函数
- Generator 函数是 ES6 提供的一种异步编程解决方案,语法行为与传统函数完全不同
- generator函数的特性有以下两点
- 一是,
function关键字与函数名之间有一个星号; - 二是,函数体内部使用
yield表达式
- 一是,
- generator是es6提供的函数同步执行的方法,使用*号标记函数为generator,内部使用yield暂停表达式,使用next进行放行
-
Nodejs多进程应用场景,如何做负载均衡和进程间通讯
- master进程负责启动子进程,然后子进程工作
- Worker 进程的数量一般根据服务器的 CPU 核数来定,这样就可以完美利用多核资源
-
进程和线程的区别
- 线程就可以当做是进程里面的执行的单元,同时它也是这个进程里面的一个能够调度的实体
-
CommonJs概念
- 由于早期javascript缺少模块的概念,产生了commonjs规范
- 规范特性
- 通过require引入模块并应用在当前的上下文
- 模块内部需要用exports来提供导出
- 相关文章
- Noejs CommonJS模块机制
-
Nodejs模块
- es5和es6区别
- es5使用require
- es6使用import
- es6 module属于编译时加载,也就是静态加载,在编译时就能确定模块的依赖关系,以及输入和输出的变量;commonjs属于运行时加载,只有代码在运行时才能确定这些东西。
- es6 module可以做到tree-shaking,也就是可以加载模块部分用到的内容,commonjs需要加载整个模块,再取内容。
- es6 module输出的是值的引用,commonjs输出的是值的拷贝。
- es6 module中的import是异步加载,commonjs中的require是同步加载
- export和export.default区别
- export.default是默认导出,一个模块只允许有一个默认导出,重复的会被覆盖
- export类似module.export,可以导出一个或多个成员
- es5和es6区别
-
ExpressJs
- 概念
- node中上手最简单,内置功能多的框架
- 特点
- 内置了常用中间件,方便使用
- express.static 提供静态资源,例如 HTML 文件、图像等
- exporess.json 使用 JSON 有效负载解析传入请求
- express.urlencoded 解析带有 URL 编码负载的传入请求
- express.text(基于body-parser) 将请求参数解析为字符串
- express.router 路由文件
- 回调基于callback
- 内置了常用中间件,方便使用
- 概念
-
KoaJs
-
概念
- 下一代的nodejs框架koa 是由 Express 原班人马打造的,致力于成为一个更小、更富有表现力、更健壮的 Web 框架。使用 koa 编写 web 应用,通过组合不同的 generator,可以免除重复繁琐的回调函数嵌套,并极大地提升错误处理的效率。koa 不在内核方法中绑定任何中间件,它仅仅提供了一个轻量优雅的函数库,使得编写 Web 应用变得得心应手
-
特点
-
洋葱卷模型
-
概述
- 先由内向外执行,再由外向内执行
-
源码
function compose (middleware) { // ... return function (context, next) { // last called middleware # let index = -1 // 一开始的时候传入为 0,后续会递增 return dispatch(0) function dispatch (i) { // 假如没有递增,则说明执行了多次 if (i <= index) return Promise.reject(new Error('next() called multiple times')) index = i // 拿到当前的中间件 let fn = middleware[i] if (i === middleware.length) fn = next // 当 fn 为空的时候,就会开始执行 next() 后面部分的代码 if (!fn) return Promise.resolve() try { // 执行中间件,留意这两个参数,都是中间件的传参,第一个是上下文,第二个是 next 函数 // 也就是说执行 next 的时候也就是调用 dispatch 函数的时候 return Promise.resolve(fn(context, dispatch.bind(null, i + 1))); } catch (err) { return Promise.reject(err) } } } }-
为什么需要
- 因为express的next在异步情况下的顺序不能保持一致,所以需要用await保证顺序,就形成了洋葱卷模型
- 其实就是express的next不是用promise实现的,导致异步无法控制,而koa的next是用promise实现的,再结合流行的await,可以很好的控制中间件的异步顺序
-
-
没有内置任何中间件,比express更轻量
-
基于es6,默认await/async
-
有一个统一上下文遍历ctx,方便业务处理,不再需要层层向下传递。
-
比koa1中的generator更简单的异步,async/await
-
缺点
- 上下文依赖ctx,导致ctx臃肿,难以维护
- 没有强一致的约束,对团队素质要求高
-
-
-
EggJs
- 特点
- 支持ts
- 基于koa,内置洋葱卷模型
- 约定大于配置
- controller
- service
- router
- 内置多进程模型
- node内置了一个模块cluster 多进程
- 插件机制
- 比起传统的util文件,插件更适合拓展和维护,一个插件只做一件事。
- 而且插件的约定也是按照egg的目录结构而来的,一个迷你的egg应用
- 去掉了router和controller
- 而且插件的约定也是按照egg的目录结构而来的,一个迷你的egg应用
- 比起传统的util文件,插件更适合拓展和维护,一个插件只做一件事。
- 渐进式开发
- 前期,最初团队抽象出了一些公共的方法 .util.ts
- 中期,这个通用方法还不是很完善,直接用插件不好维护,但可以先写成插件的形式
- 通过config/plugin.js来挂载
- 后期,经过一段时间考验后,该插件已经完善且稳定,所以可以进行单独的抽离
- 就是单独抽离出一个npm包,不过包结构要按照egg的格式来
- 终期,已经积累了很多可以复用的插件,并且在多个团队和项目中可以复用,所以此时可以沉淀到框架中
- 将可复用的插件单独抽象成一个框架给多个团队和项目使用
- 缺点
- 基于koa,自带多进程模型,相比较koa和express较重
- 约定大于配置,业务扩展难度高,插件扩展难度也会变高
- 基于koa,上下文依赖ctx,导致ctx臃肿,难以维护
- 特点
-
NestJs
-
特点
- 基于express
- 因为为了设计一个开箱即用的框架,而express内置了很多模块,所以基于express
- 完全支持typescript
- 类型约束
- 编译期间有类型检查,能预知错误
- 模块概念
- 通过模块将每个应用功能进行解耦。相比express等框架,没有模块约束,代码相比nestjs,维护难度更高
- 异常过滤器
- 全局的异常过滤器,对全局的异常做定制化处理
- 管道
- 对请求参数进行转换或者验证
- 守卫
- 用户权限校验
- 用户角色校验
- 用户鉴权等
- 更符合现代化编程的中间件模式
- 传统的express,koa等node框架,通过和路由编码的方式来进行绑定
- 而nestjs是基于模块进行中间件配置的形式来绑定中间件
- 拦截器,比如用于请求前后的日志链路追踪,或者请求和返回参数的定制化
- 官方文档非常完善,每一个模块都提供了标准的示例
- AOP(Aspect Oriented Programming),面向切面编程
- IOC
- 控制反转。比如传统的开发模式是每次都要重新实例化一个对象。但是在nestjs的IOC模式中,只需要将对象注入到构造函数声明中就行
- 生命周期钩子函数
- OnModuleInit
- 初始化主模块依赖处理后调用一次
- OnApplicationBootstrap
- 在应用程序完全启动并监听连接后调用一次
- OnModuleDestroy
- 收到终止信号(例如SIGTERM)后调用
- beforeApplicationShutdown
- 在
onModuleDestroy()完成(Promise被resolved或者rejected);一旦完成,将关闭所有连接(调用app.close() 方法).
- 在
- OnApplicationShutdown
- 连接关闭处理时调用(app.close())
- OnModuleInit
- OOP面向对象思想
- 面向对象编程,通过对象内的各种属性和方法来完成编程。容易维护和扩展。
- 封装 将通用的方法抽象到一个util内
- 继承 扩展类的功能
- super关键字用于访问和调用对象父类上的函数。可以调用父类的构造函数,也可以调用父类的普通函数
- 多态
- 同一操作作用于不同的对象上面,可以产生不同的解释和不同的执行结果
- 比如两个方法都有send函数,要在一个函数内进行调用,就要根据不同的方法调用不同的send函数。那么利用多态,直接将类初始化,函数内部只需要执行send方法而不需要关注上层是谁了
- 比如使用抽象类和接口实现
- 面向对象编程,通过对象内的各种属性和方法来完成编程。容易维护和扩展。
- FP函数式编程
-
函数式编程是一种强调以函数使用为主的软件开发风格 ,也是一种范式
- 用函数来编程,更好的模块化
- 函数可以复用
- 低耦合
-
伪代码
- 函数作为参数执行
- 函数作为返回值执行
-
其他的应用场景
编写可以轻松复用和配置的小代码块,就像我们使用npm一样
举个例子,你有一家商店,然后你想给你的优惠顾客10%的折扣:function discount (price, discount) { return price * discount } // 当一个顾客消费了500元 const price = discount(500, 0.1) // $50 // 从长远看,你的每一笔生意都要计算10%的折扣 const price = discount(1500, 0.1) // $150 const price = discount(2000, 0.1) // $200 const price = discount(50, 0.1) // $5 const price = discount(300, 0.1) // $30 // 将这个函数柯里化,然后我们就不用每次都写那0.1了 function discount (discount) { return (price) => { return price * discount } } const tenPercentDiscount = discount(0.1) // 现在,我们只需用商品价格来计算就可以了: tenPercentDiscount(500) // $50 // 接下来,有些优惠顾客越来越重要,让我们称为vip顾客,然后我们要给20%的折扣,我们这样来使用柯里化了的discount函数: const twentyPercentDiscount = discount(0.2) // 我们为vip顾客使用0.2调用柯里化discount函数来配置了一个新的函数。这个twentyPercentDiscount函数会被用来计算vip顾客的折扣: twentyPercentDiscount(500) // $100 twentyPercentDiscount(3000) // $600 twentyPercentDiscount(80000) // $16000避免频繁调用具有相同参数的函数
比如我们有个用来计算体积的函数function volume (l, w, h) { return l * w * h } // 碰巧你仓库里的所有物品都是100m高。你会看到你不停地用h=100来调用这个函数: volume(200, 30, 100) // 2003000 volume(32, 45, 100) // 144000 volume(2322, 232, 100) // 53870400 // 为了解决这个问题,你把volume函数柯里化(像我们之前做过的): function volume (h) { return (w) => { return (l) => { return l * w * h } } } // 我们能给同类物品定义一个特殊函数: const hCylinderHeight = volume(100) hCylinderHeight(200)(30) // 600000 hCylinderHeight(2322)(232) // 53870400
-
- 基于express
-
应用场景
- 中大型企业框架
- ts支持,减少团队代码后期维护成本
- 更现代的开发模式
- 丰富的插件生态,提高开发效率
- 中大型企业框架
-
自定义注解
- 通过这个包实现reflect-metadata
-
-
V8虚拟机
-
什么是V8虚拟机?说说你对虚拟机的理解
- v8引擎是谷歌浏览器用的虚拟机。用于解释和执行javascript代码
- 说到底,JavaScript引擎就是用来执行JavaScript代码用的,为其提供了一个运行时环境,提供解释/编译、自动内存管理(GC)、对象模型、核心库等功能。
-
为什么v8引擎的性能强劲
- 相比较其他的javascript引擎,v8的性能更高
- 热点代码缓存
- 增量式的垃圾回收机制
- 隐藏类,对相同属性的对象通过隐藏类共享,后续访问只需要根据设定的对象偏移量操作即可。如果位置发生变化,则重新生成隐藏类
- 对隐藏类做缓存,因为获取隐藏类的地址依然有提升空间,所以就对隐藏类进行缓存,查找的时候先判断是否是相同的隐藏类,是的话直接使用该缓存结果
- 新版本的v8引入了Sparkplug引擎,提高非热点代码的执行效率
- 相比较其他的javascript引擎,v8的性能更高
-
垃圾回收机制
- 64系统为1.4g
- 32系统0.7g(因为32位系统内存最大只支持4g)
- 也可以通过启动参数来调整
- 32和64区别,内存大小不同,兼容性不同
- 新生代:存活周期短
- 老年代:存货周期长
- v8默认采用的是分代式垃圾回收机制
- V8垃圾回收机制
- 其他垃圾回收机制
- 标记清除
- 标记清楚在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象。这样设计是因为存活的在对象占用比例小,所以才会更高效
- 优点
- 比较通用和简单的算法
- 缺点
- 内存不连续
- 复制清除
- 将堆内存一分为二,from和to这两个空间,分配对象的时候,会先检查from空间是否还有存活对象,有的话就复制到to空间中,那些非存活对象会被释放。完成复制后,to和from的空间再进行互换,下次分配的时候继续执行刚才的步骤。当一个对象检查多次依然存活,那么它就会晋升到老年代中。判断内存地址来区分是否被检查过
- 优点
- 解决内存碎片问题
- 回收效率高
- 缺点
- 将内存缩小为原来的一半,代价高
- 随着存活对象的比例提升,复制的成本会逐渐提高
- 标记整理
- 解决内存碎片化和复制清除内存利用率低的问题
- 让所有存活的对象移动到一段,然后直接清理掉另一端的内存。这样就避免了内存碎片和内存利用率低的问题
- 当存活对象过多时,v8采用增量式迁移,每次移动一小部分进行处理,提高处理效率
- 分代式垃圾回收
- V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象
- 新生代使用复制清除回收算法
- 老年代使用标记整理算法(因为标记清除会留下不连续的内存碎片),并且v8对老年代的回收做了优化,使用增量标记提高了回收效率
- 标记清除
-
内存结构
-
为什么需要堆栈区
- 程序执行过程中,需要记录上下文,那么就要把数据记录到内存中合适的地方,并做好分配和初始化等工作。
-
堆区
- 堆区用来存储对象,由栈区的对象引用地址来进行调用
- 这样设计的使对象实体的 运用 更加的灵活、隔离、模块化
- 灵活:相当于业务数据存放到一个空间足够的池子,我想实现怎样的逻辑,需要怎么的业务数据,通过引用的方式直接获取想要的业务数据。
- 隔离:业务数据和业务逻辑存放在不同的空间,互不干扰。
- 模块化:通过业务数据和业务逻辑的组合,形成具有特定功能的模块。
- 这样设计的使对象实体的 运用 更加的灵活、隔离、模块化
- 对象内存的管理由垃圾回收机制来处理
- 堆区用来存储对象,由栈区的对象引用地址来进行调用
-
堆栈区(栈区)
- 栈区用来记录程序的执行顺序,所以只存储了基本变量类型和对象的引用地址
- 函数调用栈,先进后出
- 原因
- 要是在生活中我们也是按照栈的规则来排顺序,这个世界岂不是乱了套了,试想你去银行排队取钱,明明你是第一个去,却等到晚上晚上银行人员快下班了你才最后处理完业务,恐怕你早就跟人干起来了
- 举个例子吧:我创建一个函数A,在函数A中调用了另一个函数B!那么堆栈中应该是先把A的压栈,再把B压栈!而只有当B这个函数执行完了才会继续执行A后面的代码,所以必须先把B弹栈!这就是后进先出!不然的话程序岂不是乱套了!
- 原因
- 主要作用
- 保存函数的局部变量
- 向被调用函数传递参数
- 返回函数的返回值
- 保存函数的返回地址。返回地址是指从被调用函数返回后调用者应该继续执行的指令地址
- 工作流程
- 每个函数在执行过程中都需要使用一块栈内存用来保存上述这些值,我们称这块栈内存为某函数的栈帧(stack frame)。当发生函数调用时,因为调用者还没有执行完,其栈内存中保存的数据还有用,所以被调用函数不能覆盖调用者的栈帧,只能把被调用函数的栈帧“push”到栈上,等被调函数执行完成后再把其栈帧从栈上“pop”出去,这样,栈的大小就会随函数调用层级的增加而生长,随函数的返回而缩小
-
栈区和堆区的区别示例
-
以图书馆作为例子,图书馆就是系统 全部 的内存空间,里面的任何东西都是基于图书馆来分配空间。
每一本书就是一个 对象实体,他们存放在书架上,书架就是 堆。假设图书馆有各种各样的书架,可以满足所有大小的书本,即使书的大小各异,管理员只需要找到合适的位置存放。
为了方便存取书本,图书馆管理员会为每一本书设计一个编号,并记录在一个表格上,编号就是对象实体的 内存地址。
那什么是 对象引用 呢,答案就是读者的每一条借书记录,每一次的借书行为可以理解为对书本的一次引用。借书的记录都会登记在一个表格上,这个表格就是 栈。借书记录仅仅是一段文字,所需要的空间很小,而且大小基本固定,通常情况下用一个本子、一个电子表格、一个数据库,做一个表格就可以满足需求。
书本、编号、借书记录三者的结合,相辅相成,让整个图书馆的对图书的管理更加的灵活、方便和规范。
其实,代码世界中很多的设计原理都是源于我们的生活,又高于生活。设计模式就在我们身边,无处不在,善于观察生活中的事物,从生活中领悟设计模式吧
-
-
-
-
都用过哪些NodeJs模块
- 内置模块
- cluster
- 操作多进程
- process
- 处理环境变量,监听全局未捕获异常,控制进程退出,获取机器负载信息等
- http
- 给其他服务发起http请求
- fs
- 操作文件的增删改查
- buffer
- buffer是一个二进制数据流,操作文件,数据流转换,比如base64编码解码等
- stream
- 流,处理大文件,避免大文件占用内存过高的问题
- cluster
- 第三方模块
- lodash
- 判断数值是否为空 isEmpty
- 对空字符串 null undefind 0 空数组的判断都很好用
- 数组去重 uniq
- 用js的话要么自己抽象一个方法,要么用set,lodash自己有封装好的
- 对数字的高级操作,交集(intersection),补集(xor),过滤(difference),分组(group)等
- 等等等
- 判断数值是否为空 isEmpty
- bluebird/async 异步流程控制
- 异步串行
- 异步并行
- 同时串并
- 等等等
- moment/dayjs
- 日期处理
- 时间戳转日期
- 日期转时间戳
- 获取某几个月的时间
- 计算时间差
- 等等等
- 日期处理
- node-xlsx
- xlsx文件的导入导出解析
- ioredis
- 连接redis驱动,操作redis
- mongoose
- 连接mongodb驱动,操作Mongodb
- log4js
- 服务日志记录和输出
- qiniu
- 对接第三方云存储平台,处理文件的增删改查
- lodash
- 内置模块
-
看过哪些模块的源码
-
lodash
-
出于好奇,看了isEmpty源码
-
先判断是否为空
-
再判断是否像数组
- 判断是否拥有length属性
- 判断是否是函数
- 用typeof判断 object和function 此时都会被判定为对象
-
接下在像数组的情况下继续进行或的判断
- 判断是否是数组,使用Object.prototype.toString.call()判断,如果是’[object Array]'这个字符串,就是数组
- 不是数组,再判断是否是字符串
- 用typeof判断是否是字符串
- 满足任意一项,则返回length长度,0对于js是false,大于0则证明是有值的
-
如果不是数组也不是字符串,则执行nativeKeys方法
- 先用Object强制转换,对于undefind,null等无效类型,默认返回空数组,其他的则转换为对应的string,number,json等类型
- 然后再用Object.keys获取变量的key列表,返回length
- 0是false,大于0的是true
-
Object.prototype.toString.call()原理
- JavaScript类型检查
-
和instanceof,type of区别
-
typeof只能判断基本类型,引用类型都是object
function instance_of(L, R) {//L 表示左表达式,R 表示右表达式 var O = R.prototype; // 取 R 的显示原型 L = L.__proto__; // 取 L 的隐式原型 while (true) { if (L === null) return false; if (O === L) // 当 O 显式原型 严格等于 L隐式原型 时,返回true return true; L = L.__proto__; } } -
instanceof判断构造函数的 prototype 属性是否出现在某个实例对象的原型链上
-
instanceof 的工作原理就是将 s 每一层的 proto 与 F.prototype 做比较
找到相同返回 true
至最后一层仍没有找到返回 false -
比如判断 一个字段的类型是否是数组
- 会先拿这个数组的原型链__proto__原型链对比数组的原型prototype
- 如果一致则返回true,否则继续对比
- 下一层的原型链就是Object的了,如果还是不一样就继续对比
- 一直到为null,则返回false
-
但instanceof有个缺点,不能用来判断是否为Object,因为最终都指向了Object。
-
-
-
-
-
koa-bodyparser
- 平台服务总是报很多json类的转换异常,看不到具体的日志,因为没有执行到中间件就被捕获了。
- 后来发现只要post请求的body参数不是json类型,该插件就会抛错,然后被全局异常捕获。然后单独把这个包拿出来,只做一个打印,然后由拦截器中间件来处理这个错误
-
-
什么是原型和原型链
- 原型
- 每个对象都有prototype属性
- prototype包含了对象的属性和方法
- 原型链
- 对象的追踪过程,函数->对象->null
- 原型
-
什么是闭包
-
函数内部保存的变量不随这个函数调用结束而被销毁就是闭包
-
闭包的应用场景
- 操作函数内部变量
- 将变量维护在内存中不释放
- 常见的例子就是递归计算和函数式编程
-
闭包的例子
const fun = ()=>{ let num = 0; return (v)=>{ return num += v; }; } const data5 = fun(); //初始化函数fun并得到函数的匿名函数返回值(这里只初始化了一次) console.log(data5(1)); //1 给匿名函数传参并得到累加的结果 console.log(data5(1)); //2 由于fun函数未重新初始化,且此时num的值为1,所以累加得2 console.log(data5(1)); //3 与上面雷同
-
-
什么是深拷贝和浅拷贝
- 比如基本类型是深拷贝,拷贝的是值
- 对象是浅拷贝,拷贝的是引用地址
- 需要重新分配内存地址才能解决浅拷贝问题
-
常用的方法有
- JSON.parse(JSON.stringify(obj))
- lodash的deepLone方法
- 自定义克隆方法
const deepClone = (obj) => { if (obj === null || typeof obj !== 'object') { return obj; } const clonedObj = Array.isArray(obj) ? [] : {}; for (let key in obj) { if (obj.hasOwnProperty(key)) { clonedObj[key] = deepClone(obj[key]); } } return clonedObj; };
-
-
JavaScript作用域
-
分为全局和局部作用域
-
每次代码执行前会先进行"预编译"
-
比如有下面一段代码
var a = 1; function foo(){ var b = 2; function bar(){ var c = 3; console.log(c + b + a); } bar(); } foo();-
在执行之前会先预编译成以下的预编译代码
- 生成全局作用域 global object 简称go
GO{ a: undefined, foo: function foo{...} }- 执行到foo的时候 生成foo的函数局部作用域 active object 简称ao
AO1{ b: undefined, bar: function bar(){...} }- 执行foo内部函数bar的时候,生成bar的函数局部作用域
AO2{ c: undefined }-
然后先执行ao2,给变量c复制,在当前局部作用域可以找到,然后执行b,发现当前局部作用域没有,于是就去外层的作用域查找,找到了,执行。然后执行a,发现发现当前局部作用域没有,于是就去外层的作用域查找,发现也没有,一直找到全局作用域,找到了执行,没找到就当作undefind处理
- 其中 这个查找的过程就是作用域链,有点类似js的原型链
-
-
-
JavaScript继承,更详细的请查看JS继承原理
-
es5
-
原型继承
-
使用prototype重新赋值,然后再扩展新对象的prototype
-
示例
// 继承 B.prototype=new A() // 扩展 B.prototype.splice = ()=>{};
-
-
call和apply,更详细的请查看这篇文章
-
用来改变this的指向,将一个对象作为另一个对象的实现
-
示例
function myfunc1(){ this.name = 'Lee'; this.myTxt = function(txt) { console.log( 'i am',txt ); } } function myfunc2(){ myfunc1.call(this); } var myfunc3 = new myfunc2(); myfunc3.myTxt('Geing'); // i am Geing console.log (myfunc3.name); // Lee -
其中myfun2中没有任何实现,只是将myfun1替换了myfun2的实现
-
区别
- call的第二个参数可以是任意类型,而apply必须是数组
-
-
-
es6
-
使用class类,通过extends关键字实现继承
-
类只是一个语法糖,背后其实还是构造函数来实现的
-
原理
-
通过_inherits函数实现
-
先判断当前对象是否是函数,如果不是函数则报错类型异常
-
然后就是继承父类的原型和原型链,下面是示例
// 继承原型链 B.prototype._proto_ = A.prototype
-
-
-
super关键字用来做什么,更详细的请查看这篇文章
- 用于访问和调用对象父类上的函数
-
super为什么在构造函数中必须写在前面,否则就不能用this?
-
比如下面的代码
class Person { constructor(name) { this.name = name; } } class PolitePerson extends Person { constructor(name) { this.greetColleagues(); //这行代码是无效的,后面告诉你为什么 super(name); } greetColleagues() { alert('Good morning folks!'); } }- 如果允许在调用super之前使用this的话。一段时间后,我们可能会修改greetColleagues,并在提示消息中添加Person的name:
greetColleagues() { alert('Good morning folks!'); alert('My name is ' + this.name + ', nice to meet you!'); }-
但是我们忘记了super()在设置this.name之前先调用了this.greetColleagues()。 所以此时this.name还没有定义,就会出现出现undefind
-
所以javascript强制在this之前调用super,先完成父类构造函数的构建,再执行子类
-
super的实现也是使用call方法
-
-
-
-
bind,call和apply应用场景和区别,更详细的请查看这篇文章
- 都可以用来改变this指向
- call的第二个参数是任意类型
- apply的第二个参数是数组
- 应用场景
- call和apply多用来实现继承
- bind多用来改变this指向
-
2个等于号和3个等于号区别,更详细的请查看这篇文章
- 2个会进行类型转换 比如判断1和’1’ 他们是相等的
- 3个不会进行类型转换,所有是严格判断
-
线上cpu高的问题
- 定时器
- 有一天突然线上服务的cpu不间断的飙升到三四百
- 于是排查代码,发现在早期的代码中,有一处每30s批量查询数据库(根据指定客户数,并发在20-30之间),并对返回值进行计算和处理(批量计算客户的号码区间,筛选和重组,比如03766848660-03766848889)
- 因为该业务对性能要求不高,所以让同事把代码改为分批执行,每次执行十个,就解决了此性能问题
- redis
- 有一天上午十点多收到运维通知,redis告警cpu占用率高,于是就排查最近代码,发现其他部门有同事,在关键业务处使用keys*来查询所有
- 于是立马所属部门同事,给出建议方案进行更改
- 有一些大key,存储了一个账户的所有座席配置(存储的数据量过大,高大几m甚至几十m),频繁获取也会导致redis cpu飙升。于是在当天晚上就进行了简化,只存储业务需要的字段,对不需要的字段进行剔除
- 有一天上午十点多收到运维通知,redis告警cpu占用率高,于是就排查最近代码,发现其他部门有同事,在关键业务处使用keys*来查询所有
- 定时器
-
线上内存高的问题
- 内存泄漏
- 有一天下午,客户报问题,服务突然不可用了
- 发现node接口服务自动重启了
- 查看最近代码发现是因为有人用了global对象,全局缓存。用来给数据库降低压力的,但是有一个用户监控类的缓存没有清除,导致内存持续升高
- 后来改成放在redis中后解决
- 有一天下午,客户报问题,服务突然不可用了
- 流出宽带高
- 系统中提供了对外开放接口,但早期部分接口没有做分页,允许查询所有,导致某一天数据库的外网出流量特别高,数据库频繁告警。所以就立刻做了热更新,做了默认分页20,解决了此问题
- 数据库内存暴涨,导致某节点重启。同事在对线上服务做脚本处理时(分析线上用户数据脚本),因为走的是内部鉴权,没有限制。导致对查询没有做好并发控制,瞬间的并发(同时发起100个查询请求,持续几分钟),拖垮了数据库节点。导致了故障。后续解决方案是统一了鉴权,不再放宽内部请求。
- 内存泄漏
-
排查内存泄漏的方案是什么
- 看最近代码是否有以下问题
- 全局对象
- 闭包
- 定时器用过后没有清除
- 或者使用easy-monitor可视化工具查看某段时间的内存使用情况
- 看最近代码是否有以下问题
-
数组和链表数据结构和区别,更详细的请查看这篇文章
- 数组 有顺序,大小固定,查询效率高
- 链表 无顺序,没有固定大小,插入删除效率高
-
什么是缓冲区
- nodejs buffer是一个二进制数据流,在操作文件的时候会用到。处理数据流
-
Nodejs最近大版本都更新了什么,更详细的请查看这篇文章
-
官网维护的更新日志
-
https://github.com/nodejs/node/tree/main/doc/changelogs
-
node 10
- 支持http2
- 增加了n-api 支持
- 修复了一些漏洞
-
node 12
- 提供了打印堆快照的工具
- http换成lhttp
- Worker Threads 工作线程
-
node 14
- 支持es module,使用import导入模块
- 升级v8版本
- 可选链,空值合并操作符
- 异步本地存储。async 调用栈追踪,由此的来了trace,链路追踪id的插件
-
node 16
- 更新v8版本
- 返回promise的定时器
- Node.js针对不同的平台提供预构建的二进制文件,给苹果芯片提供了新的二进制版本
- 其他相关漏洞修复
-
node 18
- 内置fetch,基于undiciundici
- 内置test单元测试模块
- 更新v8版本
- 其他修复等
-
-
js如何判断数据类型,更详细的请查看这篇文章
-
typeof,instanceof,Object.prototype.toString.call
-
Object.prototype.toString.call()原理
- 和instanceof相同,但使用的是就近原型链,而不会去向上寻找(比如找到了顶级Object)。所以传入一个数组时,就获取的是数组的原型链__proto__是Array
-
和instanceof,type of区别
-
typeof只能判断基本类型,引用类型都是object
-
instanceof判断构造函数的 prototype 属性是否出现在某个实例对象的原型链上
function instance_of(L, R) {//L 表示左表达式,R 表示右表达式 var O = R.prototype; // 取 R 的显示原型 L = L.__proto__; // 取 L 的隐式原型 while (true) { if (L === null) return false; if (O === L) // 当 O 显式原型 严格等于 L隐式原型 时,返回true return true; L = L.__proto__; } }-
instanceof 的工作原理就是将 s 每一层的 proto 与 F.prototype 做比较
找到相同返回 true
至最后一层仍没有找到返回 false -
比如判断 一个字段的类型是否是数组
- 会先拿这个数组的原型链__proto__原型链对比数组的原型prototype
- 如果一致则返回true,否则继续对比
- 下一层的原型链就是Object的了,如果还是不一样就继续对比
- 一直到为null,则返回false
-
但instanceof有个缺点,不能用来判断是否为Object,因为最终都指向了Object。
-
-
-
-
node如何接受客户端上传的文件
- 使用node的multer或者busboy等工具包
- 接受前端的form表单文件
- 然后使用node的stream流写入文件
-
箭头函数,更详细的请查看这篇文章
- 缩短函数代码
- 解决this指向问题
-
单元测试
- mocha框架
- 提高项目质量
- 减少测试成本
- 精准定位bug
TypeScript
-
特点
- 能够使用最新的esma规范
- js的超集
- 静态类型化编程
- 提供了注解,更现代化的开发模式
- 编译期间的类型检查
-
应用场景
- 中大型企业的最佳选择
- 使用最新的ECMA规范
- 更健壮的企业级服务
-
缺点
- 增加了类型,提高了开发工作量
- 有一些库目前还不支持ts,比如缺少.d.ts文件
- 对团队素质要求高
-
目前用的什么版本,有什么特性
-
目前用的4.6版本
-
特性
-
super关键字允许写在this后面,以前只能写在前面
-
枚举类型支持解构
type Action = | { kind: "NumberContents", payload: number } | { kind: "StringContents", payload: string }; // 以前结构会报错 const { kind, payload } = action; if (kind === "NumberContents") { let num = payload * 2 // ... } -
更智能的jsdoc,通过注释也可以看到类型
-
其他的问题修复等
-
-
-
-
经常用哪些类型接口
- type 简单类型 字符串数字等
- interface 复杂类型 对象等
- Record 根据输入的索引生成新类型
- Pick 取旧类型中的部分索引类型为新类型
- Omit 提出原类型中的部分属性,生成新的类型
- Exclude 根据索引移除类型中的key得到新的索引类型
- ReturnType 获取函数返回值类型
-
自定义装饰器和原理
数据库
Mongodb
-
关系型和非关系型区别
- sql语句不同,mongo的是json类型,而mysql是一个字符串语句,中间用空格间隔
- 关系型支持连表,非关系型不支持
- 非关系型数据结构灵活,比如mongo,都是key,value类型
- 非关系型比关系型更灵活,比如mongo可以随时的动态增删字段
-
Mongodb应用场景
- 操作简单,开发成本低。因为数据结构都是json,尤其和javascript很契合
- 扩展性强。nosql型数据库不要求强一致的字段结构,可以随便的增删字段
- 高性能和吞吐量。传统型数据库都有事务,导致速度没有mongo快
- mongodb分片集群。扩展方便,提高集群性能和高可用性
-
Mongo优缺点
- 优点
- 弱一致性,不要求强一致数据结构
- 高扩展性,任意扩展字段和数据库集群节点
- mongodb是商业化的,发展稳定
- JSON存储结构,开发高效
- 更现代化的可视化管理工具,比如MongodbCompase,NoSQLBooster,ClusterControl等
- 缺点
- 表关联查询支持弱,在部分复杂业务场景下,开发效率低
- 旧版本不支持事务(新版本3.6支持)
- 因为弱类型,可以更改数据类型,后期维护成本高
- 占用空间大,因为都是bson结构的key,value形式
- 优点
-
Mongo集群是否了解
- 什么是副本集
- 概念
- mongodb的高可用方案
- 应用场景
- 数据备份
- 数据恢复
- 读写分离
- 副本集最小可用方案
- 一主两从
- 都有哪些独写策略
- primary 默认 所有的读操作都从当前副本集主节点
- primaryPreferred 从主节点读取数据,但是如果主节点不可用了,会从从节点读取
- secondary 所有读操作都从副本集的从节点读取
- secondaryPreferred 从从节点进行读操作,但是如果从节点都不可用了,从主节点读取
- nearest 从副本集中延迟最低的成员读取,不考虑成员的类型
- 概念
- 副本集配置
- 最小配置
- 一主两从
- 一个主节点
- 一个复制集有且仅有一台服务器处于Primary状态,只有主节点才对外提供读写服务。如果主节点挂掉,复制集将投票选出一个备节点成为新的主节点
- 两个备用节点
- 备用节点,复制集允许有多台Secondary,每个备用节点的数据与主节点的数据是完全同步的。Recovering 恢复中,当复制集中某台服务器挂掉或者掉线后数据无法同步,重新恢复服务后从其他成员复制数据,这时就处于恢复过程,数据同步后,该节点又回到备用状态
- 一个仲裁节点
- 该类节点可以不用单独存在,如果配置为仲裁节点,就主要负责在复本集中监控其他节点状态,投票选出主节点。该节点将不会用于存放数据。如果没有仲裁节点,那么投票工作将由所有节点共同进行
- 副本集健康检测
- 每个成员都需要知道其他成员的状态:哪个是主节点?哪个可以作为同步源?哪个挂掉了?为了维护集合的最新视图,每个成员每隔两秒钟就会向其他成员发送个心跳请求(heartbeat request)。心跳请求的信息量非常小,用于检查每个成员的状态
- 数据同步和恢复
- 每个节点都有自己的oplog日志,该日志记录了每一个写操作,备份节点通过该日志同步数据,后续也通过该日志恢复数据
- 副本集搭建
- 更详细的请查看这篇文章
- 副本集主节点选举过程
- 触发选举的时机
- 副本集被加入了新节点
- 重启副本集
- 使用rs.stepdown命令(将主节点降低)或使用rs.reconfig命令(重新配置现有副本集)
- 心跳检测超时,比如主节点或副节点崩溃
- 选举过程
- 选举规则是根据票数来决定,票数最高,且获得了“大多数”成员的投票支持的节点获胜。“大多数”:假设复制集内投票成员数量为N,则大多数为 N/2 + 1。例如:3个投票成员,则大多数的值是2。当复制集内存活成员数量不足大多数时,整个复制集将无法选举出Primary,复制集将无法提供写服务,处于只读状态
- 若票数相同,且都获得了“大多数”成员的投票支持的,节点状态是健康的,节点优先级高且数据新的节点获胜。数据的新旧是通过操作日志oplog来对比的,优先级可以通过人工配置
- 仲裁节点
- 提升集群可用性
- 假设现在有三个节点,其中两个节点崩溃,那么按照N/2+1的选举规则,3/2+1>1,但此时只有一个节点存活,所以无法进行投票,就导致集群不可用
- 有了仲裁节点后,仲裁节点不存储数据,只用来选举。那么你当前的节点数就是2,在两个节点崩溃的情况下,因为有了仲裁节点的加入,使得集群可以正常投票选举,继续提供服务
- 提升集群可用性
- 为什么集群节点通常都要求是奇数而不是偶数
- 主要防止脑裂的情况
- 通常在集群间通信异常的时候,可能会分裂成两个小集群
- 奇数的情况下,比如5台机器,由于脑裂分裂成了以下两组
- A:1节点 B:4节点
- A:2节点 B:3节点
- …
- 因为(总节点数/2)+1的模式,那么总会有一个小集群在选举后继续提供服务
- 偶数的情况下,比如4台机器,由于脑裂分裂成了以下两组
- A:1节点 B:3节点
- A:2节点 B:2节点
- …
- 因为(总节点数/2)+1的模式,其中第二种情况因为不满足选举模式,从而导致无法继续提供服务
- 通常在集群间通信异常的时候,可能会分裂成两个小集群
- 主要防止脑裂的情况
- 触发选举的时机
- 什么是分片
- 概念
- 把一张表中的数据分割到不同的服务器上进行保存。一般用在特别大量的数据库集群中,比如一张表的数据几百个g这种,通过分片到多台服务器上。比如传统的副本集,所有的数据都在一个服务器上,分片通过分布式存储来提高查询性能。
- 每一个分片集群都有一个主分片,其中包含该数据库的所有未分片集合,存储了所有未分片集合的数据
- 在初始化数据库时,会选择集群中数据量最少的分片作为主分片
- 组成
- mongos路由,用于将请求转发给不同的分片,将多个分片的结果进行整合
- config-server,保存集群的元数据,比如分片的路由规则,服务器配置等等
- 分片,存储数据库数据,一个分片默认是64m。分片由分片键和分片算法组成
- 分片键
- 有了分片,但还需要解决数据块的问题,如果所有的数据库都存储在一个分片,那么性能会打折扣。所以出现了分片键,分片键能够将数据块分为多个小块分别存储在不同的分片中来提升性能
- 范围片键
- 可以高效的读取连续范围内的目标文档。如果你使用范围查询,则可以比较快速的拿到所有的结果值。因为数据所在的数据chunk比较少
- hash片键
- 哈希分片在分片集群中提供了更均匀的数据分布,集合中那些具有近似值的文档,可能会被分到不同的块上
- 范围片键
- 有了分片,但还需要解决数据块的问题,如果所有的数据库都存储在一个分片,那么性能会打折扣。所以出现了分片键,分片键能够将数据块分为多个小块分别存储在不同的分片中来提升性能
- 每一个分片集群有一个主分片
- 每一个分片默认三个副本
- 分片键
- 概念
- 分片和副本集的区别
- 副本集
- 硬件和维护成本低
- 发生故障时,备份直接可以直接恢复服务
- 分片
- 维护成本高,因为将数据分部到了很多台机器上
- 对数据流大的应用来说能显著提高查询性能
- 副本集
- 如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样
- 如果一个分片停止了,除非查询设置了“Partial”选项,否则查询会返回一个错误。如果一个分片响应很慢,MongoDB会等待它的响应
- 数据在什么时候才会扩展到多个分片(shard)里
- MongoDB 分片是基于区域(range)的。所以一个集合(collection)中的所有的对象都被存放到一个块(chunk)中。只有当存在多余一个块的时候,才会有多个分片获取数据的选项。现在,每个默认块的大小是 64Mb,所以你需要至少 64 Mb 空间才可以实施一个迁移。
- 其他
- 副本集默认每2秒检测心跳,感知其他节点是否宕机,角色发生转换等
- 副本集依赖oplog,mongo的写操作日志来完成数据的同步的
- 副本集的主从同步机制核心是,主节点在完成写操作后同步到oplog日志中,然后从节点主动拉取oplog日志中的日志
- 什么是副本集
-
都有哪些数据类型
- 和mysql类似,底层存储的时候会有以下类型
- string
- array
- boolean
- date
- double
- int
- object
- 等等
- 和mysql类似,底层存储的时候会有以下类型
-
ObjectId如何组成
- 一个24位数的字符串
- 前八位是时间戳
- 后六位是主机标识
- 后四位是进程id
- 后六位是自增的随机数
- 一个24位数的字符串
-
什么是索引
- 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。就好比书的目录,有了目录才能更精确的查找,否则只能进行全表搜索
-
常用的索引类型
- 主键索引
- 主键_id,数据库默认插入的索引
- 唯一索引
- 针对某一个字段的索引
- 复合索引
- 多字段联合的索引
- 主键索引
-
索引的优缺点
- 优点
- 提升数据查询性能
- 缺点
- 占用额外的空间
- 维护索引成本
- 优点
-
mongodb索引数据结构和原理
- mongodb使用的是基于二叉树的B树
- 因为在大多数场景中,都是读多写少。所以相比较传统的B+树(只有叶节点存放数据,其余节点用来索引),mongodb的设计是为了更高的查询性能而来。B树的每个索引节点都会有Data域。所有对于B树来说,只要找到对应的索引节点,就可以访问,所以对于非范围类查询性能很高。
- 叶子节点:没有孩子节点的节点叫作叶子节点
- 非叶子节点:跟叶子节点相反,有孩子节点的节点
- mongodb使用的是基于二叉树的B树
-
Mongo查询计划
- db.find().explain
- 都看哪些指标?
- stage 直接看出是否使用索引
- FETCH 根据索引位置查找
- IXSCAN 索引扫描
- COLLSCAN 全表扫描
- nReturned 返回了多少
- totalKeysExamined 索引扫描了多少
- totalDocsExamined 文档扫描了多少
- executionTimeMillis 整体执行时长
- stage 直接看出是否使用索引
- 一般看着这几个指标就能看出是否用到了索引,或者索引是否设计合理
-
数据库语句执行过程
- 首选客户端向服务器发送一个查询请求
- 服务器先检查是否有缓存,有缓存则返回,没有缓存则执行下一个阶段
- 缓存的重新发生在数据库表数据大小,表结构等发生变更时
- 下一个阶段
- sql解析
- 检查sql是否合法,如果find查询第一个参数指定的操作符不对,比如$in写成了in,则mongo解析会抛异常
- 预处理
- 生成该sql的最优查询计划
- 执行胜出的查询计划并齿形
- 将结果返回给客户端
- sql解析
-
数据库cpu高的问题
- 瞬间有很多大量的慢查询,一直没有处理完,导致cpu飙升
- 是因为内部产品交互通过http,但是没有控制频率,导致大量请求瞬间打到服务和数据库
- 当时解决的方案是
- 通过日志分析平台,统计最近半小时的请求和频次
- 查看代码用到该查询条件的代码
- 找到了一个频次异常的接口
- 找到了对应的代码
- 锁定到是内部运营平台调用释放客服号码的接口,这个接口是释放一个租户内的所有号码,少则几十个,多则几百上千。运营平台来调用的时候没有控制频率,导致瞬间几千个请求打过来。数据库的cpu就飙升了
- 然后联系到使用运营平台的人,暂停这个操作(因为系统有记录操作人)。暂停后,数据库负载恢复,后续我们的接口增加频次限制,运营平台也增加调用接口的频次控制
- 内部报表统计接口查询报表,因为报表的数据流大,查询时间有时候会在几秒,统计的时候没有注意频次,cpu也会飙升
- 瞬间有很多大量的慢查询,一直没有处理完,导致cpu飙升
-
数据库内存高的问题
- 某一天数据库的内存频繁告警超过80%,于是先查看数据库慢查询(怀疑是查询的结果集过大),然后锁定到了几张表。
- 查找几个涉及到这个表查询的业务,导出,对外接口
- 然后就分析导出和对外接口的调用频次
- 发现有个请求,指定的查询结果数是1000,平均每秒1-2次请求
- 然后我们内部有一个限流器
- 根据ip限制它一分钟只能调用20次
- 查询结果,一次最多100个
- 然后数据库的内存占用量就恢复了
-
数据库流量高的问题
- 和上面的问题一样
-
Mongo底层存储结构
- mongo使用的是WiredTiger存储引擎,该引擎使用B树作为数据结构
- B树是一种自平衡的搜索,和二叉树不同的是,二叉树最多两个子节点,而B树是每个节点的关键字=节点数-1
- 每个树节点都存有数据,所以只要找到索引就可以进行访问,更适合查询
-
性能优化
在上面"NodeJs如何提升性能和代码质量"中有提到 -
慢查询分析
- db.system.profile.find({“millis”:{$gte:8000}}).limit(10).pretty();比如查询十条时间大于8000毫秒的sql语句并对结果进行美化
- 该慢查询结果将返回查询消耗的时间,查询指定,查询条件等
- 然后我们可以再使用explain对该查询条件进行分析,在上面的"Mongo查询计划"已提到查询计划的关键指标
- 在知道具体的慢查询库,表和查询条件后,我们可以查看服务代码来进行排查和优化
- db.system.profile.find({“millis”:{$gte:8000}}).limit(10).pretty();比如查询十条时间大于8000毫秒的sql语句并对结果进行美化
Redis
-
和其他传统数据库区别
- redis的sql语句和传统的不同
- redis基于内存内存,省去了磁盘操作,所以性能高
- redis多用于热点数据查询,不像传统数据库用来存储大量数据
-
Redis应用场景都有哪些
- 热点数据缓存
- 缓存数据共享
- 分布式锁 nx
- 计数器 incr
- 单点登录
-
数据结构
- string
- 字符串是所有编程语言中最常见和最常用的数据类型,而且也是redis最基本的数据类型之一,而且redis中所有key的类型都是字符串,它是一个由字节组成的序列,在Rediss中是二进制安全的。它是标准的key-value,通常用于存储字符串、整数和浮点。Value可容纳高达512MB的数据
- list
- 列表是一个双向可读可写的管道,其头部是左侧,尾部是右侧,一个列表可以最多包含2^32-1个元素,即4294967295个元素
- set
- set是string类型的无序集合,集合中的成员是唯一的,这就意味着集合中不能出现重复的数据,可以在两个不同的集合中对数据进行比对并取值
- zset
- redis有序集合和集合一样,也是string类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个double双精度浮点数类型的分数,redis正是通过该分数来为集合中的成员进行从小到大的排序,有序集合成员是唯一的,但分数却可以重复,集合是通过hash表实现的,所以添加,删除,查找的复杂度是O(1),集合中最大的成员数是2^32-1,每个集合可以存储40多亿成员
- hash
- hash是一个string类型的feild和value的映射表,hash特别适合用于存储对象,redis中每个hash可以存储40多亿键值对
- string
-
常用操作语句
- string
- set/get 存储和获取key
- mset/mget 批量存储和获取多个key
- append 对某个key的值做追加操作
- incr 对数值做递增操作
- exists 判断某个key是否存在
- expire 设置过期时间
- ttl 查看过期时间
- persist 取消key的过期时间变为永久
- list
- lpush 生成列表并插入数据
- llen 获取列表长度
- set
- sadd 生成无序集合
- smembers 获取无序集合set1的所有数据
- sdiff 差集
- sinter 交集
- sunion 并集
- zset
- zadd 生成有序集合
- zcard 获取集合长度
- hash
- hset 生成hash key
- hdel 删除一个hash key的字段
- hgetall 获取指定hash的所有key,value
- string
-
为什么Redis快
- 基于内存,省去了操作磁盘的时间
- 单线程,减去了多线程的上下文切换和锁的问题
- 多路复用,类似nodejs事件循环,所有的读写都放入事件循环中,内部用多线程来执行
-
常用的数据结构有哪些
- set 简单字符串存储
- exists 是否存在指定key
- del 删除key
- mset 存储多个键值对
- incr 计数器
- expire 过期时间
-
缓存击穿
- 概念
- 高并发流量,访问的这个数据是热点数据,请求的数据在 DB 中存在,但是 Redis 存的那一份已经过期,后端需要从 DB 加载数据并写到 Redis
- 但由于高并发,可能会把数据库击垮,导致服务不可用
- 解决方案
- 热点key不设置过期时间
- 给热点key的过期时间设置一个随机值,避免同一时间过期
- 给一个1-10分钟的过期时间
- 问题场景
- 比如用户信息
- 概念
-
缓存穿透
- 概念
- 意味着有特殊请求在查询一个不存在的数据,即数据不存在 Redis 也不存在于数据库。导致每次请求都会穿透到数据库,缓存成了摆设,对数据库产生很大压力从而影响正常服务
- 解决方案
- 缓存空值:当请求的数据不存在 Redis 也不存在数据库的时候,设置一个缺省值(比如:None)。当后续再次进行查询则直接返回空值或者缺省值
- 问题场景
- 在缓存击穿的基础上,数据库也查不到,也没有一个默认值,导致一直查询
- 概念
-
缓存雪崩
- 概念
- 大量的请求无法在 Redis 缓存系统中处理,请求全部打到数据库,导致数据库压力激增
- 解决方案
- 过期时间添加随机值
- http接口限流
- 服务熔断降级
- 问题场景
- 大量热点数据同时过期,导致大量请求需要查询数据库并写到缓存;
- Redis 故障宕机,缓存系统异常
- 概念
-
过期策略
- 定期策略
- 当Redis运行到设定的时期时会在具有过期设置的key中随机测试一些key,并且把其中过期的key从内存中删除
- 具体来说,Redis 每秒执行 10 次:
- 从具有关联过期的key集中测试 20 个随机key
- 删除所有发现过期的key
- 如果超过 25% 的key已过期,则从步骤 1 重新开始
- 惰性策略
- 当某个客户端试图访问key时,发现该key已超时会把此key从内存中删除
- 定期策略
-
内存淘汰策略
- noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错
- allkeys-lru:在主键空间中,优先移除最近未使用的key
- volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key
- allkeys-random:在主键空间中,随机移除某个key
- volatile-random:在设置了过期时间的键空间中,随机移除某个key
- volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除
- 配置方法
- 编辑redis.conf,更改maxmemory-policy配置
- redis默认是noeviction
-
持久化机制,优缺点
-
RDB
-
概念
- 在指定时间将当前时刻内存中的数据生成一个快照文件(.rdb文件,默认为dump.rdb),并将这个快照文件保存到磁盘上。这样,即使redis宕机了,下次重启时也可以通过读取这个快照文件来恢复数据
-
备份策略
-
save 3600 1 -> 3600秒内有1个key被修改,则触发RDB save 300 100 -> 300秒内有100个key被修改,则触发RDB save 60 10000 -> 60秒内有10000个key被修改,则触发RDB -
重写操作是redis主进程fork一个子进程来处理,避免阻塞主进程
-
-
redis默认是rbd策略
-
-
AOF
-
概念
- AOF是redis提供的另一种数据持久化方式,它会记录客户端对redis服务端的每一次写操作,并将这些写操作以redis协议追加保存到后缀为aof的文件末尾。在redis服务器重启时,会读取并加载aof文件,达到恢复数据的目的。
-
开启aof
- 更改reids.conf中的appendonly配置,0为不开启,1为开启
-
备份策略
- appendfsync always
- 客户端对redis服务器的每次写操作都写入AOF日志文件。这种方式是最安全的方式,但每次写操作都进行一次磁盘IO,非常影响redis的性能,所以一般不使用这种方式。
- appendfsync everysec
- 每秒刷新一次缓冲区中的数据到AOF文件。这种方式是redis默认使用的策略,是考虑数据完整性和性能的这种方案,理论上,这种方式最多只会丢失1秒内的数据
- appendfsync no
- redis服务器不负责将数据写入到AOF文件中,而是直接交给操作系统去判断什么时候写入。这种方式是最快的一种策略,但丢失数据的可能性非常大,因此也是不推荐使用的
- appendfsync always
-
AOF重写
-
背景
- AOF是Redis增量模式的持久化方式,随着redis的持续运行,会不断有新的数据写入AOF文件中,逐渐占用大量磁盘空间,还会降低Redis启动速度。Redis中有rewrite机制来合并AOF历史记录。
- 比如当我们对同一个key做多次写操作时,就会产生大量针对同一个key操作的日志指令,导致AOF文件会变得非常大,恢复数据的时候会变得非常慢
-
触发命令 bgrewriteaof
-
触发策略
- auto-aof-rewrite-percentage 100
- 当文件的大小达到原先文件大小(上次重写后的文件大小,如果没有重写过,那就是redis服务启动时的文件大小)的两倍
- auto-aof-rewrite-min-size 64mb
- 文件重写的最小文件大小,即当AOF文件低于64mb时,不会触发重写
- auto-aof-rewrite-percentage 100
-
重写流程
-
(1)bgrewriteaof触发重写,判断是否存在bgsave或者bgrewriteaof正在执行,存在则等待其执行结束再执行;
(2)主进程fork子进程,防止主进程阻塞无法提供服务;
(3)子进程遍历Redis内存快照中数据写入临时AOF文件,同时会将新的写指令写入aof_buf和aof_rewrite_buf两个重写缓冲区,前者是为了写回旧的AOF文件,后者是为了后续刷新到临时AOF文件中,防止快照内存遍历时新的写入操作丢失;
(4)子进程结束临时AOF文件写入后,通知主进程;
(5)主进程会将上面的aof_rewirte_buf缓冲区中的数据写入到子进程生成的临时AOF文件中;
(6)主进程使用临时AOF文件替换旧AOF文件,完成整个重写过程。
-
-
-
-
RDB优缺点
- 优点
- 体积比aof小,rdb更紧凑
- 恢复的速度快,因为rdn是快照型数据,不用重新读取并写入内存
- 缺点
- 因为有同步间隔,所以宕机时毕竟存在数据丢失
- 虽然是异步备份,但当redis机器负载高的时候,备份的时间也会加长
- 优点
-
AOF优缺点
- 优点
- 数据备份比RDB可靠,因为可以设置每次写入追加
- 自动重写机制,缩小aof文件
- 缺点
- 对redis性能有损耗,毕竟每次写入都同步
- aof文件体积大,恢复时间长
- 优点
-
-
redis高可用
- 主从模式
- 概念
- 和传统数据库一样,一主两从,用来做数据备份,提高数据库读写能力的
- 应用场景
- 读写分离
- 主写,从读,降低主节点压力,提高查询性能
- 数据备份
- 机器宕机,磁盘损坏等,可以用其他节点数据进行备份
- 提高服务高可用性
- 至少一主两从,主节点挂了,从节点顶上
- 读写分离
- 数据同步策略
- 全量同步
- 发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份
- 1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照(快照文件先接收保存到磁盘,最后加载到内存中);
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
- 增量同步
- Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
- Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令
- 全量同步
- 概念
- 哨兵
- 概念
- 用于监控Redis集群中Master状态的工具,是Redis高可用解决方案,哨兵可以监视一个或者多个redis master服务,以及这些master服务的所有从服务。 某个master服务宕机后,会把这个master下的某个从服务升级为master来替代已宕机的master继续工作。
- 即使后来之前的master重启服务,也不会变回master了,而是作为slave从服务
- 应用场景
- 当主服务器宕机时,需要将从服务器手动切换(
slaveof no one)到主从服务器,这需要人工干预。
- 当主服务器宕机时,需要将从服务器手动切换(
- 作用
- 心跳检测
- Sentinel会不断检查主服务器和从属服务器是否正常运行
- 通知
- 当受监控的Redis服务器出现问题时,Sentinel会通过API脚本向管理员或其他应用程序发送通知
- redis发布订阅来完成
- 自动故障转移
- 当主节点无法正常工作时,Sentinel将启动自动故障转移操作。它将与发生故障的主节点处于主从关系的从节点之一升级到新的主节点,并将其他从节点指向新的主节点
- 心跳检测
- 概念
- 哨兵自动选举机制
- 没有哨兵的情况下,主从模式需要人为干预才能够正常的进行选举,并且后续的ip更换操作也很繁琐
- 哨兵每秒会给所有节点发送心跳检测,如果心跳检测超时则认定为死忙
- 为了避免在网络阻塞或者机器负载高的情况下影响单个哨兵的能力,通常会搭建哨兵集群,三个哨兵节点
- 当一个哨兵判断主节点下线后会通知其他哨兵根据自己掌握的节点状况进行投票和选举
- 其投票通过数和mongodb一样,(N/2)+1,比如三个哨兵,那么阈值为2
- 投票通过后又由谁来进行主从的切换?
- 哨兵内部还会再进行主哨兵选举,先发现主节点故障的哨兵拥有优先投票权,每一个哨兵只能投票一次
- 哨兵集群数和数据库集群数类似,都是奇数,为了防止脑裂
- 主从模式
-
redisAOF问题,更详细的请查看这篇文章
AOF重写导致的redis子进程崩溃,服务重启。解决方案是先优化代码中的大key,延迟重写时机,保证服务可用,比如超过上一重写文件的多少倍后再重写。待redis写入量没那么高时,再调整会重写策略,提前重写即可。主要是大key占用了不必要的空间。 -
分布式锁的使用和问题,解决方案
- 应用场景
- 多个定时器任务扫描,如何避免同一个任务重复处理
- setnx
- 存在返回0
- 不存在返回1
- setex
- 解决定时器问题,设置锁的同时设置过期时间
- 应用场景
-
什么是缓存重建
- 热点key大量失效
- key不过期
- 或者惰性创建,访问的时候,先检查,有则读取,没有则创建
- 热点key大量失效
-
redis是单线程还是多线程,6.0以后多线程解决了什么问题
- 单线程,减去了多线程的上下文切换和锁的问题
- 多路复用,类似nodejs事件循环,所有的读写都放入事件循环中,内部用多线程来执行
- 多线程还是为了解决io性能,引入多线程,每一个线程维护一个事件队列
-
redis事务
-
MULTI,EXEC,DISCARD,WATCH 四个命令是 Redis 事务的四个基础命令。其中:
MULTI,告诉 Redis 服务器开启一个事务。注意,只是开启,而不是执行 。
EXEC,告诉 Redis 开始执行事务 。
DISCARD,告诉 Redis 取消事务。
WATCH,监视某一个键值对,它的作用是在事务执行之前如果监视的键值被修改,事务会被取消。 -
应用场景
- 数据一致性
-
-
redis发布订阅
- 和node事件机制一样,通过on监听,发送等
-
cpu高
- 有一天上午十点多redis告警cpu占用率高,于是就排查最近代码,发现有人用了keys*来查询所有
- 当时立马改代码升级优化了一些
- 后面还发现有一些大key,存储了一个账户的所有座席配置,频繁获取也会导致redis cpu飙升
- 有一天上午十点多redis告警cpu占用率高,于是就排查最近代码,发现有人用了keys*来查询所有
-
内存高
- 有一次线上的redis机器内存告警
- 我们先查看目前存在的大key(数据量比较大的key)
- bigkeys命令可以查看,但只能看到String、hash、list、set、zset这五种类型
- 优点是可以在线扫描,不阻塞服务;缺点是信息较少,内容不够精确。
- 使用redis-rdb-tools工具,它实例上执行bgsave,bgsave会触发redis的快照备份,导出csv形式的文件,然后就可以进行分析了
- bigkeys命令可以查看,但只能看到String、hash、list、set、zset这五种类型
- 解决方案
- 当时这个大key hset占用了5m的空间,寸的时候是全量存进去。但实际使用只用了几个字段。所以当时就立刻更改代码,对这种key进行拆分,只存必要的字段。就解决了这个问题
- 我们先查看目前存在的大key(数据量比较大的key)
- 有一次线上的redis机器内存告警
-
性能优化
- key的命名尽量简短,节省空间,提升搜索性能
- 不要使用keys *,keys *, 这个命令是阻塞的,即操作执行期间,其它任何命令在你的实例中都无法执行。当redis中key数据量小时到无所谓,数据量大就很糟糕了。可以去使用SCAN进行滚动分页查询解决。
- 合理的设置key的有效期一些不应该长期存储的key,比如验证码,临时的token,session等都应该设置有效期,避免长期占用孔间
- 合理的关闭AOF持久化存储,对于某些不需要进行持久化存储的业务可以关闭AOF,因为每次AOF重写都需要占用额外的cpu和内存
- 避免使用大key,比如一个key的值上m甚至几十m时,严重影响查询性能并且占用空间
- 集群扩展
- 冷热数据分离
-
慢查询分析
- redis慢查询分析支持两个参数配置
- slowlog-log-slower-than 预设阈值,单位微妙(默认10000)。超过预设阈值的才会被记录到慢查询日志中
- slowlog-max-len 慢查询日志的列表长度(能记录的慢日志条数)。一个新的命令满足慢查询条件时被插入到这个列表中, 当慢查询日志列表已处于其最大长度时, 最早插入的一个命令将从列表中移出
- slowlog-log-slower-than 的默认值是 10000 微秒,也就是 10 毫秒。
- slowlog-max-len 的默认值是 128,也就是说慢查询命令队列可以保存 128 条慢查询记录
- config set slowlog-log-slower-than 100 设置慢查询阈值为100毫秒
- config set slowlog-max-len 200 设置慢查询日志保存行数为200
- slowlog get 1 获取最近一条慢查询,如果不带数字则进行滚动获取
127.0.0.1:6379> slowlog get 1 1) 1) (integer) 7 2) (integer) 1610156232 3) (integer) 24 4) 1) "slowlog" 2) "get" 5) "127.0.0.1:58406" 6) ""-
记录的慢查询标号,倒序显示
-
记录该命令的时间戳
-
执行命令的耗时,微秒为单位
-
执行的具体命令
-
执行该命令客户端的 IP 地址和端口号
-
- 在找到对应的慢查询命令和请求来源后,我们就可以通过服务的请求日志和服务代码找到对应的接口/代码来进行排查了
- redis慢查询分析支持两个参数配置
架构
微服务的优缺点
- 优势
- 每一个应用都是独立的服务
- 相比较单点服务,服务的升级和迭代不影响其他服务
- 服务性能提升
- 服务拆分后,体积变小,也没有其他服务的代码影响,整体性能提升
- 更适合快速迭代
- 相比较单点服务,每次发布都是一个整体,编译,打包时间长。微服务编译和打包时间短
- 单一职责
- 随着服务和团队的扩大,单体服务已经不能满足多个团队间的协作,因为一个团队的代码变动可能影响其他团队。所以拆分后,每个团队变更自己的服务,不影响其他人的
- 每一个应用都是独立的服务
- 劣势
- 分布式部署后,调用关系变得复杂了,之前都是单点,服务内部就通信即可。现在多个服务都是http和消息中间件调用,维护成本变高
- 测试难度提升,一个服务的接口变动会影响其他调用方
- 运维难度提升,之前只需要升级,监控单点服务。现在多个服务,每一个服务的升级,监控都是更高的成本问题
什么是restful风格
-
简称rest,它是一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件,它主要用于客户端和服务端交互类的软件。基于这个风格设计的软件可以更简介,更有层次
-
特性
- 资源
- 可以用一个URI(统一资源定位符)指向它,每种资源对应一个特性的URI。要获取这个资源,访问它的URI就可以,因此URI即为每一个资源的独一无二的识别符
- 表现层
- 比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式。
- 状态转换
- 四个表示操作方式的动词:GET、POST、PUT、DELETE。他们分别对应四种基本操作:GET用来获取资源,POST用来新建资源,PUT用来更新资源,DELETE用来删除资源
- 资源
-
如何设计
-
路径设计:数据库设计完毕之后,基本上就可以确定有哪些资源要进行操作,相对应的路径也可以设计出来。
动词设计:也就是针对资源的具体操作类型,有HTTP动词表示,常用的HTTP动词如下:POST、DELETE、PUT、GET
-
常用的设计模式,应用场景,解决了什么问题
- 单例 业务隔离
- 单例模式可以保证内存里只有一个实例,减少了内存的开销
- 可以避免对资源的多重占用
- 更专注,只做一件事
- 适配器模式 继承
- 提高代码重用性
- 提高代码的扩展性
- 开放封闭
- 当需要改变一个程序的功能或者给这个程序增加新功能的时候,可以使用增加代码的方式,尽量避免改动程序的源代码,防止影响原系统的稳定
- 策略模式
- 避免多重判断
- 扩展性高
- 工厂模式
- 主要用来初始化对象,规范对象初始化过程,节省对象的初始化成本
什么是DDD设计模式,应用场景,解决了什么问题
- 概念
- 领域驱动设计模式,把业务拆分成细粒度的领域,解决因为项目庞大而导致的耦合性问题
- application 应用层 属于业务的上层,用来编排业务层
- domain 领域层 实现具体业务处理,service逻辑层
- interface 接口层,接收接口调用
- repository 数据库仓储,处理数据库操作
- infrastructure 基础设施层,处理常量,通用方法等
- 只做增删改查 不做任何其他业务
- 引入VO,DTO,DO,PO概念
- VO
- 视图对象,主要对应界面显示的数据对象。对于一个 WEB 页面,或者 SWT、SWING 的一个界面,用一个 VO 对象对应整个界面的值
- DTO
- 数据传输对象,接收前端传递来的对象值以及接收时的校验等
- DO
- 领域对象,就是从现实世界中抽象出来的有形或无形的业务实体
- PO
- 持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一一对应的映射关系,也就是数据库实例化对象
- VO
- 应用场景
- 项目逻辑性复杂,规模较大项目适合用DDD模式
- 解决了以下问题
- 传统的MVC模式的业务层全部由service承担,这就导致service层代码臃肿且越来越难维护,模块间的关系难以梳理,模块间的耦合度过高,比如一个service方法可能包含,参数校验,参数解析,业务处理,异步事件,消息队列,数据库操作等。有个ddd,那么一个service层就被拆分为基础设施层,应用层,领域层,仓储层
- 在划分领域的基础上,又对实体对象进行了划分,分为VO,DTO,DO,PO。业务对象的细分一方面使得业务更加便于理解和区分,也让业务间的实例化对象隔离,避免污染而造成后续的维护等问题
Kakfa
-
概念
- 业务解耦
- 传统的http业务,每一个接收方的变动都可能导致推送方的代码有所变动,久而久之,非常不利于维护。有了消息队列,那么推送放只负责推送消息,对于接收方如何处理,它不需要关心,从而达到了解耦。
- 削峰
- 传统模式,并发量大的会导致业务异常,比如数据库负载过高。而消息队列会根据对方的消费能力来处理,可能会有短暂的挤压,但不会导致数据库负载过高
- 可靠性传输
- 传统http如果没有重试机制,会导致请求丢失。kafka会保证被消费者接收
- 业务解耦
-
组成
- 生产者 消息发送方
- 实例 kafka服务器, Kafka服务器,负责消息存储和转发
- topic 消息类别,Kafka按照topic来分类消息
- 分区 用于提高kakfa吞吐量
- 副本 每个分区有多个副本 默认10个,不能大于broker的数量,用于做主备切换
- 消费者 接受消息
- 消费者组 多个消费者在一个消费组,一个分区的数据只能被一个组内的一个消费者消费。同一个消费者可以处理同一个主题下不同分区的数据
- zookeeper 保证kafka集群的通信,配置和可用性
-
当前使用的是2.8.0版本
-
消费者获取消息的机制
- 通过拉取的方式
- pull模式消费者自主决定是否批量从broker拉取数据,而push模式在无法知道消费者消费能力情况下,不易控制推送速度,太快可能造成消费者奔溃,太慢又可能造成浪费
- 生产者会发送给订阅这个主题的分区,如果指定分区,则发给指定分区。如果没有指定,则轮询发送。
-
kafka为什么用zookeeper
- 主要用于在集群中不同节点之间进行通信,在 Kafka 中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取,除此之外,它还执行其他活动,如: leader 检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等
-
消息同步机制
- ack=0 不关注消费者是否收到消息
- ack=1 只要leader节点收到通知 就算成功(kafka默认选项)
- ack=-1 所有复制节点收到通知才算成功
-
什么是分区
- 如果你创建的
topic有5个分区,当你一次性向 kafka 中推 1000 条数据时,这 1000 条数据默认会分配到 5 个分区中,其中每个分区存储 200 条数据 - 这样做的目的,就是方便消费者从不同的分区拉取数据,假如你启动 5 个线程同时拉取数据,每个线程拉取一个分区,消费速度会非常非常快!
- 发送消息时先发给主分区,主分区同步给子分区
- 分配机制
- 1、数据在写入的时候可以指定需要写入的分区,如果有指定,则写入对应的分区
- 2、如果没有指定分区,但是设置了数据的key,则会根据key的值hash出一个分区
- 3、如果既没指定分区,又没有设置key,则会轮询选出一个分区
- 分配机制
- 消费者从主分区中拉取消息
- 如果你创建的
-
kafka消息顺序
- 同一个分区内的消息是有序的
- 多个分区是无序的
-
消费者分区分配策略
- RangeAssignor 范围分配
- kafka默认的分配策略,假如现在有 10 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6,7,8,9;消费者排序完之后将会是C1-0,C2-0,C3-0。那么第一个消费者就多消费一个分区
- 默认按照编号排序分配
- RangeAssignor 范围分配
-
kafka如何跟踪消费状态
- 通过offset偏移量来标记消费的位置
-
分区策略
- 轮询 一次将消息发给该topic下所有分区
- 指定分区
-
kafka为什么性能强
- 利用分区提高集群负载
- 多个分区
- 数据缓存
- 如果在 Cache 中存在该数据且是最新的,则直接将数据传递给用户程序,免除了对底层磁盘的操作,提高了性能
- 批处理
- 控制分批发送
- 利用分区提高集群负载
-
应用场景
- 日志收集
- 对接多方,需要业务解耦
- 用户登录退出事件
- 企业账单
- 通话事件
- 报表事件
-
常见面试题
- kafka中的broker 是干什么的
- broker 是消息的代理,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉取指定Topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
- kafka中的 zookeeper 起到什么作用,可以不用zookeeper么
- zookeeper 是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,
但是broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller 和 检测broker是否存活等等。
- zookeeper 是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,
- Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
- ISR:In-Sync Replicas 副本同步队列。AR:Assigned Replicas 所有副本
- kafka中consumer group 是什么概念
- 同样是逻辑上的概念,是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费。group内的worker可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个worker消费(同一group内)
- kafka的消费者是pull(拉)还是push(推)模式,这种模式有什么好处
- kafka遵循了一种大部分消息系统共同的传统的设计:producer 将消息推送到 broker,consumer 从broker 拉取消息
- 优点:pull模式消费者自主决定是否批量从broker拉取数据,而push模式在无法知道消费者消费能力情况下,不易控制推送速度,太快可能造成消费者奔溃,太慢又可能造成浪费
- 缺点:如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,直到新消息到到达。为了避免这点,Kafka 有个参数可以让 consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发送)
- kafka遵循了一种大部分消息系统共同的传统的设计:producer 将消息推送到 broker,consumer 从broker 拉取消息
- kafka 如何不消费重复数据?比如扣款,我们不能重复的扣
- 这个问题换种问法,就是kafka如何保证消息的幂等性。对于消息队列来说,出现重复消息的概率还是挺大的,不能完全依赖消息队列,而是应该在业务层进行数据的一致性幂等校验
- 比如你处理的数据要写库(mysql,redis等),你先根据主键查一下,如果这数据都有了,你就别插入了,进行一些消息登记或者update等其他操作。另外,数据库层面也可以设置唯一健,确保数据不要重复插入等 。一般这里要求生产者在发送消息的时候,携带全局的唯一id
- kafka Stream
- Kafka Streams是一个客户端程序库,用于处理和分析存储在Kafka中的数据,并将得到的数据写回Kafka或发送到外部系统。可以说是消息转换器,在消息发送之前进行转换后再重新发送。可以针对部分业务场景做数据化定制,或者在不改变生产者业务的前提下来转换消息体
- kafka中的broker 是干什么的
-
集群
- kafka最小可用集群是三个节点,也就是三个broker,和传统集群类似,一个主节点,两个从节点
-
消息队列常见问题
- 消息堆积
- 某天运维监控系统告警,kafka的消息堆积超过阈值200,于是进入系统查看发现某topic下的消息堆积已经达到了220
- 于是查看代码中接收该topic消息的代码,先是排查了对第三方接口同步调用的日志,均在200毫秒内返回,又查看企业内部调用,发现有一个数据同步接口延迟最高可达30s
- 联系到该部分的同事,经过排查发现是因为该接口代码近期有更新,增加了部分查询数据和逻辑复杂的运算,导致上层应用消费能力下降,从而导致上层的消息堆积
- 临时的解决方案是当天该部门回滚代码,保证服务可用
- 最终解决方案是,该接口只负责接收和存储事件。具体的业务处理交给内部服务来进行定时的处理
- 上层应用也将部分第三方,其他部门的接口调用改为了异步或超时处理
- 消息重复
- 同样是上面的问题,同步的延迟导致触发了kafka的重试,数据库中被插入了重复数据,同时重复的调用了其他服务的接口,也导致了其他服务存储了重复的数据
- 后续我们将部分对幂等性要求高的业务统一做了数据校验重复方案,就解决了此问题
- 消息堆积
Apollo
- 什么是apollo
- 一款可靠的分布式配置管理中心,诞生于携程框架研发部,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景
- 特点,应用场景
- 统一管理不同环境,不同集群的配置
- 配置实时更新
- 版本发布
- 灰度发布
- 权限管理
- 组成
- application 应用
- environment 环境
- cluster 集群
- namespace 命名空间
- 组件
- config service
- admin service
- protal
私有包使用nexus作为仓储
Docker
- 什么是docker
- 使用go编写,开源的容器引擎。docker可以让开发者打包他们的应用和依赖到一个轻量的容器中,然后可以发布到任意的linux平台。
- dockerfile
- 用来构建docker镜像的文本文件,包含了构建镜像的指令和说明等
- 应用场景和优缺点
- 比起传统sh脚本,docker镜像更适合自动编译,打包和发布
- 自动化集成,cicd
- 维护成本低,容错率高
- 隔离运行环境
- 常用命令
- docker info 查看docker版本信息
- docker images 查看镜像列表
- docker search 镜像名称 搜索镜像
- docker run 镜像名称 运行镜像
- docker ps -a 查看容器列表
- docker image rm 镜像名 删除某一个镜像
- 你们公司都是如何使用docker的
- 公司内部使用k8s来管理和编排docker。
- 在ci阶段,使用dockerfiler完成编译,打包。然后将镜像推送到harbor仓储。到cd阶段,上k8s环境更改镜像id,触发k8s的更新后,自动滚动发布。
K8s
-
什么是k8s,和docker区别
- 概念
- 一个容器编排工具,可以滚动升级,对运行的容器状态进行监控,还有健康检查等
- docker是一个容器部署工具,运行环境隔离,有自己的文件系统等
- 优点
- 运行管理隔离,相互不影响
- 有利于分布式,因为容器轻量,每一个应用都可以当作一个容器
- 缺点
- 随着容器的增加,容器的管理是个大问题
- 服务升级如何保证不中断
- 服务运行状态的监控
- 容器的监控
- 优点
- 概念
-
特点,应用场景和优缺点
- 中大型应用使用k8s比较合适,因为随着应用体积变大,运维监控成本会变高
-
k8s的组成
- apiserver
- Kubernetes API 服务器验证并配置 API 对象的数据, 这些对象包括 pods、services、replication、controllers 等。 API 服务器为 REST 操作提供服务,并为集群的共享状态提供前端, 所有其他组件都通过该前端进行交互
- etcd
- etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
- proxy
- 工作节点上的一个网络代理组件,运行在每个节点上
它维护节点上的网络规则,实现了Kubernetes Service 概念的一部分 。它的作用是使发往 Service 的流量(通过ClusterIP和端口)负载均衡到正确的后端Pod
- 工作节点上的一个网络代理组件,运行在每个节点上
- kubelet
- Kubelet组件运行在Node节点上,维持运行中的Pods以及提供kuberntes运行时环境,主要完成以下使命:
1.监视分配给该Node节点的pods
2.挂载pod所需要的volumes
3.下载pod的secret
4.通过docker/rkt来运行pod中的容器
5.周期的执行pod中为容器定义的liveness探针
6.上报pod的状态给系统的其他组件
7.上报Node的状态
- Kubelet组件运行在Node节点上,维持运行中的Pods以及提供kuberntes运行时环境,主要完成以下使命:
- apiserver
-
k8s核心概念
- pod
- k8s内的一个容器单元,相当于一个拥有命名空间和存储卷的docker容器
- deployment
- 用来管理pod,控制pod的增删改
- service
- 实现pod的网络通信。因为pod每次变更都会发生ip变动,所以就需要一个入口来屏蔽ip的变动,实现通过service访问内部pod
- service和pod没有直接关系,pod通过endpoints暴漏出来,只要pod变更就会同步到endpoints中。service通过endpoints的映射关系来访问pod
- pod
-
k8s的健康检查机制都有哪些
- 存活探测器
- 用来探测什么时候重启定时器
- 就绪探测器
- 用来探测什么时候可以接受请求流量
- 启动探测器
- 用来探测应用程序何时启动
- 存活探测器
-
如何实现集群管理
- 开发人员通过rancher可视化平台,实现对pod的生命周期管理
-
K8S基础
- K8S的概念
- 是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制
- k8s解决了什么问题
- 解决以下问题
- 随着容器的增加,容器的协调和调度步骤主键繁琐
- 服务升级如何保证不中断
- 服务运行状态的监控
- 容器的监控
-
K8S中POD的概念
- k8s内的一个容器单元,相当于一个拥有命名空间和存储卷的docker容器
-
K8S的命名空间
- 命名空间 namespace 是 k8s 集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的命名空间,例如,可以为 test、devlopment、production 环境分别创建各自的命名空间
- 命名空间适用于存在很多跨多个团队或项目的用户的场景
- 命名空间 namespace 是 k8s 集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的命名空间,例如,可以为 test、devlopment、production 环境分别创建各自的命名空间
-
Deployment无状态应用的部署
- 编写一个yml文件,按照k8s的格式定以命名空间,pod标签,端口号,镜像id等
-
Service的类型
- clusterip
- 通过集群的内部 IP 暴露服务,选择该值时服务只能够在集群内部访问。 这也是默认的 ServiceType
- NodePort
- 通过每个节点上的 IP 和静态端口(NodePort)暴露服务。 NodePort 服务会路由到自动创建的 ClusterIP 服务。 通过请求 <节点 IP>:<节点端口>,你可以从集群的外部访问一个 NodePort 服务。
- LoadBalancer
- 使用云提供商的负载均衡器向外部暴露服务。 外部负载均衡器可以将流量路由到自动创建的 NodePort 服务和 ClusterIP 服务上
- clusterip
-
Service和pod的关系
- service和pod并没有直接的关系。pod通过endpoints暴露出来,只要pod发生变更,便会同步至endpoints中。有了service和endpoints后,kube-proxy会实时监听它们的更新和删除操作,然后更新iptables代理规则,重新生成该service访问pod的ip和端口映射规则
-
labels标签
- 当相同类型的资源越来越多,对资源划分管理是很有必要,此时就可以使用label为资源对象 命名,以便于配置,部署等管理工作,提升资源的管理效率
-
labels selector 标签选择器
- Label selector(标签选择器)是Kubernetes核心的分组机制,通过label selector客户端/用户能够识别一组有共同特征或属性的资源对象
- 通过资源对象上定义的Label Selector来筛选要监控的Pod副本的数量,从而实现Pod副本的数量始终符合预期设定的全自动控制流程
- kupe-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立器每个Service到对应Pod的请求转发路由表,从而实现Service的智能负载均衡机制
- 通过对某些Node定义特定的Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略,Kube-scheduler进程可以实现Pod定向调度的特性
- Label selector(标签选择器)是Kubernetes核心的分组机制,通过label selector客户端/用户能够识别一组有共同特征或属性的资源对象
-
Ingress七层负载均衡
- ingress其实类似nginx,通过k8s监听ingress资源的变化,重新生成nginx.conf文件,然后生效
- 和tcp七层协议一样,只不过最后通过service完成负载均衡
- ingress其实类似nginx,通过k8s监听ingress资源的变化,重新生成nginx.conf文件,然后生效
-
K8S深入
-
K8S的资源配额、限制
- 通常nodejs的pod限制在2c4g,但可以通过配置yml文件来达到以下目的
- 达到1.8c的时候扩容一个pod
- 达到3.5g的时候库容一个pod
- 通常nodejs的pod限制在2c4g,但可以通过配置yml文件来达到以下目的
-
K8S的环境变量
- 在yml配置文件中的env下定义即可
-
K8S配置管理(ConfigMap、Secret等)
- configmap是k8s的一个配置管理组件,可以将配置以key-value的形式传递,通常用来保存不需要加密的配置信息,加密信息则需用到Secret,主要用来应对以下场景:
- 使用k8s部署应用,当你将应用配置写进代码中,就会存在一个问题,更新配置时也需要打包镜像,configmap可以将配置信息和docker镜像解耦。
- 使用微服务架构的话,存在多个服务共用配置的情况,如果每个服务中单独一份配置的话,那么更新配置就很麻烦,使用configmap可以友好的进行配置共享。
其次,configmap可以用来保存单个属性,也可以用来保存配置文件
- configmap是k8s的一个配置管理组件,可以将配置以key-value的形式传递,通常用来保存不需要加密的配置信息,加密信息则需用到Secret,主要用来应对以下场景:
-
K8S的滚动更新
- 所谓滚动升级,就是在升级过程中,并不一下子启动所有新版本,是先启动一台新版本,再停止一台老版本,然后再启动一台新版本,再停止一台老版本,直到升级完成
-
K8S的健康检查
-
存活探测器
- 用来探测什么时候重启定时器
-
就绪探测器
- 用来探测什么时候可以接受请求流量
-
启动探测器
- 用来探测应用程序何时启动
-
K8S的存储管理(PV、PVC等)
kubernetes 入门实践-存储 volume-nfs-pv-pvc
-
K8S的有状态服务StatefulSet
kubernetes 入门实践-有状态的服务 StateFulSet
-
K8S的Job、CronJob
批任务处理,其中CronJon可以处理定时任务 -
使用流水线部署K8S应用
GitHub Actions CI/CD
-
-
K8S进阶
-
K8S集群搭建
kubernetes 入门实践-搭建集群 -
K8S负载均衡
kubernetes 入门实践-Ingress
其中ingress负责访问service的策略,而ingress-controller负责负载均衡策略 -
K8S的调度策略(亲和、反亲和等)
Pod亲和性指的是满足特定条件的的Pod对象运行在同一个node上, 而反亲和性调度则要求它们不能运行于同一node -
K8S的存储(本地存储、分布式存储等)
kubernetes 入门实践-存储-hostpath
kubernetes 入门实践-搭建nfs服务器 -
K8S中的负载均衡(ClusterIP、NodePort、L4、L7负载均衡)
-
K8S的弹性伸缩(HPA)
- HPA
- 根据资源利用率或者自定义指标自动调整replication controller, Deployment 或 ReplicaSet,实现部署的水平自动扩缩容,让部署的规模接近于实际服务的负载。可以使用rancher界面功能,终端命令或者hpa yml配置文件完成
- HPA
-
使用Helm Chart发布应用
- helm是kubernetes生态系统中的一个软件包管理工具,类似ubuntu的apt,centos的yum或python的pip一样,专门负责管理kubernetes应用资源;使用helm可以对kubernetes应用进行统一打包、分发、安装、升级以及回退等操作
-
K8S的日志、监控、告警体系
-
Istio服务网格与流量治理
-
K8S技术演进路线(AKS、ASK、ACI、FaaS等)
-
-
项目
你们线上运行多少机器,都是什么配置,为什么这样配置
- 旧平台 我们部门总共20台,大多都是4c8g的机器,一共14个服务
- 新平台 ,一共接近30台服务器,但经过容器化管理后,单位其实是pod。我们pod基本配置都是2c4g的,每个服务两个pod,部分流量大的pod会扩展到3-4个,除了个别服务,因为要处理导入和导出,所以内存较高。新平台的服务,我们部门总共有25个
QPS达到多少
- 能打到1000-1200 200+ms
你们登录加密token怎么做的
- 直接用md5来做的
- 后台通过加盐来对比数据库密码
单点登录如何做的
- 用redis存储单点登录状态,第三方发起/loginToken登陆时,通过接口传递用户标记获取token,然后用token发起单点登录
说说对sass行业的理解
- 是一种通过网络提供集中式服务的软件。
- 不用购买,安装和维护任何软件硬件,只需要根据需要。每个月付钱即可。和"租"类似
什么是线程安全和不安全
- 安全
- 有锁机制,避免了多个线程争抢资源问题
- 不安全
- 没有锁,多个线程可能争抢资源,导致业务异常。比如多个定时器任务就需要用到锁。或者相同状态的业务处理,或者有顺序要求的业务处理等
什么是GRPC
- 先看一下rcp和http区别
- RPC 主要用于公司内部的服务调用,性能消耗低,传输效率高,实现复杂。
HTTP 主要用于对外的异构环境,浏览器接口调用,App 接口调用,第三方接口调用等。
- RPC 主要用于公司内部的服务调用,性能消耗低,传输效率高,实现复杂。
- grpc是基于rpc的一个框架
ElasticSearch
- 什么是Elasticsearch
- 基于lucence的搜索引擎,接口风格基于resultful,使用Java开发的
- 分片
- 概念
- 在ES中所有数据的文件块,也是数据的最小单元块,整个ES集群的核心就是对所有分片的分布、索引、负载、路由等达到惊人的速度
- 假设 IndexA 有2个分片,我们向 IndexA 中插入10条数据 (10个文档),那么这10条数据会尽可能平均的分为5条存储在第一个分片,剩下的5条会存储在另一个分片中。
- 设置分片的关键字是number_of_shards
- 设置分片副本的关键字是number_of_replicas
- 设置分片的策略
- 建议:(仅参考)
- 1、每一个分片数据文件小于30GB
- 2、每一个索引中的一个分片对应一个节点
- 3、节点数大于等于分片数
- 概念
- 副本
- 保障系统的高可用性,如果分片异常,副本分片会晋升为分片
- 特点
- 分布式文件存储
- 和mongodb分片优点类似,将多条数据分布在不同的分片上,提高查询性能
- 也有master和node节点
- 实时分析的分布式搜索引擎
- 基于倒排索引和lucence
- 高扩展性
- 扩展简单,只需要一台机器,根据配置文件指定集群节点加入即可
- 分布式文件存储
- 优缺点
- 优点
- 高可用性,分布式部署,支持快照备份和恢复
- 和传统的数据库集群一样,都是三个节点
- 类似mongodb的分片机制,把数据存储在不同的分片中,提高查询性能和负载承受能力
- 生态完善,部署简单,数据迁移简单等
- 根据文档即可部署
- kibana日志分析
- elasticsearch内置了数据迁移api
- 内置多种分词器,满足大部分业务场景
- 完全模糊搜索 ngram
- 中文分词 IK
- 还有很多其他的
- 搜索性能高
- 每个字段都有索引
- 高可用性,分布式部署,支持快照备份和恢复
- 缺点
- 增加维护成本,毕竟是一个额外的组件
- 不能随意更改索引结构,对于现有数据的结构,只能通过迁移数据到新索引结构上来解决
- 优点
- 应用场景
- 模糊搜索,全文检索
- 日志分析,kibana内部集成了elasticsearch
- 运维监控
- 当前用的是2.x版本
- 索引比较大的 工单数据量是一千多万,占用空间三百多g
- 一千多万数据量用默认的stander分词器,占用一百多g。使用ngram后占用三百多g
- 业务中的应用场景
- 客户手机号和昵称模糊搜索
- 工单编号和工单备注模糊搜索
- 通话关联的客户昵称和手机号模糊搜索
- 正序和倒排索引区别
- 正序索引
- 概念
- 好比mongodb,搜索一个关键字,要扫描表中每一个文档进行匹配
- 好比在mongo中模糊搜索,包含这个关键字的文档
- 数据库就会用这个关键字逐个匹配表中的文档,如果有100个文档,就扫描100次
- 优点
- 直接正序插入,不用对关键词进行拆分,所以插入效率高
- 缺点
- 检索性能差
- 概念
- 倒排索引
- 概念
- 和正序反过来,比如搜索苹果手机,那么倒排索引会拆分成苹,果,手,机这四个词,每一个词分别对应了包含该关键字的文档id
- 三要素
- 词条
- 检索的关键词,关键字key
- 词典
- 词条的集合,拆分后的词组
- 倒排表
- 记录词条出现的位置和频率,每一项是一个倒排项
- 词条
- 优点
- 检索性能高
- 缺点
- 插入的效率低,因为要对关键字进行拆分,构建索引
- 概念
- 正序索引
- 当前使用的是什么版本 2.x版本
- Elasticsearch基本概念
- 集群
- 节点
- 索引
- 文档
- 类型
- Elasticsearch如何保证写一致
- 在操作写入的时候,es会进行以下步骤确保写一致性
- 检查活跃的副本数,这个参数默认为1,也可以自己指定。如果活跃的副本数小于设定的值,则写入失败
- 然后等待所有副本写入成功(中间会有一些重试措施)才返回,但并不是所有都写入才算成功
- 写入中,如果有一个副本异常,持续失败,那么副本会通知主节点,将异常的副本关系移除。被移除的副本不接受任何请求。
- 在操作写入的时候,es会进行以下步骤确保写一致性
- Elasticsearch写一致性策略
- one:只要有1个primary shard是可用的,就可以进行写操作
- all:必须所有的primary shard和replica shard都是可用的,才可以进行写操作
- quorum:默认值。要求所有的shard中,必须大部分shard都是可用的,才可以进行写操作
- int( (shard + number_of_replicas) / 2 ) + 1
- 举个例子,3个primary shard,number_of_replicas=1,总共有3 + 3 * 1 = 6个shard
- quorum = int( (3 + 1) / 2 ) + 1 = 3
- 所以,要求6个shard中至少有3个shard是active状态的,才可以执行这个写操作
- 你们都用到了哪些分词器
- stander
- ngram
- Elasticsearch基本语法
- 数据结构
- index 索引
- type 类型
- id 字段id
- routing 路由
- body 数据体
- 查询
- query 查询器
- should 或条件,至少满足一项
- filter 过滤器,条件
- term 精准匹配
- match 模糊匹配
- Match_phrase 短语模糊匹配
- size 查询多少个
- _source 返回指定字段
- 数据结构
- Elasticsearch数据类型
- text:被分析索引的字符串类型
- keyword:不能被分析,只能被精确匹配的字符串类型
- date:日期类型,可以配合format一起使用
- long:长整型,数字类型
- integer:整型,数字类型
- short:短整型,数字类型
- double:双精度浮点型,数字类型
- Boolean:布尔型,true、false
- array:数组类型
- object:对象类型,json嵌套
- ip:ip类型
- geo_point:地理位置类型
- Elasticsearch使用中遇到的问题
- 默认的stander不能满足业务场景模糊搜索的需求,然后使用ngram进行改造,设置最小和最小分次数,设置的是1_25。它会逐字分词,然后使用uniq对重复结果过滤,对于大文本的场景较少,所以再使用limit对结果数进行限制。
- 数据迁移失败,因为es默认会字符串进行转换,比如’1.0’会被转成1,字符串’2022’会被转换成日期格式,但字符串是一个自由的文本内容,按照es隐式转换标准会失败,所以就把这两个配置项给关闭了numeric_detection 数字转换,date_detection 日期转换
- 如何监控Elasticsearch状态
- elasticsearch-head 开源地址在github
- 常见面试题
- 集群
- 一共13个es节点,接近30个索引,大部分以业务命名,个别的会以日期命名。
- 默认情况下,,Elasticsearch为每个索引创建五个主分片和一个副本。这意味着每个索引将包含五个主分片,每个分片将具有一个副本。
- api
- elasticsearch常用API
- 性能优化
- 对于不需要模糊匹配的字段尽量使用keyword。keyword不进行分词,直接索引
- 尽量使用term查询
- 只存储业务需要字段,节省空间并提升性能
- 减少大文本存储,虽然es适合大文本检索,但过大的文本也会造成性能问题
- 使用索引滚动模式,避免一个索引数据过于庞大而造成的性能问题。可以采用按月或按年来进行日期滚动
- 减少搜索结果,避免每次查询上百上千的数量,过多的查询结果也会造成性能问题
- 冷却分离存储,分两种级别
- 业务级别,非热点或核心业务可以存储冷数据中,这样热数据索引空间变小,就能够提升热数据的性能
- 用户级别,将非活跃用户的数据存储到冷索引中,那么热索引的空间变小,自然查询性能就变高了
- 集群
综合
该篇是对标了几个大厂常问和一些偏八股文的问题
TCP和UDP区别
- UDP提供无连接服务
- UDP不需要维护连接状态
- UDP适用于效率高的应用
- UDP不像TCP那样每一次发送都需要进行确认
- UDP性能高,开销小
- UDP连接不可靠
HTTP和HTTPS区别
- HTTPS协议需要CA证书,费用较高;而HTTP协议不需要;
- HTTP协议是超文本传输协议,信息是明文传输的,HTTPS则是具有安全性的SSL加密传输协议;
- 使用不同的连接方式,端口也不同,HTTP协议端口是80,HTTPS协议端口是443;
- HTTP协议连接很简单,是无状态的;HTTPS协议是有SSL和HTTP协议构建的可进行加密传输、身份认证的网络协议,比HTTP更加安全。
- HTTPS使用了非对称加密和对称加密:HTTPS是在HTTP的基础上增加了SSL层,服务器和客户端传输数据前先采用非对称加密算法生产一个秘钥,再用这个秘钥使用对称加密算法加密要传输的数据,这样做即保证了秘钥的安全,有提高了数据加密效率。
HTTP长连接和短链接区别
- 长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,下次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
- 而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好。
- http1.1 默认支持长连接(keep-alive),TCP连接之后不会马山断开,之后再加载静态资源,都会基于这个TCP连接。http1.1还保持了host头部,也支持虚拟主机。而且支持断点续传
- 长连接详解
- 第一次请求网页时会打开一个TCP连接,去加载css等静态资源,等这些请求加载完毕后才会释放连接。当一个请求对于的回包回来时,他却无法分辨是属于哪个请求的。所以回包只能按请求顺序返回,这就引来了另一个问题-线头阻塞。
- 长连接详解
- http 2.0 多路复用。基于TCP连接并行发送多个请求和接受响应,解决http1.1请求串行的性能问题等
TCP长连接和HTTP长连接区别
- TCP的是为了检测心跳,保持活跃的
- HTTP的主要是在TCP的保活基础上重用连接,提高性能的
TCP如何保证可靠性传输
- ARQ协议(超时重传协议)
- ARQ 协议也就是超时重传机制。通过确认和超时机制保证了数据的正确送达,ARQ 协议包含停止等待 ARQ 和连续 ARQ
- 正常传输过程
只要 A 向 B 发送一段报文,都要停止发送并启动一个定时器,等待对端回应,在定时器时间内接收到对端应答就取消定时器并发送下一段报文
浏览器输入网址后都发生了什么
- 输入www.baiidu.com
- 将域名发送给DNS服务器
- DNS服务器返回一个ip地址
- 然后客户端会把自己的ip和DNS返回的ip 分别换算成二进制,然后对比前三位数是否在一个子网
- 在一个子网则直接发送
- 不在一个子网,则将数据包发给交换机,通过以太网协议广播到路由器(网关),路由器再继续进行寻址,直到找到对应的ip服务器
- 然后把http请求打包到数据包中构成请求报文
- 然后就到了传输层,经过TCP协议需要设置接收方的端口。然后把应用层的数据包封装到TCP数据包中,并加上一个TCP头部,该头部包含了接收方的端口号
- 然后就到了网络层,走ip协议,把tcp协议的头和数据包放入ip数据包中,再加一个ip头(包含了本机和接收方的ip地址)
- 然后就到了数据链路层,再把ip数据包放入以太网数据包中,头部存放了本机网卡的mac地址,网关的mac地址。但是以太网的数据包限制大小在1500个字节,如果超出则进行分割,分割后的数据包报头都包含了mac地址。然后再通过交换机,用以太网协议进行广播分发
- 直到找到最后的ip服务器。收到分割后的包根据ip头的序号再讲这分割后的包进行合并。然后从ip数据包中找到tcp数据包,再从tcp数据包中找到http数据包进行读取和处理。然后再把返回的数据封装成http响应报文并放在http数据包中,再放入tcp数据包,再放入ip数据包,最终封装成以太网数据包,通过网关寻址转发回去
HTTP1.0,1.1,2.0的区别
- http1.0 需要指定kepp-alive来保持连接,默认短链接,每次请求都要重新建立一次TCP连接,处理完毕后就释放连接。但这样的话当网页内容较多时,比如css,js比较多,那么每次都要重新请求,就很浪费资源
- http1.1 支持长连接(keep-alive),TCP连接之后不会马山断开,之后再加载静态资源,都会基于这个TCP连接。http1.1还保持了host头部,也支持虚拟主机。而且支持断点续传
- 长连接详解
- 第一次请求网页时会打开一个TCP连接,去加载css等静态资源,等这些请求加载完毕后才会释放连接。当一个请求对于的回包回来时,他却无法分辨是属于哪个请求的。所以回包只能按请求顺序返回,这就引来了另一个问题-线头阻塞。
- 长连接详解
- http 2.0 多路复用。基于TCP连接并行发送多个请求和接受响应,解决http1.1请求串行的性能问题等
- 其实长连接和短连接指的是TCP连接
HTTP三次握手和四次挥手过程
- 三次握手
- 第一次握手(进入同步已发送状态)
- 向服务器发送连接请求报文段 包含了端口和序列号
- 发送SYN序列号,此时seq=a
- 第二次握手(进入同步收到状态)
- 确认报文段,标识服务器希望从客户端这边接收到数据的序列号
- 服务端返回SYN序列号,其中seq=b,并把ack+1进行返回
- 第三次握手(已进入连接状态)
- 客户端收到服务端发送的确认ACK后,还要再次向服务器给出确认,确认报文段的ACK设置为1
- SYN内的seq=b+1
- 三次握手的目的不仅在于通信双方了解一个连接正在建立,还在于用数据包的选项承载特殊的信息,确保通信双方是可靠的
- 第一次握手(进入同步已发送状态)
- 四次挥手
- 第一次挥手(终止等待状态)
- 客户端向服务器发出连接释放的报文段
- 发送 FIN,seq=a
- 第二次挥手(终止等待状态2)
- 服务区收到连接释放报文段后立即发出确认
- 服务端返回ACK,seq=b,ack=a+1
- 第三次挥手(最后确认)
- 如果服务器已经没有向客户端发送数据,其应用的进程就通知服务器释放连接
- 服务端继续返回FIN,seq=b,ack=a+1
- 第四次挥手(时间等待)
- 客户端收到服务器的连接释放报文段后,立即对此发出确认
- 这样就能够让TCP重新发送最终的ACK以避免出现丢失的情况,重新发送最终的ACK并不是因为TCP重新传递了ACK,而是因为通信的另一方重新传递了它的FIN序列号
- 为了保证 B 能收到 A 的确认应答。若 A 发完确认应答后直接进入 CLOSED 状态,如果确认应答因为网络问题一直没有到达,那么会造成 B 不能正常关闭。
- 客户端发送ACK,seq=b+1
- 第一次挥手(终止等待状态)
为什么是三次握手而不是两次
- 可以想象如下场景。客户端发送了一个连接请求 A,但是因为网络原因造成了超时,这时 TCP 会启动超时重传的机制再次发送一个连接请求 B。此时请求顺利到达服务端,服务端应答完就建立了请求。如果连接请求 A 在两端关闭后终于抵达了服务端,那么这时服务端会认为客户端又需要建立 TCP 连接,从而应答了该请求并进入 ESTABLISHED 状态。此时客户端其实是 CLOSED 状态,那么就会导致服务端一直等待,造成资源的浪费。
进程,线程,协程区别
-
进程是具有⼀定独⽴功能的程序关于某个数据集合上的⼀次运⾏活动,进程是系统进⾏资源分配和调度的⼀个独⽴单位。每个进程都有⾃⼰的独⽴
内存空间,不同进程通过进程间通信来通信。由于进程⽐较重量,占据独⽴的内存,所以上下⽂进程间的切换开销(栈、寄存器、虚拟内存、⽂件
句柄等)⽐较⼤,但相对⽐较稳定安全。 -
线程是进程的⼀个实体,是CPU调度和分派的基本单位,它是⽐进程更⼩的能独⽴运⾏的基本单位.线程⾃⼰基本上不拥有系统资源,只拥有⼀点在运
⾏中必不可少的资源(如程序计数器,⼀组寄存器和栈),但是它可与同属⼀个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共
享内存,上下⽂切换很快,资源开销较少,但相⽐进程不够稳定容易丢失数据。 -
协程是⼀种⽤户态的轻量级线程,协程的调度完全由⽤户控制。协程拥有⾃⼰的寄存器上下⽂和栈。协程调度切换时,将寄存器上下⽂和栈保存到
其他地⽅,在切回来的时候,恢复先前保存的寄存器上下⽂和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下
⽂的切换⾮常快。
时间和空间复杂度
- O(1) 没有循环 一次性执行
- O(logN) 对数型TCP
- O(n)线性 一个循环
- O(n2)平方 for循环嵌套for
- O(n3)立方 for循环嵌套for再嵌套for
- O(2^n)指数
- …
serverless
- 核心概念
- 弱化了储存和计算之间的联系。 服务的储存和计算被分开部署和收费,服务的储存不再是它本身的一部分,而是演变成了独立的云服务,这使得计算变得无状态化,更容易调度和缩扩容,同时也降低了数据丢失的风险
- 代码的执行不再需要手动分配资源。 我们再也不需要为服务的运行指定需要的资源(比如使用几台机器、多大的带宽、多大的磁盘…),只需要提供一份代码,剩下的交由serverless平台去处理就行了
- 按使用量计费。 serverless按照服务的使用量(调用次数、时长等)进行计费,而不是像传统的serverful服务那样,按照使用的资源(ECS实例、VM的规格等)计费。
微信云开发技术架构
Serverless入门