计算机网络(IP/TCP/HTTP)
计算机网络
1.OSI七层协议以及四层协议
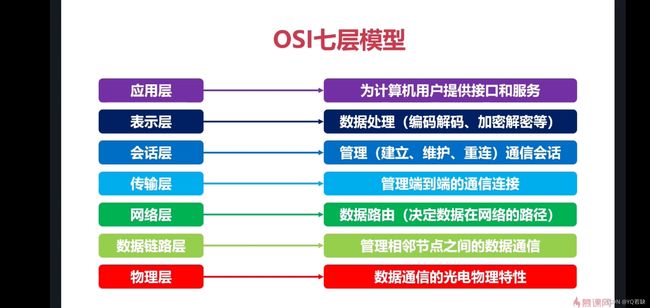
实际使用时只包含四层协议:从上到下依次是
- 应用层(http)
- 传输层(tcp/udp)
- 网络层(ip)
- 网络接口层(以太网协议)


对于不同层次的协议:

网络中具体的传输过程
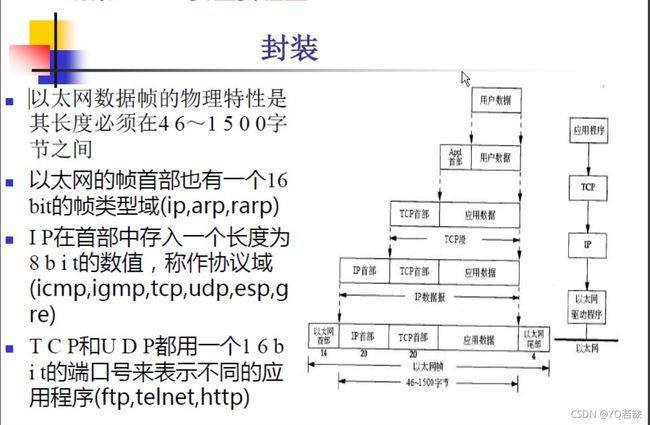
从上图可见传输的数据每经过一层,就会添加该层的协议首部,相反的在到达目标地址时,每经过一层就会解析出对应层的首部。
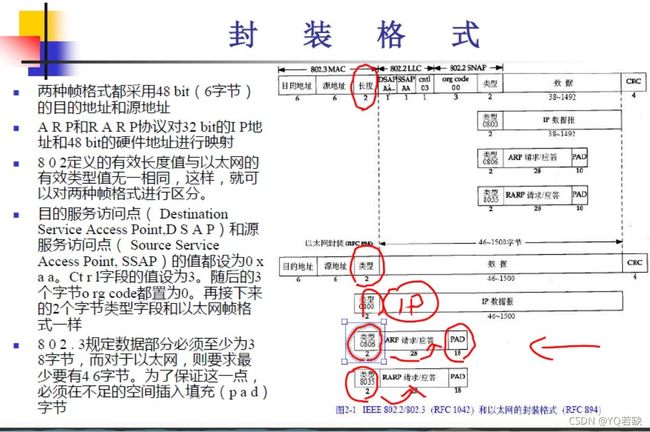
2.链路层(以太网和IEEE 802)

以太网的封装较为简单,共14字节,目的地址,源地址,类型。

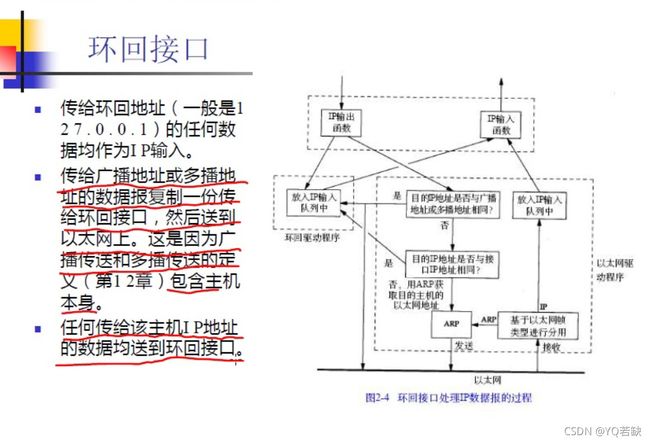
2.1 本地回环
2. 2 ARP(Address Resolution Protocol)
简单来说,他是通过IP地址来动态获取MAC地址的一种协议,使用方式是通过广播发送ARP请求包。

3.网络层(IP和ICMP)
3.1 IP

IP首部格式解析(Internet Protocal)

IP抓包如下

IP分片
在IP的出接口进行分片


3.2 ICMP
ICMP的消息可以分为两类:
- 通知出错原因的错误消息。
- 用于诊断的查询消息。
ICMP封装再IP数据报内部,被认为是IP的附属协议。

3.3 PING

3.4 Traceroute
用的UDP的包

3.5 IP选路

4.传输层(TCP和UDP)
4.1 TCP
TCP提供一种面向连接的,可靠的字节流服务。

TCP首部格式解析(Transmission Control Protocol)
各部分说明
- 源端口号( 16 位):它(连同源主机 IP 地址)标识源主机的一个应用进程。
- 目的端口号( 16 位):它(连同目的主机 IP 地址)标识目的主机的一个应用进程。这两个值 加上 IP 报头中的源主机 IP 地址和目的主机 IP 地址唯一确定一个 TCP 连接。
- 顺序号 seq( 32 位):用来标识从 TCP 源端向 TCP 目的端发送的数据字节流,它表示在这个 报文段中的第一个数据字节的顺序号。
- 确认号 ack( 32 位):包含发送确认的一端所期望收到的下一个顺序号。
- 控制位( control flags , 6 位):在 TCP 报头中有 6 个标志比特,它们中的多个可同时被设 置为 1 。依次为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Im2hbSXA-1630416126449)(image/TCP控制位.png)] - 窗口大小( 16 位):数据字节数,表示从确认号开始,本报文的源方可以接收的字节数,即源 方接收窗口大小。窗口大小是一个 16bit 字段,因而窗口大小最大为 65535 字节
TCP特点及其目的
TCP通过检验和、序列号、确认应答、重发控制、连接管理以及窗口控制的机制实现可靠性传输。
- 通过序列号(sqe)与确认应答(ack)提高可靠性。
- 超时重发机制(当发送的数据在一定时间没有收到确认应答时,需要重发数据)
- 利用窗口控制提高速度(这里有一个面试题,注意)
TCP三次握手

详解
第一次握手:主机 A 发送位码为 SYN=1,随机产生 seq=1234567 的数据包到服务器,主机 B 由 SYN=1 知道,A 要求建立联机;
第二次握手:主机 B 收到请求后要确认联机信息,向 A 发 送 ACK=1 ack =( 主 机 A 的 seq+1),SYN=1,随机产生 seq=7654321 的包
第三次握手:主机 A 收到后检查 ack number 是否正确,即第一次发送的 seq number+1,以及位码 ACK 是否为 1,若正确,主机 A 会再发送,ACK=1 ack number=(主机 B 的 seq+1),主机 B 收到后确认
TCP四次挥手

详解
TCP 建立连接要进行三次握手,而断开连接要进行四次。这是由于 TCP 的半关闭造成的。因为 TCP 连 接是全双工的(即数据可在两个方向上同时传递)所以进行关闭时每个方向上都要单独进行关闭。这个单方向的关闭就叫半关闭。当一方完成它的数据发送任务,就发送一个 FIN 来向另一方通告将要终止这个方向的连接。
- 关闭客户端到服务器的连接:首先客户端 A 发送一个 FIN,用来关闭客户到服务器的数据传送, 然后等待服务器的确认。其中终止标志位 FIN=1,序列号 seq=u
- 服务器收到这个 FIN,它发回一个 ACK,确认号 ack 为收到的序号加 1。
- 关闭服务器到客户端的连接:也是发送一个 FIN 给客户端。
- 客户段收到 FIN 后,并发回一个 ACK 报文确认,并将确认序号 seq 设置为收到序号加 1。 首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
2MSL(maximum segment lifetime)的作用: - 保证服务端能够接收到客户端的最后回应。
- 确保所有老连接的数据在网络中消失。
TIME_WAIT状态的作用
主动关闭的Socket端会进入TIME_WAIT状态,并且持续2MSL时间长度,MSL就是maximum segment lifetime(最大分节生命期),这是一个IP数据包能在互联网上生存的最长时间,超过这个时间将在网络中消失。MSL在RFC 1122上建议是2分钟,而源自berkeley的TCP实现传统上使用30秒,因而,TIME_WAIT状态一般维持在1-4分钟。
TIME_WAIT状态存在的理由:
1)可靠地实现TCP全双工连接的终止
在进行关闭连接四路握手协议时,最后的ACK是由主动关闭端发出的,如果这个最终的ACK丢失,服务器将重发最终的FIN,因此客户端必须维护状态信息允 许它重发最终的ACK。如果不维持这个状态信息,那么客户端将响应RST分节,服务器将此分节解释成一个错误(在java中会抛出connection reset的SocketException)。因而,要实现TCP全双工连接的正常终止,必须处理终止序列四个分节中任何一个分节的丢失情况,主动关闭 的客户端必须维持状态信息进入TIME_WAIT状态。2)允许老的重复分节在网络中消逝
TCP分节可能由于路由器异常而“迷途”,在迷途期间,TCP发送端可能因确认超时而重发这个分节,迷途的分节在路由器修复后也会被送到最终目的地,这个 原来的迷途分节就称为lost duplicate。在关闭一个TCP连接后,马上又重新建立起一个相同的IP地址和端口之间的TCP连接,后一个连接被称为前一个连接的化身 (incarnation),那么有可能出现这种情况,前一个连接的迷途重复分组在前一个连接终止后出现,从而被误解成从属于新的化身。为了避免这个情 况,TCP不允许处于TIME_WAIT状态的连接启动一个新的化身,因为TIME_WAIT状态持续2MSL,就可以保证当成功建立一个TCP连接的时 候,来自连接先前化身的重复分组已经在网络中消逝。
TCP交互数据流
对于数据量小的报文,收集起来一起发送。

TCP成块数据流
对于成块数据流,TCP采用滑动窗口协议。该协议允许发送方在停止并等待确认前可以连续发送多个分组。由于发送方不必每发一个分组就停下来等待确认,因此该协议可以加速数据的传输。


TCP超时和重传


4.2 UDP
UDP不会关心分片问题,IP会进行分片。

UDP首部格式解析(User Datagram Protocol)

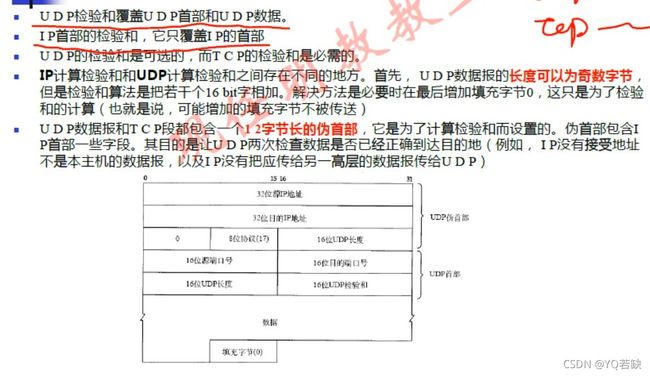
4.3 广播与多播
5.应用层(HTTP)
5.1 FTP
数据传输协议

控制信道建立连接,数据信道进行数据传输。


5.2 Telent
不安全,交互式数据流

5.3 DNS
Domain Name System—>域名服务器
- 是一个位于应用层的协议。
- 其主要功能是将域名转化未IP地址。
5.4 HTTP
概念
Hyper Text Transfer Protocol 超文本传输(转移)协议
- 传输协议:定义了,客户端和服务器端通信时,发送数据的格式
- 特点:
- 基于TCP/IP的高级协议
- 默认端口号:80
- 基于请求/响应模型的:一次请求对应一次响应
- 无状态的:每次请求之间相互独立,不能交互数据
- 历史版本:
- 1.0:每一次请求响应都会建立新的连接
- 1.1:复用连接
HTTP1.1 默认采用持久连接(Keep-Alive)
请求头部和响应头部都有一个key-value
Connection: Keep-Alive,这个键值对的作用是让HTTP保持连接状态,因为HTTP 协议采用“请求-应答”模式,当使用普通模式,即非 Keep-Alive 模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP 协议为无连接的协议);当使用 Keep-Alive 模式时,Keep-Alive 功能使客户端到服务器端的连接持续有效。在HTTP 1.1版本后,默认都开启Keep-Alive模式,只有加入加入
Connection: close才关闭连接,当然也可以设置Keep-Alive模式的属性,例如Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。
请求消息数据格式
- 请求行
请求方式 请求uri 请求协议/版本
GET /login.html HTTP/1.1- 请求方式:
- HTTP协议有7中请求方式,常用的有2种
- GET:
- 请求参数在请求行中,在url后。
- 请求的url长度有限制的
- 不太安全
- POST:
- 请求参数在请求体中
- 请求的url长度没有限制的
- 相对安全
- GET:
- HTTP协议有7中请求方式,常用的有2种
- 请求方式:
- 请求头:客户端浏览器告诉服务器一些信息
请求头名称: 请求头值- 常见的请求头:
- User-Agent:浏览器告诉服务器,我访问你使用的浏览器版本信息
- 可以在服务器端获取该头的信息,解决浏览器的兼容性问题
- Referer:
http://localhost/login.html- 告诉服务器,我(当前请求)从哪里来?
- 作用:
- 防盗链:
- 统计工作:
- 作用:
- 告诉服务器,我(当前请求)从哪里来?
- User-Agent:浏览器告诉服务器,我访问你使用的浏览器版本信息
- 常见的请求头:
- 请求空行
空行,就是用于分割POST请求的请求头,和请求体的。 - 请求体(正文):
- 封装POST请求消息的请求参数的
- 字符串格式:
POST /login.html HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Referer: http://localhost/login.html
Connection: keep-alive
Upgrade-Insecure-Requests: 1
\r\n
username=zhangsan
响应消息数据格式
-
请求消息:客户端发送给服务器端的数据
- 数据格式:
- 请求行
- 请求头
- 请求空行
- 请求体
- 数据格式:
-
响应消息:服务器端发送给客户端的数据
- 数据格式:
- 响应行
- 组成:协议/版本 响应状态码 状态码描述
- 响应状态码:服务器告诉客户端浏览器本次请求和响应的一个状态。
- 状态码都是3位数字
- 分类:
- 1xx:服务器就收客户端消息,但没有接受完成,等待一段时间后,发送1xx多状态码
- 2xx:成功。代表:200
- 3xx:重定向。代表:302(重定向),304(访问缓存)
- 4xx:客户端错误。
- 代表:
- 404(请求路径没有对应的资源)
- 405:请求方式没有对应的doXxx方法
- 代表:
- 5xx:服务器端错误。代表:500(服务器内部出现异常)
- 响应头:
- 格式:头名称: 值
- 常见的响应头:
- Content-Type:服务器告诉客户端本次响应体数据格式以及编码格式
- Content-disposition:服务器告诉客户端以什么格式打开响应体数据
- 值:
- in-line:默认值,在当前页面内打开
- attachment;filename=xxx:以附件形式打开响应体。文件下载
- 值:
- 响应空行
- 响应体:传输的数据
- 响应行
- 响应字符串格式
- 数据格式:
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Length: 101
Date: Wed, 06 Jun 2018 07:08:42 GMT
\r\n
$Title$
hello , response
Http与Https
对称加密
存在的问题:
对称加密存在密钥协商问题。也就是说在协商密钥的时候可能被发现协商的密钥是什么,这样等同于不加密。

非对称加密
基于对称加密存在的问题,又有了非对称加密。非对称加密算法需要一组密钥对,分别是公钥和私钥,这两个密钥是成对出现的。公钥加密的内容需要用私钥解密,私钥加密的内容需要用公钥解密!私钥由服务器自己保存,公钥发送给客户端。客户端拿到公钥后就可以对请求进行加密后发送给服务端了,这时候就算被小王截获,小王没有私钥也无法解密发送的内容,这样确保了客户端发送到服务端数据的“安全”!但是由于公钥也需要通过网络发送给客户端,同样能被小王截获,这样服务器私钥加密后的内容依然可以被小王截获并解密,并且非对称加密的效率很低。
对称加密和非对称加密都存在密钥传输的问题,但是至少非对称加密可以保证客户端传输给服务端的内容无法被“破解”,而对称加密算法性能又比较好,那我们是不是可以这样子呢。第一次通信的时候服务端发送公钥给客户端,由客户端产生一个对称密钥,通过服务端的公钥加密后发送给服务端,后续的交互中都通过对称密钥进行加密传输。也就是说先通过非对称密钥加密对称密钥,通过对称密钥加密实际请求的内容。

上面的方案看起来天衣无缝,小王拿到数据后貌似就无偿下手了,但是真的就天意无缝了吗?我们看看下图
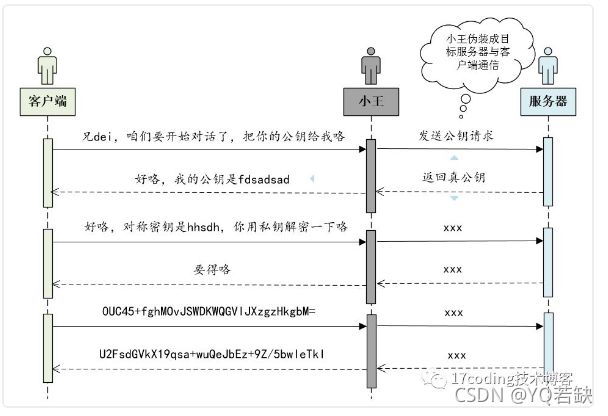
也就是说小王可以伪装成服务器,与客户端进行通信。类似于你与服务端之间多了一个中间商!也就是说协商密钥的过程依然存在漏洞!
有点脑阔疼!还能不能让我安全的上网了!就没有更安全的机制了么? 在协商密钥的过程中,客户端怎么能确定对方是真正的目标服务器呢?怎么证明服务器的身份呢?我们先了解一下数字证书!
数字证书
我们生活中有各种证,有能证明自己是个有身份的人的身份证,有能证明自己读了几年书的毕业证。这些证都是由某些权威机关认证、无法伪造的,能证明自己身份的凭据。那服务器是不是也能有个类似身份证的东西,在与服务器进行通信的时候证明自己确实是目标服务器而不是小王伪造的呢?在生活中这些证件都是事实在在能看得见摸得着的,而计算机中的证书是虚拟的,看得见但是摸不着,是数据形式记录的,所以叫数字证书!
客户端第一次与服务器进行通信的时候,服务器需要出示自己的数字证书,证明自己的身份以及自己的公钥。
那这个数字证书怎么产生的呢?总不能是服务器自己造一个吧?上面说到了我们生活中的证书是由权威机构颁发的、无法伪造的,比如身份证就是由派出所发证、毕业证由教育部发证,如果需要验证真假,只需要上相关的系统输入编号查询就能查到了!那我们数字证书也应该有这两个特性-权威机构颁发、防伪
Https
本文的标题是HTTPS,但是到目前为止HTTPS只字未提!其实HTTPS=HTTP+SSL,在HTTP层和TCP之间加了一个SSL/TLS层,如下图:
HTTPS = HTTP + 加密 + 认证 + 完整性保护
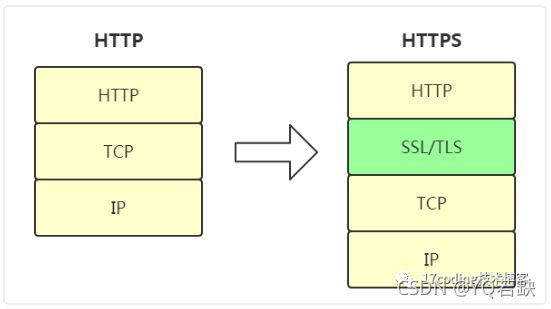
SSL(Secure Sockets Layer)中文叫“安全套接层”,后来由于广泛应用,SSL标准化之后就改名为TLS(Transport Layer Security)安全传输层协议,其实HTTPS就是通过上面说到的那些手段来解决网络上可能存在的数据泄密、篡改、假冒的这些问题,保证网络传输的安全的啦!
HTTPs通信具体流程:
- 客户端向服务端发送建立连接的请求,服务端将认证证书发个服务端。
- 客户端拿到认证的证书,使用证书的公钥进行解密,得到证书,以及服务器的公钥。
- 使用服务器的公钥对对称密钥进行加密,并发送给服务器端。
- 双方使用协商过后的对称密钥进行通信。
引用:
- HTTP协议的Keep-Alive 模式
- 图解HTTP
- 图解TCP/IP
- TCP/IP教程
- 慕课网教程