看完这篇文章,入门hadoop--这么细,你不看看?
1.什么是hadoop
1.1 hadoop的简介

Hadoop是一个由Apache基金会所开发的分布式系统基础架构,一个能够对大量数据进行分布式处理的软件框架; Hadoop以一种可靠、高效、可伸缩的方式进行数据处理;用户可以在不了解分布式底层细节的情况下,开发分布式程序。
关键词解析:
Apache基金会:Apache软件基金会(也就是Apache Software Foundation,简称为ASF),是专门为支持开源软件项目而办的一个非盈利性组织。在它所支持的Apache项目与子项目中,所发行的软件产品都遵循Apache许可证(Apache
License)。
分布式系统:分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
1.2 hadoop的发展历程
Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
狭义上来说,hadoop就是单独指代hadoop这个软件,
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
Hadoop生态的图例:

对于Hadoop的发展起到至关重要的一个人我们不得不提,这个人就是Hadoop之父:

1.3 hadoop的版本介绍
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,ClouderaManager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
(5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
(4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
(6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
2.为什么要使用hadoop
2.1 hadoop的设计目的
用户通过开发分布式程序,充分利用低廉价的硬件资源完成海量数据的存储和运算,不仅仅能够完成数据的存储和运算,还要能保证数据的安全性和可靠性
2.2 hadoop的优势
1.高可靠性。因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
2.高扩展性。当存储hdp集群的存储能力和运算资源不足时,可以横向的扩展机器节点来达到扩容和增强运算能力
3.高效性。因为它以并行的方式工作,通过并行处理加快处理速度
4.高容错性。Hadoop能够自动保存数据的多个副本,当有存储数据的节点宕机以后, 会自动的复制副本维持集群中副本的个数 ,并且能够自动将失败的任务重新分配。
5.低成本。hadoop可以运行在廉价的机器上并行工作,达到高效,安全,效率于一身目的。
3.hadoop的核心知识点
1.HDFS (Hadoop Distributed File System) 分布式文件系统:负责海量数据的存储和管理
2.MapReduce分布式运算系统:负责海量数据的运算
3.YARN分布式资源调度和任务监控平台

3.x没有太大的改变
4.什么是hdfs
4.1 hdfs的概念:
HDFS分布式文件系统,全称为:Hadoop Distributed File System,首先这是一个文件系统,主要用于对文件的存储,通过和linux相似的目录树系统定位文件和目录的位置,其次,他是分布式的,解决海量数据的存储问题,HDFS系统统一管理,提供统一的操作目录,操作命令和API
4.2 为什么要用hdfs:
因为随着数据量越来越大,一台机器已经不能满足当前数据的存储,如果使用多台计算机进行存储,虽然解决了数据的存储问题,但是后期的管理和维护成本比较高,因为我们不能精准的知道哪台机器上存储了什么样的数据,所以我们迫切的需要一个能够帮助我们管理多台机器上的文件的一套管理系统,这就是分布式文件系统的作用,而hdfs就是这样的一套管理系统,而且他也只是其中的一种.
5.hdfs的优缺点
5.1 优点:
高容错性:HDFS将文件进行切块,然后存储在集群的不同机器中,默认每个物理切块存储3个副本,如果有一台机器出现宕机或者磁盘损坏导致存储的物理块丢失时,HDFS可以对其进行自动修复
高扩展性:当HDFS系统的存储空间不够时,我们只需要添加一台新的机器到当前集群中即可完成扩容,这就是我们所说的横向扩容,而集群的存储能力,是按照整个集群中的所有的机器的存储能力来计算的,这也就是我们所说的高扩容性
海量数据的存储能力:可以存储单个大文件,也可以存储海量的普通文件
5.2 缺点:
5.2.1 不适合低延时数据访问;
-
比如毫秒级的来存储数据,这是不行的,它做不到。
-
它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况 下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。
5.1.2 无法高效的对大量小文件进行存储
-
存储大量小文件的话,它会占用NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
-
小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
5.1.3 不支持并发写入、文件随机修改
-
一个文件只能有一个写,不允许多个线程同时写。
-
仅支持数据 append(追加),不支持文件的随机修改。
6.hdfs的角色分析
HDFS默认采用的是主从架构,架构中有三个角色:一个叫NameNode,一个叫DataNode,还有一个叫secondaryNameNode
主从架构示例图:

所以我们在搭建hdfs架构时,需要一台NameNode,三台DataNode,一台SecondaryNameNode.
NameNode:主要负责存储文件的元数据,比如集群id,文件存储所在的目录名称,文件的副本数,以及每个文件被切割成块以后的块列表和块列表所在的DataNode
DataNode:主要负责存储数据,包含一整个文件或者某个文件切成的块数据,以及块数据的一些校验信息等
SecondaryNameNode:主要负责和NameNode的checkpoint机制(类似于备份机制)等
注意事项:
- 1. 大文件进行切片存储时,hadoop1.x版本默认切片大小是64MB,Hadoop2.x以后默认大小是128MB,也就是说当我们的一个文件进行存储时,如果小于128MB,会整个文件进行存储,如果大于128M,会将该文件切成块进行存储,如果想要修改切块大小,可以在安装hdfs时进行配置
- 2.每个文件默认副本是3个,切成的块文件也是如此
问题:为什么块大小为128M???
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认为128M的原因,基于最佳传输损耗理论!不论对磁盘的文件进行读还是写,都需要先进行寻址!最佳传输损耗理论:在一次传输中,寻址时间占用总传输时间的1%时,本次传输的损耗最小,为最佳性价比传输!目前硬件的发展条件,普通磁盘写的速率大概为100M/S, 寻址时间一般为10ms!
10ms / 1% = 1s
1s * 100M/S=100M
因为我们的计算机的底层进制是2进制,所以设置100M对于计算机来说并不是最友好的,应该将其设置为2的次方值,对于100M来说,最近的就是128M,所以我们将其设置为128M
如果公司中磁盘传输效率显示为300M/s,那么我们在设置时,最好设置为256M,目前SATA硬盘一般传输效率为500M/S,所以具体设置多少,还需要根据公司中使用的磁盘来设定
问题:能不能将块设置的小一些?
理论上是可以的,但是如果设置的块大小过小,会占用大量的namenode的元数据空间,而且在读写操作时,加大了寻址时间,所以不建议设置的过小
问题:不能过小,那能不能过大?
不建议,因为设置的过大,传输时间会远远大于寻址时间,增加了网络资源的消耗,而且如果在读写的过程中出现故障,恢复起来也很麻烦,所以不建议
7.hdfs的搭建和配置
- 1.找出之前搭建好的集群机器中的某一台,比如doit01,
- 2.上传文件到/opt/apps 目录下,如果没有该目录,可以先执行
cd /opt #切换到对应目录
mkdir apps #在opt目录下创建一个apps目录
然后再apps目录内部执行rz命令开始上传

如果输入rz命令不好用,证明没有下载过rz命令,可以输入
yum -y install lrzsz
#rz命令是主机上传到虚拟机文件的命令
#sz是主机从虚拟机下载文件到本地的命令
- 3.对hadoop-3.1.1.tar.gz进行解压操作
tar -zxvf hadoop-3.1.1.tar.gz
- 4.查看解压后的目录
cd hadoop-3.1.1
ll

- 5.开始对hdfs进行配置,进入到etc目录下
cd etc #这里要注意 不要写成 cd /etc 这样是进入到根目录下的etc
# 接着往里面进
cd hadoop
- 6.先配置hadoop的java依赖
vi hadoop-env.sh
#在hadoop-env.sh最后一行添加以下环境信息
export JAVA_HOME=/opt/apps/jdk1.8.0_191\
如果没有安装jdk的话,需要先去安装jdk
- 7.除了配置hadoop的默认java依赖以外,我们还需要一些扩展配置
hadoop是有一些默认的配置文件的,这些默认的配置文件在jar包中,如果如果相对hadoop的默认配置信息进行修改或者增加的话,可以在xx-site.xml文件中进行配置,这算是我们的一些扩展配置.
在当前目录中
vi hdfs-site.xml
将下面配置信息copy到文件中的<configuration>configuration>标签中
<property>
<name>dfs.namenode.rpc-addressname>
<value>doit01:8020value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/opt/hdpdata/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/opt/hdpdata/datavalue>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>doit02:50090value>
property>
这个时候hdfs的默认配置就基本配置完毕,但是我们只配置了一台机器,还有两台机器没有配置,但是重复上述过程太麻烦,所以我们可以使用一个远程复制的命令将hadoop的解压包复制给另外两台机器
#先切换到apps目录下
cd /opt/apps
#然后执行
scp -r hadoop-3.1.1 $doit02:$PWD
scp -r hadoop-3.1.1 $doit03:$PWD
以后我们还可能会经常给另外的机器复制文件,所以我们可以写一个脚本对该命令进行封装,然后需要分发什么直接运行该脚本即可
#在apps目录下创建一个专门存放各种脚本的目录
mkdir scriptDir
#然后创建一个脚本文件
touch cluster_script.sh
#然后编辑该脚本
vi cluster_script.sh
#脚本内容:
#!/bin/bash
for hostname in doit02 doit03
do
scp -r $1 $hostname:$PWD
done
- 7.配置完毕以后,初始化NameNode
#进入到hadoop的bin目录里面
cd /opt/apps/hadoop-3.1.1/bin
#然后执行命令
./hadoop namenode -format
- 8.查看是否初始化成功,直接到/opt目录下查看是否有hdpdata目录被创建出来

- 9.接下来我们可以依次启动hdfs的角色,先启动namenode
进入到sbin目录下
cd /opt/apps/hadoop-3.1.1/sbin
#启动namenode
./hadoop-daemon.sh start namenode
#然后再启动datanode
./hadoop-daemon.sh start datanode
#在进入不同的机器里面执行启动datanode的命令
- 10.查看每台机器上是否已经有了对应的服务进程,可以通过一个命令jps,专门查看java服务进程,查看显示有namenode或者datanode证明已经启动成功,这个时候,集群就已经搭建完毕了

- 11.hadoop还给我们提供了一个web端的监控页面,用于专门查看hdfs文件系统,路径为:
http://ipaddress:9870/ 比如:http://doit01:9870/
ipaddress 是你的namenode的主机名,需要配置主机名的映射

我们还能监控到datanode的启动情况,也就是查看有多少个datanode节点在运行

如果进不去这个页面,有两种原因导致:
1.没有配置主机名映射,需要在windows主机内部配置域名映射
配置主机名映射 要找到windows主机里面的hosts文件

有些电脑默认是不能修改host文件的,所以我们可以将host文件复制到桌面修改完毕之后再粘贴回来,添加内容如下,直接添加到文件末尾即可:
192.168.79.101 doit01
192.168.79.102 doit02
192.168.79.103 doit03
2.没有关闭虚拟机的防火墙,或者namenode没有开启,没有开启namenode的情况下,将namenode进行开启即可,没有关闭防火墙的情况下,我们需要手动关闭防火墙,并且禁用掉防火墙的自动开启功能
systemctl status firewalld #先查看防火墙状态
systemctl stop firewalld #关闭防火墙
systemctl start firewalld #开启防火墙
systemctl restart firewalld #重启防火墙
systemctl disable firewalld #关闭防火墙自启动
systemctl enable firewalld #开启防火墙自启动
想要彻底禁用防火墙,需要先执行关闭,再执行禁用
systemctl stop firewalld
systemctl disable firewalld
8.hdfs的一键启动和停止
通过上面我们的启动发现,我们需要更换不同的机器来启动对应的节点,但是,机器越多的情况下,操作起来难度越大,所以,我们接下来配置在一台机器里面,将整个hdfs集群启动起来的命令
进入到sbin目录里面
cd /opt/apps/hadoop-3.1.1/sbin/
有两个文件:
start-dfs.sh
stop-dfs.sh

这两个就是一键启停hdfs系统的命令,执行后发现只启动了namenode或者启动了同一台机器上的namenode和datanode,那是因为我们在执行start-dfs.sh这个脚本时,脚本内部需要加载所有的datanode节点信息,加载的这个文件叫做workers

workers默认在etc/hadoop/目录内,所以我们应该先去把所有的datanode节点的ip配置到workers文件里面,那就进入目录内
cd /opt/apps/hadoop-3.1.1/etc/hadoop

然后编辑此文件:
vi workers
将里面内容删除,然后换成如下代码:
doit01
doit02
doit03
#这里配置的还是主机名映射,让start-dfs.sh文件启动时自动加载workers文件中的内容,
#获取到所有的datanode节点所在的机器,然后挨个启动
配置完毕以后,再次执行start-dfs.sh命令,查看是否能够启动成功,启动后,发现报错
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [doit02]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation
这个错是因为我们启动hdfs时候需要一些root用户的权限,而我们的start-dfs.sh里面没有对应的权限,所以我们应该给改文件添加上对应的权限信息
vi start-dfs.sh
vi stop-dfs.sh
然后在第二行插入
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
保存退出
重新执行start-dfs.sh命令,这样就能够启动成功了
其他配置:
配置在任意位置启动集群:因为我们现在只能在sbin目录下启动集群,类似于我们安装完jdk以后只能在bin目录下使用javac命令,所以我们应该配置以下环境变量,保证我们不管在任何位置都能够启动集群
cd /etc
vi profile
#添加以下代码
export HADOOP_HOME=/opt/apps/hadoop-3.1.1/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#保存退出
source profile
配置查看所有机器的hadoop进程的脚本文件
cd /opt/apps/scriptDir
#创建脚本文件
touch jps-all.sh
#编辑脚本文件
vi jps-all.sh
#脚本中的内容
#!/bin/bash
for host in doit01 doit02 doit03
do
echo "################$host进程状态###############"
ssh $host "source /etc/profile;jps;exit"
done
配置脚本文件任意位置运行
cd /etc/ #进入/etc目录
vi profile #编辑文件
添加以下代码
export SH_HOME=/opt/apps/scriptDir
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SH_HOME
#保存退出,然后执行
source profile
到此为止,所有的hdfs文件系统的安装和配置就搞定了,可以先去查看所有的机器的java进程情况,然后关闭对应的节点以后,再去使用start-dfs.sh命令一键启动集群
9.hdfs的shell客户端操作
启动集群以后,我们不仅可以通过监控页面直接查看hdfs文件系统,而且还能够通过命令操作hdfs端,默认命令是:
hdfs dfs 参数选项
例子:
hdfs dfs -ls / #查看当前hdfs的根目录下的所有成员
但是通过观察结果我们发现,结果显示的是我们linux下的根目录,也就是说,该命令默认操作的是linux的根目录,但是我们需要操作的是hdfs,所以修改命令为:
hdfs dfs -ls hdfs://doit01:8020/
但是如果我们一直这么写,比较麻烦,所以我们可以到配置文件中对其进行修改,将默认地址改为hdfs的根目录即可,先去查看默认配置文件中的默认操作目录地址:
该路径在core-default.xml里面

这里是默认配置文件中的配置,我们可以在core-sit.xml中重新配置即可:
cd /opt/apps/hadoop-3.1.1/etc/hadoop
vi core-site.xml
#添加下面代码到然后再次执行 hdfs dfs -ls /
发现操作的就已经是我们hdfs系统的根目录了
配置完毕之后,接下来我们来查看hdfs中的其他操作命令
标注以下常用命令:
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...] #查看hdfs系统中的文件内容
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...] #更改用户组
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] # 更改权限
[-chown [-R] [OWNER][:[GROUP]] PATH...] # 更改所属用户
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>] #上传
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] #下载
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...] #统计文件夹个数 文件个数 文件所在空间大小
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>] #复制
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]] #查看集群的存储能力
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...] #查找文件
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] #下载
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>] #查看文件前面几行内容
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]] #查看当前目录中的所有信息
[-mkdir [-p] <path> ...] # 创建文件夹
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>] #移动
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>] #上传
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] #删除文件
[-rmdir [--ignore-fail-on-non-empty] <dir> ...] #删除目录
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>] #查看文件后几行内容
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...] #创建文件
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
以上命令,加注释的都尽量记住!!!
注意事项:
1.修改hdfs中的某个目录权限时,如果想一并修改其内容文件权限,可以使用 hdfs dfs -chmod -R 777 文件夹这个命令
2.删除hdfs系统中的根目录下的所有文件时,需要使用绝对路径 hdfs dfs -rm -r hdfs://doit01:8020/*
10.hdfs的java客户端操作
10.1.准备工作:
- 1:创建一个maven的java项目
- 2:将依赖添加进pom.xml中
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.doit.hadoopgroupId>
<artifactId>doit29artifactId>
<version>1.0-SNAPSHOTversion>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>8source>
<target>8target>
configuration>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfs-clientartifactId>
<version>3.1.1version>
<scope>providedscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.30version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.62version>
dependency>
dependencies>
project>
- 3 不要忘了刷新项目,将依赖jar包下载到本地仓库中
10.2.文件上传的代码:
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class UploadFile {
public static void main(String[] args) throws URISyntaxException, IOException {
/*
将一个文件上传到hdfs的根目录
*/
//加载配置信息
Configuration conf = new Configuration();
//更改配置信息
// conf.set("dfs.blocksize","256M");
// conf.set("dfs.replication","2");
//确定要操作的系统的地址
URI uri = new URI("hdfs://doit01:8020");
//创建文件系统对象 根据配置信息和uri
FileSystem fs = FileSystem.newInstance(uri, conf);
//创建上传文件的路径
Path src = new Path("D:\\word.txt");
//创建接受文件的路径信息,这个路径是hdfs的根目录
Path dest = new Path("/");
//开始上传
fs.copyFromLocalFile(src, dest);
//关闭资源
fs.close();
}
}
注意:当我们同时在默认配置文件里面,site配置文件里面和代码里面配置了同一项内容时,优先级以代码中的配置最高,其次是site文件中,再其次是默认配置文件
我们可以从源码中获取一些配置文件的加载信息,来查看我们的配置文件加载的顺序:
1.在pom.xml文件中添加下面依赖:
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfs-clientartifactId>
<version>3.1.1version>
<scope>providedscope>
dependency>
2.ctrl + n搜索Namenode类,找到hadoop相关jar包下的Namenode类,点击进去
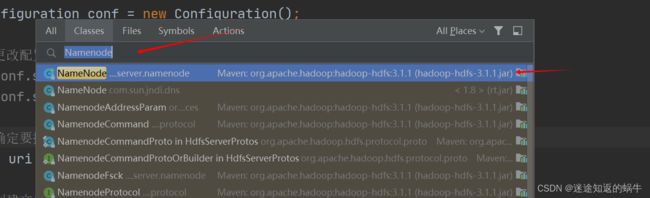
3.ctrl + f 搜索main方法:

4.创建配置文件对象,接着点击该方法进下一层源码
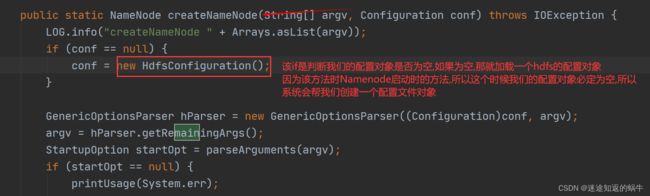 5.按着ctrl键然后用鼠标左键点击该方法:
5.按着ctrl键然后用鼠标左键点击该方法:

6.点击该类进入查看

7.进入该类,然后搜索core

观察发现,core也是在一个静态代码块中,所以,我们在加载hdfs配置文件之前,其实是先加载了core的配置文件的,由此推断出,我们的配置文件加载顺序是先default,然后site,这样的话,如果我们在site里面对default中的配置信息进行修改,那么就会覆盖掉default中的默认配置信息.而这些配置文件的加载只是在Namenode启动时加载的,那么在我们上传文件时,我们在代码里面再次设置一些配置,这个时候,就会再次覆盖掉site文件中的配置信息,以我们的配置信息为主,这就是为什么我们的配置信息有优先级顺序的原因
也可以通过debug调试查看相关的配置文件加载顺序:

10.3.文件下载的案例
package com.doit.hdp_demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class DownloadFile {
public static void main(String[] args) throws URISyntaxException, IOException {
//加载配置信息
Configuration conf = new Configuration();
//确定要操作的系统的地址
URI uri = new URI("hdfs://doit01:8020");
//创建文件系统对象 根据配置信息和uri
FileSystem fs = FileSystem.newInstance(uri, conf);
//创建接受文件的路径信息,这个路径是hdfs的根目录
Path src = new Path("/word.txt");
//创建上传文件的路径
Path dest = new Path("D:\\");
//开始上传
fs.copyToLocalFile(src, dest);
//关闭资源
fs.close();
}
}
注意事项:想要将hdfs上面的文件下载到本地目录中,需要在主机上配置hadoop环境
1.解压压缩包到本地目录,不要出现中文路径


2.配置环境变量
右键我的电脑选中属性选项:

3.进入新的界面后选择高级系统设置

4.再次进入页面后选择环境变量
5.然后选择新建
6.在新建框里面输入: 
7.上述点击确定退出后,再次找到path变量,选中,然后点击编辑

8.然后按照序号步骤进行操作即可:

最后一路点击确定即可退出,配置完毕之后不要忘记重启idea,这样才能重新加载本地配置,如果想要查看是否配置成功,可以win+r快捷键输入cmd,然后输入hdfs命令查看效果,如果出现的是以下内容,那么就证明配置成功.

这样就能保证我们将hdfs系统里面的文件下载到本地磁盘上
10.4 修改文件名和移动
package com.doit.hdp_demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class RenameAndMoveDemo {
public static void main(String[] args) throws URISyntaxException, IOException {
//加载配置信息
Configuration conf = new Configuration();
//确定要操作的系统的地址
URI uri = new URI("hdfs://doit01:8020");
//创建文件系统对象 根据配置信息和uri
FileSystem fs = FileSystem.newInstance(uri, conf);
Path a = new Path("/a") ;
//目标的文件夹一定要存在才能移动
if(fs.exists(a)) { // 存在
if(fs.isDirectory(a)) { // 并且是一个文件夹
//移动
//fs.rename(new Path("/b.txt"), new Path("/a/b.txt")) ;
//重命名
fs.rename(new Path("/a/b.txt"), new Path("/a/c.txt")) ;
}
}
fs.close();
}
}
10.5.删除案例
package com.doit.hdp_demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class DeleteFileDemo {
public static void main(String[] args) throws URISyntaxException, IOException {
//加载配置信息
Configuration conf = new Configuration();
//确定要操作的系统的地址
URI uri = new URI("hdfs://doit01:8020");
//创建文件系统对象 根据配置信息和uri
FileSystem fs = FileSystem.newInstance(uri, conf);
Path f = new Path("/a");
// 路径是否存在
if(fs.exists(f)) {
// 递归删除文件夹
fs.delete(f, true) ;
}else {
System.out.println("路径不存在");
}
fs.close();
}
}
10.6.创建文件夹
package com.doit.hdp_demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class MkDirDemo {
public static void main(String[] args) throws URISyntaxException, IOException {
//加载配置信息
Configuration conf = new Configuration();
//确定要操作的系统的地址
URI uri = new URI("hdfs://doit01:8020");
//创建文件系统对象 根据配置信息和uri
FileSystem fs = FileSystem.newInstance(uri, conf);
fs.mkdirs(new Path("/a/b/c")) ;
fs.close();
}
}
10.7 判断是否是文件夹:
package com.doit.hdp_demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class IsDirDemo {
public static void main(String[] args) throws URISyntaxException, IOException {
//加载配置信息
Configuration conf = new Configuration();
//确定要操作的系统的地址
URI uri = new URI("hdfs://doit01:8020");
//创建文件系统对象 根据配置信息和uri
FileSystem fs = FileSystem.newInstance(uri, conf);
// Path path = new Path("/a");
Path path = new Path("/b.txt");
// fs.isFile(arg0) // 是否是文件
boolean b = fs.isDirectory(path); // 是否是文件夹
if (b) {
System.out.println("文件夹");
} else {
System.out.println("文件");
}
fs.close();
}
}
10.8 遍历文件夹
package com.doit.hdp02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class HdfsDemo1 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//创建文件对象
FileSystem fs = FileSystem.newInstance(new URI("hdfs://doit01:8020"), conf, "root");
//查看HDFS的根目录中的内容
FileStatus[] fst = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fst) {
// fileStatus 路径下的文件或者文件夹
if (fileStatus.isDirectory()) {
//文件夹
Path path = fileStatus.getPath();
System.out.println(path);
// 遍历文件夹下的文件 --> 文件性质的操作 获取元信息
//listFiles() ;
} else {
// 文件 获取元信息 路径 名字 大小 .....
fileStatus.getPath();
// 获取文件名
fileStatus.getPath().getName();
// 父级路径
fileStatus.getPath().getParent();
// 最后访问时间
fileStatus.getAccessTime();
// 最后修改时间
fileStatus.getModificationTime();
// 副本的葛素
fileStatus.getReplication();
// 块大小
fileStatus.getBlockSize();
//大小
fileStatus.getLen();
}
}
fs.close();
}
}
10.9 遍历文件,获取元数据信息
package com.doit.hdp02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.net.URI;
import java.util.Arrays;
public class HdfsDemo2 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//创建文件对象
FileSystem fs = FileSystem.newInstance(new URI("hdfs://doit01:8020"), conf, "root");
//查看HDFS的根目录中的内容
//第一个参数是我们的HDFS 需要操作的目录
//第二个参数是是否递归获取该目录中的文件 如果为true 就递归获取 如果为false 就不递归
RemoteIterator<LocatedFileStatus> fr = fs.listFiles(new Path("/"), false);
while(fr.hasNext()){
LocatedFileStatus ls = fr.next();
String name = ls.getPath().getName();
if (name.equals("hadoop")) {
BlockLocation[] bt = ls.getBlockLocations();
System.out.println(Arrays.toString(bt));
long length = bt[2].getLength(); //获取每一块数据块的大小
String[] names = bt[0].getNames(); // 获取ip地址加端口号
String[] hosts = bt[0].getHosts(); // 存储该物理块的所有的节点的主机名
String[] ids = bt[0].getStorageIds();
StorageType[] st = bt[0].getStorageTypes();
System.out.println(Arrays.toString(st));
//第一个是偏移量 第二个是块的大小 后面的三个参数是分别存储于哪个节点
//[0,134217728,doit02,doit03,doit01, 134217728,134217728,doit02,doit03,doit01, 268435456,66123926,doit02,doit03,doit01]
}
}
}
}
10.10 读数据
随机读取数据
seek()方法 字节流
skip() 方法 字符流
public class ReadDataFromHdfsFile {
public static void main(String[] args) throws Exception {
FileSystem fs = HDFSUtils.getFs();
Path path = new Path("/a.txt") ;
/* 字节读取
* if(fs.exists(path)) {
// 获取一个文件的输入流
FSDataInputStream fis = fs.open(path);
// 跳跃 随机读取
fis.seek(2);
//从头读取
int i = fis.read() ;
System.out.println(i);
fis.close();
}*/
if(fs.exists(path)) {
// 获取一个文件的输入流
FSDataInputStream fis = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(fis));
// 跳过指定的位置读取
//注意 windows中的文本换行是\r\n linux中是\n 实际每行的长度是 length+2 / +1
br.skip(4) ; //ok\n // ok\r\n
String line = br.readLine();
System.out.println(line);
}
fs.close();
}
}
10.11 写数据
对随机的写是不支持的 , 不建议随机写 文件内容不允许修改 不建议修改文件内容和直接写数据到hdfs中
/**
* 注意 :
* hdfs的设计目的是为了存储海量的数据
* 对随机的写是不支持的 , 不建议随机写 文件内容不允许修改
* 追加内容很少操作
*
*/
public class WriteDataToHdfsFile {
public static void main(String[] args) throws Exception {
FileSystem fs = HDFSUtils.getFs();
//fs.append(new Path("追加内容")) ;
FSDataOutputStream fos = fs.create(new Path("/xx.oo"));
// 默认是对个 fos的覆盖
fos.writeUTF("hello tom cat ");
fos.write("hello".getBytes());
fos.flush();
fos.close();
fs.close();
}
}
11.hdfs的内部原理机制
11.1.hdfs的写数据的流程
HDFS的写数据流程是hadoop中最复杂的流程之一
简图如下:

详图如下:

1.客户端生成一个DistributedFileSystem对象,然后请求namenode上传文件word.txt
2.namenode根据文件名从目录树中进行查询操作,查看改文件是否存在,已经客户端用户是否有权限在分布式系统中创建文件,然后返回响应状态,ok,可以上传
3.DistributedFileSystem请求上传第一部分文件,并且申请block块信息
4.namenode创建block块信息,包括blockID,BGS(block Generation Stamp),offset,len,replication,存储的datanode地址,并将信息返回给client
5.client接受到namenode的返回信息以后,创建一个FSOutputStream对象,先去架设连接管道,也就是我们说的Pipeline
6.管道架设好以后,会创建出来FSDataInputStream流将blk01中的内容读到一个buf中,buf大小为4096,也就是4KB,然后每次读满一个buf,就会flush一次,flush出去的数据,会写到chunk中,一个chunk大小为512b的数据内容加上4b的校验(checksum)内容,也就是516b,chunk是数据传输过程中的最小校验单位,然后再将chunk写入到packet中,packet是client和datanode进行数据传输的最小单位,一个packet大概是64KB,相当于126个chunk,也就是说一个packet里面保存了126个chunk,然后,但是可能装不满packet,64kb相当于是65536b,516*126大小等于65016,其实packet里面还包含了一些packet的头信息,也就是packet的一些默认值,所以最多包含了126个chunk
7.一个packet写好以后.将packet保存在dataqueue中,然后通过FSOutputStream将队列中的packet写出去,一旦队列中的数据被写出去,就会将队列中的数据移除到ackqueue中,这是一个应答队列,负责接受Pipleline返回来的应答机制
8.datanode接受到packet以后,会将数据序列到本地磁盘,然后继续将packet发送到下一台机器上,直到最后一台datanode保存完毕之后,然后返回应答信息(ack),packet的发送顺叙是上游到下游,ack的返回机制时下游到上游,然后由最上游做统计,返回给最终的客户端
9,客户端校验应答ack,发现没有问题,先将ackqueue中的packet移除,移除完毕之后,就会给namenode发送保存成功,然后接着发送下一块儿数据,直到全部发送完成,
10,如果在发送过程中,其中某一台datanode没有保存成功,那么这台datanode会自动退出Pipleline,然后client再检测ack时,发现应答数不对,会先停止发送packet,然后将出错的packet从ackqueue中移动到dataqueue,再次发送
11.再次发送之前,客户端将重新架设Pipleline,并且根据 fs.client.block.write.replace-datanode-on-failure.policy/enable 的设置决定是否寻找新的节点代替BadNode,客户端向NameNode申请新的BGS,这个BGS将在重新架设流水线成功后,成为副本和block的BGS。这样BadNode的副本的BGS就和还健在的DataNode,以及NameNode那边block的BGS相差,如果以后BadNode重启,重新向namenode进行副本汇报时,那么因为副本的版本(BGS是Replica的版本标识)过老,而被要求删除,就保证了badnode不会存储一个不完整的副本
数据处理的一些源代码:



DataXceiverServer.java里面的代码都是datanode的接受数据的代码,这里不再展示
应答异常的一些处理:



这里显示根据BadNode出现的时间段,选择不同的处理方式,1.创建阶段,2.传输阶段,3.关闭阶段,添加完新节点以后,会重新生成新的Pipleline,具体要不要添加新的节点

具体是否要添加节点,可以根据配置文件中的这个参数进行参考

如果不需要添加新的节点,那么就继续使用剩下的节点建立新的Pipleline进行数据传输

上面源码,不建议掌握,了解即可!!
从 pipeline setup 错误中恢复
1.在 pipeline 准备阶段发生错误,分两种情况:
新写文件:Client 重新请求 NameNode 分配 block 和 DataNodes,重新设置 pipeline。
追加文件:Client 从 pipeline 中移除出错的 DataNode,然后继续。
2.从 data streaming 错误中恢复
当 pipeline 中的某个 DataNode 检测到写入磁盘出错(可能是磁盘故障),它自动退出 pipeline,关闭相关的 TCP 连接。
当 Client 检测到 pipeline 有 DataNode 出错,先停止发送数据,并基于剩下正常的 DataNode 重新构建 pipeline 再继续发送数据。
Client 恢复发送数据后,从没有收到确认的 packet 开始重发,其中有些 packet 前面的 DataNode 可能已经收过了,则忽略存储过程直接传递到下游节点。
3.从 close 错误中恢复
到了 close 阶段才出错,实际数据已经全部写入了 DataNodes 中,所以影响很小了。Client 依然根据剩下正常的 DataNode 重建 pipeline,让剩下的 DataNode 继续完成 close 阶段需要做的工作。
以上就是 pipeline recovery 三个阶段的处理过程,这里还有点小小的细节可说。 当 pipeline 中一个 DataNode 挂了,Client 重建 pipeline 时是可以移除挂了的 DataNode,也可以使用新的 DataNode 来替换。这里有策略是可配置的,称为 DataNode Replacement Policy upon Failure,包括下面几种情况:
NEVER:从不替换,针对 Client 的行为
DISABLE:禁止替换,DataNode 服务端抛出异常,表现行为类似 Client 的 NEVER 策略
DEFAULT:默认根据副本数要求来决定,简单来说若配置的副本数为 3,如果坏了 2 个 DataNode,则会替换,否则不替换
ALWAYS:总是替换
11.2.hdfs的文件下载

11.3.hdfs中的NN和DN的交互

DN向NN汇报当前解读信息的时间间隔,默认6小时;

DN扫描自己节点块信息列表的时间,默认6小时

11.4.hdfs中的checkpoint

首先我们要考虑一个问题:NameNode的元数据到底存储在什么位置?
假设:
1.存储在磁盘上,由于用户需要经常访问我们的hdfs做一些增删改查操作,所以,对于我们来说,存储在磁盘上并不是特别好的办法,因为操作越多,磁盘的IO越多,就会造成响应速度慢,效率低下,这明显不是我们需要的
2.存储在内存中,交互速度快,外界的增删改查我们都能即使更新自己的元数据,但是一旦系统断电,那么我们的元数据就会从内存中消失,导致我们的集群没法工作,所以元数据不能单纯的存放在内存中.
所以我们可以使用第三种方式,就是元数据一部分在内存中和客户端做交互,然后为了元数据的安全性,我们还会每隔一段时间对将元数据序列化到磁盘上,那么新的问题产生了,多久序列化一次比较好,时间过长,容易造成序列化文件和内存中的元数据不一致,时间过短,又会造成磁盘和内存的大量IO,还是会影响我们的效率和性能,所以,在这个过程中,我们又加入一个新的日志文件,这个日志文件专门用于记录两次序列化之间的操作信息,这样即使两次序列化之间出现了断电,造成内存中的元数据丢失,但是我们可以通过日志文件和磁盘的元数据文件反序列化到内存中,依然能恢复到断电前的状态,日志文件时不断被追加写入的,所以如果一直追加写入,内容只会越来越多,所以,我们实际的日志文件是有非常多的,没写够一定的数量,就会被替换成一个新的日志文件
NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage(元数据的镜像文件)和Edits(日志)文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。

每次NameNode启动,都会先加载fsimage进入内存,然后再将日志中的操作加载过来,保证元数据是最新的
checkpoint的时间设置:
要么一小时更新一次,要么当edits日志操作记录达到100W执行一次


secondaryNameNode多久询问一次是否执行checkpoint?? 一分钟询问一次

如果你想查看镜像文件和日志文件中的内容,直接查看是乱码,因为里面都是一些序列化的内容,可以通过两个命令进行查看:
oiv:查看镜像文件
oev:查看日志文件

命令格式:
# 以XML的形式查看镜像文件和日志文件
hdfs oiv -p XML -i fsimage_0000000000000000000 -o ./fsimage.xml
hdfs oev -p XML -i edits_0000000000000006828-0000000000000006829 -o ./fsimage.xml

上图就是变成xml文件后的日志文件
12.什么是MR
12.1 MR的概念:
MR全称叫做MapReduce
MapReduce 本身是用于并行处理大数据集的软件框架
12.2 MR的解释:
可能大部分同学看了以上的内容还是不能对MR有一个很好地理解,那么,接下来,我们可以来对以上的内容进行分析解释,达到最好的理解效果:
1.什么是分布式运算?
一个总任务,分配给多台机器,不同机器上面执行对应的子任务,直到最后总任务完成,这就是所谓的分布式运算.
举个例子:
2021年进行的全国人口普查:
1.如果是由北京进行统一普查,这是可以的,但是效率很慢,而且工作量巨大,可能会造成工作停滞现象.
2.那我们怎么做,我们可以把工作进行划分,按照地级市进行划分,比如河南省,按照许昌,驻马店,郑州,洛阳等地级市进行各自统计,然后将各个地级市的统计结果汇总给省份做第一次合并统计
3.省内第一个合并统计过后,再将省内数据给到首都,首都做二次汇总,这样最终就实现了人口的大普查操作
这个例子中,我们就用到了MR的思想,首先,按照地级市统计人口就是任务的划分,有多少个地级市,就相当于我们把大任务划分成了多少个小任务,这就是我们MR阶段的M阶段,叫做map阶段,map阶段主要做得就是映射统计,得到的最终结果是一些键值对儿.
而我们的两次汇总阶段可以理解为Reduce阶段,他的最终目的是将结果进行合并,当然,最终的合并结果并不是一成不变的,可以根据需求不断变化
2.为什么要使用分布式运算?
因为单台机器运算资源不足.
由于单台机器的性能原因,可能无法满足我们的运算需求,所以我们可以借助多台机器合作,帮助我们完成最终的运算结果.
对于大数据来说,并行计算可以提高更多的运行效率,而我们的分布式运算,就可以使用并行运算,对大数据文件的处理达到更好的效果
3.MR的优点:
1.MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2.良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3.高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4.适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并行工作,提供数据处理能力。
4.MR的缺点
1.不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2.不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3.不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
有向无环图:在图论中,如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。

13.MR的核心思想:
MR的核心思想如下图所示:

MR一共将一个任务分为两大阶段,一个叫map阶段,一个叫reduce阶段,map阶段将一个文件或者多个文件划分称多个map任务,然后执行map任务,将结果传递给reduce阶段,reduce阶段做最终的结果合并
MR的入门案例:
WordCount:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDemo2 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wordcount");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(2);
FileInputFormat.setInputPaths(job,new Path("D:\\hdp_data\\wdcount.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\wd_values"));
job.waitForCompletion(true);
}
static class WordCountMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] sp = value.toString().split("\\s+");
for (String s : sp) {
Text k = new Text(s);
IntWritable v = new IntWritable(1);
context.write(k, v);
}
}
}
static class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count++;
}
context.write(key, new IntWritable(count));
}
}
}
13.1 Map阶段:
13.1.1 map任务切片的划分(splits)
map阶段会将一个文件或者多个文件按照文件的大小或者数量进行任务划分,划分出来的任务称之为任务切片(splits),每一个任务切片对应一个map任务,每一个map任务都需要在一个MapTask中才能执行.
MapTask: map任务在运行时的一个容器
任务切片默认划分策略:
- 按照文件大小进行划分:
默认情况下,是将一个文件按照128M进行划分,也就是说一个200M文件,会被分配给两个任务
1.第一个map任务读取0-128M的数据
2.第二个map任务读取128-200M的数据
注意事项:任务切片和hdfs的物理切块不一样,物理切块是将文件切割成一个个的block,而任务切片只是把一个文件划分给多个任务,每个任务读取其中的一部分
任务切片默认按照128M,但是如果一个文件剩余的大小不超过128M的1.1倍,就不会继续切割
举例:
一个文件大小268M,那么在做任务切片时,会先判断该文件的大小是否大于128的1.1倍,
如果大于,就将前128M的数据交给第一个map任务去处理,
然后再去判断剩余的数据大小是否大于128M的1.1倍,如果大于,就继续将中间的128M分给第二个任务,
如果剩余的文件数据大小不大于128M的1.1倍,那就将剩余的所有的内容数据划分给第二个任务
- 按照文件数量进行划分:
还有一种划分方式就是如果传递过来的文件是一堆小文件,每个小文件都小于128M的1.1倍,那么每个小文件都是一个map任务,有多少个小文件就会生成多少个map任务
注意事项: 当小文件数量过多时,会导致切片数量过多,浪费资源,所以,尽量不要使用MR处理小文件
切片的源码:
在FileInputFormat 类中有一个 getSplits()方法


13.1.2 map任务如何读取数据(TextInputFormat)
map任务读取数据时,是按照任务切片从hdfs中读取该切片对应的文件的block,读取的时候,默认按照一次一行的方式读取数据,读出来的数据会以KV对儿的形式在整个MR流程中进行传递
K:当前读取的行的起始偏移量
V:当前读取的行内容,
默认读取类:TextInputFormat类
TextInputFormat的内部有一个方法createRecordReader(),该方法给我们返回一个数据的提取器LineRecordReader,该提取器就是最终读取文件内容的类,默认是按照一行一行的方式进行读取
源码如下:
TextInputFormat

注意事项:上面的TextInputFormat只是默认的MR的读取方式,我们后续也可以通过设置,修改他的读取方式,这点有点类似于IO流中到底是按照字节读还是按照字符读还是按照行读取,此处先使用默认的读取方式
问题: 数据从文件中读取出来之后,去了哪里?
因为MR是一个系统框架,该框架内部将读取出来的数据按照键值对儿放入到一个上下文对象中(Context),通过Context将数据传递给当前任务的map方法,在map方法中有具体的数据处理逻辑.
Context: 上下文对象,作用于整个MR流程,负责将数据从上游传递到下游
框架中的map方法并没有具体的实现逻辑,因为框架不知道用户使用该方法的具体处理方案,所以将该方法留给用户进行重写,让用户进行自定义,所以在当前框架中,给用户留了两个类分别叫Mapper和Reducer,用户需要通过继承这两个类,重写内部的map和reduce方法,完成逻辑的补充,而数据被读取出来之后,也会最终传递给Mapper中的map方法和Reducer中的reduce方法,重写这两个方法之后,就可以使用多态的形式,让MR框架运行我们写好的处理逻辑,写法如下:
public class WordCountDemo {
// map任务 继承mapper类
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context){
// map任务对文件读取出来的数据的处理逻辑
}
}
//reduce任务 继承reducer类
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context){
// reduce任务对map任务传递过来的数据的处理逻辑
}
}
}
上述代码在WordCountMapper 继承Mapper类和Reducer类时,需要指定4个泛型,下面来讲解每一个泛型代表的意思:
Mapper
- LongWritable: 这个泛型代表的是数据被TextInputFormat读取到map任务中时的key,该key默认情况下是每一行数据的起始偏移量,比如 第一行有 a a a三个字符 那么第一行的起始偏移量就是0,第二行的起始偏移量就是第一行的字节数+1,所以我们一般使用整数类型来表示该泛型,但是由于大数据中文件比较大,可能会导致我们的起始偏移量超过int范围,所以使用long类型来进行替代.
那为什么此处是LongWritable呢??
因为数据在传输的过程中必定要经过内存,所以数据一般要经过序列化才能传输,而Long这个类实现的是java中的序列化接口,但是该接口在序列化对象时,会将对象序列化的数据量变得很大,假设一个保存了10个字节的对象,被java的序列化接口序列化之后,存入到文件中后可能会变成80个字节,这样很容易造成我们的文件数据越来越大,越来越难处理,序列化的过程可以自己测试,所以hadoop给我们提供了一种自己封装的序列化方式,他按照自己的序列化方式,提供了几种常见的序列化类,分别是:
LongWritable ,IntWritable , Text(类似于java中的字符串), NullWritable(类似于java中的null值)…
如果是自定义类型想要在hadoop中实现序列化,只需要实现Writable接口即可,这个接口就是hadoop给我们提供的序列化接口. - Text: 这个泛型是我们读取的每一行的内容,默认每一行内容都是String,所以使用Text
- Text: 将内容处理后,发送给reduce端时,以Text类型为key进行发送,此案例是做wordcount统计,所以,我们以处理后的每一个单词为key,单词都是String类型,所以使用Text
- IntWritable: 每一个单词在当前行出现的次数
Reducer
- Text: map端传递数据时,后面的两个泛型的key是什么,这个就是什么
- IntWritable: map端传递数据时,后面的两个泛型的value是什么,这个就是什么
- Text: 做汇总后的每个单词
- IntWritable: 每一个单词在当前文件中出现的总次数
13.1.3 map方法执行的生命周期:
map方法在执行前,Mapper类会从上下文环境中获取当前读取的文件是否还有下一行数据,只要有,Mapper类就会将该行数据取出,然后交给具体的map逻辑进行处理,所以map方法基本上就是一行数据会被调用一次,所以map方法是一个被循环调用执行的方法,源码如下:

13.1.3 map任务如何对数据进行输出处理(MapOutputBuffer)
map任务对数据进行处理完毕之后,会通过上下文传递给一个数据收集器,该数据收集器的类是NewOutputCollector,
该类中有一个方法write,源码如下:

该收集器将数据收集进MapOutputBuffer,该类是一个缓冲区类,专门用于存储map端的输出数据,而且是对数据进行分区存储,该缓冲区大小是100M,有一个阈值上限80M,一旦map写入该缓冲区的数据到达了80M的阈值,那么缓冲区就会将数据溢写出去,形成文件,并且在缓冲区的collect方法中,还会对我们的map端输出的key和value进行序列化,这就是为什么我们需要提前使用序列化的原因,
100M的缓冲区,80M存储数据,20M存储kvmeta,kvmeta中存储了kv的索引和分区,以及key的起始位置,value的起始位置和value的长度等信息
原码如下:

溢写出去的数据,会被存储到磁盘上形成文件,文件内的数据会按照分区器的提供的分区标记进行分区存储,那么数据的key值的分区标记是什么时候被加载的呢???
在我们的Map端数据被收集进缓冲区的时候,就已经被分区器打上了分区标记,具体代码看上图.
分区器的实现看下面的分解
13.1.4 分区器(Partitioner)
什么是分区:
将Map的输出的数据按照key进行划分,默认是按照key的哈希值进行划分成n组,这个过程就叫做分区
分区的目的:
分区的目的就是提升reduce端聚合速度和效率,因为我们最终会把map端分成的n组数据,分配给不同的ReduceTask做聚合操作
分区器的执行时间:
Map端的分区器是在收集器(Collector)对代码进行收集时(collect)加载的

partitoner: 是一个分区器对象,MR中默认的分区器类是HashPartitioner,其内部有一个方法是对Map端输出的key值进行分区计算的

分区器的算法解释:
- key.hashCode() : 获取map端输出的key的哈希值
- & Integer.MAX_VALUE : 把key的哈希值的变为正数,取消负数的key值
- % numReduceTasks : 拿着上一步运算过后的key值 % reduceTask的数量
ReduceTask的数量默认为1,我们可以在代码端对ReduceTask进行设置
13.1.5 map阶段任务执行的简图

上图是一个MapTask的执行流程
MR阶段Map流程的简述:
1.job任务提交以后,系统根据job任务的输入路径,对job任务做任务切片
2.将任务切片存入到一个集合中,然后计算任务切片的数量,任务切片的数量决定了map任务的数量(一般称之为map任务的并行度)
3.每一个map任务分配到一个任务切片,任务切片中包含了当前map任务需要读取的文件的block的起始位置和长度,以及所存储的机器列表
4.map任务开始使用TextInputFormat读取block块中的数据
5.将数据读取出来之后,传递给我们自己写的map方法,然后经过map方法逻辑的处理,再传递给环形缓冲区(MapOutputBuffer)
6.传递给环形缓冲区时不是传递过去的,是被收集器收集过去的,被收集时,还会被打上分区标记,为溢写做准备
7.环形缓冲区内部会对数据进行排序,按照分区进行区内排序,使用快排的方式进行排序
8.当环形缓冲区内部数据达到80M的时候,会将数据溢写形成文件存储到磁盘上,溢写的文件也是按照分区进行溢写,
因为数据块最大为128M,而唤醒缓冲区80M溢写一次,所以可能会溢写多次,形成多个溢写文件.
9.对溢写文件进行合并,按照分区标记合并
10.对合并后的数据进行排序,按照归并排序的方式
11.开放Http的下载服务,然后等待reduce阶段将数据读取到reduce任务中
13.2 Reduce阶段:
13.2.1 reduce任务的数据获取
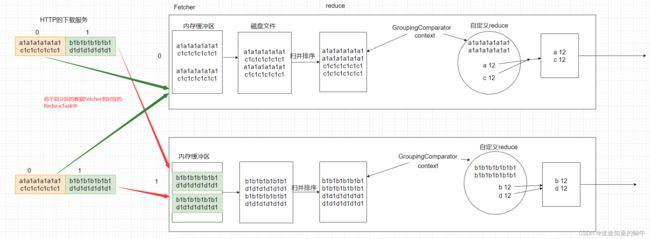
reduce阶段在map阶段之后执行,当map端的数据形成最终的分区文件之后,reduce阶段会通过Fetcher类去抓取分区文件中对应的分区的数据,每一个reduce对应一个ReduceTask,一个ReduceTask也叫做一个分区.
reduce的简图
13.2.2 reduce任务对数据的处理
- 1.通过Fetcher类将map端的数据文件按照分区标记进行数据抓取
- 2.数据抓取之后存放在内存中,当内存中到达阈值时,也会将数据溢写形成文件
- 3.对多个溢写文件进行合并并且排序,按照归并排序的形式
- 4.对合并排序后的数据进行分组,按照key相同的分到一组,通过GroupingComparator分组
- 5.将分组后的一组数据全部取出,使用上下文对象取出,然后传递给reduce方法
- 6.reduce方法会使用一个被重复利用的迭代器对一组key相同的数据的值进行迭代取出,最后做合并操作
- 7.reduce将合并后的数据通过context写出到最终的值文件夹中
13.2.3 reduce中的分组器和迭代器
分组器:GroupingComparator
排序后的数据会被reduce中的一个分组器分组,按照key进行划分,然后将key相同的一组数据通过上下文对象传递给我们重写的reduce任务做最终的逻辑处理
迭代器:
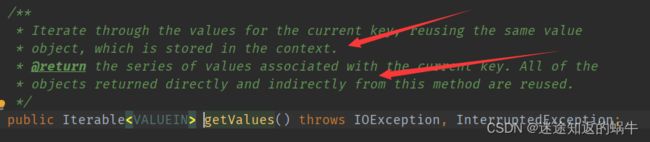
传送给重写的reduce的方法的数据是一组key相同的数据,所以我们在处理数据时,只需要将这一组值遍历取出即可,需要依赖ReduceTask给我们提供的迭代器,实现代码如下:

此处的迭代器对象是一个不断被赋值的重用对象,有点类似于单例模式,遍历一个值,将值赋给values,然后再在下面的逻辑中将values每次读取的值给到value,源码解释如下:
大概意思是返回一个可重用的值对象,不断的 从一组值中被赋值
13.2.4 reduce的最终输出
reduce方法会将最后处理后的数据通过上下文输出到我们的输出路径形成的文件夹内部,有几个分区,就会形成几个文件.

14.MR的案例代码:
14.1 入门案例:
package com.doit.hdp_day02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDemo1 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 求文件中每个单词出现的次数
Job job = Job.getInstance(conf, "wordcount");
//设置该MR任务执行时执行M和R任务的类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//设置map任务的输出泛型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce任务的输出泛型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置reduce的分区数
job.setNumReduceTasks(2);
//设置输出路径和输入路径
FileInputFormat.setInputPaths(job,new Path("D:\\hdp_data\\wdcount.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\hdp_data\\wdcount_value"));
//将任务提交到本地模式运行
job.waitForCompletion(true);
}
/*
默认情况下 hadoop会使用读一行 写入一行的操作 将数据传递给我们
KEYIN: 每一行的起始位置的字节偏移量 Long
VALUEIN: 每一行的内容 String
KEYOUT: String 输出的每个单词
VALUEOUT: 输出的每个单词在当前读取到的block块中的出现的次数 Integer
LongWritable
*/
static class WordCountMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// a a a a a a a a b b b
// a 1 a 1 a 1 a 1 a 1
String[] sp = value.toString().split("\\s+");
for (String s : sp) {
Text k = new Text(s);
IntWritable v = new IntWritable(1);
context.write(k, v);
}
}
}
/*
KEYIN, 跟map端的keyout类型一致
VALUEIN, 跟map端的valueout类型一致
KEYOUT, Text
VALUEOUT IntWritable
*/
static class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
// reduce 会把key相同的一组数据获取出来 将key相同的一组数据的值不断迭代获取
// reduce 是一组数据执行一次
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
}
14.2 温度案例:
package com.doit.hdp_day02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TemperatureDemo {
public static void main(String[] args) throws Exception {
/*
需求: 求出每一天的最高温度
//任务切片的数量和文件的大小 以及 文件的数量有关
*/
Configuration conf = new Configuration();
// 求文件中每个单词出现的次数
Job job = Job.getInstance(conf, "Temperature");
//设置该MR任务执行时执行M和R任务的类
job.setMapperClass(TemperatureMapper.class);
job.setReducerClass(TemperatureReducer.class);
//设置map任务的输出泛型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce任务的输出泛型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输出路径和输入路径
FileInputFormat.setInputPaths(job,new Path("D:\\hdp_data\\temperature"));
FileOutputFormat.setOutputPath(job,new Path("D:\\hdp_data\\temperature_value"));
//将任务提交到本地模式运行
job.waitForCompletion(true);
}
static class TemperatureMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] sp = value.toString().split("\\s+");
Text k = new Text(sp[0]);
IntWritable v = new IntWritable(Integer.parseInt(sp[1]));
context.write(k, v);
}
}
static class TemperatureReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int max = Integer.MIN_VALUE;
for (IntWritable value : values) {
int num = value.get();
max = Math.max(max, num);
}
IntWritable v = new IntWritable(max);
context.write(key, v);
}
}
}
14.3 电影案例:
1.每部电影的均分:
package com.doit.day03;
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MovieDemo1 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
/*
1.每部电影的均分
*/
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(MovieMapper.class);
job.setReducerClass(MovieReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\hdp_data\\movie"));
FileOutputFormat.setOutputPath(job,new Path("D:\\hdp_data\\movie_values"));
job.waitForCompletion(true);
}
static class MovieMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String jsonMovie = value.toString();
Movie movie = JSONObject.parseObject(jsonMovie, Movie.class);
Text k = new Text(movie.getMovie());
DoubleWritable v = new DoubleWritable(Double.parseDouble(movie.getRate()));
context.write(k, v);
}
}
static class MovieReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
double count = 0;
double sum = 0;
for (DoubleWritable value : values) {
count++;
sum += value.get();
}
DoubleWritable v = new DoubleWritable(sum / count);
context.write(key, v);
}
}
}
14.4 电影案例
2.每个人的均分
package com.doit.day03;
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MovieDemo2 {
//每个人的均分
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(MovieMapper2.class);
job.setReducerClass(MovieReducer2.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\hdp_data\\movie"));
FileOutputFormat.setOutputPath(job,new Path("D:\\hdp_data\\movie_values2"));
job.waitForCompletion(true);
}
static class MovieMapper2 extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String jsonMovie = value.toString();
Movie movie = JSONObject.parseObject(jsonMovie, Movie.class);
Text k = new Text(movie.getUid());
DoubleWritable v = new DoubleWritable(Double.parseDouble(movie.getRate()));
context.write(k, v);
}
}
static class MovieReducer2 extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
double count = 0;
double sum = 0;
for (DoubleWritable value : values) {
count++;
sum += value.get();
}
DoubleWritable v = new DoubleWritable(sum / count);
context.write(key, v);
}
}
}
14.5 电影案例:
3.每个人的均分
package com.doit.day03;
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MovieDemo3 {
//每个人的均分
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(MovieMapper3.class);
job.setReducerClass(MovieReducer3.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:\\hdp_data\\movie"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hdp_data\\movie_values3"));
job.waitForCompletion(true);
}
static class MovieMapper3 extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String jsonMovie = value.toString();
Movie movie = JSONObject.parseObject(jsonMovie, Movie.class);
Text k = new Text(movie.getMovie());
IntWritable v = new IntWritable(1);
context.write(k, v);
}
}
static class MovieReducer3 extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count++;
}
IntWritable v = new IntWritable(count);
context.write(key, v);
}
}
}
14.6 join案例
package com.doit.day04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
//com.doit.day04.JoinDemo1
public class JoinDemo1 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(JoinDemo1.class);
job.setMapperClass(JoinMapper.class);
job.setReducerClass(JoinReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
static class JoinMapper extends Mapper {
String fileName;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit fs = (FileSplit) context.getInputSplit();
fileName = fs.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
if (fileName.equals("order.txt")) {
String[] orderArr = s.split(",");
context.write(new Text(orderArr[1]), new Text(orderArr[0]));
} else if (fileName.equals("user.txt")) {
String[] userArr = s.split("-", 2);
context.write(new Text(userArr[0]), new Text(userArr[1]));
}
}
}
static class JoinReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
// user01 order01 order02 zs-m-20
/*
user01 order01 zs-m-20
user01 order02 zs-m-20
*/
ArrayList orderList = new ArrayList();
ArrayList userList = new ArrayList();
for (Text value : values) {
if (value.toString().contains("order")) {
orderList.add(value.toString());
} else {
userList.add(value.toString());
}
}
for (String o : orderList) {
for (String u : userList) {
StringBuilder sb = new StringBuilder(key.toString());
sb.append("--").append(o).append("--").append(u);
context.write(new Text(sb.toString()), NullWritable.get());
}
}
}
}
}
14.7 index案例
第一个MR
package com.doit.day04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* hello a.txt-2 b.txt-3 c.txt-2
* world a.txt-3 b.txt-1
*
*
* wordcount
* hello-a.txt 2
* hello-b.txt 2
*
*
* 切片数量是与 文件大小和文件数量相关
*/
public class IndexDemo1 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(IndexMapper.class);
job.setReducerClass(IndexReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:\\hdp_data\\index"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hdp_data\\index_values"));
job.waitForCompletion(true);
}
static class IndexMapper extends Mapper {
String fileName;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit fs = (FileSplit) context.getInputSplit();
fileName = fs.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
String[] sp = s.split("\\s+");
for (String s1 : sp) {
Text k = new Text(s1 + "-" + fileName);
IntWritable v = new IntWritable(1);
context.write(k, v);
}
}
}
static class IndexReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count++;
}
IntWritable v = new IntWritable(count);
context.write(key, v);
}
}
}
第二个MR
package com.doit.day04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class IndexDemo2 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(IndexMapper2.class);
job.setReducerClass(IndexReducer2.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("D:\\hdp_data\\index_values"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hdp_data\\index_values_two"));
job.waitForCompletion(true);
}
static class IndexMapper2 extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] sp = value.toString().split("-");
Text k = new Text(sp[0]);
Text v = new Text(sp[1].replaceAll("\\s+", "-"));
context.write(k, v);
}
}
static class IndexReducer2 extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
String s = "";
for (Text value : values) {
s = s + value.toString() + "\t";
}
Text v = new Text(s);
context.write(key, v);
}
}
}
14.7 预聚合
package com.doit.day04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDemo3 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setNumReduceTasks(2);
//设置Map端的预聚合操作
job.setCombinerClass(MyCombiner.class);
FileInputFormat.setInputPaths(job, new Path("D:\\hdp_data\\wdcount.txt"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hdp_data\\wd_values"));
job.waitForCompletion(true);
}
static class WordCountMapper extends Mapper {
Text k;
IntWritable v;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
k = new Text();
v = new IntWritable();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] sp = value.toString().split("\\s+");
for (String s : sp) {
k.set(s);
v.set(1);
context.write(k, v);
}
}
}
}
// 预聚合操作
class MyCombiner extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count++;
}
context.write(key, new IntWritable(count));
}
}
14.8 使用自定义分区器
package com.doit.day04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.lib.HashPartitioner;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDemo2 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setNumReduceTasks(2);
// 自定义分区器的使用
job.setPartitionerClass(MyPartitioner.class);
FileInputFormat.setInputPaths(job, new Path("D:\\hdp_data\\wdcount.txt"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hdp_data\\wd_values"));
job.waitForCompletion(true);
}
static class WordCountMapper extends Mapper {
Text k;
IntWritable v;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
k = new Text();
v = new IntWritable();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] sp = value.toString().split("\\s+");
for (String s : sp) {
k.set(s);
context.write(k, NullWritable.get());
}
}
}
}
// 自定义分区器
class MyPartitioner extends Partitioner {
static int count = 0;
@Override
public int getPartition(KEY key, VALUE value, int numPartitions) {
count++;
return count % numPartitions;
}
}
14.8 小文件的合并
切片时: 每一个文件对应一个或者多个任务切片,如果小文件过多,会生成大量的任务切片,消耗资源,所以我们可以将小文件进行合并操作:
package com.doit.day04;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDemo1 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定内容读取类 合并小文件的操作
job.setInputFormatClass(CombineTextInputFormat.class);
job.setNumReduceTasks(2);
FileInputFormat.setInputPaths(job, new Path("D:\\hdp_data\\word"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hdp_data\\word_values"));
job.waitForCompletion(true);
}
static class WordCountMapper extends Mapper {
Text k;
IntWritable v;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
k = new Text();
v = new IntWritable();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] sp = value.toString().split("\\s+");
for (String s : sp) {
k.set(s);
v.set(1);
context.write(k, v);
}
}
}
static class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count++;
}
//强引用 弱引用
context.write(key, new IntWritable(count));
}
}
}
15.YARN
15.1 yarn的简介
yarn是hadoop集群当中的资源管理系统模块,从hadoop2.0开始引入yarn模块,yarn可为各类计算框架提供资源的管理和调度,主要用于管理集群当中的资源(主要是服务器的各种硬件资源,包括CPU,内存,磁盘,网络IO等)以及调度运行在yarn上面的各种任务。
yarn核心出发点是为了分离资源管理与作业监控,实现分离的做法是拥有一个全局的资源管理(ResourceManager,RM),以及每个应用程序对应一个的应用管理器(ApplicationMaster,AM)
总结一句话就是说:yarn主要就是为了调度资源,管理任务等。
其调度分为两个层级来说:
一级调度管理:
计算资源管理(CPU,内存,网络IO,磁盘)
二级调度管理:
任务内部的计算模型管理(AppMaster的任务精细化管理)
15.2 yarn的角色介绍
- ResourceManager: YARN集群的主节点,控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。
- 调度器(ResourceScheduler):根据各个应用程序的资源需求,进行分配,对资源进行分配和调度,其内部是一个队列。
- NodeManager: YARN集群的从节点,NodeManager 提供针对集群中每个节点的服务,从监督对一个容器的生命周期到监视资源和跟踪节点健康。
- ApplicationMaster: 管理一个在 YARN 内运行的应用程序的每个实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
- container:这是一个虚拟的概念,yarn中所有应用都是在container之上运行的,包括ApplicationMaster
(1)container是yarn中资源的抽象,它封装了某个节点上一定的资源(CPU,内存,磁盘,网络等等)
(2)container由AM向RM申请,由RM中的ResourceScheduler分配给AM,运行AM的container、运行各类任务的container
15.2.1 ResourceManager基本职能
- ResourceManager需通过两个RPC协议与NodeManager和ApplicationMaster交互,具体如下:
1.1 ResourceTracker:NodeManager通过该RPC协议向ResourceManager注册、汇报节点健康状况和Container运行状态,并领取ResourceManager下达的命令,这些命令包括重新初始化、清理Container等,在该RPC协议中,NodeManager与ResourceManager之间采用了“pull模型”,NodeManager总是周期性地主动向ResourceManager发起请求,并通过心跳应答领取下达给自己得命令
1.2 ApplicationMasterProtocol:应用程序的ApplicationMaster通过该RPC协议向ResourceManager注册、申请资源和释放资源
1.3 ApplicationClientProtocol:应用程序的客户端通过该RPC协议向ResourceManager提交应用程序、查询应用程序状态和控制应用程序(比如杀死应用程序和修改应用程序优先级)等
1.4 ContainerManagementProtocol:ApplicationMaster通过该RPC协议要求NodeManager启动、停止Container和获得Containers的状态
概括起来,ResourceManager主要完成以下几个功能:
1.与客户端交互,处理来自客户端的请求 启动和管理ApplicationMaster,并在它运行失败时重新启动它;
2.资源管理和调度,接收来自ApplicationMaster的资源申请请求,并为之分配资源
3.管理NodeManager,接收来自NodeManager的资源汇报信息,并向NodeManager下达管理指令(比如杀死Container等)
15.2.2 ResourceManager内部架构
- ResourceM主要由以下几个部分组成:
用户交互模块:ResourceManager分别针对普通用户、管理员和Web提供了三种对外服务,具体实现分别对应ClientRMService、AdminService和WebApp
1. ClientRMService:ClientRMService是为普通用户提供的服务,它处理来自客户端的各种RPC请求,比如提交应用程序、终止应用程序、获取应用程序状态
2. AdminService:ResourceManager为管理员提供了一套独立的服务接口,管理员可通过这些接口管理集群,比如动态更新节点列表、更新ACL列表、更新队列信息等
3. WebApp:为了更加友好地展示集群资源使用情况和应用程序运行状态等信息。YARN对外提供了一个Web界面 NM管理模块
4. NMLivelineMonitor:监控NM是否活着,如果一个NodeManager在一定时间(默认为10min)未汇报心跳信息,则认为它死掉了,需要将其从集群中移除
5. NodesListManager:维护正常节点和异常节点列表,管理exclude(类似于黑名单)和include(类似于白名单)节点列表,这两个列表均是在配置文件中设置的,可以动态加载
6. ResourceTrackerService:处理来自NodeManager的请求,主要包括注册和心跳两种,其中,注册是NodeManager启动时发生的行为,请求包中包含节点的ID、可用的资源上线等信息;而心跳是周期性行为,包括各个Container运行状态、运行的各个Application列表、节点健康状况(可通过一个脚本设置)等信息,作为请求的应答,ResourceTrackerService可为NodeManager返回待释放的Container列表、Application列表等信息 - AM管理模块:
1. AMLivelinessMonitor:监控AM是否活着,如果一个ApplicationMaster在一定时间(默认为10min)内未汇报心跳信息,则认为它死掉了,它上面所有正在运行的Container将被置为失败状态,而AM本身被重新分配到另外一个节点上(用户可指定每个ApplicationMaster的尝试次数,默认是2)执行
2. ApplicationMasterLauncher:与某个NodeManager通信,要求它为某个应用程序启动ApplicationMaster
3. ApplicationMasterService(AMS):处理来自ApplicationMaster的请求,主要包括注册和心跳两种请求,其中,注册是ApplicationMaster启动时发生的行为,注册请求包中包含ApplicationMaster启动节点;对外的RPC端口号和tracking
4. URL等信息;而心跳则是周期性行为,汇报信息包含所需资源描述、待释放的Container列表、黑名单列表等,而AMS则为之返回新分配的Container、失败的Container、待抢占的Container列表等信息 - Application管理模块:
1. ApplicationACLsManager:管理应用程序访问权限,包含两部分权限:查看权限和修改权限。查看权限主要用于查看应用程序基本信息,而修改权限则主要用于修改应用程序优先级、杀死应用程序等
2. RMAppManager:管理应用程序的启动和关闭
3. ContainerAllocationExpirer:当AM收到RM新分配的一个Container后,必须在一定时间(默认为10min)内在对应的NM上启动该Container,否则RM将强制回收该Container,而一个已经分配的Container是否该被回收则是由ContainerAllocationExpirer决定和执行的 - 状态机管理模块
1. RMApp:RMApp维护了一个应用程序(Application)的整个运行周期,包括从启动到运行结束整个过程。由于一个Application的生命周期可能会启动多个Application运行实例(ApplicationAttempt),因此可认为,RMApp维护的是同一个Application启动的所有实例的生命周期
2. RMAppAttempt:一个应用程序可能启动多个实例,即一个实例运行失败后,可能再次启动一个重新运行,而每次启动称为一次运行尝试(或者“运行实例”),用“RMAppAttempt”描述,RMAppAttempt维护了一次运行尝试的整个生ing周期
3. RMContainer:RMContainer维护了一个Container的运行周期,包括从创建到运行结束整个过程。目前YARN尚不支持Container重用,一个Container用完后会立刻释放,将来可能会增加Container重用机制
4. RMNode:RMNode维护了一个NodeManager的生命周期,包括启动到运行结束整个过程 - 安全管理模块:ResourceManager自带了非常全面的权限管理机制
- 资源分配模块:
该模块主要涉及一个组件——ResourceScheduler。ResourceScheduler是资源调度器,它按照一定的约束条件(比如队列容量限制等)将集群中的资源分配给各个应用程序,当前主要考虑内存和CPU资源。ResourceScheduler是一个插拔式模块,YARN自带了一个批处理资源调度器——FIFO和两个多用户调度器——Fair Scheduler和Capacity Scheduler
15.2.3 NodeManger
NodeManager是运行在单个节点上的代理,它管理Hadoop集群中单个计算节点,功能包括与ResourceManager保持通信,管理Container的生命周期、监控每个Container的资源使用(内存、CPU等)情况、追踪节点健康状况、管理日志和不同应用程序用到的附属服务等。
NodeManager是YARN中单个节点的代理,它需要与应用程序的ApplicationMaster和集群管理者ResourceManager交互;它从ApplicationMaster上接收有关Container的命令并执行(比如启动、停止Contaner);向ResourceManager汇报各个Container运行状态和节点健康状况,并领取有关Container的命令(比如清理Container)
15.2.4 NodeManger的基本职能
两个主要的协议 ResourceTrackerProtocol协议 和 ContainerManagementProtocol协议
-
ResourceTrackerProtocol协议
a.registerNodeManager
注册自己,需要告诉RM自己的host ip、端口号、对外的tracking url以及自己拥有的资源总量(当前支持内存和虚拟内存两种资源)。
b.nodeHearbeat
NodeManager启动后,通过RPC协议向ResourceManager注册、汇报结点健康状况和Container运行状态,并领取ResourceManager下达的命令,包括重新初始化、清理Container占用资源等。 -
ContainerManagementProtocol协议
应用程序的ApplicationMaster通过RPC协议向NodeManager发起针对Container的相关操作,包括启动Container、杀死Container、获取Container执行状态。
ApplicationMaster可以将Container相关操作通过RPC的方式第一时间告诉NodeManager。
15.2.5 NodeManager的内部架构

-
NodeStatusUpdater
NodeStatusUpdater是NodeManager与ResourceManager通信的唯一通道。当NodeManager启动时,该组件向ResourceManager注册,并汇报节点上可用的资源(该值在运行过程中不再汇报);之后,该组件周期性与ResourceManager通信,汇报各个Container的状态更新,包括节点上正运行的Container、已完成的Container等信息,同时ResouceManager会返回待清理Container列表、待清理应用程序列表、诊断信息、各种Token等信息。 -
ContainerManager
ContainerManager是NodeManager中最新核心的组件之一,它由多个子组件构成,每个子组件负责一部分功能,它们协同工作组件用来管理运行在该节点上的所有Container,其主要包含的组件如下:
1.RPCServer 实现了ContainerManagementProtocol协议,是AM和NM通信的唯一通道。ContainerManager从各个ApplicationMaster上接受RPC请求以启动新的Container或者停止正在运行的Contaier。
2.ResourceLocalizationService 负责Container所需资源的本地化。能够按照描述从HDFS上下载Container所需的文件资源,并尽量将他们分摊到各个磁盘上以防止出现访问热点。此外,它会为下载的文件添加访问控制权限,并为之施加合适的磁盘空间使用份额。
3.ContainerLaucher 维护了一个线程池以并行完成Container相关操作。比如杀死或启动Container。 启动请求由AM发起,杀死请求有AM或者RM发起。
4.AuxServices NodeManager允许用户通过配置附属服务的方式扩展自己的功能,这使得每个节点可以定制一些特定框架需要的服务。附属服务需要在NM启动前配置好,并由NM统一启动和关闭。典型的应用是MapReduce框架中用到的Shuffle HTTP Server,其通过封装成一个附属服务由各个NodeManager启动。
5.ContainersMonitor 负责监控Container的资源使用量。为了实现资源的隔离和公平共享,RM 为每个Container分配一定量的资源,而ContainerMonitor周期性的探测它在运行过程中的资源利用量,一旦发现Container超过它允许使用的份额上限,就向它发送信号将其杀死。这可以避免资源密集型的Container影响到同节点上的其他正在运行的Container。
注:YARN只有对内存资源是通过ContainerMonitor监控的方式加以限制的,对于CPU资源,则采用轻量级资源隔离方案Cgroups. -
NodeHealthCheckservice
结点健康检查,NodeHealthCheckSevice通过周期性地运行一个自定义的脚步和向磁盘写文件检查节点健康状况,并通过NodeStatusUpdater传递给ResouceManager.而ResouceManager则根据每个NodeManager的健康状况适当调整分配的任务数目。一旦RM发现一个节点处于不健康的状态,则会将其加入黑名单,此后不再为它分配任务,直到再次转为健康状态。需要注意的是,节点被加入黑名单后,正在运行的Container仍会正常运行,不会被杀死。
第一种方式通过管理员自定义的Shell脚本。(NM上专门有一个周期性任务执行该脚本,一旦该脚本输出以"ERROR"开头的字符串,则认为结点处于不健康状态
第二种是判断磁盘好坏。(NM上专门有一个周期性任务检测磁盘的好坏,如果坏磁盘数据达到一定的比例,则认为结点处于不健康的状态)。 -
DeleteService
NM 将文件的删除功能服务化,即提供一个专门的文件删除服务异步删除失效文件,这样可以避免同步删除文件带来的性能开销。 -
Security
安全模块是NM中的一个重要模块,它由两部分组成,分别是ApplicationACLsManager 确保访问NM的用户是合法的,ContainerTokenSecretManger:确保用户请求的资源是被RM授权过的。 -
WebServer
通过Web界面向用户展示该节点上所有应用程序运行状态、Container列表、节点健康状况和Container产生的日志等信息。
15.2.6 ApplicationMaster的介绍
- ApplicationMaster基本介绍
ApplicationMaster实际上是特定计算框架的一个实例,每种计算框架都有自己独特的ApplicationMaster,负责与ResourceManager协商资源,并和NodeManager协同来执行和监控Container。 - ApplicationMaster职能
(1) 初始化向ResourceManager报告自己的活跃信息的进程
(2) 计算应用程序的的资源需求。
(3) 将需求转换为YARN调度器可以理解的ResourceRequest。
(4) 与调度器协商申请资源
(5) 与NodeManager协同合作使用分配的Container。
(6) 跟踪正在运行的Container状态,监控它的运行。
(7) 对Container或者节点失败的情况进行处理,在必要的情况下重新申请资源。 - 报告活跃
(1) 注册
ApplicationMaster执行的第一个操作就是向ResourceManager注册,注册时AM告诉RM它的IPC的地址和网页的URL。
IPC地址是面向客户端的服务地址;网页URL是AM的一个Web服务的地址,客户端可以通过Http获取应用程序的状态和信息。
注册后,RM返回AM可以使用的信息,包括:YARN接受的资源的大小范围、应用程序的ACL信息。
(2) 心跳
注册成功后,AM需要周期性地发送心跳到RM确认他还活着。参数yarn.am.liveness-monitor.expiry配置AM心跳最大周期,如果RM发现超过这个时间还没有收到AM的心跳,那么就判断AM已经死掉。 - 资源需求
AM所需要的资源分为静态资源和动态资源。
(1) 静态资源
在任务提交时就能确定,并且在AM运行时不再变化的资源是静态资源,比如MapReduce程序中的Map的数量。
(2) 动态资源
AM在运行时确定要请求数量的资源是动态资源 - 调度任务
当AM的资源请求数量达到一定数量或者到了心跳时,AM才会发送心跳到RM,请求资源,心跳是以 ResourceRequest形式发送的,包括的信息有:resourceAsks、ContainerID、containersToBeReleased。
RM响应的信息包括:新分配的Container列表、已经完成了的Container状态、集群可用的资源上限。 - 启动container
(1) AM从RM那里得到了Container后就可以启动Container了。
(2) AM首先构造ContainerLaunchContext对象,包括分配资源的大小、安全令牌、启动Container执行的命令、进程环境、必要的文件等
(3) AM与NM通讯,发送StartContainerRequest请求,逐一或者批量启动Container。
(4) NM通过StartContainerResponse回应请求,包括:成功启动的Container列表、失败的Container信信息等。
(5) 整个过程中,AM没有跟RM进行通信。
(6) AM也可以发送StopContainerRequest请求来停止Container。 - 完成container
当Container执行结束时,由RM通知AM Container的状态,AM解释Container状态并决定如何继续操作。所以YARN平台只是负责为计算框架提供Container信息。
15.3 yarn的安装
15.3.1 YARN的安装
- 进入到hadoop的配置文件中
cd /opt/apps/hadoop-3.1.1/etc/hadoop
vi core-site.xml
- 打开core-site.xml文件
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://doit01:8020value>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>rootvalue>
property>
configuration>
- 在当前目录下,打开yarn-site.xml
vi yarn-site.xml
- 将下面的配置信息插入到该文件中
<property>
<name>yarn.resourcemanager.hostnamename>
<value>doit01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>2value>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>2.1value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
- 配置MR程序在yarn上运行
在当前目录内,输入
vi mapred-site.xml
插入以下配置信息
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
- 在当前目录,将上面配置信息发送给另外两台节点:
scp core-site.xml doit02:$PWD
scp yarn-site.xml doit02:$PWD
scp mapred-site.xml doit02:$PWD
scp core-site.xml doit03:$PWD
scp yarn-site.xml doit03:$PWD
scp mapred-site.xml doit03:$PWD
- 在启动脚本中添加以下代码:
cd /opt/apps/hadoop-3.1.1/sbin/
vi start-yarn.sh # 添加下面的三行代码
vi stop-yarn.sh # 添加下面的三行代码
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
YARN的web监控页面:
http://hadoop001:8088
可以通过执行hadoop自带的jar包案例,来观察yarn的监控变化
# 使用hadoop自带的wordcount运行
hadoop jar /opt/apps/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /input /output
15.3.2 配置历史服务器
如果想查看历史记录,我们可以配置以下历史服务器:
# 进入配置文件目录
cd /opt/apps/hadoop-3.1.1/etc/hadoop/
# 配置历史服务器:
vi mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>doit01:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>doit01:19888</value>
</property>
分发给另外两台机器:
scp ./mapred-site.xml doit02:$PWD
scp ./mapred-site.xml doit03:$PWD
启动历史服务器:
# 最好先关闭集群,然后一块儿启动
mapred --daemon start historyserver
一键启停hdfs,yarn和历史服务:
#!/bin/bash
status=$1
if [ $status == start ]
then
ssh doit01 "source /etc/profile;start-all.sh;mapred --daemon start historyserver;exit"
fi
if [ $status == stop ]
then
ssh doit01 "source /etc/profile;stop-all.sh;mapred --daemon stop historyserver;exit"
fi
15.3.3 日志聚焦功能的配置:
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
配置yarn-site.xml:
cd /opt/apps/hadoop-3.1.1/etc/hadoop/
vim yarn-site.xml
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://doit03:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
分发文件:
scp ./yarn-site.xml doit02:$PWD
scp ./yarn-site.xml doit03:$PWD
关闭集群
stop-yarn.sh
mapred --daemon stop historyserver
重新开启集群
start-yarn.sh
mapred --daemon start historyserver
15.4 将程序运行在集群上
15.4.1 打包提交到yarn集群
1.打包:
在程序上添加一行代码:
job.setJarByClass(JoinDemo.class);
2.在pom.xml中添加依赖:
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
刷新maven
3.将代码中的输入路径和输出路径修改掉:
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
4.选择maven的package指令开始打包,选择占用空间小的包
jar包在项目的target目录下

5.将jar和数据通过FTP上传给linux虚拟机

6.将数据上传到hdfs上面
hdfs dfs -mkdir /join
hdfs dfs -put /order.txt /join
hdfs dfs -put /user.txt /join
7.在linux虚拟机中,开始执行命令
hadoop jar ./hdp_32-1.0-SNAPSHOT.jar com.doit.hdp_day04.JoinDemo /join /join_value
15.4.2 在idea上直接运行到yarn上
需要添加以下几行代码:
conf.set("mapreduce.framework.name", "yarn");
conf.set("fs.defaultFS", "hdfs://doit01:8020");
conf.setBoolean("mapreduce.app-submission.cross-platform", true);
//指定Yarn resourcemanager的位置
conf.set("yarn.resourcemanager.hostname","hadoop103");
System.setProperty("HADOOP_USER_NAME", "root");
// 创建需要提交的job的对象
Job job = Job.getInstance(conf, "Temperature");
job.setJar("D:\\doit_hp\\doit_edu37\\hdp_edu\\target\\hdp_edu-1.0-SNAPSHOT.jar");
job.setJarByClass(TemperatureDemo.class);
然后将四个默认配置文件加载到idea中即:

15.4 yarn的常用命令
#yarn application 查看任务
# 列出所有Application
yarn application -list
# Kill掉Application
yarn application -kill application_1612577921195_0001
#yarn logs 查看日志
# 查询Application日志:yarn logs -applicationId -containerId
yarn logs -applicationId application_1612577921195_0001 -containerId container_1612577921195_0001_01_000001
#yarn container 查看容器
#列出所有Container yarn container -list