ElasticSearch 索引设计指南
1. 何为ES索引设计
ElasticSearch(以下简称:ES )是一个分布式、RESTful 风格的搜索和数据分析引擎。区别于传统关系型数据库(比如:MySQL、Oracle 等),ES 在定义数据模型和搜索方式上非常灵活,数据模型可以采用静态数据映射与动态数据映射,搜索方式也支持多维度类型的搜索(结构化数据、非结构化数据、地理位置、指标参数等)。如果对事务性要求不高或者事务性操作在 RDMS 端,可以考虑使用 ES 作为海量数据存储与检索分析的平台。用户在创建新索引时,可以直接写数据,所有配置走默认,收缩自如、十分灵活;也可以精细化评估,按照自己的业务需求,提前做好索引的 settings 和 mappings 的设置,未雨绸缪、尽在掌握。
针对 ES 索引设计还是有一些问题困扰着我们:
-
那么何为 ES 索引设计?
-
为什么需要提前规划,做不好索引设计又会出现什么问题?
-
如何做好 ES 索引设计,有什么需要注意的要点?
-
索引应该如何设置分片数,副本数?
-
索引大小不可预估,如何做动态拆分?
-
mapping 如何设置,有什么需要注意的?
-
以下会逐点展开,抽丝剥茧,让大家基于上述问题的解析对 ES 索引设计有一个全新的认知。
1.1 ES 索引设计
ES 索引设计主要是根据在新索引数据写入前,提前手动创建索引的配置与数据结构,以达到极致的稳定性和资源利用的最大化。一个完备的 ES 索引设计,通常会涉及以下几个点:
-
索引的存储量评估与分片数大小
-
索引的读写情况
-
索引的副本数量
-
索引的字段类型与是否可扩展
-
性能优化需要调整哪些参数
-
以上几点包含了索引层面、分片层面、字段层面的考量,后续的几个章节主要也是围绕这几点进行展开分析。
1.2 ES 索引设计可能遇到的问题
如果采用的是索引动态创建,使用的将是默认的配置。对于数据量大,业务复杂的系统,可能会出现如下问题:
分片数无法修改,数据膨胀后,导致无法使用:ES 7.x 后默认分片数为 1 ,而单个分片的存储 doc 数为 2,147,483,519 。超过则无法写入。而分片数设置后,无法修改,只能通过 reindex 进行调整,但是会有很大的性能隐患和时间成本。
影响写入性能:对于日志类的写多读少的业务类型,没必要按照默认的每秒进行 refresh 刷新,可以根据业务情况,调整为 60s 甚至 120s ,这样可以大大提升写入性能。
影响恢复性能:当集群有节点 left 集群的时候,集群需要对 unassigned shards 进行恢复,如果是默认的配置,则会在1min 后进行恢复(将宕机节点的 shards 在集群的副本进行恢复),这样会大大提升集群节点之间的 IO 操作,当本节点加入进来后,还会继续进行大量的节点间 shards 同步,会大大影响恢复进度,继而影响集群性能。如果是调高"index.unassigned.node_left.delayed_timeout"这个参数,集群则会在一段时间内不做分配,在宕机节点重启后,由宕机节点本机磁盘数据进行恢复,在大型集群调优中,能提到数倍的恢复差异。
数据结构无法更改: ES 的字段类型一旦创建无法更改,当动态映射的类型不满足业务需求时,则会出现隐患。
举例,下图是动态创建写入数据:

以上数据对应的动态映射的 settings 如下:
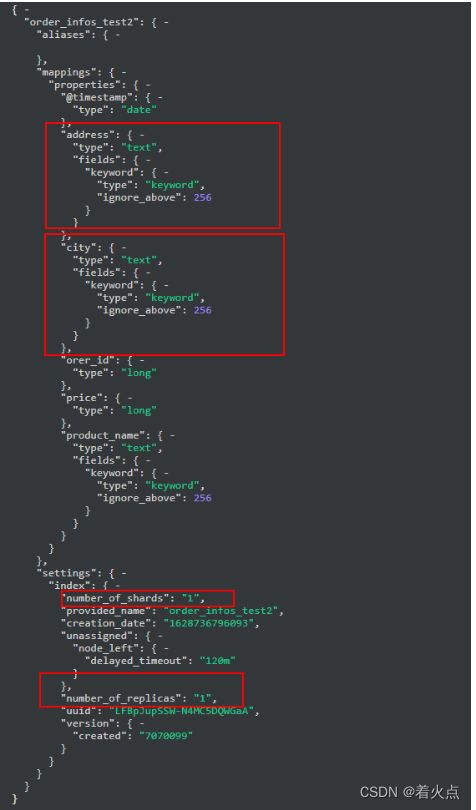
可以看到如果直接动态映射,很多索引级别和 mapping 级别的设置都不可控。
而静态映射,在设置的时候就能把握很多属性细节:

2. 索引Settings设计
索引的 Settings 部分主要针对的是索引和分片层面的设置,重点讨论的是索引的分片大小与分片数的评估(涉及到存储评估设置)、索引恢复设置与性能优化设置。相信了解了这些可以对索引的 Settings 设置更加游刃有余。
要点:索引大小预估、分片大小设计、shards_per_nodes、refresh、flush设置、node_left(delayed_timeout)、replicas
2.1 存储评估设置
在创建索引前,应该做一个短暂的评估,重点在于索引的业务类型、存储周期、分片配置这几块。
2.1.1 业务类型
-
写多读少
一般日志类的数据是写多读少,压力主要在写入端,且数据量很大。索引通常以日期为单位(常见的有按天、也有按周的),比如log_appcode-yyyy.mm.dd或者log_appcode-yyyy.ww。
对于写入量特别大的索引,建议使用 rollover 进行索引滚动创建管理。这样能保证单个索引存储量可控,单个分片存储也可控。动态索引的使用效果如下:
log_appcode-2021-10-01-000001
log_appcode-2021-10-01-000002
log_appcode-2021-10-01-000003-
写少读多
除日志类外,很多业务类的数据是写少读多,也即数据产生并不是周期性的,可以根据业务和压测进行数据量来进行评估。
对于查询量大的索引,应保证查询性能优先,可以设置尽可能多的分片数,以保证请求平摊提升性能。
2.1.1.1 rollover 操作实践
a. 创建需要 rollover 的索引,并设置对应的别名 alias
PUT log_xxx-20211020-000001
{
"aliases": {
"log_xxx-alias": {
"is_write_index": true
}
}
}b. 向别名批量插入若干数据
PUT log_xxx-alias/_bulk
{"index":{"_id":1}}
{"name":"zhangsan"}
{"index":{"_id":2}}
{"name":"lisi"}
{"index":{"_id":3}}
{"name":"wangwu"}
{"index":{"_id":4}}
{"name":"zhaoliu"}
{"index":{"_id":5}}
{"name":"qinqi"}c. 调用 rollover api ,触发调整逻辑,设置三个维度,其中 max_docs 生效
POST log_xxx-alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 5,
"max_size": "5gb"
}
}运行结果:

d.继续插数据,可以看出数据已经写到新的 index 中
PUT log_xxx-alias/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}运行结果:

以上 rollover 的流程可以用如下图展示:

2.1.2 存储周期
存储周期决定了索引的存储量上限,用户可以在创建前评估存储周期,可参考业务类型中的来一并评估。
2.1.3 分片配置
分片:分片( shard )是 ES 中存储数据的文件块,也是 ES 数据存储的最小单位。通常一个索引会分为多个分片存储,不同分片存储的数据不同。分片可以被放置在任何节点上。
分片主要有以下两种作用:
-
提升索引水平扩展的能力(扩缩容量)
-
提高索引的读写性能,可以充分利用分布式特性,提高吞吐量
分片也有局限:一旦创建了分片数,无法更改。因为数据写入时,每个 doc 都会进行路由,将 routing 的 hash 值与分片数取模来确定 doc 对应的分片。如果更改分片数,则无法确定 doc 对应的分片。算法很简单,如下:
shard = hash(routing)%number_of_primary_shards
分片数设置主要调整如下参数:
-
index.number_of_shards :索引的分片数
Elastic 官方推荐的单分片大小存储控制在 20GB~40GB 之间,不要超过 50GB 。如果单分片存储量超出范围过大,会出现如下问题:
-
有超出单分片文档数限制的风险:分片内部对应的是Lucene的索引文件,一个Lucene索引文件包含多个Segment(段),后者是Lucene索引中最小的独立存储单元。因为Segment内部的doc id使用Java的整型,所以doc 数的限制也为=》 Integer.MAX_VALUE : 2,147,483,519 条。超出此条数,则索引无法写入,会导致数据丢失
-
恢复速度慢: 单分片越大,在节点重启、分片恢复的时候时间就会越长,IO 压力也会越大。同时会影响查询性能
-
增加迁移成本:分片是 ES 对数据的隔离,单分片过大还会增加迁移索引数据迁移时间成本
基于上述,分片数的设置是索引设计的重中之重。根据实战经验与官方论坛,总结出几点设计思路:
-
评估存储周期
-
评估每天的存储量。继而根据单天的存储量 * 存储周期 = 总存储量
-
初算分片数:根据总存储量 / 分片存储量(日志数据建议50GB、业务数据建议30GB)
-
微调分片数:如果算得的分片数 << 节点数,可以考虑适当增加分片数量,以提升并发性能。理想情况下:在规模中小型的集群中,分片数 == 节点数能发挥出集群最大的性能。
2.1.4 副本设置
副本( replicas )主要用来提供集群的高可用。
副本的缺点:影响集群写入性能(写入的时候会主副分片都写入数据)与提升一倍的存储成本
副本的优点:提升查询性能(查询的时候可以主、副分片并行执行)
一般评估副本的数量,需要评估业务的场景和集群节点规模。建议:普通业务1个副本即可,安全等级高、重要性大的,可适当增加副本数。
副本数设置主要调整如下参数:
-
index.number_of_replicas :索引的副本数
例如,ES 7.x 中的.security 索引是用来保存认证账号信息的,极为重要,集群内部设置的副本就非常多。公司内部的一个日志大集群,管理公司所有实时日志,其中 .security 保存全员账号信息。设置的副本就为 9 。
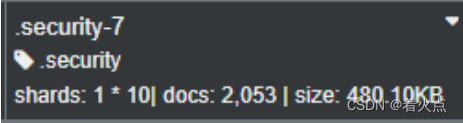
但是如果要保证高可用,一定要保证最少为 1
副本设置为 0 ,可能会出现以下问题:
-
高可用性无法保证:一旦有节点宕机,集群状态直接从Green=》 Red,宕机节点无法使用,影响非常大;
-
可能造成数据倾斜:0 副本可能造成数据写入指定的机器,从而整体数据倾斜。机器资源利用差异加大;
-
副本数的设计结合数据的安全需要。对于数据安全性要求非常高的业务场景,建议做好:增加备份(结合 ES 官方备份方案)。
分片和副本设置参考如下:
PUT /index/_settings
{
"settings": {
"index.number_of_shards": "10",
"index.number_of_replicas": "1"
}
}2.2 索引恢复设置
索引恢复是一个复杂的过程,通常如果有节点left 集群后,会在一分钟后,集群开始进行恢复。
恢复期间主要会根据分片元数据信息,其余节点对应的宕机节点的分片,置这些分片为主分片,同时进行副本分片数据传输和同步,整体过程会消耗大量的 IO 资源,影响集群稳定性。且当宕机节点重启后,集群还会进行 rebalance shard ,进行进一步的平衡分配分片。整体而言时间很长,苦不堪言。
index.unassigned.node_left.delayed_timeout : 节点脱离集群后多久分配unassigned shards(默认1min)
可以调整上述参数来保证节点恢复期间,不要进行 unassigned 的分配。可以根据索引的存储量、分片数为不同的索引进行设置,如下的设置就能保证节点 left 集群 5 分钟内不进行分配:
PUT /index/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}2.3 性能优化设置
索引 Settings 中有很多参数可以直接影响到集群的读写性能,调整到位则事半功倍,一招调错也可能影响全局。
一般来说,集群默认的配置对性能影响不大,但是遇到数据海量的集群可能会出现一些问题,需要调整相关的参数来提高集群的稳定性和读写性能。
文中选取实践中使用最频繁的,效果最佳的两个参数:
-
index.routing.allocation.total_shards_per_node :将分配给单个节点的最大分片数(副本和主分片)。默认为无界。
-
index.refresh_interval :执行刷新操作的频率,这使得最近对索引的更改对搜索可见。默认为 1s 。
total_shards_per_node 参数主要影响的是集群写入的情况,当一个索引在同一个节点上有多个分片时,海量写入时会极大地飙高此节点的 CPU 占用和 Load 使用量。可以根据节点数、分片数调整此参数。例如:
比如数据节点有 10 个,索引分片数有 8 个,副本数 1 个。则设置为 2 则可。
比如数据节点有 20 个,索引分片数有 5 个,副本数 1 个。则设置为 1 则可。
refresh_interval 参数也是影响写入的性能,默认的 1s 属于近实时的检索,对于实时性要求高的可以适用。但是对于写多读少的日志类数据则不适合,集群要在每秒钟都要生成一个 Segment ,非常耗费资源,影响写入性能。推荐根据业务使用频次来设置此参数:
如果可以接受一定时间的查询延迟,则可以适当调大 refresh_interval 。
我们这边nginx的日志量很大,就单独做了设置,total_shards_per_node 设置为1、refresh_interval 设置为120s 。参考如下:
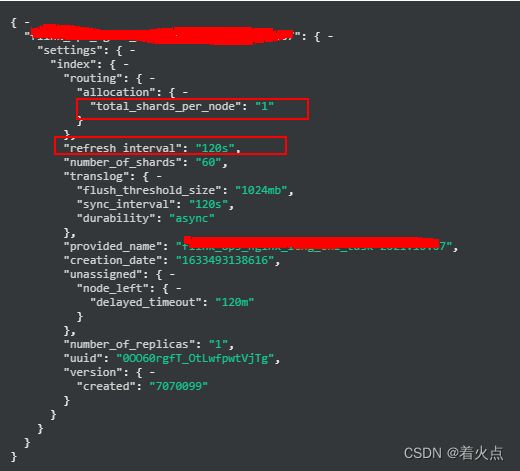
3. 索引Mapping设计
Mapping 是定义文档以及其包含的字段如何存储和索引的。Mapping 可以用来做如下定义:
-
哪些字段可以设置为全文检索字段
-
每个字段的数据类型
-
Date 类型的格式
-
自定义规则来控制Dynamic Mapping的映射
-
设置单个字段是否额外存储与存储类型
3.1 索引Mapping存储概要
索引映射(Mapping) 分为动态映射和静态映射。其中动态映射指数据写入 ES 索引时进行动态映射匹配。
如果不确定写入的数据字段或者类型,可以使用动态映射,等业务稳定后,视情况调整索引的 mapping 即可。
动态映射适合新字段和不确定类型的字段映射,官网推荐了两种方式来扩展和完善动态映射规则:
-
Dynamic field Mapping
动态字段映射保证了基本的字段匹配规则,只要是 "dynamic" : "true"(默认),就会开启字段映射,匹配规则如下:

-
Dynamic templates
动态模板可以为字段动态添加各种映射规则,比如可以匹配到包含特定字符的字段进行数据类型映射。
也可以直接根据 match_mapping_type 匹配到的数据字段进行映射。适合于特定类型的映射,可以作为静态 mapping 的有效补充。
3.2 索引Mapping设计流程
设置字段设计的时候,可以参考几点来进行:
-
评估业务数据字段个数(常态化的)
-
根据不同的字段评估类型,并判断是否需要检索
-
评估字段是否需要排序、聚合分析。如果是text类型字段,需要聚合分析的,需要开启 fielddata
-
字段是否需要额外存储( store )
根据以上几点基本可以最准确的定义字段的映射关系与存储结构,达到资源的利用最大化。
3.3 Mappings设计关键性参数
Mapping 设置中,除了数据类型,还有一些参数属性可以设置,挑选出核心影响的几个,整理如下:

3.4 Mapping的注意事项
-
ES不支持删除已有字段
-
ES不支持修改字段类型
如果做动态映射,可能会出现使用过程中字段类型冲突的情况,此时只能 reindex 进行重新重置索引,并进行数据同步。如果数据量特别大的情况, reindex 期间会极大地影响集群性能。一定要慎重。
4. 复杂类型的设计
4.1 宽表模式
不同于 MySQL 类的传统关系型数据库,ES 对于多表关联查询不占优势。但是由于其灵活扩展的字段设计,可以采用宽表模式来有效的解决。
比如:一个用户发表多篇旅行游记,存储游记列表,设计对比如下:
按照 MySQL 建表思维:需要创建两个表(用户表、博客内容表),通过 userid 进行关联;
按照 ES 索引思维:可以创建游记索引,在每个游记内容中携带用户信息即可。内容有所增加,但是一次检索就可。
宽表模式:顾名思义,就是字段很多的数据表,通常是指业务相关的各指标、维度、属性关联在一起的一张数据表。宽表包含维度层次比较多,也容易造成冗余,但是有利于进行海量数据提取与分析,广泛应用于 olap 领域。
举例:ES 中游记索引设计如下:

4.2 Nested类型
nested 类型属于 ES 的对象类型,允许存储复杂嵌套的对象模型。nested 的出现提供了对象类型数组中的独立查询,保证了读取精度。nested 可以保证数组中每个对象的独立性。
nested 缺陷也比较明显,因为更新子文档需要更新整个对象,所以更新效率低。
4.3 父子文档类型
在 ES 6.x 版本后父子文档使用 join 来替代。父子文档解决了 nested 的子文档不能独立更新的问题,保证了父与子更新的独立性。比较适合 1 个父对多个子,且子文档更新频繁的场景。
父子文档更新便捷,但是由于内部维护了父子的复杂关联关系,需要占据更多内存,查询性能较之 nested 也较低。
Nested 和父子文档都属于文档嵌套的模型,但是使用方式和使用场景各有不同,详细对比如下:

5. 索引设计实战
本章节笔者通过生产的实时日志集群(简称:日志集群)的真实案例来剖析在生产中是如何使用上述的设计架构要点进行实战的。重点围绕索引的生命周期管理、分片的维护与评估、templates的灵活设计运用,以及实际的一个设计后的生产情况。力求给读者一个更直观的综合感受。
5.1 索引生命周期管理
索引生命周期管理通常指 ES 的各索引的存储周期管理维护,是维护 ES 集群稳定,存储成本,分片管理的重要方案。
日志集群采用了自研的方案,构成了“申请 + 维护 + 清理” 三位一体的生命周期管理方案。下面详细介绍一下:
-
申请:日志集群以周为存储粒度,每个索引都是类似 log_appcode-yyyy.ww 这种模式,存储周期默认也是7天。如果需要保留更多的周期,则需要用户进行申请延长存储配额。我们这边自研了数据平台自助工单申请平台,其中就有 ES 存储周期的申请功能。见下图:

审批过后,该 appcode 对应的索引生命周期自动变成新的周期。
-
维护:日志集群将不同的 appcode 的索引生命周期数值存储到了 postgresql 中,从日志申请流程通过,即会写入新 appcode 与默认的存储时长。当每次有存储周期修改审批后,自助工单平台会操作修改 postgresql 进行时长的调整。
-
清理:根据 postgresql 的 appcode 存储数据,编写好清理脚本,并用 airflow 进行任务定时调度(每周一次),可以起到每周的索引清理工作。
注意:由于每周需要删除的索引众多(大约900~1000),不能一次删除,需要一个一个删除,并且中间进行 3-5s 的休眠。清理过程中,可以观察集群的 pending_tasks 是否飙高,集群 load 是否变高,来保障稳定性。可以选择集群使用率低的时间段来进行索引的清理操作。
5.2 索引settings设计
日志集群中索引 settings 设计主要需要考虑的点有:分片的周期评估与调整、性能优化的整体调整(主要包括total_shards_per_node 、refresh)、索引的提前创建。
5.2.1 分片周期调整
每周会有 airflow 定时任务进行索引分片评估计算。具体的逻辑如下:
a. 拿到本周的各 appcode 对应索引的主分片存储量,按照分片 SIZE (40G)来计算出分片数,可以参考如下 api 来执行
_cat/indices?format=json&pretty&bytes=b&h=index,pri,docs.count,pri.store.size
b. 获取到数据节点实例数,在 a 步骤得到的分片数和实例数取小值。如下:
计算方式:shard_count = MIN(shard_count, node_count)
api:_cat/nodes?format=json&h=name,ip,node.role
c. 计算 buffer ,buffer + shard_count 为最终的分片数。通常比例系数为30%,buffer为比例系数 * shard_count
日志类型数据分片大小建议在 30~50G 之间为佳。
具体 templates 的维护与设计管理,请见下章节。
5.2.2 total_shards_per_node 周期调整
total_shards_per_node 的周期调整可以和分片调整放到一起。以减少维护成本。
total_shards_per_node 默认为无限量。
调整原则为:保证单个索引在单个节点上保留最少的分片数,以避免数据分片倾斜的情况。
total_shards_per_node 的调整逻辑如下:
a. 首先设置 total_shards_per_node 几个范围,日志集群这边根据数据、节点情况设置了三个范围
total_shards_per_node: 1 => shard_count < node_count
total_shards_per_node: 2 => node_count < shard_count < node_count * 1.3(比例系数)
total_shards_per_node: 3 => node_count * 1.3 < shard_countb. 根据上述的范围来计算不同索引的 total_shards_per_node 。
5.2.3 refresh 周期调整
refresh 的调整相对比较简单:默认所有的索引 refresh_interval 设置为 60s
对于非高优先级的 appcode,total_shards_per_node >1 的,设置 refresh_interval 为 120s 。
5.2.4 索引周期创建
确立好上述索引的配置信息后,可以提前创建下一周期的索引。
索引创建时机很重要,日志集群按周来索引数据,需要周一之前创建好下一周期的索引。
创建索引主要注意的点:
a. 为节省资源,需要在创建前判断索引在当前周是否有索引数据,如果没有,则不创建下一周期(如果已经下线,则就不会创建新的索引)
b. 创建索引需要串行执行,且每个索引创建后,需要休眠 3-5s
c. 索引周期创建同样需要 airflow 定时任务。根据每周的索引数和执行时长,评估创建的时间范围,来进行定时任务的调整。
5.3 templates 设计管理
templates 是索引模板,可以定义好一类 index-pattern的settings 、mappings。而日志类索引正式由于得天独厚的分类优势可以划分为各个不同的 index-pattern ,进而创建 templates 。
日志集群的 templates 架构主要分为两块:default templates、index-pattern templates。
前者是提取日志数据的公共内容写入到统一的 templates ,供所有日志索引数据
5.3.1 default templates
default templates 是默认的模板,用来作为根模板使用,适用于放一些通用的配置,以达到方便配置管理的作用。
日志集群的 default templates 主要做了以下几点:
a. 提供默认的分片、refresh
注:使用 default templates 的分片数和 refresh 刷新频率主要是为了新增的日志提供默认的配置。日志集群做过统计基本上 95% 以上的索引周存储量都在 1TB 以内,所以默认创建 20 分片的索引能满足绝大多数需求。
number_of_shards: 20
refresh_interval: 60sb. 日志统一字段配置
根据各个业务线写入的数据字段类型,和 kafka 存储的日志源数据信息,提取了一些共用字段,举例如下:
@timestamp: date
send_time : long (时间戳)
app_code : keyword
source_ip : keyword
content : text
log_name : keyword更进一步,我们可以根据字段类型进行自身的数据内容,使用情况来进行字段属性方面的调整,比如:
app_code : 字段存储的是每个 appcode ,在单个 appcode 下没有检索意义。故而设置 index: false
content : 字段存储的是日志的主要内容,内容通常比较冗长。设置 norams: false, 不对 content 计算得分
根据上述,还对 source_ip、send_time 等字段都做了 index:false 的设置
一个较为完整的 default template 如下:
{
"order": 1,
"index_patterns": [
"log_*"
],
"settings": {
"index": {
"routing": {
"allocation": {
"total_shards_per_node": "1"
}
},
"refresh_interval": "60s",
"number_of_shards": "20",
"translog": {
"durability": "async"
},
"number_of_replicas": "1"
}
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"send_time": {
"index": false,
"type": "long"
},
"source_host": {
"ignore_above": 256,
"type": "keyword"
},
"log_name": {
"ignore_above": 256,
"type": "keyword"
},
"content": {
"norms": false,
"type": "text"
},
"app_code": {
"ignore_above": 256,
"index": false,
"type": "keyword"
},
"source_ip": {
"ignore_above": 256,
"index": false,
"type": "keyword"
}
}
},
"aliases": {}
}5.3.2 建立各自的 template
一般有如下情况下需要用到独立的 template :
a. 有独立于 default templates 的字段需要提前设置,比如增加字段
b. 针对 default templates 的现有字段有属性调整设置,比如调整 date 类型的 format
c. 创建独立的 shard_count、total_shards_per_node ,如上文 5.2 所示
比如其中一个日志索引存储的是 city 相关的日志数据,所以会增加 cityName 字段;@timestamp(date类型) 写入的格式为 yyyy-MM-dd HH:mm:ss.SSS ,则修改了 date 的 format ;而分片相关的设置会在定时任务中进行自动更新。一个独立的 template 参考如下:
{
"order": 99,
"index_patterns": [
"log_order_info-*"
],
"settings": {
"index": {
"number_of_shards": "256",
"routing": {
"allocation": {
"total_shards_per_node": "2"
}
},
"refresh_interval": "120s"
}
},
"mappings": {
"properties": {
"cityName": {
"type": "keyword"
},
"@timestamp": {
"format": "strict_date_optional_time||epoch_millis||yyyy-MM-dd HH:mm:ss.SSS",
"type": "date"
}
}
},
"aliases": {}
}templates 的重要字段说明:
-
order:创建索引template的执行的顺序,如果一个索引有多个 templates 匹配,则会根据 order 的顺序,升序执行。order 值越高的越后面执行,多个 templates 进行合集。相同配置以 order 高值为准,如果字段类型彼此冲突,会报错。
-
index_patterns:是 templates 匹配的 index 模板,一般会带上*,可以匹配多个相同类型的索引。
5.4 实战总结
总结上述的实战,主要涉及到了三块:索引生命周期管理、索引 settings 设计管理、索引的 templates 管理,这几块既有配置类的设计管理,也有性能方面的考虑,还加入了生产中使用的 templates 进行设计管理,提升可维护性。并统一通过 airflow 定时任务进行自动化维护,保证了索引周期性设计的稳定性。具体流程参考下图:

6. 最佳实战建议
Settings层面
-
分片大小:单分片控制在 20~40G 内。单分片支持的 doc 数量在2,147,483,519。
-
分片数量:建议趋近于节点数,提升并发性能
-
副本数量:reindex 数据建议为 0 个;生产使用建议至少 1 个
-
total_shards_per_node:如果分片数小于等于节点数,建议1个。否则按比例增加即可。
-
refresh_interval: 时效性要求高建议用默认 1s ,否则建议设置在 30~60s 左右。
Mappings层面
-
templates 使用:对于同一类型索引进行提炼,提前做 templates ,方便后期灵活调整。
-
keyword、text:精准查询与聚合计算使用 keyword 、分词检索使用text;
-
动态templates:对于不确定的字段需要设置类型映射,可以考虑使用。
-
字段数量:单索引推荐字段数 1000 以内
-
对象嵌套:默认限制嵌套 20 层,建议不要超过 3 层
-
属性设置:根据业务情况,针对不同字段类型进行属性设置。比如对于不查询检索的字段,设置 index:false ,具体参见 3.3 章节。
7. 总结
文末,总结一下 ES 索引设计的核心考量因素:
-
业务模型已知的情况下,尽可能使用静态设计。对于不确定的字段,可以结合动态 mapping 进行控制
-
索引分片和副本一定要提前设计好,如果索引存储周期不定,数据量很大的情况,可以结合 rollover 控制单分片大小
-
Mapping 创建好后,无法更改,所以对于不确定的参数建议进行完备的测试,方可放入生产环节
-
根据业务提前设计要比后续遇到问题填坑省很多事情
相信读者认真看完此篇文章,结合业务场景,仔细思考,定能设计出性能更好、稳定性更强的索引。