String、StringBuffer、StringBuilder相关性质和面试题
String、StringBuffer、StringBuilder相关性质和面试题
String基本性质
- 可以字面量赋值,也可以通过new造对象赋值;
- String声明为
final类型,不可继承,且具有不可变性; - String底层用
final修饰的value[]数组存储,在jdk8.0之前用char[]数组,jdk9.0后用byte[]数组存储;(why?因为使用发现大部分String类型能够被一个字符存储下来,虽然汉字不行,但是大部分还是英文类型居多,这样用byte数组存储能明显节省空间); - String实现了Serializable接口和Comparable接口;
String的不可变性和StringTable
String s1 = "abc";
String s2 = "abc";
System.out.println(s1==s2);//true
- 上述字符串的创建是以字面量的形式赋值的,而字面量在类的加载后是存储在字符串常量池
StringTable中的。
在jdk6.0时,字符串常量池是放在方法区中(此时方法区称为永久代,占用虚拟机内存);jdk7.0时,字符串常量池被转移到堆中;jdk8.0后,字符串常量池仍然被保留在堆中(而永久代的概念被元空间取代,占用本地内存)。
问:为什么字符床常量池的位置需要从方法去到堆中区?
答: 因为如果StringTable放在方法区中,只有在full GC的时候才会回收空间,回收的效率并不高。实际中字符串会被大量的创建,由于回收效率低,更加容易导致方法区内存不足,而放在堆中,可以利用minor/major/full gc回收,回收效率更高。
StringTable的一个特点是不能存放两个相同内容的字符串的,且不可更改(只能重新创建)。在jdk7.0之前,StringTable底层是固定大小的Hashtable,长度为1009,所以不存在相同的两个字符串。jdk7.0之后,长度不固定,默认设置为60013。当字符串常量池中存储的字符串过多时,会导致哈希冲突严重,导致链表的长度变长,从而导致在调用String.intern()时降低性能。
结合上面两点可以得出,变量s1和s2指向的是字符串常量池中的同一个“abc”,因此判断结果为true。
String s1 = "abc";
String s2 = "abc";
s1 = "hello";
//s1 += "def";拼接/replace函数同样是需要在StringTable重新创建
System.out.println(s1 == s2);//false
System.out.println(s1);//hello
System.out.println(s2);//abc
如果给s1重新赋值“hello”,会在字符串常量池新建一个“hello”,然后s1的指针指向“hello”,所以判断结果为false。
- +=拼接/replace()函数同样是需要在StringTable重新创建;
问:String对象的创建通过字面量和new的方式两者有什么不同?
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc");
String s4 = new String("abc");
System.out.println(s1 == s2);//true
System.out.println(s3==s4);//false
Person p1 = new Person("Tom",12);
Person p2 = new Person("Tom",12);
System.out.println(p1.name == p2.name);//true
答:通过字面量的方式创建的对象,变量存储的指针地址是直接指向字符串常量池的;
而通过new的方式创建对象,变量存储的指针地址指向堆空间中开辟的value数据的地址,数组的指针地址会指向字符串常量池中的“abc”。同理,Person的例子也是一样的,“Tom”是字面量存储在字符串常量池中,p1指针指向堆中对象,name指向字符串常量池中的“Tom”。而字符串常量池是共享的,字符不可重复的,所以判断结果为true。
问:解释下列结果。
String s1 = "jvm";
String s2 = "hotspot";
String s3 = "jvm" + "hotspot";
String s4 = "jvmhotspot";
String s5 = s1 + "hotspot";
String s6 = s1 + s2;
String s7 = (s1 + s2).intern();
System.out.println(s3 == s4);//true
System.out.println(s3 == s5);//false
System.out.println(s3 == s6);//false
System.out.println(s3 == s7);//true
答:
- 拼接的两边都是字面量的话,结果在常量池中;(实际上,这个属于编译期的优化结果)
- 拼接的两边中有一边是变量,那么结果放在堆中;(实际上,相当于在堆中new String(),内容为拼接的结果)
- 如果利用intern()方法,在常量池中新建字符串对象,返回该对象的引用。(就是说intern()会判断在字符串常量池中是否有所需的字符串,有,返回常量池中该字符串的引用,没有的话,先创建再返回引用)
- 注意:
如果s1被final修饰,那么s3s5返回true;
如果s1、s2被final修饰,那么s3s5和s3 == s6返回true;
问:底层分析字符串拼接的一边或者两边是变量的情况。
答:
String s1 = "a";
String s2 = "b";
String s3 = s1 + s2;
s1 + s2执行细节如下:
1、创建StringBuilder对象,StringBuilder s = new StringBuilder()
2、s.append(“a”)
3、s.append(“b”)
4、s.toString() //约等于new String(“ab”):因为正常new String(“ab”)会在堆中和常量池中有两个对象,而toString中的没有在常量池中生成,为什么,我也不清楚。
问:几道题你看着办?
题一
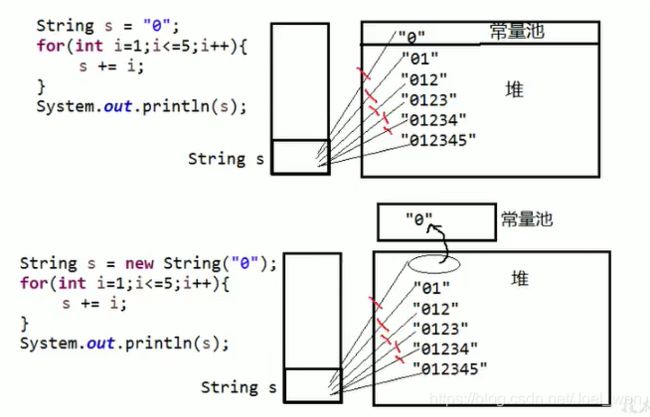
解析:略。
题二
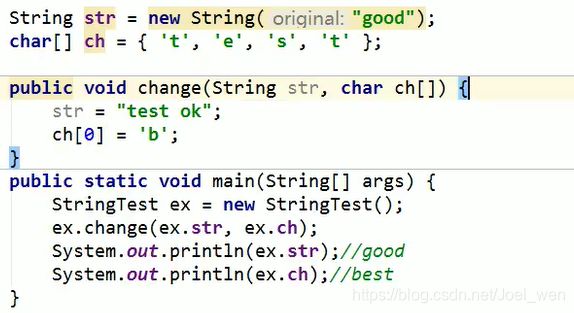
解析:函数调用,把变量str指向的地址赋给形参str,根据string的不可变性,形参变成“test ok”,需要重新创建一个字符串,所以形参str保存的地址变成“test ok”字符串存储的地址,但这不影响原来的变量str的指向地址。
而形参ch指向数组,数组可以修改,所以内容被改变。
题三

解析:
new String("ab");:2个对象。一个是new的String对象”ab“,一个是再字符串常量池中的“ab”。
new String("a") + new String("b");*6个对象。**第一个是因为拼接操作new的StringBuilder对象,第二个是new的String对象"a",第三个是字符串常量池中的”a“,第四个是new的String对象"b",第五个是字符串常量池中的”b“,第六个是StringBuilder.toString方法调用时new的String对象。
从上述可以看出,原始题的字符串常量池中有”ab“字符串,而扩展题里的字符串常量池中没有。这里就是StringBuilder的toString(),为什么常量池里没有我也不知道!!!
题四
// intern一
String a = new String("1").intern();
// intern二
String b = new String("1");
b.intern();
//intern三
String d = b.intern();
String c = "1";
System.out.println(a == c);// true
System.out.println(b == c);// false,虽然b调用了intern,但是没有改变b,intern是返回地址到新变量,所以d是指向常量池的
System.out.println(d == c);// true
//说明:intern有返回值,返回值是字符串常量池的引用地址
解析:intern有返回值,调用intern的对象本身并不受影响。
题五
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
String s5 = new String("2") + new String("2");
String s6 = "22";
s5.intern();
System.out.println(s5 == s6);
}
答案:结果和jdk版本有关。主要影响就是字符串常量池位置的变化。jdk6在永久区,jdk7/8在堆。
jdk6:false+false+false;
jad7/8:false+true+false;
解析:
- 第一个结果都是false:因为s是new方式,会在堆中和常量池中创建对象”1“,而s是指向堆中”1“;虽然s调用了intern,但是不改变s指向的地址(和题四一个道理);s2指向的是创建在字符串常量池中的”1“,所以s显然不等于s2。
- 第二个结果在jdk6时是false,在jdk7/8时是true。
- jdk6: 此时,字符串常量池不在堆中,s3仅仅在堆中创建对象”11“,而字符串常量池中没有(具体原因同题三),且s3是指向堆中”11“;虽然s调用了intern,首先判断字符串常量池中没有”11“,会在字符串常量池中直接创建”11“,但是不改变s指向的地址(和题四一个道理);s4指向的是创建在字符串常量池中的”11“,所以s3显然不等于s4。
- jdk7/8: 此时,字符串常量池在堆中,s3仅仅在堆中创建对象”11“,而字符串常量池中没有(具体原因同题三),且s3是指向堆中”11“;虽然s调用了intern,首先判断字符串常量池中没有”11“,为了节省空间,并不在在常量池中创建”11“,而是创建一个指向堆空间中”11“的地址,但是不改变s指向的地址(和题四一个道理);s4间接通过字符串常量池指向堆中”11“,所以s3等于s4。
- 第三个结果都是false。第三个和第二个的差别就在于字符串常量显示创建和intern()方法调用顺序不同。由于第三个是先显示创建常量在字符串常量池,**并不会触发intern()的上述机制,**会在字符串常量池中实打实创建一个”22“,而不是向intern()一样,创建指向堆中”22“的地址。
总结:由于jdk版本的不同,intern()方式的实现原理发生了些许的变化。
题六
String s = new String("a") + new String("b");
String s2 = s.intern();
System.out.println(s == "ab");//jdk6:false jdk7:true
System.out.println(s2 == "ab");//jdk6:true jdk7:true
解析:”ab“字面量本身首先是存储在字符串常量池中的,这点是需要先明确的。上述==比较,比较的是地址。
一个问题?题目中的”ab“是指存放在哪里的?如果内存中堆中和字符串常量池都有呢?
强记:”ab“在堆中和字符串常量池都有,那么指的在字符串常量池的”ab“,只有一个有,那就是哪一个。
jdk6中,s存的是指向堆中的地址,s2存的指向字符串常量池的地址,”ab“有两个,所以指的常量池的地址,所以false+true;
jdk7中,s存的是指向堆中的地址,s2存的也是字符串常量池中存储的是堆中”ab“的地址,”ab “只有一个,所以地址也是堆中的,所以true+true。
String和基本数据类型、包装类、StringBuffer、StringBuilder的转换
String–>基本数据类型: Integer.parseInt()、Float.parseFloat…
String s1 = "123";
int i1 = Integer.parseInt(s1);
基本数据类型–>String:String.valueOf()
int i1 = 123;
String s1 = String.valueOf(i1);
String s2 = i1 + "";
String–>StringBuffer、StringBuilser:
String s1 = "abc";
StringBuffer sb1 = StringBuffer(s1);
StringBuilder sb2 = StringBuilder(s1);
StringBuffer、StringBuilser–>String:
StringBuffer sb1 = StringBuffer("abc");
String s1 = String(sb1);
String s2 = sb1.toString();
String、StringBuffer、StringBuilder
问:三者异同?
(底层存储jdk9开始从char[]数组变成byte[]数组)
String:不可变字符序列,声明为fianl,不可扩容,效率最低
StringBuffer:可变字符序列,可扩容,继承于AbstractStringBuilder,线程安全,效率低
StringBuilder(jdk5.0):可变字符序列,可扩容,继承于AbstractStringBuilder,线程不安全,效率高
StringBuffer、StringBuilder初始化底层数组长度为:字符串长度+16
扩容机制:x2+2;