开放词汇视觉定位 OV-VG: A Benchmark for Open-Vocabulary Visual Grounding 论文笔记
开放词汇视觉定位 OV-VG: A Benchmark for Open-Vocabulary Visual Grounding 论文笔记
- 一、Abstract
- 二、Abstract
- 三、相关工作
-
- A、视觉定位
- B、短语定位
- C、开放词汇学习
- D、开放词汇视觉定位
- 四、数据集构建
-
- A、数据集描述
- B、数据集分离
-
- 1) 图像分离
- 2)类别分离
- C、数据标注和样本
-
- 1)OV-VG Referring Expression Annotation
- 2)OV-VG Bounding Box Annotation
- 3)OV-PL Annotation
- 五、方法
-
- A、整体网络
- B、特征编码器
- C、模块结构
-
- 1)语言引导的特征注意力模块 Language-Guided Feature Attention Model
- 2)文本-图像 Query 选择
- D、特征解码器
- E、训练损失
- F、实施细节
- 六、实验
-
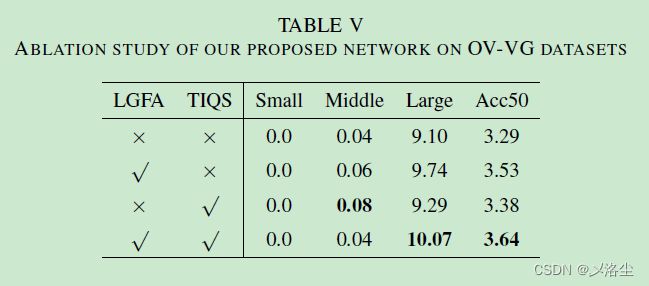
- A、消融研究
- B、数据泄露
- C、数据集分析及错误案例
- D、可视化实验
- 七、结论
写在前面
又是一周周末,光调代码去了,都没时间看论文了,汗。
这是一篇关于开放词汇定位的文章,也是近两年的新坑。
- 论文地址:OV-VG: A Benchmark for Open-Vocabulary Visual Grounding
- 代码地址:https://github.com/cv516Buaa/OV-VG
- 收录于:IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 6 千粉丝有你的参与呦~
一、Abstract
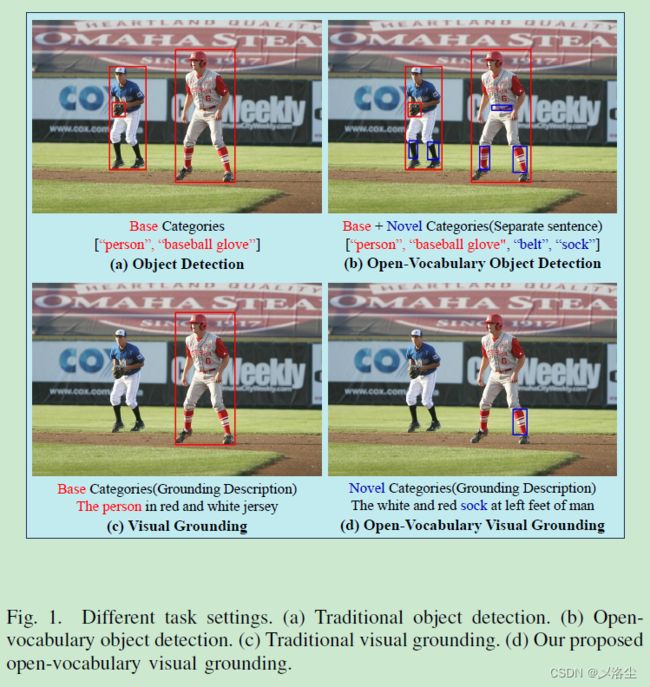
开放词汇检测旨在检测那些未出现在预定词汇中的目标,类似的任务有视觉定位 Visual Grounding (VG)。然而当前的基础模型虽然在很多视觉语言任务上表现很好,但是在开放视觉定位 open-vocabulary visual grounding (OV-VG) 上还没有拿得出手的工作。本文提出一种新的 OV 任务,名为开放词汇定位 Open-Vocabulary Visual Grounding (OV-VG) 和开放词汇短语定位 Open-Vocabulary Phrase Localization (OV-PL)。整体目标是建立起语言描述和新颖目标定位间的联系。
为了测试这两任务,建立了一个包含 7272 张图像的数据集,由 1 万个实例组成,其中的 1 千张用于组成 OV-PL 数据集。基于这些数据,测试了大量的方法,但是效果都不太好。于是本文提出一种方法,其中包含两个关键模块:图像文本 Query 选择 Text-Image Query Selection (TIQS) 、语言引导的特征注意力 Language-Guided Feature Attention (LGFA),用于促进对新类别的识别以及增强视觉和文本信息的对齐。大量的实验表明方法达到了 SOTA 的性能。
二、Abstract
首先指出视觉定位的定义和意义。之前的方法通过增强视觉-语言表示弥补了视觉语言的代沟,但是检测新的目标不太行。另外,在视觉定位任务中,目前没有公开的数据集用于支持新类别目标的检测。
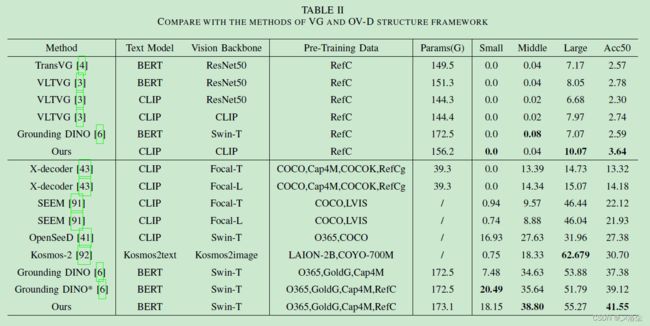
最近,开放词汇学习很火,尤其是基于 CLIP 的模型,快速席卷了开放词汇检测和开放词汇分割 open-vocabulary detection (OV-D)、open-vocabulary segmentation (OV-S)。但现有的方法受限于大量的数据。于是本文引入一个手工裁剪的数据集,用于开放词汇视觉定位 open-vocabulary visual grounding (OV-VG) 任务,同时设计了一个数据集,其中包含 100 个新颖的类别,每个类别包含 100 个实例。每张图像对应两种描述:一个只包含基础的类别,而另一个则是基础和新颖的概念组合。提出的方法包含文本-图像 query 选择 text-image query selection (TIQS) 和语言引导的特征注意力 language-guided feature attention (LGFA)。此外,还提供了一些 baseline 模型用于 OV-PL 数据集。OV-VG、OV-PL 与 VG、PL、OV-D 的区别如下表所示:

本文贡献总结如下:
- 提出开放词汇视觉定位 open-vocabulary visual grounding (OV-VG) 和开放词汇短语定位 open-vocabulary phrase localization (OV-PL) 任务,发布了两个数据集。
- 在 OV-VG 和 OV-PL 数据集上测试了现有的方法(这也行?)。
- 提出一个网络,整合了 text-image query selection (TIQS) 和 language-guided feature attention (LGFA)。
- 大量的实验验证了方法的有效性。
三、相关工作
A、视觉定位
现有的方法可以划分为两阶段的方法和单阶段方法。而大部分的视觉定位基本上都是目标检测方法的拓展。
两阶段方法中,首先是生成区域 proposals,接着是利用特定的语言输入鉴定最合适的 proposal,缺点在于推理速度太慢。另一方面,单阶段的方法能无缝地整合视觉和语言特征来直接圈出特定的区域。然而由于逐点进行特征表示,在捕捉复杂的视觉语言信息时,能力稍显不足。
随着 Transformer 的出现,能够直接检索出特定的目标,例如 TransVG、VLTVG。
B、短语定位
短语定位旨在建立起名词短语和特定区域间的联系,通过引入空间关系,可以区分出不同的实体。一些弱监督和无监督的方法尝试减小标注的成本,例如 Align2Ground。而本文引入一种新的开放词汇定位方法,同时展示了多种 Baseline 方法。
C、开放词汇学习
主流的开放词汇目标检测 open-vocabulary object detection (OV-D) 可以划分为五个类别:知识蒸馏、区域文本预训练、利用更平衡的数据集和伪标签来训练模型、prompting modeling、区域文本对齐。例如 ViLD、FVLM、Grounding DINO。
开放词汇分割催生了很多技术,例如 Visual Language Models (VLMs)、diffusion models、开放词汇视频理解、开放词汇 3D 理解。然后是一些方法举例:OpenSeeD、X-Decoder。
D、开放词汇视觉定位
开放词汇目标检测方法旨在鉴别出未定义的目标类别,应用很广泛。目前还没有 Benchmark 或者方法用于开放视觉定位任务。于是本文引入两个 Benchmark 数据集,OV-VG 和 OV-PL,同时提供大量的 Baseline 模型用于 OV-VG 任务。此外,引入了一些短语定位方法。最后提出了一种网络用于解决 OV-VG 问题。
四、数据集构建
A、数据集描述
OV-VG 数据集包含 7272 张图像,共计 1 万个实例。所有的图像选自 MSCOCO 数据集,且与 RefCOCO+\g 无交集。选择 COCO 中的 80 个类别作为基础类,另外 100 个来自 LVIS 的类别作为新颖类别。进一步从 OV-VG 数据集中挑选出 1 千张图像作为开放词汇短语定位任务的数据集,标注格式与 Flickr30k Entities 一致。
B、数据集分离
1) 图像分离
由于 RefCOCO 和 COCO2017 的训练集和测试集有交集,于是从 COCO2017 val 和 RefCOCO val 中挑选图像。同时确保 OV-PL 中的 1 千张图像完全来源于 OV-VG。
2)类别分离
选择 COCO 中的 80 个类别作为基础类,另外 100 个来自 LVIS 的类别作为新颖类别。
C、数据标注和样本
1)OV-VG Referring Expression Annotation
6 个标注打工人,两个质量检测打工人。样本如下图所示;

开始时在每个描述中用新类别来代替旧的,描述中包含颜色、形状、关联关系等。OV-VG 数据集不仅包含新的类别,而且在标注过程中,特意增强对视觉-语言的理解。举例如下:

RefCOCO 包含了目标和一些位置词语,而 RefCOCO+ 用动作行为代替了其绝对位置,RefCOCOg 则使用来更细节的描述。OV-VG 描述模仿 RefCOCOg 的格式,旨在从细节上描述新颖类别目标的信息,同时也并未限制方向词汇和属性词汇的使用。RefCOCO、RefCOCO+、RefCOCOg、OV-VG 数据集的平均描述长度分别为 3.61、3.53、8.43 和 9.32。
2)OV-VG Bounding Box Annotation
利用 LVIS 中的原始标注 boxes,处理成与 RefCOCO 相同的格式,包含位置和尺寸 4 个维度,表示目标的左上角和右下角坐标。OV-VG 和 RefCOCO val 的数据分布如下图所示:

从图中看到,OV-VG 和 RefCOCO val 的实例数量几乎相同,1 万 vs. 10834。相比于 RefCOCO val,OV-VG 的尺度变化则更加明显,更加符合现实。同时 OV-VG 数据集中的目标更小,因此需要模型更精确的定位能力。
3)OV-PL Annotation
从 OV-VG 中选择 1 千张图像构建 OV-PL 数据集,标注方式类似于 Flickr30k Entities,但是只有两种结构化的描述(前者是 5 种)。其中一个句子仅使用基础的类别,而另一个同时使用基础和新颖的类别。标注分为两个阶段:指代描述+bounding box 标注。样本如下图所示:

五、方法
A、整体网络

如上图所示,结合当前的 VG 和 OV-VD 网络结构来设计端到端的 OV-VG 网络。给定图像文本对,首先用图像 Backbone,类似 ResNet-50 或 Swin Tranformer 提取图像特征;文本 Backbone,类似 BERT 或 CLIP 提取文本化的 embedding。之后将图像和文本特征送入一个特征编码器用于特征融合。
为对齐这两种模态,在特征编码器中添加图像-文本和文本-图像跨模特注意力。然后应用语言引导的特征注意力 language-guided feature attention (LGFA) 和文本-图像 query 选择 text-image query selection (TIQS) 来进一步指代目标。LGFA 强化图像特征,使其能够关注指代表达式区域,而 TIQS 提供所有潜在的与位置相关的 boxes,并从中选择出 top-K 个 queries。最后,应用特征编码器来分析编码后的图像和文本特征,定位到更精确的目标位置并输出 top-1 box。算法路线图如下所示:

B、特征编码器
给定图像和文本表达式,送入 CLIP 图像和文本 Backbone,提取图像特征和文本 embedding。使用多尺度可变形自注意力来增强展平后的图像特征,使用自注意力增强文本特征。最后引入两个跨膜态注意力深度融合图像和文本信息。在融合当前层的输出后,接下来更新输入用于下一层的融合。定义 n = m i n ( N v , N l ) n=min(N_v,N_l) n=min(Nv,Nl),其中 N v N_v Nv 和 N l N_l Nl 分别是图像和文本的编码器层, v v ′ v_v^{\prime} vv′ 定义为:
v v ′ = c o n c a t ( P v → l ( P l → v ( v v ( i ) , v l ( i ) ) ) ) , 0 ≤ i ≤ n ) v_{v}^{\prime}=concat\left(\mathcal{P}_{v\to l}\left(\mathcal{P}_{l\to v}\left(v_{v(i)},v_{l(i)}\right)\right)\right),0\leq i\leq n) vv′=concat(Pv→l(Pl→v(vv(i),vl(i)))),0≤i≤n)其中 P v → l ( ⋅ ) \mathcal{P}_{v→l}(\cdot) Pv→l(⋅) 和 P l → v ( ⋅ ) \mathcal{P}_{l→v}(\cdot) Pl→v(⋅) 分别表示图像-文本,文本-图像融合。 v v ( i ) v_{v(i)} vv(i) 和 v l ( i ) v_{l(i)} vl(i) 分别是图像和文本编码器的第 i i i 层,接着是一个 FFN + ReLU 激活。
C、模块结构
1)语言引导的特征注意力模块 Language-Guided Feature Attention Model
LGFA 基于多头注意力机制,其中的 query 为展平的图像特征 v v ′ v_v^{\prime} vv′,key 和 value 则是文本 embedding v l ′ v_l^{\prime} vl′。多头注意力对齐展平后的图像和文本特征生成语义图 v s ′ v_s^{\prime} vs′。然后使用线性投影和 L2 归一化将 v v ′ v_v^{\prime} vv′ 和 v s ′ v_s^{\prime} vs′ 投影到相同的空间,记为 v ^ v ′ \hat v_v^{\prime} v^v′ 和 v ^ s ′ \hat v_s^{\prime} v^s′。接下来为每个点 x x x 计算注意力得分:
S x = α ⋅ exp ( − ( 1 − v ^ v ′ ( x ) T v ^ s ′ ( x ) ) 2 2 σ 2 ) S_x=\alpha\cdot\exp\left(-\frac{\left(1-\hat{v}_v^{\prime}\left(x\right)^{\mathbf{T}}\hat{v}_s^{\prime}\left(x\right)\right)^2}{2\sigma^2}\right) Sx=α⋅exp −2σ2(1−v^v′(x)Tv^s′(x))2 其中 α \alpha α 和 σ \sigma σ 为可学习的参数。
基于上式得到的注意力分数,采用点乘对 v v ′ v_v^{\prime} vv′ 计算,得到新的 v v ′ ′ v_v^{\prime\prime} vv′′ 用于特征解码器:
v v ′ ′ = β ⋅ v v ′ ⋅ S x + ( 1 − β ) ⋅ v v ′ v_v^{\prime\prime}=\beta\cdot v_v^{\prime}\cdot S_x+(1-\beta)\cdot v_v^{\prime} vv′′=β⋅vv′⋅Sx+(1−β)⋅vv′其中 β \beta β 是平衡超参数,实验中设为 0.7。
2)文本-图像 Query 选择
首先生成 Proposals,根据展平的图像特征 v v ′ v_v^{\prime} vv′ 和文本特征 v l ′ v_l^{\prime} vl′,计算两者间的 eisum:
S l = v ′ T v l ′ ∥ v v ′ ∥ ∥ v l ′ ∥ S_l=\frac{v^{^{\prime}\operatorname{T}}v_l^{\prime}}{\left\|v_v^{\prime}\right\|\left\|v_l^{\prime}\right\|} Sl=∥vv′∥∥vl′∥v′Tvl′其中 S l S_l Sl 表示 logit 分数。此函数用于衡量图像特征和文本 embedding 间的相似度,旨在匹配这两个模态特征。之后根据 loggit 分数,从中选出 top-K 个 queries,送入到解码器。
D、特征解码器
引入 DINO 解码器,并添加一些文本注意力来对齐文本-图像模态。
首先,将 top-K 个 queries 作为特征解码器的输入。query t q ∈ R C × 1 t_q\in\mathbb{R}^{C\times1} tq∈RC×1 输入到自注意力模块,来收集与目标 t l ∈ R C × 1 t_l\in\mathbb{R}^{C\times1} tl∈RC×1 相关的语义信息。而 LGFA 模块的输出作为 key 和 value 用于图像-文本跨模态注意力。于是聚合 t l t_l tl 和 v v ′ ′ v_v^{\prime\prime} vv′′ 特征得到视觉特征 t l ′ ∈ R C × 1 t_l^{\prime}\in\mathbb{R}^{C\times1} tl′∈RC×1 作为 query,文本 embedding v l ′ v_l^{\prime} vl′ 作为 key 和 value,输出 t v t_v tv。定义 i ( 1 < i < N ) i(1
t q i + 1 = f L N ( f L N ( t q i + t v ) + f F F N ( f L N ( t q i + t v ) ) ) t_q^{i+1}=f_{LN}\left(f_{LN}\left(t_q^i+t_v\right)+f_{FFN}\left(f_{LN}(t_q^i+t_v)\right)\right) tqi+1=fLN(fLN(tqi+tv)+fFFN(fLN(tqi+tv)))其中 f L N ( ⋅ ) f_{LN}(\cdot) fLN(⋅) 和 f F F N ( ⋅ ) f_{FFN}(\cdot) fFFN(⋅) 分别表示 L2 归一化和前项传播网络。每个解码器层添加跨膜态注意力信息用于视觉-语言对齐。
E、训练损失
在训练阶段,结合 OV-VD 和 VLTVG 的损失函数到提出的 OV-VG 框架内。此外,引入对比对齐损失。具体来说,将文本 embedding 视为 t i t_i ti,proposal embeddings 的数量为 N N N, O i + O^{+}_{i} Oi+ 表示与 t i t_i ti 对齐的正样本数量。于是损失定义如下:
L c t s = 1 ∣ O i + ∣ ∑ j ∈ O i + − log ( exp ( t i T o j / τ ) ∑ k = 0 N − 1 exp ( t i T o k / τ ) ) \mathcal{L}_{cts}=\frac1{\left|O_i^+\right|}\sum_{j\in O_i^+}-\log\left(\frac{\exp\left(t_i^To_j/\tau\right)}{\sum_{k=0}^{N-1}\exp\left(t_i^To_k/\tau\right)}\right) Lcts= Oi+ 1j∈Oi+∑−log(∑k=0N−1exp(tiTok/τ)exp(tiToj/τ))其中 τ \tau τ 为温度参数,整体损失为:
L = λ g i o u L g i o u + λ L 1 L L 1 + λ c t s L c t s \mathcal{L}=\lambda_{\mathrm{giou}}\mathcal{L}_{\mathrm{giou}}+\lambda_{\mathrm{L1}}\mathcal{L}_{\mathrm{L1}}+\lambda_{\mathrm{cts}}\mathcal{L}_{\mathrm{cts}} L=λgiouLgiou+λL1LL1+λctsLcts其中 L g i o u \mathcal{L}_\mathrm{giou} Lgiou、 L L 1 \mathcal{L}_{\mathrm{L1}} LL1、 L c t s \mathcal{L}_{\mathrm{cts}} Lcts 分别表示 GIoU 损失、L1 损失和对比对齐损失。 λ g i o u = L c t s = 2 \lambda_{\mathrm{giou}}=\mathcal{L}_{\mathrm{cts}}=2 λgiou=Lcts=2、 λ L 1 = 5 \lambda_{\mathrm{L1}}=5 λL1=5 为平衡的超参数。
F、实施细节
模型训练在 RefCOCO 数据集上,推理在 OV-VG。图像 Backbone 采用 ResNet-50 和 CLIP。输入尺寸 640 × 640 640\times640 640×640,最大文本长度 256 256 256。两块 3090,AdamW 优化器,初始学习率 1 × 1 0 − 4 1\times 10^{-4} 1×10−4,权重衰减 1 × 1 0 − 5 1\times10^{-5} 1×10−5,Batch 16,10 个 epochs。
六、实验
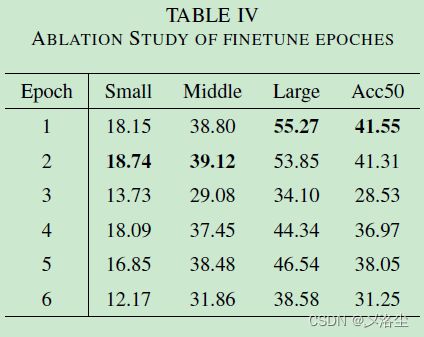
A、消融研究
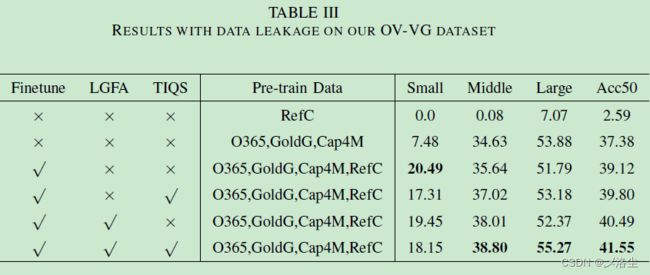
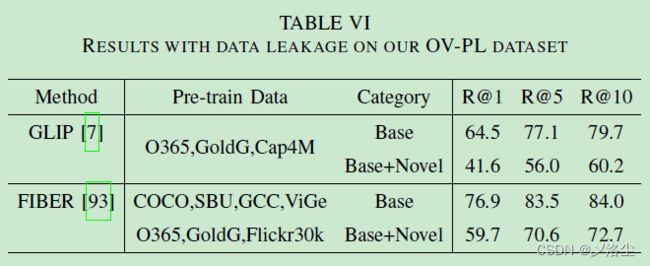
B、数据泄露
C、数据集分析及错误案例

D、可视化实验

七、结论
本文引入两个数据集 OV-VG 和 OV-PL,提出了一种 OV-VG 框架,整合了 LGFA 和 TIQS 模块。在 OV-VG 数据集上的表现表明本文提出的方法效果很好。通过可视化实验验证了方法的理论。
写在后面
这是篇挖坑的工作,思路还是比较简单的,后续有想“水”点论文的同学可以按照此种方法来操作下。当然缺点也有,这个创新点还是稍显薄弱,另外 Fig. 1 图片论文中根本没有引用,那么放上来是干啥的?图形摘要?