【西瓜书+花书】速通
参考:BV1qY4y187Ff
第一部分:机器学习
回归算法
1. 机器学习概述
数据挖掘:大规模机器学习算法去计算用户情况
计算机视觉:无人驾驶汽车
推荐算法
……
预测样本->特征抽取(转换成计算机能够理解的数据,重要!提取特征)->学习函数->预测
实用工具:Numpy科学计算 pandas数据分析 matplotlib数据可视化 scikit-learn机器学习
2. 回归算法
监督学习(有标签)、无监督学习(无标签)
回归:要预测出一个具体的值!就是回归问题,比如银行根据你的具体情况判断能借你多少额度
分类:结果是类别,比如银行能借钱不能借钱

学习就是学权重参数,来判断每个数据的权重大小,就是每个数据对结果的影响程度
每个x前面乘以一个θ作为权重,让x对结果的影响处于一个正确的位置,
令x0=1,θ0x0+θ1x1+θ2x2 = θ0+θ1x1+θ2x2,那么就可以把他们写成矩阵相乘形式了
就是[θ0,θ1,θ2]*[x0,x1,x2]相当于wx(这里的w和x都是矩阵向量的形式)
这里额度是标签,工资年龄都是样本数据
3/4. 线性回归误差
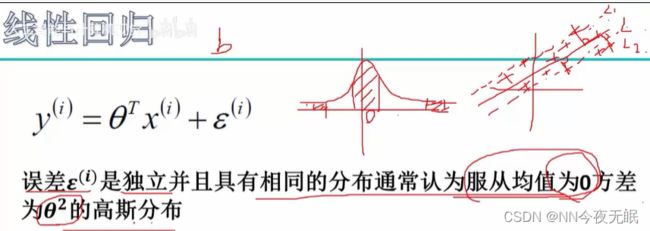
就是说,本来是y=θx,但是呢,有时候,真实值不可能刚刚好是θx算出来的值,可能偏大偏小,所以我们要加一项偏置bias,这样预测才会准一点
那么偏置具体要是多少才ok呢? 首先,bias是独立同分布的,因为每次的预测样本不会互相影响所以是独立的。然后一般离散的样本数据够大就是服从高斯分布(就是正态分布)
那么怎样的高斯分布好呢?我们就要调整这个bias,让所有值的偏离基本服从均值为0方差为θ平方的高斯分布。
那么,怎么求bias呢?
我们通过已知条件“偏离基本服从均值为0方差为θ平方的高斯分布”,可以得出以下式子,开始化简!

第一个式子:p(epsilon) 就是高斯分布,均值μ等于0所以不写。
第二个式子:用左边的式子化出epsilon(e = y-θx)带入第一个式子,得到第二个式子,就化掉了所有epsilon,然后就变成了p与y/x/θ的关系了,即什么样的θ和x组合完之后,越接近y的概率
概率越大越好了(因为带进去的是y-θx,这个表示的就是y和θx的距离,y和θx的距离越小,越接近,y-θx就越小,前面加了个负号,就是相当于整个括号值越大,也就相当于整体越大,这样就说明,整体越大概率越大,距离越小,误差epsilon越小)
第三个式子:似然函数:
在数学中,符号“∑”和“Π”分别用来表示求和与求积。把每一个x累乘起来
似然函数L(θ)越大,说明整体概率越大,越大越好
(不是看的很懂似然函数为什么要累乘)
累乘不好算,用对数把乘法变成加法--->对数似然函数

如何求J(θ)最小值?

θ已经知道了,我们最早有这个式子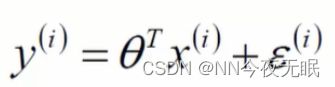
那么式子里现在只剩下我们想要的epsilon和已知的数据X和标签Y了!可以求出来bias了!
5. 逻辑回归logistic回归
sigmoid函数:可以把一个值映射成0-1之间的概率
把连续值变离散型?一个值比如说24,映射到sigmoid函数是0.3,那么我们假设50%以下就是概率太低不可能的意思,那么我们就知道这个值是false;比如映射后概率是0.6,那么就是true。
------------>逻辑回归其实是一个分类的算法,二分类问题

细节可看:【机器学习】逻辑回归(非常详细) - 知乎 (zhihu.com)
6/7. 梯度下降
这个J(θ)就是损失函数啦!
我们需要求损失最低,那么遍历所有值找到最低点那太麻烦啦!所以我们使用梯度下降
损失最低就是损失函数最小了(θ不确定的时候,其实是有很多个损失函数的,我们要找到那个最小的损失函数,xy都是固定的变量,我们只要确定θ,得到一个让整体都变得最小的那个损失函数,因为这个已经有四个变量了x,y,θ0,θ1所以不好解释这个找到最小的损失函数这一说。。。总之不能从xy那边找最小,因为那是样本数据,我们就要确定θ,机器学习里就是在求权重参数的过程,xy其实是已知值,就是全部x向量和y向量自己和自己加一起)

步长小一点没事,就是运算量大,但是大了会直接略过需要的全局最小点
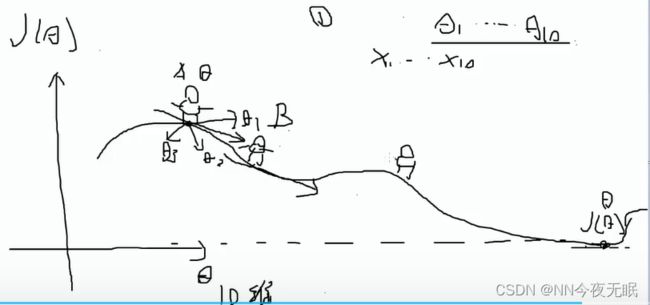
随机乱走看一下哪个方向是最小的,每次下山,是θ0~θn组合出来的一个值,比如上图就是θ0和θ1的值共同决定往哪个方向下山的,如果是10维就是,θ0~θ10共同决定的。
决策树与随机森林
1. 决策树概述
能分类也能回归
一棵决策树:
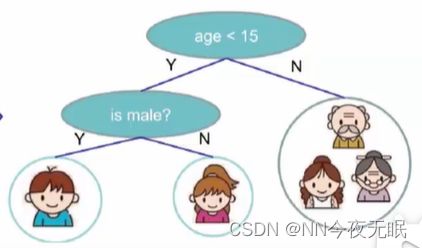
一些术语:

决策树分为两个阶段:
1. 训练阶段(用训练数据集构造出一棵决策树)
2. 分类阶段(放入真实数据,得到分类结果)
2. 熵原理
熵:分子的混乱程度

A里面什么都有,很不纯,很混乱,熵很大!(每个数字出现的概率是0.1,算出来熵很大)
gini系数和熵的变化是一样的,就是公式不一样,都是越大分类效果越差
3/4. 决策树构造
我们希望,树越深,节点数增加,熵最好变小快一点,那怎样一颗决策树熵减的快呢?怎样能让决策树少决策几次,树矮一点呢?
以下是ID3算法构造决策树:
Step1:计算原本熵值

Step2:计算每一个的熵值,熵值最大,信息增益最大
5. 信息增益率

ID3算法:它是有问题的,比如有一个数据,里面的值有非常多,比如ID:1,2,3,4,5,6,7,8,9,10,那么每种都只出现一次,他的熵就非常大,非常不稳定,那么先划分这个,就能让熵值一下子减小很多,但是先拿着个数据决策真的好吗?因为1,2,3,4,5,6,7,8,9,10里面每个ID只对应一个数据,那么划分完,根本没有起到划分效果呀!
衡量树的效果?评价函数:叶子结点的个数乘以总熵值,值越小越好!(类似损失函数,相当于叶子结点的不确定性越小越好,越小说明叶子结点的分类效果还不错)
C4.5:连续值离散化,比如1,2,3,4,5,6,7,8,9,10,划分成<=5的和>5的。年龄值也会有ID3算法导致的问题,所以可以把年龄划分成>=30岁的和<30岁的。那么具体从几开始切分比较好呢?可以在每一岁上切一刀,来算一下左边和右边的熵值差别(差别为什么的时候可以呢?希望他整体熵值很大,也就是熵值之和很大,是一种贪婪算法!计算每次的和,选择最大的)
6. 决策树剪枝
决策树不能太高,太高的话分的太仔细,有些没必要用于决策的变量的也决策了,这会导致过拟合
预剪枝:变构建变剪枝
后剪枝:全部构造好了后,再进行剪枝
剪枝时使用的限制条件:
预剪枝:
1. 可以是限制决策树的高度,当决策树构造到第3层的时候,就不继续构造了,提前停止
2. 可以是限制样本的个数,比如某个节点内的样本个数小于50了,就不继续构造了,提前停止
后剪枝:
1. 选择一些节点,然后计算评价函数,然后剪枝之后,在计算一次评价函数,来看看哪个效果好,如果剪枝效果好就剪枝(α表示叶子结点个数对于评价函数的影响,如果觉得叶子结点多一点也没关系,就可以设大一点,如果希望少一点,就α小一点)
7. 随机森林
森林:构造好几颗决策树,然后每颗决策树做一次决策,然后再把每次的决策算一个平均或者算一个众数,得到最终决策
随机:
1. 数据选择随机性:随机选择的有比例的有放回的采样,采样一部分然后构建一棵树,另一棵树再重新采样,因为有放回所以会采样到重复的
2. 特征随机性:特征有很多,但是有的特征可能对结果没有影响,比如数据的ID就没有影响,那么特征随机,最后看看使用哪些特征效果最好
bootstraping:有放回采样
bagging:有放回采样n个样本一共建立分类器
8. 案例
贝叶斯算法
1. 贝叶斯算法概述
2. 贝叶斯推导
3. 贝叶斯用于拼写纠错
4. 贝叶斯用于垃圾邮件过滤
Xgboost
支持向量机算法
时间序列AIRMA模型
神经网络基础
1. 深度学习概述
大数据时代
IMAGENET数据集
深度学习和机器学习的关系?机器学习里有一个部分叫神经网络,神经网络扩展和改进,就是深度学习的内容
无人驾驶
2. 难点与常规套路
计算机视觉:图像是三维数组的形式,三个颜色通道RGB,图像的大小?300*100大小的图像有300*100*3个数据
0-255,0暗/255亮
难点:照射角度、光照强度、形状改变、部分遮蔽、背景混入
常规套路:1. 收集数据给定标签 2.训练分类器 3.测试评估
3. k近邻分类(KNN算法)

不需要训练,是一种lazy-learning算法,但是KNN计算复杂度和训练集发小成正比!效率太低!
一个实例:
CIFAR-10经典数据集:
10类标签(50000训练数据+10000测试数据,大小均为32*32)
CIFAR-10里的10意思是有10类标签
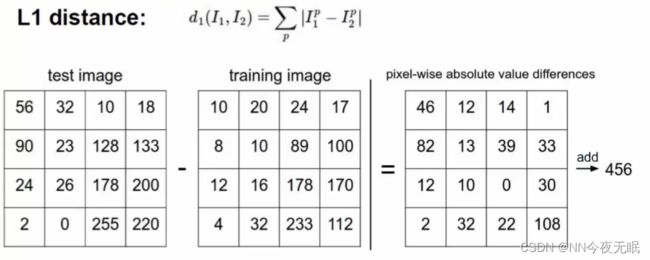
用k近邻算的话,就是看谁更近,那么对应像素点相减,最后再累加,就是距离,选择最近的即可!
但是效果不好哦!
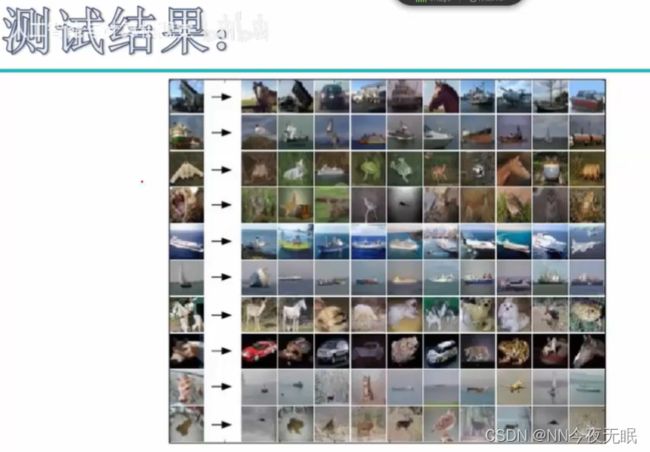 如果直接相减,只能看出整体来看像不像,这样的话背景就会对结果有影响,比如第一个,背景是蓝色,选出来背景都是蓝色,但是背景不重要!
如果直接相减,只能看出整体来看像不像,这样的话背景就会对结果有影响,比如第一个,背景是蓝色,选出来背景都是蓝色,但是背景不重要!
所以说要忽略背景,使用前景!
4. 超参数与交叉验证
接上回KNN:
距离就是一个超参数,超参数就是训练模型时可以改变的一些参数,比如作为距离,我们可以用L1 的曼哈顿距离,也可以用L2欧式距离公式(常用的是欧式距离)
所谓"超参数",就是需要人为输入,算法不能通过直接计算得出的参数
KNN中的k代表的是距离需要分类的测试点x最近的k个样本点,如果不输入这个值,那么算法中重要部分“选出k个最近邻”就无法实现。从KNN的原理中可见,是否能够确认合适的k值对算法有极大的影响。
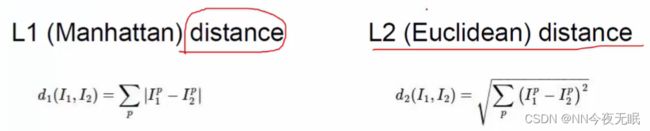
交叉验证:训练集、验证集、测试集

就是说,先拿1 2 3 4训练,用5来看看效果好不好并调节,用6来测试;下一次用1345训练 2验证;然后用1245训练 3测试...

交叉验证里的k一般取10,那么KNN里的k取多少呢?
使用交叉验证来确定k的值:
那我们怎样选择一个最佳的k呢? 在这里我们要使用机器学习中的神器:参数学习曲线。参数学习曲线是一条以不同的参数取值为横坐标,不同参数取值下的模型结果为纵坐标的曲线,我们往往选择模型表现最佳点的参数取值作为这个参数的取值。

在选取不同的k的时候,10折交叉验证的准确率如下,那我们要选择准确率最高的,此时k大概是9
KNN中K值大小选择对模型的影响:
- k值过小:
- 容易受到异常点的影响
- 容易过拟合
- 模型过于复杂
- k值过大:
- 受到样本均衡的问题
- 容易欠拟合
- 模型过于简单
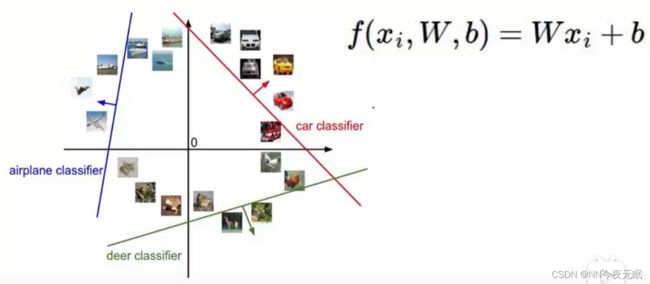
5. 线性分类(得分函数)
得分函数:
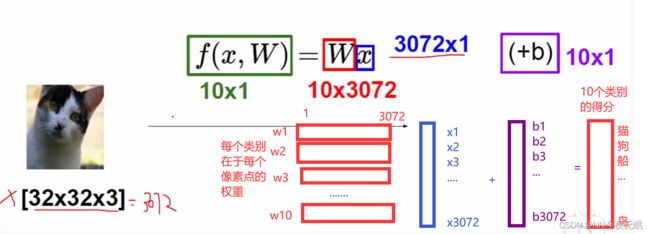

猫的得分甚至是负的,这个weight太离谱了,继续训练!
最后可以训练出合格的weight,那么就有很多条y=wx+b,就可以进行线性分类了
6. 损失函数

这里使用SVM损失函数,当然要换成别的损失函数也可以的,可以计算出损失值(+1也可以换成别的,这个1是对于分类的接受程度,如果想要更接受分类错误的情况,可以把1换大一点)

中间这一块delta就是1,就是在这一块虽然不太好但是我还是接受的损失
损失值和所有样本有关,但是又不能受到样本个数的影响,于是:
L就是f(x,W)的损失函数loss function
7. 正则化惩罚项

如果按照本身损失函数的计算方法,没有加入正则化惩罚项,对于x=[1,0,0,0],不管用权重参数w1还是2,损失值都是0.25,那难道说损失值一样,不管用权重w1还是权重w2都是一样的吗?明显w1对于x0的关注度更高,而对x1x2x3都没有关注度,而w2关注得平均,那怎么样才能发现他们的不同呢?引入正则化惩罚项!
对于L2惩罚项,计算w1和w2的平方,发现w2的惩罚比较小,那说明他惩罚的少说明他好,于是用w2权重参数
惩罚项有L1和L2,也可以称之为正规化和范数,L2惩罚项就是L2范数,也就是二范数
L0范数是指向量中非0的元素的个数。(L0范数很难优化求解)
L1范数是指向量中各个元素绝对值之和
L2范数是指向量各元素的平方和然后求平方根
8. softmax分类器
上面优化了w,可以通过正确的w计算得分值,但是我想要概率,来分类
sigmoid函数: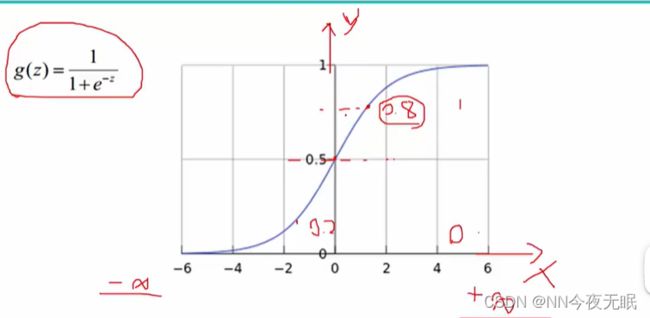
使用sigmoid函数把数字映射到0~1
类似地,softmax分类器--->归一化分分类概率

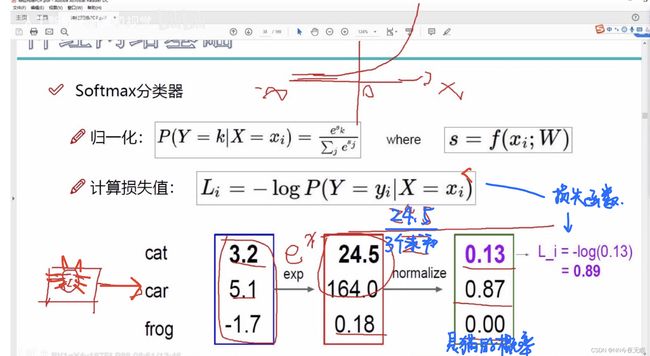 通过softmax函数进行归一化,再用损失函数取log计算损失值
通过softmax函数进行归一化,再用损失函数取log计算损失值
这里的log以10为底(不写底数的log可能以2,e,10为底,比如算法与数据结构里面是默认以2,数学物理里常用以e为底,电路里以10为底,数值计算里常用以10为底,编程语言都以e为底,但是无所谓,相差一个常数系数而已)
softmax细节:一文详解Softmax函数 - 知乎 (zhihu.com)
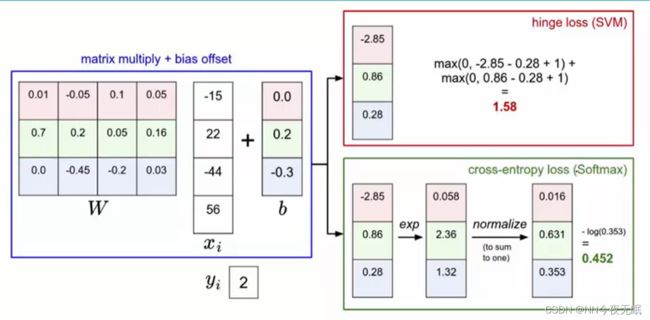
对比一下:SVM和Softmax,Softmax有一个放大操作exp,这样可以很好地把他们区别开来在进行比较
9/10. 最优化
梯度下降下山,使得J(θ)最小,那么怎样是最小呢?
梯度下降什么意思,就是要让梯度一直处于向下的趋势!如果在下山,梯度本身就是向下的ok,如果在上山,梯度上升了,不行!所以得开始走反方向,一直走到最低点
神经网络:前向传播+反向传播
先随机初始化再进行优化操作
Bachsize取数据函数--->一次迭代多张图像(16,32,64,128张都行,看计算机性能)
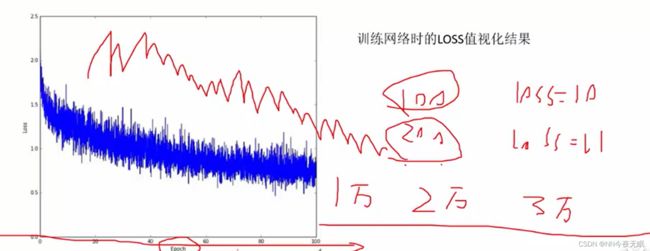
迭代次数变大,不一定都是loss变小,有时候也会有锯齿有波动,但是整体水平是向下的就可以啦!有时候要迭代到以万为单位,才能得到最终结果
1个epoch和1次迭代的意思:
# epoch: 1个epoch指用训练集中的全部样本训练一次,此时相当于batch_size 等于训练集的样本数。 如果epoch =50,总样本数=10000,batch_size=20,则需要迭代500次。
# iteration: 1次iteration即迭代1次,也就是用batch_size个样本训练一次。
(epoch是时期,batch是一批,也就是说一个时期epoch就是把所有总样本都迭代过了)
(一组20个一共10000个,则需要迭代500次,这500次就是一个epoch)
学习率LR learning rate:一般低一点0.001/0.0001都可以,因为太大的话一步直接跨过了最低点了,w += 中心梯度*LR,把变化量化小
11. 反向传播

(这里把偏导打成编导了。。。)
具体怎么算呢?
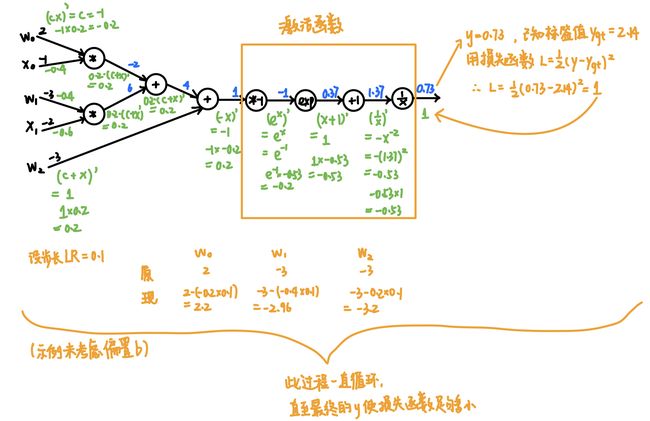
也可以一大块一大块地算:

把整块sigmoid当成一整个函数进行求偏导
常见的门单元:(就是常见的神经元)
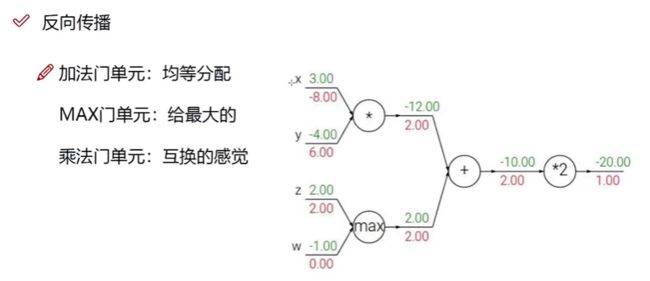 max门单元反向传播的时候,只会把梯度给最大的!
max门单元反向传播的时候,只会把梯度给最大的!
神经网络架构
1. 整体架构
神经元就是便于理解,在程序中不存在,不用定义神经元类

(此处W和X都是矩阵哈)
正向传播:比如第一个隐藏层的第一个神经元,获得输入x1x2x3,并且他们都有被权重参数给改变过了,所以x1=w1_1*x1,x2=w1_2*x2...然后再输入到神经元里面,这个神经元就是一个求和,然后通过激活函数变成非线性,再往下传,一直到得到了output(线性加权求和+非线性激活函数)
反向传播:得到了output,然后就要对最前面的input中的x1x2x3求偏导,比如对x1求偏导,得到了-10,也就是斜率gradient=-10,那说明影响很大而且是梯度向下的,说明ok,只要别向上就ok,如果是10,说明已经在上坡了,不行,w得调整成负的。
再正向传播.....
(关于为什么神经元里不是函数式:成百上千万的神经元,怎么可能一个个写函数式嘛!所以只能是简单的加权求和,但是加权求和又不完全满足,所以要使用激活函数,而且激活函数的式子也不是自己写的,是从常见激活函数里挑选的)
1/2. 激活函数
激活函数:
我们会发现在每一层的神经网络输出后都会使用一个函数(比如sigmoid,tanh,Relu等等)对结果进行运算,这个函数就是激活函数(Activation Function)。那么为什么需要添加激活函数呢?
因为神经网络中每一层的输入输出都是一个线性求和的过程,下一层的输出只是承接了上一层输入函数的线性变换,所以如果没有激活函数,那么无论你构造的神经网络多么复杂,有多少层,最后的输出都是输入的线性组合,纯粹的线性组合并不能够解决更为复杂的问题。而引入激活函数之后,我们会发现常见的激活函数都是非线性的,因此也会给神经元引入非线性元素,使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中。
激活函数可以分为线性激活函数(线性方程控制输入到输出的映射,如f(x)=x等)以及非线性激活函数(非线性方程控制输入到输出的映射,比如Sigmoid、Tanh、ReLU、LReLU、PReLU、Swish 等)
Sigmoid为什么被淘汰了!

梯度消失现象:当值比较大的时候,对sigmoid函数求偏导,会发现斜率趋近于0,越大越趋近0,但是在反向传播时,求偏导等于对该项求偏导乘上上一项的偏导,但是一个上一项的很大的值求偏导都快等于0了, 那么这一项也趋近于0,下一项也会被影响,梯度消失
解决办法:用ReLU

3. 过拟合
神经元过多,容易过拟合!
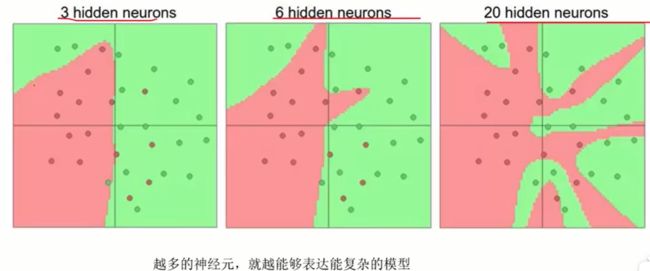
可以使用正则化惩罚项 比如λw^2,以下是惩罚力度对结果的影响

数据预处理:
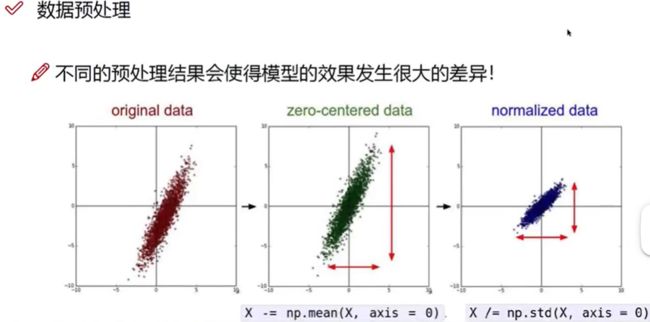
减去均值,就会以0为中心
除以标准差,就会归一化
权重初始化:随机,但是不能让初始值为0(高斯初始化!)
偏置初始化:0或1
Drop-out
设定保留率,随机选择几个神经元不更新(这次不更新而已,下次还是会更新的,只要没被随机到)可以降低过拟合风险!并且可以用迭代次数来弥补有些神经元被迭代得少的情况

A:全连接(每个神经元都和上下两层神经元全部连接在一起了)
B:drop-out
4. 例子
PCA降维与SVD矩阵分解
聚类算法
推荐系统
Word2Vec
第二部分:深度学习
深度学习基础
见《第一部分-机器学习-神经网络基础》
神经网络架构
基本与《第一部分-机器学习-神经网络架构》一致,但是第一部分介绍的比较粗糙
卷积神经网络
1. 应用领域
深度学习让机器识别变得准确
分类与检索 超分辨率重构 医学任务 无人驾驶 人脸识别
GPU比CPU快太多
2. 卷积的作用

CNN是三维的,因为NN的数据只有一维,一组数据就是二维,而CNN图片数据就是二维的了(加上通道还有三维),一大堆图片叠加在一起,就是三维的了(实际上是32x32x3x100000)
卷积:提取特征
池化:压缩特征
3. 卷积特征值计算
卷积操作:寻找最好的权重参数矩阵,相当于就是寻找最合适的卷积核!(卷积核就是权重参数矩阵呀)

比如图中的这一块卷积核(权重参数)是[[0 1 2][2 2 0][0 1 2]] 计算就是0+1x2+2x2+0+0+0+0+0+0=6(这样就是单一通道的,如果一个像素点RGB三个通道分别计算出来是1、2、3,那么就是1+2+3=6)
三通道例子:
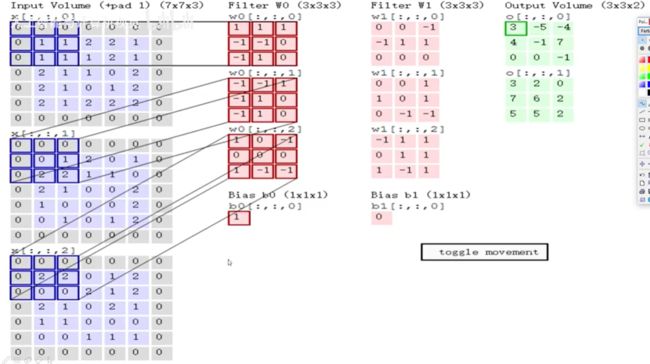
全部加和之后,还要在加上偏置b哦
4. 特征图表示

5. 步长与卷积核
滑动窗口步长:一次可以滑动一格,也可以滑动两格

如果说是对一行字卷积呢?那如果要三个字三个字卷积,那就是1x3的卷积核,卷积核不一定是正方形哦
步长不一样,得到的特征值大小也不一样
卷积核尺寸:影响选择区域的大小和得到的结果大小
6. 边缘填充、卷积核个数
边界信息缺失?padding边缘填充,可以填充0和其他padding方法
卷积核个数?比如一共要得到10个特征图,那就需要10个卷积核,每个卷积核卷出来的特征都不一样哦
7. 特征图尺寸计算与参数共享
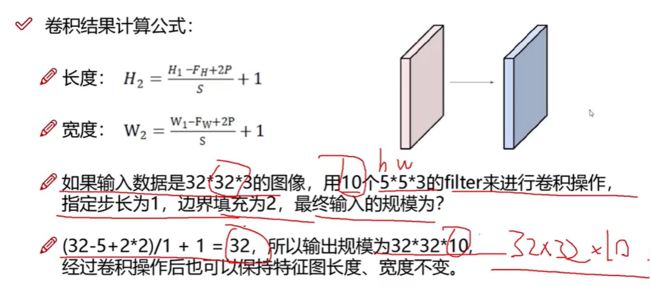
参数共享:每个区域都是同一个核!图中红、绿、蓝、黑是同一个filter

8. 池化层
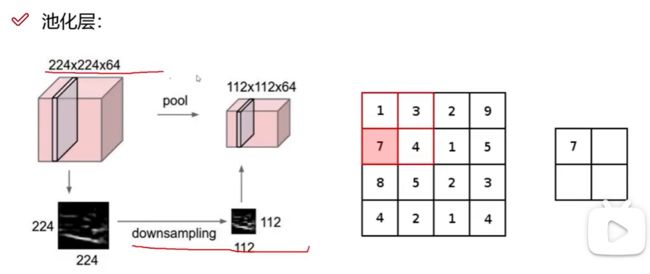
pool池化和downsample下采样是一个意思
9. 整体网络架构

两次卷积+RELU,再一次池化(只有卷积层需要神经网络计算哈,后面的RELU和POOL都没有需要更新权重参数的)
全连接层能连接三维的东西吗?所以要把这个层都拉成特征向量!在图中绿色的FC(full connection)部分,要ba 32x32x10转化为10240x5的特征向量,为什么是5,因为特征有5个
具体怎么拉成特征向量呢?
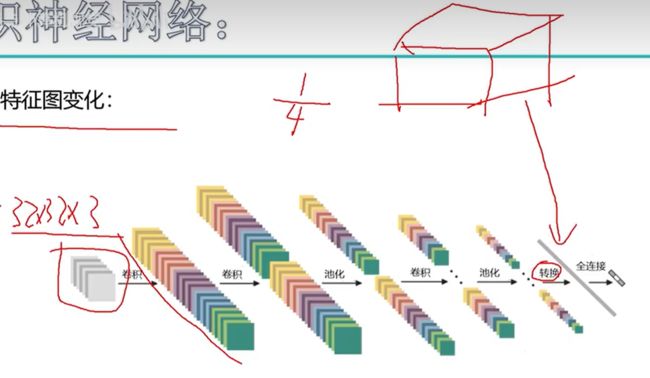
10. VGG网络
Alexnet 近代的经典网络但是淘汰了

卷积核越小越好,3x3比较多
VGG有好几个版本,D是主流版本:

在pooling特征值会损失,那他是怎样做的呢,他在每次pooling完后,使特征值翻倍!
VGG用到了16层神经网络,Alexnet8层
为什么不用更多层?实验的时候发现层数多了不好,怎么办呢?看resnet
11. 残差网络Resnet
我们需要加入更多层,但是不能让表现不好的层影响,所以要把表现不好的扔掉,但是已经加进去了不能扔掉呀,怎么办?同等映射!
加进来之后发现不好,就让这一层权重参数为0就不影响了

对比AC和ABC,发现ABC不好,就把B的参数学成0,就走AC这条路
效果:(可以多用用)

特征提取里好用
12. 感受野


递归神经网络与词向量
1. 递归神经网络RNN网络架构
如果加入了时间变量,在t1、t2、t3...数据是会变化的,不一样的,那只输入t1的数据肯定是不行

①中间隐藏层的输入t1,得到输出o1 ②把o1和t2再一起放入隐藏层,得到o2 ③把o2和t3的数据再放入隐藏层,得到o3...
这样是有先后顺序的,比如一句话“今天学习了神经网络”,那今就在天的前面,天在学的前面...
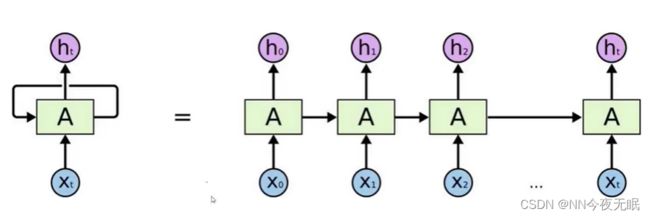
最后的输出结果才是结果,中间结果只是用来当输入数据的
数据是以WordVec输入的,WordVec把一个单词转化成词向量
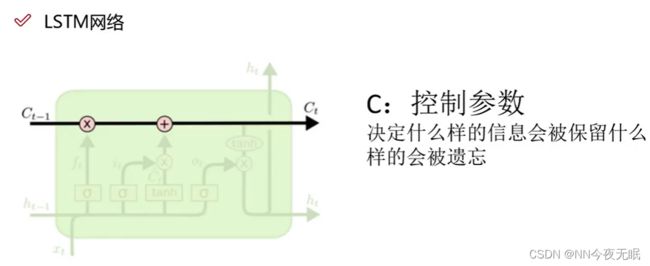
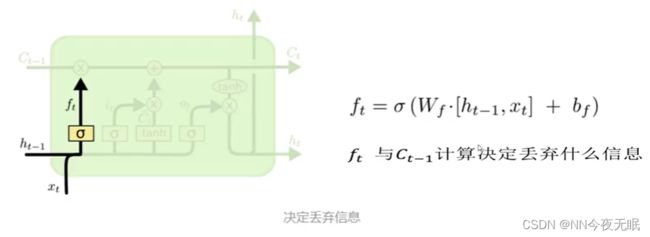
1. LSTM网络
前面的结果一定重要吗?
忘记不需要的特征

2. 词向量模型Word2Vec
1.必须有前后顺序
2. 相近的词应该在词向量空间中越近,关系不大的词应该更远
词向量空间?50-300维,因为要描述一个词需要大概50-300个属性
既然是数字表示,就可以计算词和词之间的相识度,用欧氏距离公式计算
3. 模型架构
热度图:可以看到男人和男孩有很多地方相似,就可以说明这两个词的含义很相近
词向量是有意义的!


输入在/词向量,就能输出模型
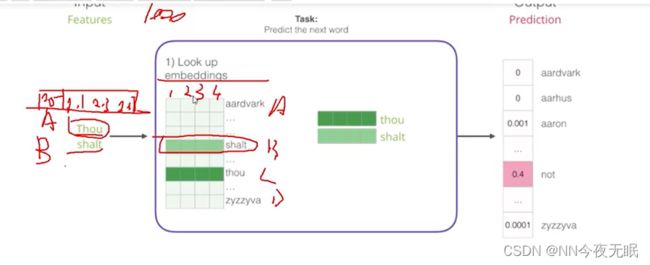
在词库中查找单词的词向量,一开始都是随机初始化的,然后进入神经网络,什么样的表达能让计算机把下一个词猜的更准确一些
4.训练数据构建
语言是跨区域的,训练数据,可以随便的找别的数据使用,只要是有逻辑顺序的文章,都可以使用
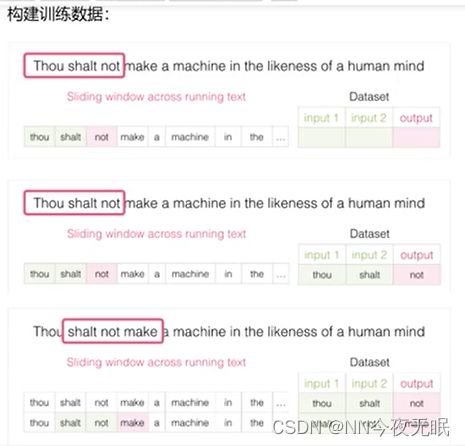
滑动窗口,把每次的前两个当成输入,最后一个当成输出,也就是标签
5. CBOW与Skip-gram模型
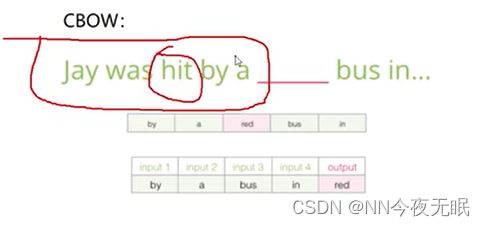
输入是上下文,输出是中间的单词


6. 负采样方案
如果全部输入了数据,比如not后面加thou,并且给了target1,那以后每次not都会自动预测为thou了,毕竟是概率为1,总是不会错的,这明显不合理,应该人为加入负采样0,怎么说呢,比如not后面不会出现play,所以我们加上一个input:not,output:play,target:0,这样一个负采样
负采样写5个就比较合理
右侧的有target比较好
