测序是测量你的遗传信息
测序是测量你的遗传信息
遗传信息,大家应该都清楚,如果不清楚的话麻烦各位翻一翻高中的肺炎双球菌实验,讲的就是啥是遗传信息,如何发现遗传信息的。
放张图,方便大家回忆。
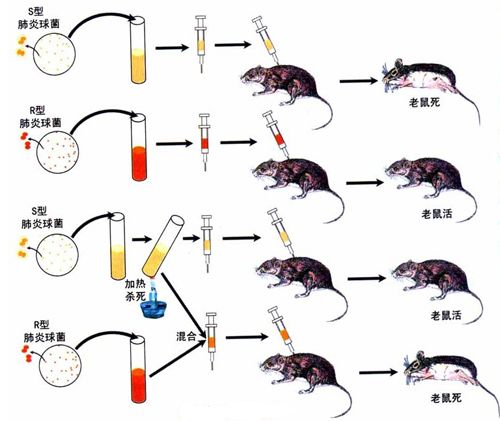
原来的科学家们通过老鼠死没死,最终得到的结论是DNA是主要的遗传物质,部分物种的遗传物质是RNA。
在弄清楚这个事情之后,大家也都知道沃森和克里克还有一些被遗忘的科学家一起努力弄清楚了DNA是双螺旋结构。并且(A-T,G-C)。
第一代测序技术
一、简介
第一代DNA测序技术用的是1975年由桑格(Sanger)和考尔森(Coulson)开创的链终止法或者是1976-1977年由马克西姆(Maxam)和吉尔伯特(Gilbert)发明的化学法(链降解). 并在1977年,桑格测定了第一个基因组序列,是噬菌体X174的,全长5375个碱基。自此,人类获得了窥探生命遗传差异本质的能力,并以此为开端步入基因组学时代。研究人员在Sanger法的多年实践之中不断对其进行改进,在2001年,完成的首个人类基因组图谱就是以改进了的Sanger法为其测序基础。
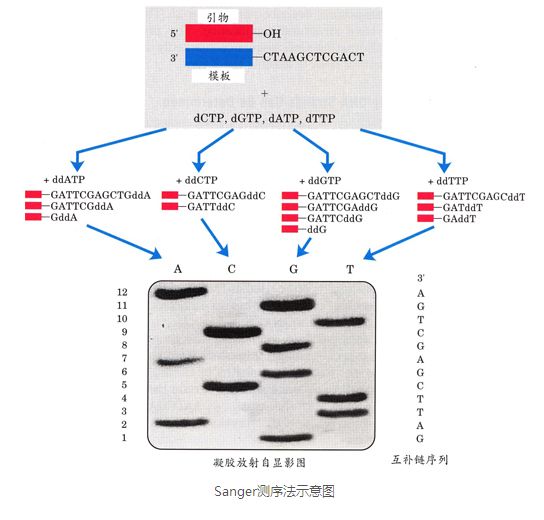
一代测序技术的原理见下图。再模板中首先分别加入A、T、G、C和四种ddNTP双脱氧核苷酸(加入ddNTP序列合成会终止),如下图第一个加入ddATP,这样每一个位置上的A位置会大量的被ddATP替代,然后终止,然后再分别加入其他的ddNTP,让他随机终止。这样对得到的这些序列进行跑胶。就得到了如下的胶图。根据ACGT的加入顺序和位置,获取信息。这个方法准确率高,费用高,是先合成,再测序的。
桑格先生13年与世长辞,但是一代测序技术在他发明之后经过各个单位的改进,今天还被大量使用。
NCBI的悼文:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3903207/
Of the three main activities involved in scientific research, thinking, talking, and doing, I much prefer the last and am probably best at it. I am all right at the thinking, but not much good at the talking.
—Frederick Sanger, 1988
二、一代测序主要应用方向
大伙肯定好奇啥是黄金测序,标题很抢眼,但的的确确存在测序的黄金标准:一代测序了,小编故称之为黄金测序。
今天给你们带来一些低门槛纯经验的黄金测序(哈哈就是一代测序了)中你应该知道的point:高通量测序最近这几年很火越来越火,但是世界上更多的还是一帮天天做分子克隆、养细胞、养细菌、杂蛋白的生物学家,究其原因Sanger测序还是测序届的金标准,由于精确度高于2、3代测序且保持大白菜价格使之地位稳固。应用范围:De Novo测序、重测序: 如突变检测、SNPs、插入、缺失克隆产物验证、比较基因组、分型: 如微生物和真菌鉴定、HLA分型、病毒分型
、其它: 如甲基化分析(重亚硫酸盐测序)和SAGE(基因表达串联分析)方法
、临床应用:肿瘤突变基因的检测和肿瘤个体化治疗。
三、一代测序注意问题
1.测序结果不到800Bases是什么原因?
(1)G/C rich、G/C Cluster。
这种情况一般表现为测序信号突然减弱或消失(图1,图2)
如在DNA样品中的DNA序列分布匀称,没有复杂结构时,正常的测序反应能保证达到800Bases以上。但有一些DNA样品立体结构复杂,造成聚合酶延伸反应终止,测序信号突然减弱或消失,或者测序结果出现套峰现象,出现这些现象的原因由DNA模板本身所造成。

图1 GC引起的信号减弱
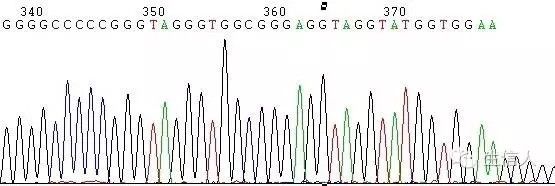
图2 G/C rich引起的信号消失
(2)A、T的Poly结构
这种情况一般表现为A、T连续结构后面的测序结果出现套峰。根据文献记载。原因在于聚合酶进行聚合反应时,由于A或T的连续,聚合酶难以识别完整的每个A或T,在某个A或T的后面便开始进行A或T连续结构以后序列的聚合反应(打滑现象),造成测序结果紊乱,出现套峰。一般在多少个A或T的后面能出现这种情况呢?现在还没有这方面的报道。根据我们的经验,这一情况的出现和A或T的连续结构后面的序列的排列情况有着直接的关系。有时10多个A或T的连续结构后面便出现套峰,但有时60~70个A或T的连续结构后面的序列也一样可以完整地读出来。具体情况还有待考证。一般来说,PCR片段直接测序时,A或T的连续结构后面的序列测序结果都会出现套峰。原因在于测序时经历了PCR反应及测序反应(测序反应本身也是PCR反应)二次聚合酶的打滑现象。

图3 polyA引起的套峰
(3)原因不明的复杂结构,测序结果出现突然信号减弱或消失
从序列上看,DNA碱基排列并无特别异常。估计是DNA整体出现复杂结构,从某一位置开始聚合酶的聚合反应便无法进行。
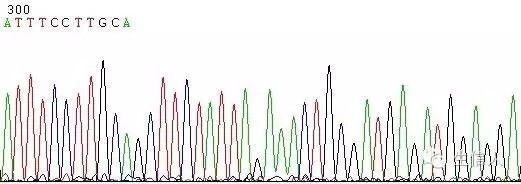
图4 复杂结构引起的信号中断
2.出现套峰是什么原因?
在测序反应中,模板或引物的原因都可能造成套峰的形成,归结其形成原因有以下几点:
(1)测序引物在模板上有两个结合位点(图5);
(2)模板不纯,如果是质粒或是菌液,原因是非单克隆(图6),如果是PCR,原因为非特异性条带(图7);
(3)模板序列的特殊结构,如poly结构、发卡结构等(图8);
(4)引物降解,或引物不纯(图9,图10)。
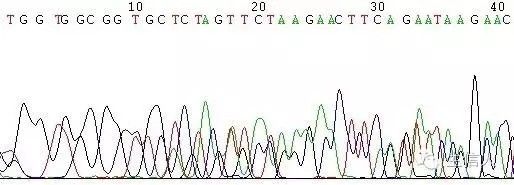
图5 双引物结合位点引起的套峰

图6 由于质粒或菌液为非单克隆引起的套峰
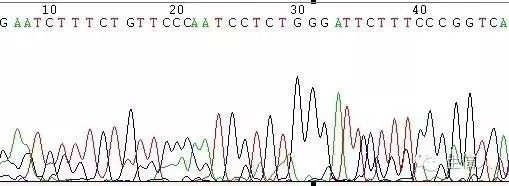
图7 PCR为非特异性条带引起的套峰
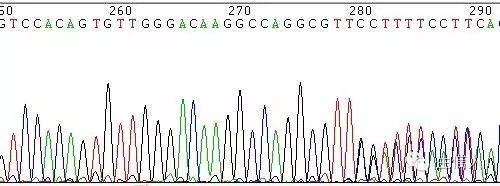
图8 模板特殊结构引起的套峰
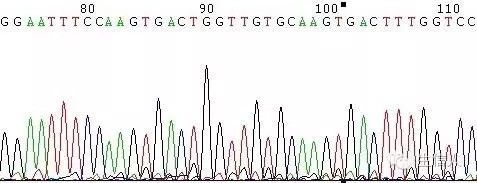
图9 引物轻微降解或引物不纯引起的套峰
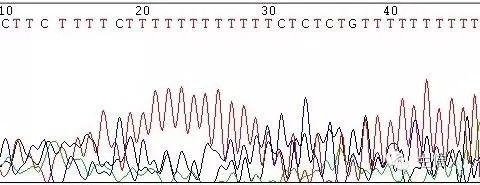
图10 引物严重降解或引物不纯引起的套峰
四、解决方案汇总
1.样品测序无信号
可能是引物结合位点不存在或被破坏;建议更换引物测序或重新提供样品测序。
2.样品测序信号差
可能是引物或模板的质量不高或是引物和模板的匹配性不好引起的,也可能是样品浓度偏低;建议提供高质量样品测序。
3.样品测序衰减
可能是由于特殊结构如Poly结构、重复序列、回文结构、发卡结构、GCrich、AT富集等导致的测序衰减,由于是样品本身结构问题无法优化建议反向测序进行拼接以得到完整序列,还有一种衰减的情况就是在一段正常峰型后逐渐衰减,可能是模板量反应量不足导致,建议制备高浓度模板测序。
4.样品测序套峰
套峰细分的话有如下几种情形:
①全双峰:多引物结合位点(针对菌液、质粒样品),非特异性扩增(针对PCR产物);
②前双峰:多引物结合位点,其中一套模板测序中断(针对菌液、质粒样品),多引物结合位点(PCR未纯化样品),引物二聚体或小片段干扰(针对PCR已纯化样品);
③中间双峰:非单克隆(针对质粒、菌液样品),碱基缺失或等位基因双模板(针对PCR未纯化样品);
④后双峰:非单克隆(针对菌液、质粒样品),碱基缺失(针对PCR样品);
针对二聚体及小片段干扰的情况建议电泳切胶回收纯化;针对多引物结合位点的情况建议更换引物测序或反方向测通样品;针对碱基缺失建议克隆测序;针对非单克隆建议在克隆无误的前提下重新挑取单克隆测序;针对非特异性扩增建议优化反应条件重新制备样品测序;针对等位基因双模板建议克隆测序。
5.样品测序中断
可能样品存在特殊高级结构,导致dNTP和ddNTP在某一碱基位点后无法与模板结合,测序酶无法继续延伸,建议使用反向引物进行测序经拼接后可以得到完整序列;或酶切后亚克隆测序。
6.样品测序移码
测序从开端发生移码可能是引物发生降解,建议重新提供引物;测序局部出现移码,可能样品存在特殊高级结构,建议反向测通。
7.样品测序底峰干扰
可能测序引物不纯,建议将引物进行PAGE胶纯化后在进行测序或重新提供引物测序;可能测序样品不纯,混有正、反向引物,建议重新制备样品测序。
第二代测序技术
一、简介
小编上大学的时候,二代测序技术主要有三家公司,罗氏的454技术,illumina的Hiseq和Solexa技术还有ABI的Solid技术。不管是哪家公司,其具体原理如何,暂且不说。他们都是边合成边测序,也就是说通过在序列合成的同时通过各种标记进行实时的序列识别。接下来,小编还没有毕业,罗氏和ABI的测序技术就提前毕业了。只剩下一家illumina。熟悉二代测序的,都清楚,他家是双端测序,通量高。Illumina基本上每天推出一款新的产品。并且通量越来越大,成本越来越低。说最近今年的例子,14,15年推出的Hiseq 4000 15,16年推出的X ten(10台hiseq X)国内有很多公司引进了这套设备。北京诺禾致源,药明康德等。目前国内的二代测序通量基本上满足了国内的科研需要和临床应用需求。由于先动优势,其他的测序公司也就放弃了在Xten市场上与诺禾进行角逐,转而成为诺禾测序市场上渠道客户。这样看来华小之间,相爱相杀。17年南京诺禾(背后有资本的力量,目前市场上的好多做健康管理,基因检测的都将从这里走渠道。),其实就是委托诺禾进行运营和管理,毕竟人家经验丰富。引入25台Novaseq测序仪。这些测序仪将主要用于生命科学健康方向。可以预见的将来,诺禾将成为二代测序市场的占用者,有一句话说的好,诺禾测序仪抖一抖,好几百家公司的数据都不合格。
由于二代测序需要对荧光信号进行识别,但是由于荧光信号较弱,因此需要进行扩增建库。也就是这一步导致二代测序存在偏好性。

二、主要应用方向
二代测序目前是科研市场上的主力,广泛的使用在物种基因组测序,转录组测序,群体测序上。另外这两年也在寻求医学上的发展,随着成本的降低,其在医学市场上的应用将会越来越多。
三、二代测序相关的名词解释
什么是高通量测序?
高通量测序技术(High-throughputsequencing,HTS)是对传统Sanger测序(称为一代测序技术)革命性的改变, 一次对几十万到几百万条核酸分子进行序列测定, 因此在有些文献中称其为下一代测序技术(next generation sequencing,NGS )足见其划时代的改变, 同时高通量测序使得对一个物种的转录组和基因组进行细致全貌的分析成为可能, 所以又被称为深度测序(Deep sequencing)。
什么是基因组重测序(Genome Re-sequencing)
全基因组重测序是对基因组序列已知的个体进行基因组测序,并在个体或群体水平上进行差异性分析的方法。随着基因组测序成本的不断降低,人类疾病的致病突变研究由外显子区域扩大到全基因组范围。通过构建不同长度的插入片段文库和短序列、双末端测序相结合的策略进行高通量测序,实现在全基因组水平上检测疾病关联的常见、低频、甚至是罕见的突变位点,以及结构变异等,具有重大的科研和产业价值。
什么是de novo测序
de novo测序也称为从头测序:其不需要任何现有的序列资料就可以对某个物种进行测序,利用生物信息学分析手段对序列进行拼接,组装,从而获得该物种的基因组图谱。获得一个物种的全基因组序列是加快对此物种了解的重要捷径。随着新一代测序技术的飞速发展,基因组测序所需的成本和时间较传统技术都大大降低,大规模基因组测序渐入佳境,基因组学研究也迎来新的发展契机和革命性突破。利用新一代高通量、高效率测序技术以及强大的生物信息分析能力,可以高效、低成本地测定并分析所有生物的基因组序列。
什么是外显子测序(whole exon sequencing)
外显子组测序是指利用序列捕获技术将全基因组外显子区域DNA捕捉并富集后进行高通量测序的基因组分析方法。外显子测序相对于基因组重测序成本较低,对研究已知基因的SNP、Indel等具有较大的优势,但无法研究基因组结构变异如染色体断裂重组等。
什么是mRNA测序 (RNA-seq)
转录组学(transcriptomics)是在基因组学后新兴的一门学科,即研究特定细胞在某一功能状态下所能转录出来的所有RNA(包括mRNA和非编码RNA)的类型与拷贝数。Illumina提供的mRNA测序技术可在整个mRNA领域进行各种相关研究和新的发现。mRNA测序不对引物或探针进行设计,可自由提供关于转录的客观和权威信息。研究人员仅需要一次试验即可快速生成完整的poly-A尾的RNA完整序列信息,并分析基因表达、cSNP、全新的转录、全新异构体、剪接位点、等位基因特异性表达和罕见转录等最全面的转录组信息。简单的样品制备和数据分析软件支持在所有物种中的mRNA测序研究。
什么是small RNA测序
SmallRNA(micro RNAs、siRNAs和 pi RNAs)是生命活动重要的调控因子,在基因表达调控、生物个体发育、代谢及疾病的发生等生理过程中起着重要的作用。Illumina能够对细胞或者组织中的全部Small RNA进行深度测序及定量分析等研究。实验时首先将18-30 nt范围的Small RNA从总RNA中分离出来,两端分别加上特定接头后体外反转录做成cDNA再做进一步处理后,利用测序仪对DNA片段进行单向末端直接测序。通过Illumina对Small RNA大规模测序分析,可以从中获得物种全基因组水平的miRNA图谱,实现包括新miRNA分子的挖掘,其作用靶基因的预测和鉴定、样品间差异表达分析、miRNAs聚类和表达谱分析等科学应用。
什么是miRNA测序
成熟的microRNA(miRNA)是17~24nt的单链非编码RNA分子,通过与mRNA相互作用影响目标mRNA的稳定性及翻译,最终诱导基因沉默,调控着基因表达、细胞生长、发育等生物学过程。基于第二代测序技术的microRNA测序,可以一次性获得数百万条microRNA序列,能够快速鉴定出不同组织、不同发育阶段、不同疾病状态下已知和未知的microRNA及其表达差异,为研究microRNA对细胞进程的作用及其生物学影响提供了有力工具。
什么是Chip-seq
染色质免疫共沉淀技术(ChromatinImmunoprecipitation,ChIP)也称结合位点分析法,是研究体内蛋白质与DNA相互作用的有力工具,通常用于转录因子结合位点或组蛋白特异性修饰位点的研究。将ChIP与第二代测序技术相结合的ChIP-Seq技术,能够高效地在全基因组范围内检测与组蛋白、转录因子等互作的DNA区段。
ChIP-Seq的原理是:首先通过染色质免疫共沉淀技术(ChIP)特异性地富集目的蛋白结合的DNA片段,并对其进行纯化与文库构建;然后对富集得到的DNA片段进行高通量测序。研究人员通过将获得的数百万条序列标签精确定位到基因组上,从而获得全基因组范围内与组蛋白、转录因子等互作的DNA区段信息。
什么是CHIRP-Seq
CHIRP-Seq( Chromatin Isolationby RNA Purification )是一种检测与RNA绑定的DNA和蛋白的高通量测序方法。方法是通过设计生物素或链霉亲和素探针,把目标RNA拉下来以后,与其共同作用的DNA染色体片段就会附在到磁珠上,最后把染色体片段做高通量测序,这样会得到该RNA能够结合到在基因组的哪些区域,但由于蛋白测序技术不够成熟,无法知道与该RNA结合的蛋白。
什么是RIP-seq
RNA Immunoprecipitation是研究细胞内RNA与蛋白结合情况的技术,是了解转录后调控网络动态过程的有力工具,能帮助我们发现miRNA的调节靶点。这种技术运用针对目标蛋白的抗体把相应的RNA-蛋白复合物沉淀下来,然后经过分离纯化就可以对结合在复合物上的RNA进行测序分析。
RIP可以看成是普遍使用的染色质免疫沉淀ChIP技术的类似应用,但由于研究对象是RNA-蛋白复合物而不是DNA-蛋白复合物,RIP实验的优化条件与ChIP实验不太相同(如复合物不需要固定,RIP反应体系中的试剂和抗体绝对不能含有RNA酶,抗体需经RIP实验验证等等)。RIP技术下游结合microarray技术被称为RIP-Chip,帮助我们更高通量地了解癌症以及其它疾病整体水平的RNA变化。
什么是CLIP-seq
CLIP-seq,又称为HITS-CLIP,即紫外交联免疫沉淀结合高通量测序(crosslinking-immunprecipitationand high-throughput sequencing), 是一项在全基因组水平揭示RNA分子与RNA结合蛋白相互作用的革命性技术。其主要原理是基于RNA分子与RNA结合蛋白在紫外照射下发生耦联,以RNA结合蛋白的特异性抗体将RNA-蛋白质复合体沉淀之后,回收其中的RNA片段,经添加接头、RT-PCR等步骤,对这些分子进行高通量测序,再经生物信息学的分析和处理、总结,挖掘出其特定规律,从而深入揭示RNA结合蛋白与RNA分子的调控作用及其对生命的意义。
什么是染色体构象捕获技术
3C 通常是用启动子或者某一个基因或者基因组某一个短的片段在邻近的几十kb或者几百kb基因组扫描可以获得相互作用区域。由于实验需要特异性引物,因而实验室相当费力的,且检测范围小。
4C同3C一样做单位点的检测,但其检测扩展到了整个基因组上。主要是引入了反向PCR,因而只需要对这一单一位点设计引物即可。
5C 做两个大片段之间相互作用点的检测,可以达到10Mb水平。其仍需使用引物,且引物设计是其技术的难点。
Hi-C 可以实现基因组对基因组水平的检测,但是获得高精度需要非常大的测序深度
ChIA-PET标在于特定的蛋白因子及其相关联的染色质相互作用.该技术将配对末端标签测序技术与ChIP相结合, 对富集了某种蛋白质的DNA 片段进行交联, 可以测定全基因组范围的特定转录因子参与的染色质远程交互作用, 从而可以呈现高特异性和高分辨率的染色质相互作用.
什么是Hi-C辅助基因组组装
Hi-C辅助基因组组装是指在已有二代或三代或光学图谱辅助组装的Draft genome序列和已知染色体数目的前提下,利用Hi-C测序数据将Draft genome序列进行染色体群组的划分,并确定各序列在染色体上的顺序和方向,使基因组组装组装水平提升到染色体水平的技术。
什么是metagenomic(宏基因组)
Magenomics研究的对象是整个微生物群落。相对于传统单个细菌研究来说,它具有众多优势,其中很重要的两点:(1) 微生物通常是以群落方式共生于某一小生境中,它们的很多特性是基于整个群落环境及个体间的相互影响的,因此做Metagenomics研究比做单个个体的研究更能发现其特性;(2)Metagenomics研究无需分离单个细菌,可以研究那些不能被实验室分离培养的微生物。
宏基因组是基因组学一个新兴的科学研究方向。宏基因组学(又称元基因组学,环境基因组学,生态基因组学等),是研究直接从环境样本中提取的基因组遗传物质的学科。传统的微生物研究依赖于实验室培养,宏基因组的兴起填补了无法在传统实验室中培养的微生物研究的空白。过去几年中,DNA测序技术的进步以及测序通量和分析方法的改进使得人们得以一窥这一未知的基因组科学领域。
什么是SNP、SNV(单核苷酸位点变异)
单核苷酸多态性singlenucleotide polymorphism,SNP 或单核苷酸位点变异SNV。个体间基因组DNA序列同一位置单个核苷酸变异(替代、插入或缺失)所引起的多态性。不同物种、个体基因组DNA序列同一位置上的单个核苷酸存在差别的现象。有这种差别的基因座、DNA序列等可作为基因组作图的标志。人基因组上平均约每1000个核苷酸即可能出现1个单核苷酸多态性的变化,其中有些单核苷酸多态性可能与疾病有关,但可能大多数与疾病无关。单核苷酸多态性是研究人类家族和动植物品系遗传变异的重要依据。在研究癌症基因组变异时,相对于正常组织,癌症中特异的单核苷酸变异是一种体细胞突变(somatic mutation),称做SNV。
什么是INDEL (基因组小片段插入)
基因组上小片段(>50bp)的插入或缺失,形同SNP/SNV。
什么是copy number variation(CNV):基因组拷贝数变异
基因组拷贝数变异是基因组变异的一种形式,通常使基因组中大片段的DNA形成非正常的拷贝数量。例如人类正常染色体拷贝数是2,有些染色体区域拷贝数变成1或3,这样,该区域发生拷贝数缺失或增加,位于该区域内的基因表达量也会受到影响。如果把一条染色体分成A-B-C-D四个区域,则A-B-C-C-D/A-C-B-C-D/A-C-C-B-C-D/A-B-D分别发生了C区域的扩增及缺失,扩增的位置可以是连续扩增如A-B-C-C-D也可以是在其他位置的扩增,如A-C-B-C-D。
什么是structure variation(SV):基因组结构变异
染色体结构变异是指在染色体上发生了大片段的变异。主要包括染色体大片段的插入和缺失(引起CNV的变化),染色体内部的某块区域发生翻转颠换,两条染色体之间发生重组(inter-chromosometrans-location)等。一般SV的展示利用Circos软件。
什么是Segment duplication
一般称为SD区域,串联重复是由序列相近的一些DNA片段串联组成。串联重复在人类基因多样性的灵长类基因中发挥重要作用。在人类染色体Y和22号染色体上,有很大的SD序列。
什么是genotype and phenotype
既基因型与表型;一般指某些单核苷酸位点变异与表现形式间的关系。
什么是Read?
高通量测序平台产生的短序列就称为reads。PE125,就是读长为125bp双端测序。
什么是Contig?
拼接软件基于reads之间的overlap区,拼接获得的序列称为Contig(重叠群),无N。
什么是Scaffold?
基因组de novo测序,通过reads拼接获得Contigs后,往往还需要构建454 Paired-end库或Illumina Mate-pair库,以获得一定大小片段(如3Kb、6Kb、10Kb、20Kb)两端的序列。基于这些序列,可以确定一些Contig之间的顺序关系,这些先后顺序已知的Contigs组成Scaffold(含有N)。
什么是Contig N50?
Reads拼接后会获得一些不同长度的Contigs。将所有的Contig长度相加,能获得一个Contig总长度。然后将所有的Contigs按照从长到短进行排序,如获得Contig 1,Contig 2,Contig 3...………Contig 25。将Contig按照这个顺序依次相加,当相加的长度达到Contig总长度的一半时,最后一个加上的Contig长度即为Contig N50。举例:Contig 1+Contig 2+ Contig 3+Contig4=Contig总长度*1/2时,Contig 4的长度即为Contig N50。Contig N50可以作为基因组拼接的结果好坏的一个判断标准。
什么是Scaffold N50?
Scaffold N50与Contig N50的定义类似。Contigs拼接组装获得一些不同长度的Scaffolds。将所有的Scaffold长度相加,能获得一个Scaffold总长度。然后将所有的Scaffolds按照从长到短进行排序,如获得Scaffold 1,Scaffold 2,Scaffold 3...………Scaffold 25。将Scaffold按照这个顺序依次相加,当相加的长度达到Scaffold总长度的一半时,最后一个加上的Scaffold长度即为Scaffold N50。举例:Scaffold 1+Scaffold 2+Scaffold 3 +Scaffold 4 +Scaffold 5=Scaffold总长度*1/2时,Scaffold 5的长度即为Scaffold N50。Scaffold N50可以作为基因组拼接的结果好坏的一个判断标准。
什么是测序深度和覆盖度?
测序深度是指测序得到的总碱基数与待测基因组大小的比值。假设一个基因大小为2M,测序深度为10X,那么获得的总数据量为20M。覆盖度是指测序获得的序列占整个基因组的比例。由于基因组中的高GC、重复序列等复杂结构的存在,测序最终拼接组装获得的序列往往无法覆盖有所的区域,这部分没有获得的区域就称为Gap。例如一个细菌基因组测序,覆盖度是98%,那么还有2%的序列区域是没有通过测序获得的。
什么是RPKM、FPKM
RPKM,ReadsPer Kilobase of exon model per Million mapped reads, is defined in thisway [Mortazavi etal., 2008]:
每1百万个map上的reads中map到外显子的每1K个碱基上的reads个数。
假如有1百万个reads映射到了人的基因组上,那么具体到每个外显子呢,有多少映射上了呢,而外显子的长度不一,那么每1K个碱基上又有多少reads映射上了呢,这大概就是这个RPKM的直观解释。
如果对应特定基因的话,那么就是每1000000 mapped到该基因上的reads中每kb有多少是mapped到该基因上的exon的read
Total exon reads
This is the number in the column with header Total exonreads in the rowfor the gene. This is the number of reads that have beenmapped to a region inwhich an exon is annotated for the gene or across theboundaries of two exons oran intron and an exon for an annotated transcript ofthe gene. For eukaryotes,exons and their internal relationships are defined byannotations of type mRNA.映射到外显子上总的reads个数。这个是映射到某个区域上的reads个数,这个区域或者是已知注释的基因或者跨两个外显子的边界或者是某个基因已经注释的转录本的内含子、外显子。对于真核生物来说,外显子和它们自己内部的关系由某类型的mRNA来注释。
Exonlength:
This is the number in the column with theheader Exon length inthe row for the gene, divided by 1000. This is calculatedas the sum of thelengths of all exons annotated for the gene. Each exon isincluded only once inthis sum, even if it is present in more annotatedtranscripts for the gene.Partly overlapping exons will count with their fulllength, even though theyshare the same region.外显子的长度。计算时,计算所有某个基因已注释的所有外显子长度的总和。即使某个基因以多种注释的转录本呈现,这个外显子在求和时只被包含一次。即使部分重叠的外显子共享相同的区域,重叠的外显子以其总长来计算。
Mapped reads
The sum of all the numbers in the column with header Totalgenereads. The Total gene reads for a gene is the total number ofreads that aftermapping have been mapped to the region of the gene. Thus thisincludes all thereads uniquely mapped to the region of the gene as well asthose of the readswhich match in more places (below the limit set in thedialog in figure 18.110) that have been allocated tothis gene's region. Agene's region is that comprised of the flanking regions(if it was specified infigure 18.110), the exons, the introns andacross exon-exonboundaries of all transcripts annotated for the gene. Thus,the sum of the totalgene reads numbers is the number of mapped reads for thesample (you can findthe number in the RNA-Seq report).map的reads总和。映射到某个基因上的所有reads总数。因此这包含所有的唯一映射到这个区域上的reads。
举例:比如对应到该基因的read有1000个,总reads个数有100万,而该基因的外显子总长为5kb,那么它的RPKM为:10^9*1000(reads个数)/10^6(总reads个数)*5000(外显子长度)=200或者:1000(reads个数)/1(百万)*5(K)=200这个值反映基因的表达水平。
FPKM(fragmentsper kilobase of exon per million fragments mapped)
FPKM与RPKM计算方法基本一致。不同点就是FPKM计算的是fragments,而RPKM计算的是reads。Fragment比read的含义更广,因此FPKM包含的意义也更广,可以是pair-end的一个fragment,也可以是一个read。
什么是转录本重构
用测序的数据组装成转录本。有两种组装方式:1,de-novo构建; 2,有参考基因组重构。其中de-novo组装是指在不依赖参考基因组的情况下,将有overlap的reads连接成一个更长的序列,经过不断的延伸,拼成一个个的contig及scaffold。常用工具包括velvet,trans-ABYSS,Trinity等。有参考基因组重构,是指先将read贴回到基因组上,然后在基因组通过reads覆盖度,junction位点的信息等得到转录本,常用工具包括scripture、cufflinks。
什么是表达谱
基因表达谱(geneexpression profile):指通过构建处于某一特定状态下的细胞或组织的非偏性cDNA文库,大规模cDNA测序,收集cDNA序列片段、定性、定量分析其mRNA群体组成,从而描绘该特定细胞或组织在特定状态下的基因表达种类和丰度信息,这样编制成的数据表就称为基因表达谱
什么是比较基因组学
比较基因组学(ComparativeGenomics)是基于基因组图谱和测序基础上,对已知的基因和基因组结构进行比较,来了解基因的功能、表达机理和物种进化的学科。利用模式生物基因组与人类基因组之间编码顺序上和结构上的同源性,克隆人类疾病基因,揭示基因功能和疾病分子机制,阐明物种进化关系,及基因组的内在结构。
什么是基因组注释
基因组注释(Genomeannotation) 是利用生物信息学方法和工具,对基因组所有基因的生物学功能进行高通量注释,是当前功能基因组学研究的一个热点。基因组注释的研究内容包括基因识别和基因功能注释两个方面。基因识别的核心是确定全基因组序列中所有基因的确切位置。
四、主要注意问题
1.建库
原理基本如下,将基因组序列采用鸟枪法打碎——俗称建库,然后采用凝胶电泳的方式将不同长度的片段分离,比如现在建库,短库一般建180bp,200bp或者300bp等。这里的180 和300 就是测序片段的长度。当然因为测序仪的读长是固定的,比如110,125,或者450等。公司现在采用的是220bp文库,读长为125bp,因为是双端测序,因此会有30bp的overlap区(这些是后期利用allpath-lg组装的必要条件)。然后大文库测序采用的时环化的技术,同样全基因组鸟枪之后,跑胶,跑出我们需要的相应的长度,比如3k,5k,7k,14k等。得到这些数据之后,再将其打断,然后测序,因为这里有一个环化的过程,所以这里的方向是RF(小文库是FR)。
2.过滤
小文库数据拿到手之后,一般要将质量较低的过滤掉,然后去掉序列两端的接头序列,而大文库处理过滤低质量和过滤掉两端接头序列之外,还要将中间的接头过滤掉。对于过滤大文库接头的程序,我推荐两个,一个是R语言写的Relox,这个要求你指定接头。还有一个就是NXtrim,美国冷泉港开发的一款专门过滤illumina公司的大文库数据接头。
3.评估
做完这些数据处理之后,一般还要对插入片段的评估。插入片段其实就是文库的大小。比如300bp的文库,插入片段就是300bp,但是我们都应该知道在目前的测序水平下,难免会有失误和误差,误差导致的后果是虽然插入片段是300bp,但是只能是平均值是300bp,存在一个方差,大概在几十bp左右。通常误差我们是可以接受的,而对于失误,我们就要把它给找出来,如果插入片段,严重偏离300bp,那么就意味着建库失败。通常我们采用的检验方法是将数据进行基因组组装,组装之后进行soap比对,然后画出比对的效率图。有人会问了难道只能组装完之后才能进行插入片段评估吗?我不知道其他的方式,只能说莫须有。
二代测序主要的使用工具,小编推荐Softberry家的工具,另外生信人是Softberry在中国的代理商。有谁想买的话,可以联系我们哦。http://www.softberry.com/
平台上提供的工具基本上从基因组,转录组,蛋白组统统都有。免费试用。

第三代测序技术
一、简介
第三代测序技术目前在市场上较为活跃的是Pacbio公司的RS II系列 和Sequl系列。二代测序主要的长度较短的问题,Pacbio将会彻底给予解决,目前其读长在9Kb以上,准确性在85%以上。通量较二代差距很大,目前Sequl的一个cell可以产出5 Gb左右。这个通量目前对于科研市场是消费的起的,但是对于临床检测,成本较高。不过值得庆幸的是,他们的CTO承诺18年一个cell可以产出150Gb,到那个时候,基本上就是1万元denovo 一个人。这对于复杂疾病的破译非常具有意义。

第三代测序技术是指单分子测序技术。DNA测序时,不需要经过PCR扩增,实现了对每一条DNA分子的单独测序。第三代测序技术也叫从头测序技术,即单分子实时DNA测序。
主要包括单分子荧光技术,也就是不需要扩增,每一个分子显示一种光,然后实时去监控,去读取。因此这里如何构建一个环境,让核酸分子单独发光,去识别是技术难点。
最近国内较火的瀚海基因的GenoCare也是基于单分子荧光技术的。
二、Pacbio主要应用
目前三代数据主要应用在科研市场的两个方向上,第一个是基因组的组装,另一个就是全长转录组。
全长转录组上的应用其实没啥说的,他不需要组装,只需要纠错,然后识别就好了,定量还是利用二代测序。这里就不说了,主要说下三代组装上的一些情况。
1.纠错
第一个就是由于三代数据的随机错误很多,因此对数据进行纠错是绕不过去的,介绍两款软件,一款是pacbioToCa,一款是ectool。一个是利用二代数据纠错,一个是利用contig进行纠错。
2.组装
第二个软件就是三代数据的组装,推荐celera Assembly。当然肯定还有其他的牛X的软件因此我们很难拿到。对了,多一句嘴,官网说单独用三代组装的话,深度要到40x。
3.混拼
第三个软件是混拼,也就是二代数据和三代数据一起组装。软件为,不废话,官网要求深度为20x。
4.补洞
第四个软件是我喜欢的,就是利用三代数据的长片段来填补二代数据组装完的gao和连接contig为scaffold。推荐软件PBjerry。官网要求深度为5X。
三、三代全长转录本分析工具
三代全长转录本在辅助基因注释,可变剪接分析,融合基因检测方面可以说大显身手,下面小编列了几个工具及对应的下载地址,供大家参考。大家有好的最新的工具欢迎留言补充!
1. 可变剪接鉴定(3个工具)
1)网址:https://github.com/liuxiaoxian/IsoSeq_AS_de_novo
Liu X, Mei W, Soltis P S, et al. Detecting Alternatively Spliced Transcript Isoforms from Single‐Molecule Long‐Read Sequences without a Reference Genome[J]. Molecular Ecology Resources, 2017.
2)网址:http://splicegrapher.sourceforge.net/
Rogers M F, Thomas J, Reddy A S N, et al. SpliceGrapher: detecting patterns of alternative splicing from RNA-Seq data in the context of gene models and EST data[J]. Genome biology, 2012, 13(1): R4.
3)网址:https://sourceforge.net/projects/cash-program/
Wu W, Zong J, Wei N, et al. CASH: a constructing comprehensive splice site method for detecting alternative splicing events[J]. Briefings in Bioinformatics, 2017: bbx034.
2. 多平台结合分析高基因密度基因组
网址:https://github.com/flemingtonlab/public
O’Grady T, Wang X, Höner Zu Bentrup K, Baddoo M, Concha M, Flemington EK. Global transcript structure resolution of high gene density genomes through multi-platform data integration. Nucleic Acids Res. 2016 Jul 12; PMID: 27407110.
3. 全长转录本分析流程TAPIS
网址:https://bitbucket.org/comp_bio/tapis
Abdel-Ghany S E, Hamilton M, Jacobi J L, et al. A survey of the sorghum transcriptome using single-molecule long reads[J]. Nature communications, 2016, 7.
4. 全长转录组浏览器
网址:https://github.com/goeckslab/isoseq-browser
Hu J, Uapinyoying P, Goecks J. Interactive analysis of Long-read RNA isoforms with Iso-Seq Browser[J]. bioRxiv, 2017: 102905.
5.全长转录组测序新转录结构发现注释工具
网址:https://bitbucket.org/ConesaLab/sqanti
Tardaguila M, de la Fuente L, Marti C, et al. SQANTI: extensive characterization of long read transcript sequences for quality control in full-length transcriptome identification and quantification[J]. bioRxiv, 2017: 118083.
6.全长转录组Iso-Seq和RNA-Seq集合进行无参考转录组分析
Ning G, Cheng X, Luo P, et al. Hybrid sequencing and map finding (HySeMaFi): optional strategies for extensively deciphering gene splicing and expression in organisms without reference genome[J]. Scientific Reports, 2017, 7.
另外一种技术就是单分子纳米技术,顾名思义,就是让核酸分子单独的经过纳米通道,通过每个分子不同的电信号进行识别。这个技术的代表是牛津大学的naropore技术。
纳米孔测序技术
纳米孔测序技术是最近几年兴起的新一代测序技术。目前测序长度可以达到150kb。这项技术开始于90年代,经历了三个主要的技术革新:一、单分子DNA从纳米孔通过;二、纳米孔上的酶对于测序分子在单核苷酸精度的控制;三、单核苷酸的测序精度控制。目前市场上广泛接受的纳米孔测序平台是Oxford Nanopore Technologies(ONT)公司的MinION纳米孔测仪。它的特点是单分子测序,测序读长长(超过150kb),测序速度快,测序数据实时监控,机器方便携带等。这篇综述重点总结了MinION测序仪的技术特点和应用领域。
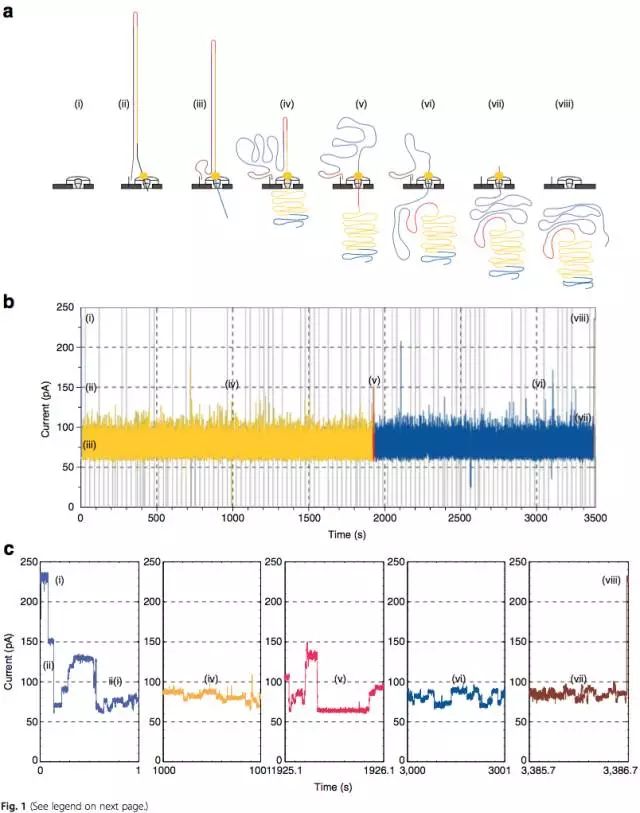
一、 MinION测序技术简介
MinION纳米孔测序仪的核心是一个有2,048个纳米孔,分成512组,由专用集成电路控制的flow cell。测序原理见图1a所示:首先,将双分子DNA连接lead adaptor(蓝色),hairpin adaptor(红色)和trailing adaptor(棕色);当测序开始,lead adaptor带领测序分子进入由酶控制的纳米孔,lead adaptor后是template read(即待测序的DNA分子)通过纳米孔,hairpin adaptor的作用是DNA双链测序的保证,然后complement read(待测序分子的互补链)通过纳米孔,最后是trailing adaptor通过。在上述测序方法中,template read和complement read依次通过纳米孔,利用pairwise alignment,它们组合成2D read;而在另外一种测序方法中,不使用hairpin adaptor,只测序template read,最终形成1D read。后一种测序方法通量更高,但是测序准确性低于2D read。每个接头序列(adaptor)通过纳米孔引起的电流变化不同(图1c),这种差别可以用来做碱基识别。
二、 MinION相对于其他NGS测序平台的优势
1、碱基修饰的检测
纳米孔测序技术可以检测四种胞嘧啶(cytosine)碱基修饰,分别为5-methycytosine,5-hydroxymethycytosine,5-formylcytosine和5-carboxylcytosine。检测准确率为92%-98%。
2、实时测序监控
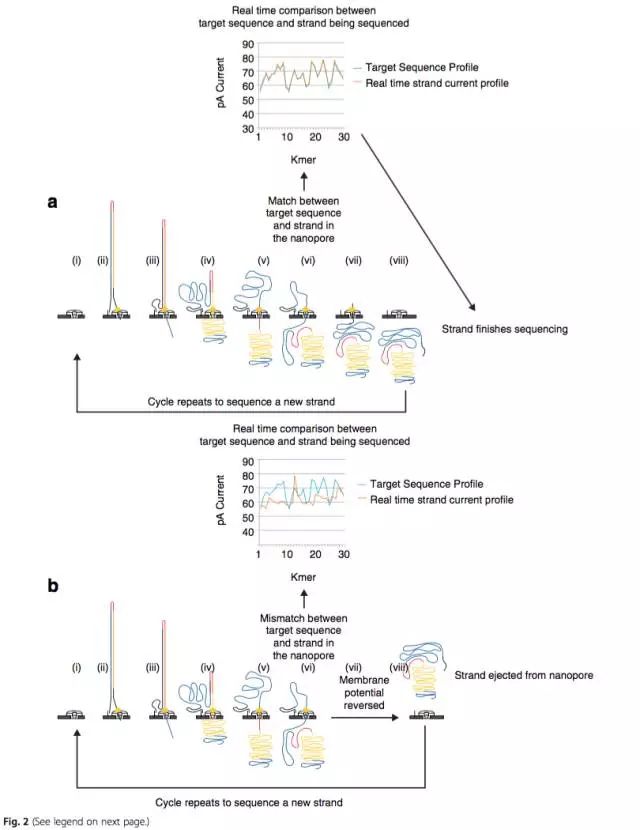
对于临床实践,实时获取和分析DNA/RNA序列是一件很重要的事情。对于传统的NGS测序,做到这一点非常不易。但对于MinION,实现起来相对容易。这不仅是因为MinION体积小,易操作等,更是因为在测序过程中单分子穿过纳米孔,其电流变化可以检测并识别,这种设计允许用户在测序过程中根据实时结果做出一些判断。
实时测序监控对于MinION针对特定目标序列测序有重要的应用(图2):当DNA片段通过纳米孔时,如果电流变化呈现与目标序列一样的趋势,则通过纳米孔。如果DNA片段与目标序列呈现不同的电流变化趋势,则不能通过纳米孔。通过这样的方式,实现目标序列的富集,从而显著减少测序时间,对于在野外和即时诊疗有重要意义。
3、测得更长的read
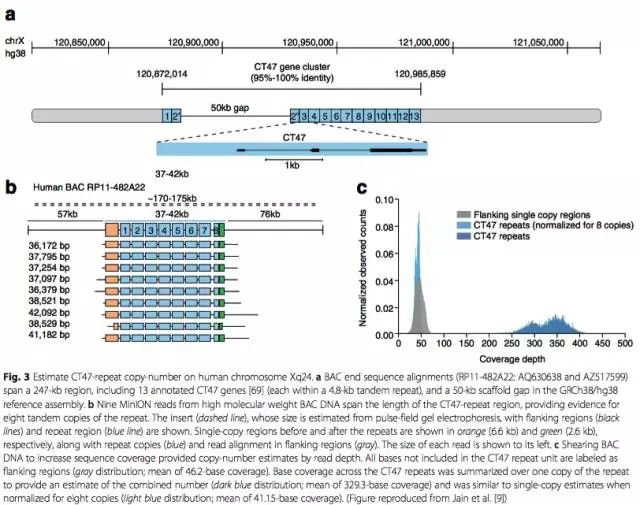
用MinION测序仪,对于1D read可以获得300kb长的read;对于2D read可以获得60kb长的read。利用MinION测序仪产生的长read,研究人员设法填充了人参考基因组Xq24号染色体一个长50kb的gap。该区域存在多个CT47基因串联拷贝,研究人员利用MinION的长read判断该区域极有可能存在8个CT47基因拷贝(图3)。
4、结构变异的检测
NGS短序列的特征使结构变异的检测往往不准确。这个问题在癌症的检测中尤其严重,这是因为癌症组织中充斥各种结构变异。研究人员发现利用MinION测得的几百个拷贝的长read得到的结构变异结果比NGS平台测得的上百万read得到的结果更可靠。
5、RNA表达分析
对于RNA表达分析,NGS平台测得的短序列带来的问题是序列需要进行拼接,才能得到转录本。这给可变剪切研究带来困扰。因为通常情况下NGS测序不能产生足够的信息将不同形式的可变剪切区分开来。而利用MinION测序仪产生的长read,可以更好地解决这个问题。研究人员利用果蝇的Dscam1基因为例,其存在18,612种可变剪切形式,利用MinION测序仪可以检测到超过7,000种可变剪切形式,而这样的结果利用NGS的短序列测序是不能够获得的。
6、生物信息学配套软件的发展
近些年来,随着生物信息分析方法的发展,MinION测序reads成功比对参考基因组的比例已经从66%提升至92%。文章下面对各种工具的适用场景进行了分别介绍。工具概述见表1。

1、碱基识别工具
Metrichor是ONT公司推出的基于隐马尔可夫模型进行碱基识别的软件。它的使用需要网络连接。MinION注册用户需要获得开发者账号才能获得软件的源代码。2016年初,两个实验室分别开发了Nanocall和DeepNano软件。这两个软件都可以在本地运行,不需要网络连接。Nanocall基于隐马尔可夫模型,可对1D read在本地进行碱基识别;DeepNano基于recurrent neural network framework,可以获得比隐马尔可夫模型更准确的碱基识别。
2、序列比对工具
传统的NGS序列比对软件不能满足MinION序列比对的需求。这是因为MinION测序数据错误率相对高且序列长,即使调整参数也不能取得好的效果。在这种情况下,适合MinION测序数据的比对软件应运而生。
MarginAlign是通过更好地估计MinION测序reads测序错误来源从而提高与参考基因组的比对效率。通过评估检测到的变异,发现其显著提高了比对的准确性。由于MarginAlign是基于LAST或BWA mem的比对结果进行优化,结果的最终准确性依赖最初的比对结果。
GraphMap是另一个用于MinION测序数据比对的软件。它利用的是一种启发式(heuristics)方法,对高错误率reads和长reads进行了优化。一项研究表明GraphMap比对的灵敏性可与BLAST媲美,且它对reads测序错误率的估计与MarginAlign相当。
3、从头组装工具
MinION测序数据不适合利用NGS数据组装的de Bruijn图法进行组装,主要存在两方面的原因。第一,de Bruijn图法等方法依赖测序reads拆分的k-mer测序准确,而高错误率的MinION测序reads不能保证这一点;第二,de Bruijn图的结构不适用长reads。
MinION测序数据的长reads更适合Sanger测序时期基于有overlap的共有(consensus)序列组装的方法。需要的是在组装前进行测序reads的纠错。第一个基于这种原理进行组装的研究组利用MinION数据组装了一个完整的E. coli K-12 MG1655基因组,序列准确率达到99.5%。他们利用的流程称为nanocorrect,首先利用graph- based,greedy partial order aligner方法进行纠错,然后利用Celera Assembler将纠错后的reads进行组装,最后利用nanopolish对组装结果进行进一步提升。
4、单核苷酸变异检测工具
Reference allele bias是一种在变异检测中倾向于少检测出变异的现象。该现象在测序reads错误率高的情况下尤为严重。
MarginAlign中的marginCaller模块是研究机构开发的适用于MinION测序数据的变异检测软件。MarginCaller利用maximum-likelihood参数估计和多条测序reads序列比对来检测单核苷酸变异。当计算机模拟出测序错误为1%时,测序深度在60X,marginCaller检测出的SNV具有97%的准确率和完整度。另外一项研究中,研究者利用GraphMap方法,检测人基因组的杂合变异,可以达到96%的准确率。利用计算机模拟的数据,GraphMap同样可以高准确率,高完整度地检测出结构变异。
Nanopolish也可以用来检测变异。它用的是event-level alignment算法。在该方法中,从参考基因组序列开始,依次评估参考基因组序列产生的电信号与测序reads的相似性进而依次修饰参考基因组序列,生成一个consensus read。直到consensus read与测序read产生的电信号足够相似,将consensus read与参考基因组序列比较,得到变异。该方法在埃博拉病毒的研究中有大约80%的准确性。
PoreSeq采用与Nanopolish类似的算法。它可以利用更低深度的测序数据获得高准确率和高完整度的SNV检测。在一项研究中,PoreSeq在16X测序深度下获得99%准确率和完整度的SNV检测,与marginAlign相比,它显著降低了测序深度。
5、共有序列的测序(consensus sequencing)方法
MinION测序数据目前只有92%的准确性。在低深度测序的情况下,不能够满足类似单体型(haplotype phasing)和人样品的SNV检测的要求。文章提到的解决问题的方法是rolling circle amplication,它的原理是将一个片段进行多次扩增,在一个DNA分子上生成多个拷贝,这样最终获得的共有序列测序结果的准确率可以达到97%。
三、MinION目前的应用领域
1、即时检测传染源
NGS测序方法可以在医院环境下进行传染源等病菌的检测,而MinION测序方法提供的是一种全新的体验。MinION在测序读长,携带的方便性,检测时长方面具有NGS不可比的优势。文献记载从样品准备到发现致病菌只需要6小时时间,而从样品放置机器到发现致病菌只需要4分钟。文章列举了截至目前用MinION测序仪涉及研究的物种及详细描述了西非爆发埃博拉病毒时,MinION测序方法在病毒检测过程中起到的重要作用。
2、非整倍体检测
MinION可以在胎儿非整倍体产前检测中发挥重要作用。利用NGS平台,通常需要1-3周时间获得结果。而利用MinION测序方法,文献报道只需要4小时。
3 、太空应用
在太空飞行中,发掘细菌和病毒是很困难的事情。大部分研究是将样品带回地球进行测序鉴定。目前,NASA准备利用MinION测序仪在国际空间站进行病菌的实时测序。
四、 展望
1 、PromethION
为了满足研究人员对高通量测序的需求,ONT公司开发了一个台式纳米孔测序仪—PromethION。PromethION有48个flow cell,可以单独运行也可以并行。每个flow cell包括3,000个通道(channel),每天产生6Tb测序数据。
2、 测序read准确性
目前MinION测序仪的测序准确率在92%左右。对于类似致病菌和可变剪切的发掘,这样的测序准确率可以满足需求。但是对于临床检测,通常read准确率需要达到99.99%。因此,文章提到ONT公司需要在测序相关的化学反应和碱基识别软件方面进行优化。
另外,文章提到MinION测序方法存在非随机的测序错误。比如MinION不能很好处理长于6个核苷酸的同聚物的测序,同时缺少碱基修饰检测的内参训练。如果这两个问题能够得到解决,共有序列(consensus)测序的准确率可以达到大于99.99%。
3 、测序read长度
目前MinION测序长度达到150kb。在未来一段时间,可以期许其测序长度可以得到更大提升。
4 、RNA直接测序
逆转录和PCR扩增会导致很多RNA自身信息的丢失,所以目前ONT公司和一些研究机构正在尝试用纳米孔技术进行RNA直接测序。之前的研究已经为此奠定了基础,比如研究表明可以对tRNA进行单通道和固态纳米孔(solid-state nanopore)检测,且纳米孔可以检测DNA和tRNA的碱基修饰。
5 、单分子蛋白测序
目前,质谱(mass spectrometry)是做蛋白组分析较好的技术,但是对于灵敏性,准确性和分辨率,目前的技术都存在局限性。2013年一项研究报道了酶介导的蛋白通过单通道纳米孔。这项研究表明蛋白的序列特征可以被检测。这些发现为蛋白质纳米孔测序奠定了很好的基础。
五、参考文献
The Oxford Nanopore MinION: delivery of nanopore sequencing to the genomics community