深入理解XGboost
XGBoost
Author:Miracle8070
From:AI蜗牛车
1. 写在前面
如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,在这简单的先捋一捋, 常见的机器学习算法:
监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯,K近邻,支持向量机,集成算法Adaboost等
无监督算法:聚类,降维,关联规则, PageRank等
这个系列已经基本包含了上面这些算法的原理和基本使用。但是,如果仅仅是会用这些算法可是不够的, 我们也得跟着时代的步伐前进,近几年,有很多大佬又在上面的某些算法上加以改进,发明了更加厉害的算法,而这些算法才是当今时代解决问题的主流,所以我们学习的一个方式就是掌握传统,而又得紧跟时代。
所以,后面考虑加上当前流行的一些主流机器学习算法,既当复习,又当提升。由于不想和传统的机器学习算法混合起来,故称之为番外,也是传统机器学习算法的延伸, 同样是尽量白话,同样是丰富实战,但会夹杂数学的身影,毕竟后面的很多算法如果没有了数学就仿佛失去了灵魂,无法活灵活现。所以机器学习算法的故事还没有完,我们还得继续走着。
学习算法的过程,获得的不应该只有算法理论,还应该有乐趣和解决实际问题的能力!
今天分享的这个算法堪称数据科学竞赛界的神器, 它似乎是用于赢得数据科学竞赛的分类器/预测器必不可少的算法, 那就是Xgboost。听这个名字,你可能一下就想到了传统机器学习算法里面的AdaBoost,哈哈,联想和对比才能更加理解算法的精华。你还别说,这个算法和那个来自于同一个家族,都是集成学习算法,都属于boosting流派,但是两者的boosting采用了不同的策略,而就是这策略的不同,导致xgboost成了目前竞赛者眼中的红人,它是目前最快最好的开源 boosting tree 工具包,比常见的工具包快 10 倍以上, 那么xgboost到底采用了什么策略呢?它又是如何做到高准确率和高速度的呢?Xgboost和AdaBoost到底有什么不同呢?Xgboost又如何来解决实际问题呢? 这些问题,在这篇文章中都会一一来解剖。
大纲如下:
Xgboost?这个故事还得先从AdaBoost和GBDT说起
Xgboost的基本原理(基于例子我们来看看好玩的公式推导)
Xgboost的实战应用(这里用xgboost做一个分类任务,然后说一下基本使用和高级功能)
Ok, let's go!
2. Xgboost? 这个故事还得先从AdaBoost和GBDT说起
我觉得,学习一个算法的时候,有时候不能直接单拿出一个算法来说,这样感觉显得突兀了些,不知道突然从哪冒出来一样。所以,讲Xgboost之前,我想先带你回顾一下我们之前的集成学习。
所谓集成学习,就是指构建多个弱分类器对数据集进行预测,然后用某种策略将多个分类器预测的结果集成起来,作为最终预测结果。在这里就不再讲了(可以理解成集成学习是一种把大家伙叫到一块,集思广益想办法解决问题的方式吧),在这里想说的是集成学习的那两大流派:Boosting和Bagging。
怎么还有两个流派呢?集思广益不就完事?哈哈, 集思广益也有不同的方式吗?比如针对同一个问题,把问题划分成不相干的子问题,然后分派给不同的人各干各的是一种, 或者同一个问题,划分成串行的子问题, 先由一个人解决一部分,解决不了的,后面的人再来这又是一种。把上面这两种方式用官方的语言描述就是:根据各个弱分类器之间有无依赖关系,分为Boosting和Bagging。
Boosting流派,各分类器之间有依赖关系,必须串行,比如Adaboost、GBDT(Gradient Boosting Decision Tree)、Xgboost
Bagging流派,各分类器之间没有依赖关系,可各自并行,比如随机森林(Random Forest)
关于Bagging流派的Random Forest(随机森林)算法,也是比较常用的,简单的说就是各个弱分类器是独立的、每个分类器在样本堆里随机选一批样本,随机选一批特征进行独立训练,各个分类器之间没有啥关系, 最后投票表决, 这个在这里不做详述,后面遇到的时候再统一总结,今天的主角是Xgboost,所以我们主要是了解一下Boosting流派, 这这里面的最具代表性的算法之一就是AdaBoost, 这个我这里不做过多的表述,详细的可以看一下专栏之前的文章, 这里只回顾一下它的算法原理,这样好引出后面的GBDT和Xgboost,并且可以进行策略上的对比。
AdaBoost,是英文"Adaptive Boosting"(自适应增强),它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。白话的讲,就是它在训练弱分类器之前,会给每个样本一个权重,训练完了一个分类器,就会调整样本的权重,前一个分类器分错的样本权重会加大,这样后面再训练分类器的时候,就会更加注重前面分错的样本, 然后一步一步的训练出很多个弱分类器,最后,根据弱分类器的表现给它们加上权重,组合成一个强大的分类器,就足可以应付整个数据集了。 这就是AdaBoost, 它强调自适应,不断修改样本权重, 不断加入弱分类器进行boosting。
那么,boosting还有没有别的方式呢?GBDT(Gradient Boost Decision Tree)就是另一种boosting的方式, 上面说到AdaBoost训练弱分类器关注的是那些被分错的样本,AdaBoost每一次训练都是为了减少错误分类的样本。而GBDT训练弱分类器关注的是残差,也就是上一个弱分类器的表现与完美答案之间的差距,GBDT每一次训练分类器,都是为了减少这个差距,GBDT每一次的计算是都为了减少上一次的残差,进而在残差减少(负梯度)的方向上建立一个新的模型。这是什么意思呢? 我可以举个例子,假设我们去银行借钱,我们想让一个决策树系统来预测可以借给我们多少钱, 如果标准答案是1000的话,假设第一棵决策树预测,可以借给我们950块钱, 那么离标准答案的1000还差50, 效果不算好,能不能提高一些呢?我们就再加一棵决策树,这课决策树过来之后,看到前面的那个已经预测到950了,只是差50, 那么我可以聚焦在这个50上,把这个残差变得再小一些,所以第二个决策树预测结果是30, 那么前两棵决策树预测结果结合起来是980, 离标准答案差20, 所以加了一棵树之后,效果好了。那么还能不能提升呢?我再来一棵树,发现残差只有20了,那我把残差变得再小, 结果第三个决策树预测20, 那么这三棵树就可以正确的预测最终的1000了。
所以GBDT就是这样的一个学习方式了,GBDT是boosting集成学习,boosting集成学习由多个相关联的决策树联合决策, 什么是相关联?就是我上面的例子:
有一个样本[数据->标签]是:[(feature1,feature2,feature3)-> 1000块]
第一棵决策树用这个样本训练的预测为950
那么第二棵决策树训练时的输入,这个样本就变成了:[(feature1,feature2,feature3)->50]
第二棵决策树用这个样本训练的预测为30
那么第三棵决策树训练时的输入,这个样本就变成了:[(feature1,feature2,feature3)->20]
第三棵决策树用这个样本训练的预测为20
搞定,也就是说,下一棵决策树输入样本会与前面决策树的训练和预测相关。用个图来表示类似这样: 这就是GBDT的工作原理了, GBDT是旨在不断减少残差(回归),通过不断加入新的树旨在在残差减少(负梯度)的方向上建立一个新的模型。——即损失函数是旨在最快速度降低残差。
这就是GBDT的工作原理了, GBDT是旨在不断减少残差(回归),通过不断加入新的树旨在在残差减少(负梯度)的方向上建立一个新的模型。——即损失函数是旨在最快速度降低残差。
那么为啥要讲GBDT呢? 我先卖个关子,不妨先看一下xgboost是怎么解决问题的。这里用xgboost原作者陈天奇的讲座PPT中的那个图来看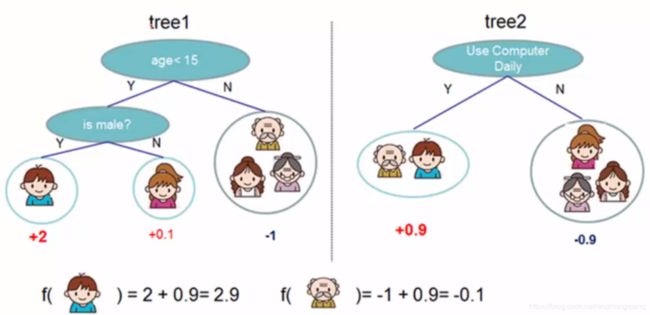 假设我想预测,这一家子人中每个人想玩游戏的意愿值。我们用xgboost解决这个问题,就是我先训练出来第一棵决策树, 预测了一下小男孩想玩游戏的意愿是2, 然后发现离标准答案差一些,又训练出来了第二棵决策树, 预测了一下小男孩想玩游戏的意愿是0.9, 那么两个相加就是最终的答案2.9。这个其实就接近了标准答案。所以xgboost是训练出来的弱分类结果进行累加就是最终的结论。
假设我想预测,这一家子人中每个人想玩游戏的意愿值。我们用xgboost解决这个问题,就是我先训练出来第一棵决策树, 预测了一下小男孩想玩游戏的意愿是2, 然后发现离标准答案差一些,又训练出来了第二棵决策树, 预测了一下小男孩想玩游戏的意愿是0.9, 那么两个相加就是最终的答案2.9。这个其实就接近了标准答案。所以xgboost是训练出来的弱分类结果进行累加就是最终的结论。
恩,你可能要拍案而起了,惊呼,这不是跟上面介绍的GBDT乃异曲同工么?事实上,如果不考虑工程实现、解决问题上的一些差异,xgboost与gbdt比较大的不同就是目标函数的定义,但这俩在策略上是类似的,都是聚焦残差(更准确的说, xgboost其实是gbdt算法在工程上的一种实现方式),GBDT旨在通过不断加入新的树最快速度降低残差,而XGBoost则可以人为定义损失函数(可以是最小平方差、logistic loss function、hinge loss function或者人为定义的loss function),只需要知道该loss function对参数的一阶、二阶导数便可以进行boosting,其进一步增大了模型的泛化能力,其贪婪法寻找添加树的结构以及loss function中的损失函数与正则项等一系列策略也使得XGBoost预测更准确。
所以,这就是我讲Xgboost的故事之前,要简单说一下AdaBoost和GBDT的原因了,这样脑海里面是不是对xgboost不那么陌生了啊,你要知道,这三个同是属于集成学习的boosting流派,AdaBoost叫做自适应提升,和GBDT,Xgboost提升时采用的策略不同,前者聚焦错误样本,后者聚焦与标准答案的残差。而GBDT和Xgboost叫做boosting集成学习,提升时策略类似,都是聚焦残差,但是降低残差的方式又各有不同。
好了,铺垫到此为止,下面真正进入主角部分 -- Xgboost的基本原理。
3. Xgboost的基本原理
Xgboost 的全称是eXtreme Gradient Boosting,由华盛顿大学的陈天奇博士提出,在Kaggle的希格斯子信号识别竞赛中使用,因其出众的效率与较高的预测准确度而引起了广泛的关注。
如果boosting算法每一步的弱分类器生成都是依据损失函数的梯度方向,则称之为梯度提升(Gradient boosting),XGBoost算法是采用分步前向加性模型,只不过在每次迭代中生成弱学习器后不再需要计算一个系数,XGBoost 是由 k 个基模型组成的一个加法运算式:
其中 为第k个基模型, 为第i个样本的预测值。那么损失函数可由预测值 与真实值 进行表示:
其中n为样本数量。
★XGBoost算法通过优化结构化损失函数(加入了正则项的损失函数,可以起到降低过拟合的风险)来实现弱学习器的生成,并且XGBoost算法没有采用搜索方法,而是直接利用了损失函数的一阶导数和二阶导数值,并通过预排序、加权分位数等技术来大大提高了算法的性能。
”
说到这里,估计你已经看不下去了吧,这说的啥跟啥啊, 听不懂啦啊!但其实我上面只是用数学的语言来说了一下前面举得xgboost的那个例子,对于某个样本,有若干个弱分类器做预测,最后的预测结果就是弱分类器的答案累加(注意此时没有权重了,如果你还记得AdaBoost模型的话,会发现那个地方每个分类器前面会有个权重 ,最终分类器是,不骗你哟), 这是上面的第一个公式,第二个公式就是说我怎么判断对于整个数据集预测的准不准啊,就得有个损失函数啊, 对比一下与真实值的差距,n个样本,我都对比一下子。这个 表示的某种损失函数,你可以先理解成平方差损失。
如此白话,应该能听懂了吧, 但还没真正讲xgboost的数学原理呢, 所以后面的数学原理我打算换一种方式,从一个例子展开,剖析数学公式,这里面就全是数学的原理了,如果你感觉直接上数学压力有点大,那么可以先跟着我继续往下,从一个例子中看看xgboost树到底是如何生成的,然后再回头看数学原理也不迟 ;)
下面就通过算法流程图举一个例子来详解xgboost树的生成。
先给出一个流程图, 不懂不要紧,可以看一遍后面的步骤,然后再回来: 为了让xgboost数学原理的部分不那么boring, 我们跟着一个例子走吧:
为了让xgboost数学原理的部分不那么boring, 我们跟着一个例子走吧:
★
假设我想预测学生考试分数, 给定若干个学生属性(比如天赋,每天学习时间,是否谈恋爱等),
通过一个决策树A, 我们可以看到一个天赋属性的预测结果:天赋高的人+90, 不高的人+60
通过决策树B, 可以看到每天学习时间高于10小时的+5,低于10小时的-5
通过决策树C, 可以看到谈恋爱的-1, 单身狗的+1
后面依次类推,还可能有更多的决策树通过学生的某些属性来推断分数。XGboost就是这样一个不断生成新的决策树A,B,C,D…的算法,最终生成的决策树算法就是树A+B+C+D+…的和的决策树。
”
我们针对这个问题看看详细的建树过程吧:
首先,我们有三个学生, 属性和标签如下:
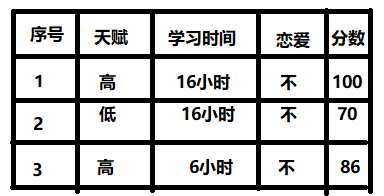 我们初始化三个样本的考试成绩预测值为0。
我们初始化三个样本的考试成绩预测值为0。定义目标函数:模型的预测精度由偏差和方差共同决定,损失函数代表了模型的偏差,想要方差小则需要更简单的模型, 所以目标函数最终由损失函数L与抑制模型复杂度的正则项Ω组成, 所以目标函数如下:
这个公式应该不需要过多的解释了吧, 其中 是正则化项
前面的 为叶子节点数, 表示j叶子上的节点权重, , 是预先给定的超参数。引入了正则化之后,算法会选择简单而性能优良的模型, 正则化项只是用来在每次迭代中抑制弱分类器 过拟合,不参与最终模型的集成。(这个正则化项可以先不用管它, 有个印象即可,后面树那个地方会统一解释)
我们下面看看这个目标函数 还能不能化简呢?
我们知道, boosting模型是前向加法, 以第t步模型为例, 模型对第i个样本 的预测为:
其中, 是第t-1步的模型给出的预测值, 是已知常数, 是我们这次需要加入的新模型,所以把这个 代入上面,就可以进一步化简:
这个就是xgboost的目标函数了,最优化这个目标函数,其实就是相当于求解当前的 。Xgboost系统的每次迭代都会构建一颗新的决策树,决策树通过与真实值之间残差来构建。什么,没有看到残差的身影?别急,后面会看到这个残差长什么样子。
我们回到我们的例子,假设已经根据天赋这个属性建立了一棵决策树A(关于如何建树在这里不做解释,可以看看[白话机器学习算法理论+实战之决策树]),只不过这里的树分裂计算收益的方式换了一种,后面会具体说到。
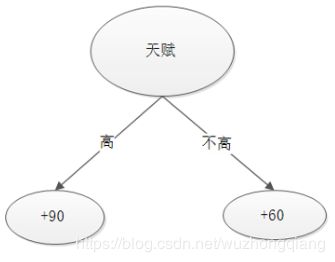 我们有了第一棵树, 通过这个树的预测结果:
我们有了第一棵树, 通过这个树的预测结果: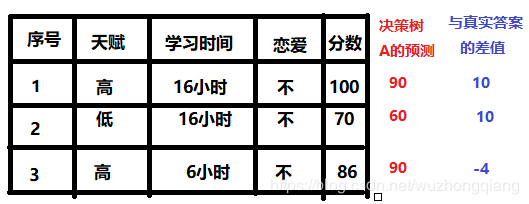 那么我们建立第二棵树的时候,我们是考虑的残差,也就是样本其实变成了下面这样:
那么我们建立第二棵树的时候,我们是考虑的残差,也就是样本其实变成了下面这样: 通过最小化残差学习到一个通过学习时间属性构建的决策树得到了90+5,60+5,90-5的预测值,再继续通过(100-95=5)(70-65)(86-85)的残差构建下一个决策树,以此类推,当迭代次数达到上限或是残差不再减小是停止,就得到一个拥有多个(迭代次数)决策树的强分类器。这个就是xgboost工作的宏观过程了。光宏观部分确实挺好理解,但具体细节呢?比如我每一次建树是怎么建的呢?既然说计算收益的方式不同, 那么我考虑分裂的时候是怎么计算收益的呢?目前你心中肯定会有这些疑问, 莫慌莫慌, 下面我把建树的细节给你娓娓道来,不过道来的过程中得崎岖一点,需要用到数学的语言。
通过最小化残差学习到一个通过学习时间属性构建的决策树得到了90+5,60+5,90-5的预测值,再继续通过(100-95=5)(70-65)(86-85)的残差构建下一个决策树,以此类推,当迭代次数达到上限或是残差不再减小是停止,就得到一个拥有多个(迭代次数)决策树的强分类器。这个就是xgboost工作的宏观过程了。光宏观部分确实挺好理解,但具体细节呢?比如我每一次建树是怎么建的呢?既然说计算收益的方式不同, 那么我考虑分裂的时候是怎么计算收益的呢?目前你心中肯定会有这些疑问, 莫慌莫慌, 下面我把建树的细节给你娓娓道来,不过道来的过程中得崎岖一点,需要用到数学的语言。
那么究竟是如何得到一棵新的树的呢?下面就是Xgboost的精髓了。前方高能,一大波数学公式来袭, 请戴好安全帽!!!
目标函数的Taylor化简:这是Xgboost的精髓了。我们首先看一个关于目标函数的简单等式变换, 把上面的目标函数拿过来:
我们看看这里的 ,这个部分,如果结合伟大的Taylor的话,会发生什么情况,你还记得泰勒吗?
★在这里插入图片描述 ”
根据Taylor公式, 我们把函数 在点 处二阶展开,可得到:
那么我们把 中的 视为 , 视为 , 那么目标函数就可以写成:
其中 是损失函数 的一阶导数, 是损失函数 的二阶导, 注意这里的求导是对 求导。
★这里我们以平方损失函数为例:
”
★则对于每一个样本:
”
由于在第t步时 是一个已知的值, 所以 是一个常数,其对函数的优化不会产生影响, 因此目标函数可以进一步写成:
所以我们只需要求出每一步损失函数的一阶导和二阶导的值(由于前一步的 是已知的,所以这两个值就是常数),然后最优化目标函数,就可以得到每一步的 f(x) ,最后根据加法模型得到一个整体模型。
但是还有个问题,就是我们如果是建立决策树的话,根据上面的可是无法建立出一棵树来。因为这里的 是什么鬼? 咱不知道啊!所以啊,还得进行一步映射, 将样本x映射到一个相对应的叶子节点才可以,看看是怎么做的?
基于决策树的目标函数的终极化简上面的目标函数先放下来:
我们这里先解决一下这个 的问题,这个究竟怎么在决策树里面表示呢?那解决这个问题之前,我们看看这个 表示的含义是什么, 就是我有一个决策树模型, 是每一个训练样本,那么这个整体 就是我某一个样本 经过决策树模型 得到的一个预测值,对吧?那么,我如果是在决策树上,可以这么想, 我的决策树就是这里的 , 然后对于每一个样本 ,我要在决策树上遍历获得预测值,其实就是在遍历决策树的叶子节点,因为每个样本最终通过决策树都到了叶子上去, 不信?看下图(样本都在叶子上, 只不过这里要注意一个叶子上不一定只有一个样本):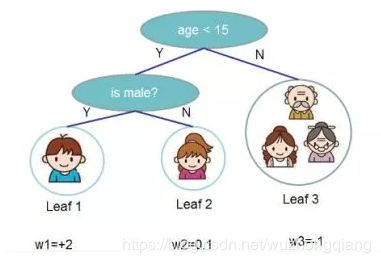 所以,通过决策树遍历样本,其实就是在遍历叶子节点。这样我们就可以把问题就行转换,把决策树模型定义成 , 其中 代表了该样本在哪个叶子节点上, 表示该叶子节点上的权重(上面分数预测里面+90, +60就是叶子节点的权重)。所以 就代表了每个样本的取值(预测值)。 那么这个样本的遍历,就可以这样化简:
所以,通过决策树遍历样本,其实就是在遍历叶子节点。这样我们就可以把问题就行转换,把决策树模型定义成 , 其中 代表了该样本在哪个叶子节点上, 表示该叶子节点上的权重(上面分数预测里面+90, +60就是叶子节点的权重)。所以 就代表了每个样本的取值(预测值)。 那么这个样本的遍历,就可以这样化简:
这个再解释一遍就是:遍历所有的样本后求每个样本的损失函数,但样本最终会落在叶子节点上,所以我们也可以遍历叶子节点,然后获取叶子节点上的样本集合(注意第二个等式和第三个等式求和符号的上下标, T代表叶子总个数)。 由于一个叶子节点有多个样本存在,所以后面有了 和 这两项,这里的 它代表一个集合,集合中每个值代表一个训练样本的序号,整个集合就是某棵树第j个叶子节点上的训练样本 , 为第j个叶子节点的取值。只要明白了这一步,后面的公式就很容易理解了。
我们再解决一下后面那部分,在决策树中,决策树的复杂度可由叶子数 T 组成,叶子节点越少模型越简单,此外叶子节点也不应该含有过高的权重 w (类比 LR 的每个变量的权重),所以目标函数的正则项可以定义为:
即决策树模型的复杂度由生成的所有决策树的叶子节点数量( 权衡),和所有节点权重( 权衡)所组成的向量的 范式共同决定。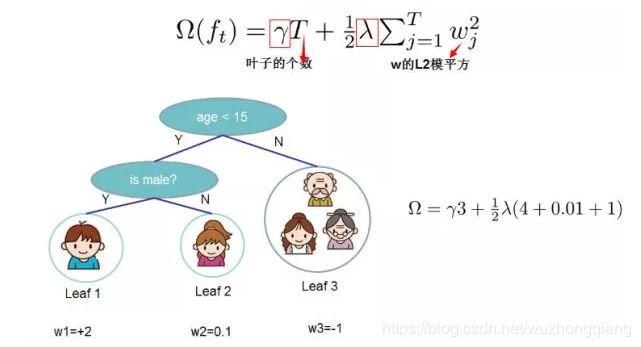 这张图给出了基于决策树的 XGBoost 的正则项的求解方式。
这张图给出了基于决策树的 XGBoost 的正则项的求解方式。
这样,目标函数的前后两部分都进行了解决,那么目标函数就可以化成最后这个样子,看看能懂吗?
这里的 为第j个叶子节点的样本集合。为了简化表达式,我们再定义:, 那么决策树版本xgboost的目标函数:
这里要注意 和 是前t-1步得到的结果, 其值已知,只有最后一棵树的叶子节点 的值不确定, 那么将目标函数对 求一阶导, 并令其等于0, , 则可以求得叶子节点j对应的权值:
那么这个目标函数又可以进行化简:
这个就是基于决策树的xgboost模型的目标函数最终版本了,这里的G和H的求法,就需要明确的给出损失函数来, 然后求一阶导和二阶导,然后代入样本值即得出。
这个 代表了当我们指定一个树的结构的时候,我们在目标上最多能够减少多少,我们之前不是说建立一个树就是让残差尽可能的小吗?到底小多少呢?这个 就是衡量这个的, 可以叫做结构分数。就类似于基尼系数那样对树结构打分的一个函数。那么这个分数怎么算呢?看下面的例子:
★”
还是上面的那个预测玩游戏的意愿,我们假设建了右边的那棵树,那么每个样本都对应到了叶子节点上去,每一个样本都会对应一个g和h, 那么我们遍历叶子节点,就会得到G和H,然后累加就可以得到这棵树的结构分数obj(这里有个小细节就是假设有N个训练样本, 那么就会有N次计算各自的 和 , 但是由于每个样本的 和 没有啥关系,所以可以并行计算,这样就可以加速训练了,而且, 和 是不依赖于损失函数的形式的,只要这个损失函数二次可微就可以了, emmm...powerful)。
有了这个,我们就知道这棵树建的好不好了。
上面是可以判断出来一棵树究竟好不好,那么建立树的时候应该怎么建立呢?一棵树的结构近乎无限多,总不能一个一个去测算它们的好坏程度,然后再取最好的吧(这是个NP问题)。所以,我们仍然需要采取一点策略,这就是逐步学习出最佳的树结构。这与我们将K棵树的模型分解成一棵一棵树来学习是一个道理,只不过从一棵一棵树变成了一层一层节点而已。这叫什么?emmm, 贪心(找到每一步最优的分裂结果)!xgboost采用二叉树, 开始的时候, 全部样本在一个叶子节点上, 然后叶子节点不断通过二分裂,逐渐生成一棵树。
那么在叶子节点分裂成树的过程中最关键的一个问题就是应该在哪个特征的哪个点上进行分裂,也就是寻找最优切分点的过程。
最优切分点划分算法及优化策略在决策树的生长过程中,一个非常关键的问题是如何找到节点的最优切分点, 我们学过了决策树的建树过程,那么我们知道ID3也好,C4.5或者是CART,它们寻找最优切分点的时候都有一个计算收益的东西,分别是信息增益,信息增益比和基尼系数。而xgboost这里的切分, 其实也有一个类似于这三个的东西来计算每个特征点上分裂之后的收益。
★
假设我们在某一节点完成特征分裂,则分列前的目标函数可以写为:
分裂后的目标函数:
则对于目标函数来说,分裂后的收益为(Obj1-Obj2):
”注意该特征收益也可作为特征重要性输出的重要依据。
那么我们就可以来梳理一下最优切分点的划分算法了:
从深度为 0 的树开始,对每个叶节点枚举所有的可用特征;
针对每个特征,把属于该节点的训练样本根据该特征值进行升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的分裂收益;(这个过程每个特征的收益计算是可以并行计算的,xgboost之所以快,其中一个原因就是因为它支持并行计算,而这里的并行正是指的特征之间的并行计算,千万不要理解成各个模型之间的并行)
选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,在该节点上分裂出左右两个新的叶节点,并为每个新节点关联对应的样本集(这里稍微提一下,xgboost是可以处理空值的,也就是假如某个样本在这个最优分裂点上值为空的时候, 那么xgboost先把它放到左子树上计算一下收益,再放到右子树上计算收益,哪个大就把它放到哪棵树上。)
回到第 1 步,递归执行到满足特定条件为止
上面就是最优切分点划分算法的过程, 看完之后,是不是依然懵逼, 这到底是怎么做的啊, 下面就看一个寻找最优切分点的栗子吧:
还是上面玩游戏的那个例子,假设我有这一家子人样本,每个人有性别,年龄,兴趣等几个特征,我想用xgboost建立一棵树预测玩游戏的意愿值。首先,五个人都聚集在根节点上,现在就考虑根节点分叉,我们就遍历每个特征,对于当前的特征,我们要去寻找最优切分点以及带来的最大收益,比如当前特征是年龄,我们需要知道两点:* 按照年龄分是否有效,也就是是否减少了obj的值* 如果真的可以分,特征收益比较大, 那么我们从哪个年龄点分开呢?
对于这两个问题,我们可以这样做,首先我们先把年龄进行一个排序, 如下图: 按照这个图从左至右扫描,我们就可以找出所有的切分点a, 对于每一个切分点a,计算出分割的梯度和 和 。然后用上面的公式计算出每个分割方案的分数。然后哪个最大,就是年龄特征的最优切分点,而最大值就是年龄这个特征的最大信息收益。
按照这个图从左至右扫描,我们就可以找出所有的切分点a, 对于每一个切分点a,计算出分割的梯度和 和 。然后用上面的公式计算出每个分割方案的分数。然后哪个最大,就是年龄特征的最优切分点,而最大值就是年龄这个特征的最大信息收益。
遍历完所有特征后,我们就可以确定应该在哪个特征的哪个点进行切分。对切分出来的两个节点,递归地调用这个过程,我们就能获得一个相对较好的树结构, 有了树结构就比较容易找最优的叶子节点,这样就能对上面的样本进行预测了。当然,特征与特征之间的收益计算是互不影响的,所以这个遍历特征的过程其实可以并行运行。
在这个过程中你是否注意到了一个问题, 就是xgboost的切分操作和普通的决策树切分过程是不一样的。普通的决策树在切分的时候并不考虑树的复杂度,所以才有了后续的剪枝操作。而xgboost在切分的时候就已经考虑了树的复杂度(obj里面看到那个 了吗)。所以,它不需要进行单独的剪枝操作。
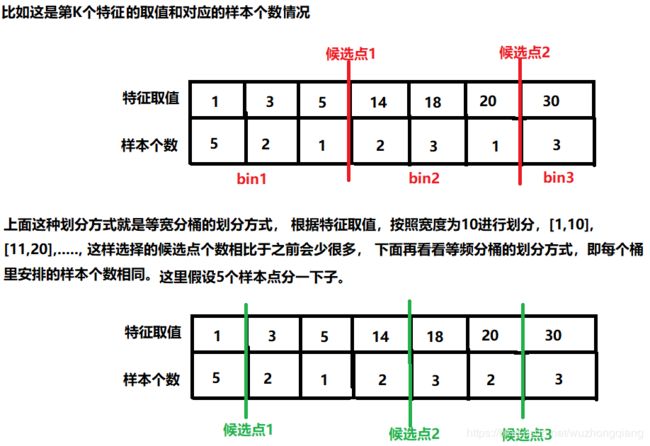
这就是xgboost贪心建树的一个思路了,即遍历所有特征以及所有分割点,每次选最好的那个。GBDT也是采用的这种方式, 这算法的确不错,但是有个问题你发现了没?就是计算代价太大了,尤其是数据量很大,分割点很多的时候,计算起来非常复杂并且也无法读入内存进行计算。所以作者想到了一种近似分割的方式(可以理解为分割点分桶的思路),选出一些候选的分裂点,然后再遍历这些较少的分裂点来找到最佳分裂点。那么怎么进行分桶选候选分裂点才比较合理呢?我们一般的思路可能是根据特征值的大小直接进行等宽或者等频分桶, 像下面这样(这个地方理解起来有点难,得画画了,图可能不太好看,能说明问题就行,哈哈):
 在这里插入图片描述
在这里插入图片描述
上面就是等频和等宽分桶的思路了(这个不用较真,我这里只是为了和作者的想法产生更清晰的对比才这样举得例子),这样选择出的候选点是不是比就少了好多了?但是这样划分其实是有问题的,因为这样划分没有啥依据啊, 比如我上面画的等频分桶,我是5个训练样本放一个桶,但是你说你还想10个一组来,没有个标准啥的啊。即上面那两种常规的划分方式缺乏可解释性,所以重点来了, 作者这里采用了一种对loss的影响权重的等值percentiles(百分比分位数)划分算法(Weight Quantile Sketch), 我上面的这些铺垫也正是为了引出这个方式,下面就来看看作者是怎么做的,这个地方其实不太好理解,所以慢一些
作者进行候选点选取的时候,考虑的是想让loss在左右子树上分布的均匀一些,而不是样本数量的均匀,因为每个样本对降低loss的贡献可能不一样,按样本均分会导致分开之后左子树和右子树loss分布不均匀,取到的分位点会有偏差。这是啥意思呢?再来一个图(这个图得看明白了): 这其实就是作者提出的那种找候选节点的方式(分桶的思路),明白了这个图之后,下面就是解释一下上面这个图的细节:第一个就是 是啥?它为啥就能代表样本对降低loss的贡献程度? 第二个问题就是这个bin是怎么分的,为啥是0.6一个箱?
这其实就是作者提出的那种找候选节点的方式(分桶的思路),明白了这个图之后,下面就是解释一下上面这个图的细节:第一个就是 是啥?它为啥就能代表样本对降低loss的贡献程度? 第二个问题就是这个bin是怎么分的,为啥是0.6一个箱?
下面从第一个问题开始,揭开 的神秘面纱, 其实 上面已经说过了,损失函数在样本 处的二阶导数啊!还记得开始的损失函数吗?
就是这个 , 那么你可能要问了, 为啥它就能代表第 个样本的权值啊?这里再拓展一下吧,我们在引出xgboost的时候说过,GBDT这个系列都是聚焦在残差上面,但是我们单看这个目标函数的话并没有看到什么残差的东西对不对?其实这里这个损失函数还可以进一步化简的(和上面的化简不一样,上面的化简是把遍历样本转到了遍历叶子上得到基于决策树的目标函数,这里是从目标函数本身出发进行化简):
这样化简够简洁明了了吧, 你看到残差的身影了吗?后面的每一个分类器都是在拟合每个样本的一个残差 , 其实把上面化简的平方损失函数拿过来就一目了然了。而前面的 可以看做计算残差时某个样本的重要性,即每个样本对降低loss的贡献程度。第一个问题说的听清楚了吧 ;)
PS:这里加点题外话,Xgboost引入了二阶导之后,相当于在模型降低残差的时候给各个样本根据贡献度不同加入了一个权重,这样就能更好的加速拟合和收敛,GBDT只用到了一阶导数,这样只知道梯度大的样本降低残差效果好,梯度小的样本降低残差不好(这个原因我会放到Lightgbm的GOSS那里说到),但是好与不好的这个程度,在GBDT中无法展现。而xgboost这里就通过二阶导可以展示出来,这样模型训练的时候就有数了。
下面再解释第二个问题,这个分箱是怎么分的?比如我们定义一个数据集代表每个训练样本的第 个特征的取值和二阶梯度值,那么我们可以有一个排名函数 :
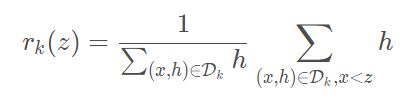
这里的 代表特征值小于 的那些样本。这个排名函数表示特征值小于z的样本的贡献度比例。假设上面图中,z是第一个候选点,那么 , 这个东西的目的就是去找相对准确的候选点 , 这里的, 而相邻两个桶之间样本贡献度的差距应满足下面这个函数:
这个 控制每个桶中样本贡献度比例的大小,其实就是贡献度的分位点。我们自己设定。比如在上面图中我们设置了 , 这意味着每个桶样本贡献度的比例是1/3(贡献度的1/3分位点), 而所有的样本贡献度总和是1.8, 那么每个箱贡献度是0.6( ),分为3( )个箱, 上面这些公式看起来挺复杂,可以计算起来很简单,就是计算一下总的贡献度, 然后指定 , 两者相乘得到每个桶的贡献度进行分桶即可。这样我们就可以确定合理的候选切分点,然后进行分箱了。
到这终于把这一块描述完了, 有点多,稍微理一理逻辑,前面那一部分是围绕着如何建立一棵树进行的,即采用贪心的方式从根节点开始一层层的建立树结构(每一层争取最优),然后就是建树过程中一个关键的问题:如何寻找最优切分点,给出了最优切分点算法,基于这个算法就可以建立树了。后面这一部分是一个优化的过程,提出了一种Weight Quantile Sketch的算法,这个算法可以将原来的分割点进行分桶,然后找到合适的候选分裂点,这样可以减少遍历时尝试的分裂点的数量,是xgboost相比于GBDT做出的切分点优化策略,现在知道为啥xgboost要快了吧,因为xgboost寻找切分点的时候不用遍历所有的,而是只看候选点就可以了。而且在特征上,xgboost是可以并行处理的。这样xgboost的建树过程及优化策略基本上就是这些了,当然这里面还有很多的细节,由于篇幅的原因就不写在这里了。
利用新的决策树预测样本值,并累加到原来的值上若干个决策树是通过加法训练的, 所谓加法训练,本质上是一个元算法,适用于所有的加法模型,它是一种启发式算法。运用加法训练,我们的目标不再是直接优化整个目标函数,而是分步骤优化目标函数,首先优化第一棵树,完了之后再优化第二棵树,直至优化完K棵树。整个过程如下图所示:
 在这里插入图片描述
在这里插入图片描述
上图中会发现每一次迭代得到的新模型前面有个 (这个是让树的叶子节点权重乘以这个系数), 这个叫做收缩率,这个东西加入的目的是削弱每棵树的作用,让后面有更大的学习空间,有助于防止过拟合。也就是,我不完全信任每一个残差树,每棵树只学到了模型的一部分,希望通过更多棵树的累加来来弥补,这样让这个让学习过程更平滑,而不会出现陡变。这个和正则化防止过拟合的原理不一样,这里是削弱模型的作用,而前面正则化是控制模型本身的复杂度。
好了, 到这里为止,xgboost的数学原理部分就描述完了,希望我描述清楚了吧。简单的回顾一下上面的过程吧: xgboost是好多弱分类器的集成,训练弱分类器的策略就是尽量的减小残差,使得答案越来越接近正确答案。xgboost的精髓部分是目标函数的Taylor化简,这样就引入了损失函数的一阶和二阶导数。然后又把样本的遍历转成了对叶子节点的遍历,得到了最终的目标函数。这个函数就是衡量一棵树好坏的标准。在建树过程中,xgboost采用了贪心策略,并且对寻找分割点也进行了优化。基于这个,才有了后面的最优点切分建立一棵树的过程。xgboost训练的时候,是通过加法进行训练,也就是每一次只训练一棵树出来, 最后的预测结果是所有树的加和表示。
关于xgboost,依然还有很多的细节没有说到,具体的去看论文吧。下面,我们就进行xgboost的实战部分, 这里我们简单的做一个分类任务, 主要是看看xgboost主要怎么用, 尤其是在一个数据竞赛中(这次重点总结了一些用法)。
3. Xgboost实战二分类
安装:默认可以通过pip安装,若是安装不上可以通过:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
网站下载相关安装包,将安装包拷贝到Anacoda3的安装目录的Scrripts目录下, 然后pip install 安装包安装
3.1 xgboost的基本使用
Xgboost参数说明页面:
https://xgboost.readthedocs.io/en/latest/parameter.html
Xgboost调参官方指南
https://xgboost.readthedocs.io/en/latest/tutorials/param_tuning.html
我们使用xgboost做一个分类任务,可以直接使用xgboost。
# 0 1:1 9:1 19:1 21:1 24:1 34:1 36:1 39:1 42:1 53:1 56:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 117:1 122:1
# 1 3:1 9:1 19:1 21:1 30:1 34:1 36:1 40:1 41:1 53:1 58:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 118:1 124:1
# 0 1:1 9:1 20:1 21:1 24:1 34:1 36:1 39:1 41:1 53:1 56:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 117:1 122:1
# 0 3:1 9:1 19:1 21:1 24:1 34:1 36:1 39:1 51:1 53:1 56:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 116:1 122:1
# 0 4:1 7:1 11:1 22:1 29:1 34:1 36:1 40:1 41:1 53:1 58:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 105:1 119:1 124:1
# 0 3:1 10:1 20:1 21:1 23:1 34:1 37:1 40:1 42:1 54:1 55:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 118:1 126:1
# 1 3:1 9:1 11:1 21:1 30:1 34:1 36:1 40:1 51:1 53:1 58:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 117:1 124:1
"""上面是libsvm的数据存储格式, 也是一种常用的格式,存储的稀疏数据。
第一列是label. a:b a表示index, b表示在该index下的数值, 这就类似于one-hot"""
import numpy as np
import scipy.sparse # 稀疏矩阵的处理
import pickle
import xgboost as xgb
# libsvm format data 的读入方式, 直接用xgb的DMatrix
dtrain = xgb.DMatrix('./xgbdata/agaricus.txt.train')
dtest = xgb.DMatrix('./xgbdata/agaricus.txt.test')
下面我们进行参数设置:关于xgboost的参数,详细的可以看上面的参数说明,这里拿分类器来说,解释一些参数:
★xgb1 = XGBClassifier( learning_rate =0.1, n_estimators=1000, max_depth=5, min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27)
”
'booster':'gbtree', 这个指定基分类器
'objective': 'multi:softmax', 多分类的问题, 这个是优化目标,必须得有,因为xgboost里面有求一阶导数和二阶导数,其实就是这个。
'num_class':10, 类别数,与 multisoftmax 并用
'gamma':损失下降多少才进行分裂, 控制叶子节点的个数
'max_depth':12, 构建树的深度,越大越容易过拟合
'lambda':2, 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample':0.7, 随机采样训练样本
'colsample_bytree':0.7, 生成树时进行的列采样
'min_child_weight':3, 孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束
'silent':0 ,设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, 如同学习率
'seed':1000,
'nthread':7, cpu 线程数
当然不需要全记住,常用的几个记住即可。可以结合着上面的数学原理,看看哪个参数到底对于xgboost有什么作用,这样利于调参。设置好参数,训练测试就行了,使用起来和sklearn的模型非常像
"""paramet setting"""
param = {
'max_depth': 2,
'eta': 1,
'silent': 1,
'objective': 'binary:logistic'
}
watch_list = [(dtest, 'eval'), (dtrain, 'train')] # 这个是观测的时候在什么上面的结果 观测集
num_round = 5
model = xgb.train(params=param, dtrain=dtrain, num_boost_round=num_round, evals=watch_list)
然后就是预测:
"""预测"""
pred = model.predict(dtest) # 这里面表示的是正样本的概率是多少
from sklearn.metrics import accuracy_score
predict_label = [round(values) for values in pred]
accuracy_score(labels, predict_label) # 0.993
模型的保存了解一下:
"""两种方式: 第一种, pickle的序列化和反序列化"""
pickle.dump(model, open('./model/xgb1.pkl', 'wb'))
model1 = pickle.load(open('./model/xgb1.pkl', 'rb'))
model1.predict(dtest)
"""第二种模型的存储与导入方式 - sklearn的joblib"""
from sklearn.externals import joblib
joblib.dump(model, './model/xgb.pkl')
model2 = joblib.load('./model/xgb.pkl')
model2.predict(dtest)
3.2 交叉验证 xgb.cv
# 这是模型本身的参数
param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic'}
num_round = 5 # 这个是和训练相关的参数
xgb.cv(param, dtrain, num_round, nfold=5, metrics={'error'}, seed=3)
3.3 调整样本权重
这个是针对样本不平衡的情况,可以在训练时设置样本的权重, 训练的时候设置fpreproc这个参数, 相当于在训练之前先对样本预处理。
# 这个函数是说在训练之前,先做一个预处理,计算一下正负样本的个数,然后加一个权重,解决样本不平衡的问题
def preproc(dtrain, dtest, param):
labels = dtrain.get_label()
ratio = float(np.sum(labels==0)) / np.sum(labels==1)
param['scale_pos_ratio'] = ratio
return (dtrain, dtest, param)
# 下面我们在做交叉验证, 指明fpreproc这个参数就可以调整样本权重
xgb.cv(param, dtrain, num_round, nfold=5, metrics={'auc'}, seed=3, fpreproc=preproc)
3.4 自定义目标函数(损失函数)
如果在一个比赛中,人家给了自己的评判标准,那么这时候就需要用人家的这个评判标准,这时候需要修改xgboost的损失函数, 但是这时候请注意一定要提供一阶和二阶导数
# 自定义目标函数(log似然损失),这个是逻辑回归的似然损失。 交叉验证
# 注意: 需要提供一阶和二阶导数
def logregobj(pred, dtrain):
labels = dtrain.get_label()
pred = 1.0 / (1+np.exp(-pred)) # sigmoid函数
grad = pred - labels
hess = pred * (1-pred)
return grad, hess # 返回一阶导数和二阶导数
def evalerror(pred, dtrain):
labels = dtrain.get_label()
return 'error', float(sum(labels!=(pred>0.0)))/len(labels)
训练的时候,把损失函数指定就可以了:
param = {'max_depth':2, 'eta':1, 'silent':1}
# 自定义目标函数训练
model = xgb.train(param, dtrain, num_round, watch_list, logregobj, evalerror)
# 交叉验证
xgb.cv(param, dtrain, num_round, nfold=5, seed=3, obj=logregobj, feval=evalerror)
3.5 用前n棵树做预测 ntree_limit
太多的树可能发生过拟合,这时候我们可以指定前n棵树做预测, 预测的时候设置ntree_limit这个参数
# 前1棵
pred1 = model.predict(dtest, ntree_limit=1)
evalerror(pred2, dtest)
3.6 画出特征重要度 plot_importance
from xgboost import plot_importance
plot_importance(model, max_num_features=10)
3.7 同样,也可以用sklearn的GridSearchCV调参
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(x_train, y_train)
print("best: %f using %s" %(grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean, param in zip(means, params):
print("%f with: %r" % (mean, param))
好了,实战部分就整理这么多吧, 重点在于怎么使用,xgboost使用起来和sklearn的模型也是非常像, 也是.fit(), .predict()方法,只不过xgboost的参数很多,这个调起来会比较复杂, 但是懂了原理之后,至少每个参数是干啥的就了解了,关于调参的技术, 得从经验中多学习,多尝试,多总结才能慢慢修炼出来。
4. 总结
哇,终于完了,到这里,终于把xgboost的一些知识说清楚了, 每一次不知不觉就会这么多字, 可能是因为这个算法太重要了吧,所以多写了点, 赶紧回顾一下:首先, 我们从集成算法开始讲起,回顾了一下AdaBoost,GBDT, 然后引出了xgboost, 我们知道同属boosting流派,但集成策略又有不同, 即使集成策略类似,那么得到最后结果的方式又不同。但对比之中,我们能更加体会它们的原理。其次,我们从数学原理的角度剖析了一下xgboost, 看到了它的目标函数,看到了如何生成一棵树,看到了如何Taylor化简,知道了为什么需要损失函数的一二阶导数,也明白了为啥这个算法这么快。最后,我们通过实战一个二分类问题,见识到了xgboost的代码实现,基本使用和一些高级策略。
下面看看xgboost相比于GBDT有哪些优点(面试的时候可能会涉及):
精度更高:GBDT只用到一阶泰勒, 而xgboost对损失函数进行了二阶泰勒展开, 一方面为了增加精度, 另一方面也为了能够自定义损失函数,二阶泰勒展开可以近似大量损失函数
灵活性更强:GBDT以CART作为基分类器,而Xgboost不仅支持CART,还支持线性分类器,另外,Xgboost支持自定义损失函数,只要损失函数有一二阶导数。
正则化:xgboost在目标函数中加入了正则,用于控制模型的复杂度。有助于降低模型方差,防止过拟合。正则项里包含了树的叶子节点个数,叶子节点权重的L2范式。
Shrinkage(缩减):相当于学习速率。这个主要是为了削弱每棵树的影响,让后面有更大的学习空间,学习过程更加的平缓
列抽样:这个就是在建树的时候,不用遍历所有的特征了,可以进行抽样,一方面简化了计算,另一方面也有助于降低过拟合
缺失值处理:这个是xgboost的稀疏感知算法,加快了节点分裂的速度
并行化操作:块结构可以很好的支持并行计算
上面的这些优点,我在描述的时候基本上都涉及到了,正是因为xgboost有了这些优点,才让它变得非常火,堪称神器了现在,但是xgboost真的perfect了吗?正所谓金无足赤,人无完人, xgboost也同样如此,比如虽然利用了预排序和近似算法可以降低寻找最优分裂点的计算量,但在节点分裂过程中仍需要遍历整个数据集。预排序过程的空间复杂度过高,不仅需要存储特征值,还需要存储特征对应样本梯度统计值的索引,相当于消耗了两倍的内存。所以在内存和计算方面还是有很大的优化空间的。那么xgboost还可以在哪些角度进行优化呢?后面通过lightgbm的故事再说给你听 ;)
xgboost的故事就先讲到这里了,希望对你有所帮助,当然还有很多的细节没有提到,本文只是抛砖引玉,具体的建议去看看原文,毕竟这个算法还是超级重要的,面试的时候也会抠得很细, 不看原文的话有些精华get不到。
参考:
xgboost论文原文 - 权威经典 : https://arxiv.org/pdf/1603.02754.pdf
Adaboost、GBDT与XGBoost的区别: https://blog.csdn.net/hellozhxy/article/details/82143554
xgboost算法详细介绍(通过简单例子讲述): https://blog.csdn.net/wufengqi7585/article/details/86078049
Introduction to Boosted Trees: https://xgboost.readthedocs.io/en/latest/tutorials/model.html
终于有人把XGBoost 和 LightGBM 讲明白了,项目中最主流的集成算法!:https://mp.weixin.qq.com/s/q4R-TAG4PZAdWLb41oov8g
xgboost的原理没你想像的那么难: https://www.jianshu.com/p/7467e616f227
XGBoost算法的原理详析[文献阅读笔记]: https://zhuanlan.zhihu.com/p/90520307
XGBoost原理介绍: https://blog.csdn.net/yinyu19950811/article/details/81079192
灵魂拷问,你看过Xgboost原文吗?: https://zhuanlan.zhihu.com/p/86816771
一文读懂机器学习大杀器XGBoost原理: https://zhuanlan.zhihu.com/p/40129825
喜欢您就点个在看!