idea maven spark 连接 sql server
在网上找了很久的方法,没有找到成功的,所以写一下
参考官网 :
-
https://docs.microsoft.com/zh-cn/sql/connect/spark/connector?view=sql-server-ver16
-
https://docs.microsoft.com/zh-cn/azure/azure-sql/database/spark-connector?view=azuresql
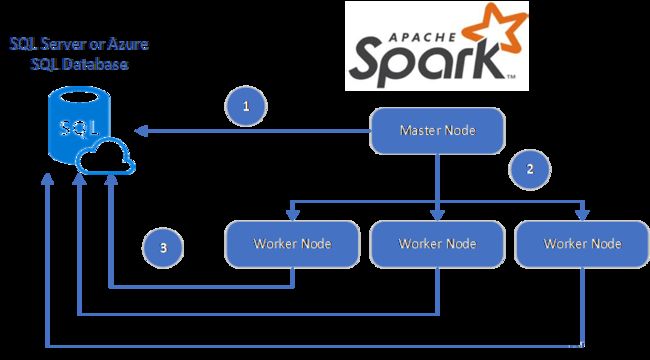
方法一:在git 上下载 connect jar 包
https://github.com/Azure/azure-sqldb-spark
maven 安装 本地cdm 仓库jar包
下载jar 包及 pom.xml 文件
https://search.maven.org/search?q=a:azure-sqldb-spark
用maven 安装jar包
mvn install:install-file -Dfile=azure-sqldb-spark-1.0.2.jar -DgroupId=com.microsoft.azure -DartifactId=azure-sqldb-spark -Dversion=1.0.2 -Dpackaging=jar
配置pom.xml
<dependency>
<groupId>com.microsoft.azuregroupId>
<artifactId>azure-sqldb-sparkartifactId>
<version>1.0.2version>
dependency>
方法二:pom.xml 上配置
<dependency>
<groupId>com.microsoft.azuregroupId>
<artifactId>spark-mssql-connector_2.12artifactId>
<version>1.1.0version>
dependency>
读数
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
写数
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
spark 执行DML DDL
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
spark sqlserver 通过批量插入操作写入数据
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.