makefile 实例讲解
1、makefile 是什么?
makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。
makefile的好处就是:
—“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具
2、makefile 引入
举个例子:
#include
void printHello(void){
printf("Hello World!\n");
}
#include
void printHello(void);
int main(){
printHello();
return 0;
}
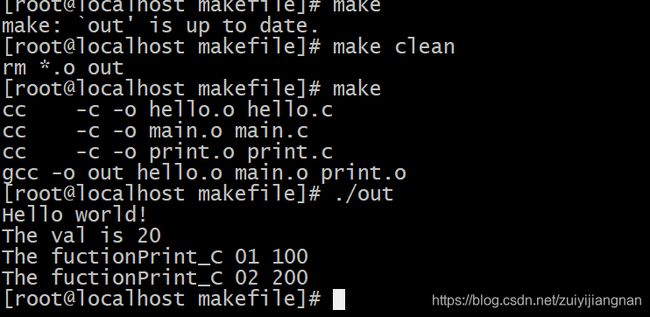
[root@5418eb82ba36 code]# g++ -o out hello.c main.c

注意:
编译了hello.c和main.c文件,使用一个命令,但需要经过四个过程
①预处理:预处理就是将要包含(include)的文件插入原文件中、将宏定义展开、根据条件编译命令选择要使用的代码,最后将这些东西输出到一个“.i”文件中等待进一步处理。
② 编译:编译就是把 C/C++代码(比如上述的“.i”文件)“翻译”成汇编代码
③汇编:汇编就是将第二步输出的汇编代码翻译成符合一定格式的机器代码,在 Linux 系统上一般表现为 ELF 目标文件(OBJ 文件)
④链接:连接就是将上步生成的 OBJ 文件和系统库的 OBJ 文件、库文件连接起来,最终生成了可以在特定平台运行的可执行文件。
注意:一般把前面三个步骤统称为编译。
生成步骤文件大致如下:
注意:g++ 编译器对于.c文件自动进行预处理
对于命令g++ -o out hello .c main.c ,修改了hello.c文件的内容,那么需要重新汇编生成xxx.o文件,虽然没有修改main.c文件,此时g++还是会默认再生成一次yyy.o文件,然后把xxx.o和yyy.o文件进行链接,这并不是我们想要的(我们想要的是如果y.o没有修改就不需要去重新生成一次了,直接使用旧的y.o文件),在文件很少的情况下几乎看不出有什么缺点,但是当文件很多的时候编译的时候就会花上很长的时间。这也是gcc的一个缺点。那如何改善呢?
解决方案:
1).对于每个c文件都分开编译(通常说的编译由三部分组成:预处理、编译、汇编,使用gcc命令:gcc -c -o x.o A.c和gcc -c -o y.o B.c),最后链接起来(使用命令:gcc -o out x.o y.o)
2).每次编译之前判断.c文件的内容是否比.o文件新,如果.c比.o新,或者.o文件不存在,那么就要重新进行编译和汇编的过程,生成相应的.o文件。
那么上述的例子可以用下面的三条语句进行编译:
g++ -c -o xxx.o hello.c
g++ -c -o yyy.o main.c
g++ -o out xxx.o yyy.o
解释:如果在第一次编译的时候,还没有生产xxx.o和yyy.o文件,所以会生成这两个文件,然后把这两个文件链接在一起生成out可执行程序,此时如果只修改了hello.c的话,那我们只需要去重新生成xxx.o文件即可,然后再和旧的yyy.o重新连接在一起生成新的out就可以,第二条语句没有必要执行。
那如何判断文件是否被修改呢?
通过判断文件的修改时间
1.当hello.c的修改时间比xxx.o的时间新的话或者xxx.o不存在,那么就需要执行gcc -c -o xxx.o hello.c 语句,生成 xxx.o文件,hello.c同理
2.当 xxx.o 或 yyy.o 比out文件新的话或out不存在,那么就需要执行g++ -o out xxx.o yyy.o 把xxx.o和yyy.o链接重新生成out文件
- 那我们需要在程序中去判断时间吗?
不需要的,因为这个步骤Makefile已经帮我们做好了,我们只需要遵循Makefile的语法即可
3.Makefile的基本规则
target:prerequisites
command
...
...
=====================
目标 : 依赖文件
[tab键] 命令
...
...
target:是目标文件,可以是object file,也可以是执行文件,还可以是一个标签label。
prerequisites:就是要生成那个target所需要的文件或者目标。
command:也就是make需要执行的命令-。
这是一个文件以来关系,也就是说target是由一个或多个目标文件依赖于prerequisites中的文件,其生成规则定义在command中,而且只要prerequisites中有一个以上的文件比target文件更新的话,command所定义的命令就会被执行,这是makefile的最基本规则,也是makefile中最核心的内容。
当 “依赖文件(prerequisites)” 比 “目标文件(target)” 新 =========>执行命令(command)
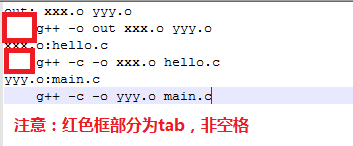
步骤一:
out: xxx.o yyy.o
g++ -o out xxx.o yyy.o
xxx.o:hello.c
g++ -c -o xxx.o hello.c
yyy.o:main.c
g++ -c -o yyy.o main.c

修改一下hello.c文件
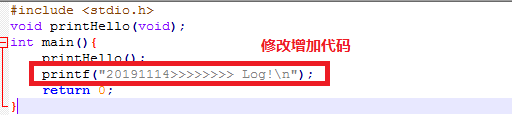
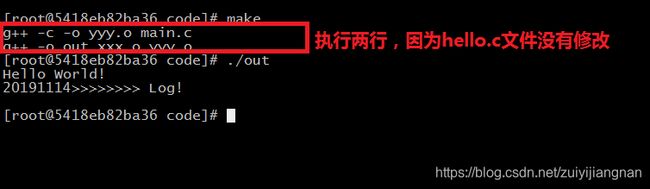
如果再次执行make
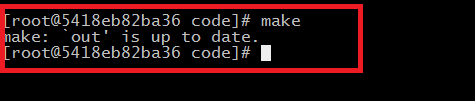
提示 out 这个目标文件已经是最新的了,检测到没有修改,所以不需要重新生成,这样就可大大提高我们工作的效率,智能检测我们的文件是否被修改,哪个文件需要重新生成。
5.Makefile简单语法
5.1.通配符
重新看一看上边所写的Makefile文件:
当文件很少的时候,可以这样写,但是当你需要编译的文件很大呢,一万个?你需要写一万个这样的语句吗吗?这个时候可以使用通配符。
- 通配符符号:%
①: $@ 表示目标文件
②: $< 表示第1个依赖文件
③: $^ 表示所有依赖文件
将上述的例子修改成使用通配符的方式:

执行make

5.2.假想目标
在上面例子的基础加上一个clean的目标文件,当调用make clean 的时候,清除所有.o文件和out文件

编译后的结果:

提示:通过上面的规律可以,make命令是可以带上目标名的,如果make后面不跟目标名字的话,默认生成第一个目标,当带上目标名的话,生成指定的目标
使用make clean可以正常执行,但如果在这个目标下有同名为clean的文件会咋样?
例子:
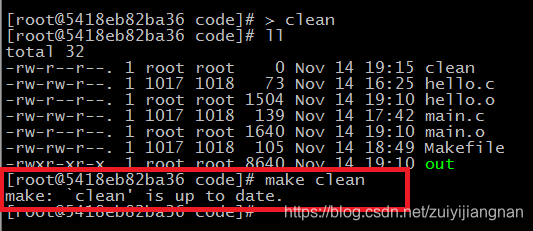
此时使用 make clean 命令,已经不会生成clean目标了
Why?
这就要看一下Makefile的核心规则:
1、当目标文件不存在
2、某个依赖文件比目标文件新
现在目标文件中有名为clean的文件,那么目标文件存在就取决于依赖,但Makefile中clean目标没有依赖,所以没有办法通过判断依赖的的时间去更新clean目标,所以clean目标文件一直都是目录中那么clean文件。所以当目录中有和clean同名文件时就没有办法执行clean操作了。
解决方法:把这个目标定义为假想目标
使用关键字定义假想目标: .phony
修改如下:
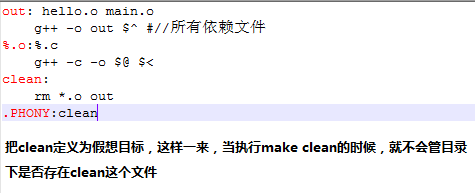
编译如下:

5.3.变量
变量的分类:
1.既时变量(简单变量):
例子:
赋值方式: A := xxx #A的值在定义就可以确定,即刻赋值
2.延时变量
例子:
赋值方式:A =xxx #A的值在使用到的时候才会确定
赋值方式:
:= 即时变量
= 延时变量
?= 延时变量,第一次定义才有效,如果这个变量在前面已经定义过,那么不执行这句赋值
+= 可以是即时变量也可以是延时变量,取决于这个变量的定义
建立一个Makefile文件,建立两个变量然后打印:
A:=aaa
B=123
all:
@echo $(A)
@echo $(B)
打印出A和B变量的值,其中@符号是不打印具体命令
编译:
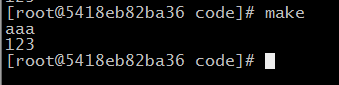
可以做如下修改,运行结果也是一样的,因为当你执行make的时候,是把整个Makefile文件读取进去分析的。
输出结果:

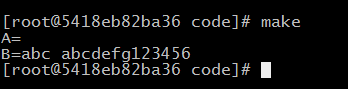
修改
编译:
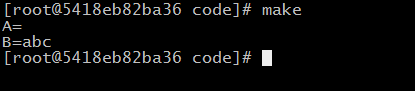
其实B的值就是等于C最终赋值的那个数值,再次修改一下:
A:=$(C)
B=$(C)
C =123
all:
@echo A=$(A)
@echo B=$(B)
C =abc
C =abcdefg123456
编译运行:

可以使用 +=进行附加的赋值,修改如下:
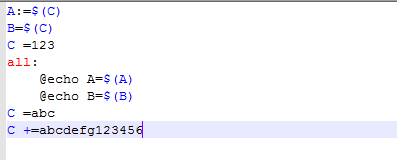
编译运行:
修改Makefile, 关于(?=)的使用:
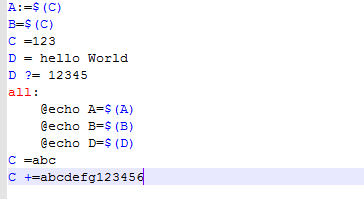
编译输出

6.Makefile 函数
6.1.foreach 函数
函数“foreach ”不同于其它函数。它是一个循环函数。类似于 Linux 的 shell 中的for 语句
语法:$(foreach VAR,LIST,TEXT)
函数功能: 这个函数的工作过程是这样的:如果需要(存在变量或者函数的引用),首先展开变量“ VAR”和“ LIST”的引用;而表达式“ TEXT”中的变量引用不展开。执行时把“ LIST”中使用空格分割的单词依次取出赋值给变量“VAR”,然后执行“ TEXT”表达式。重复直到“ LIST”的最后一个单词(为空时结束)。“TEXT ”中的变量或者函数引用在执行时才被展开,因此如果在“TEXT”中存在对“ VAR”的引用,那么“ VAR”的值在每一次展开式将会到的不同的值。
返回值: 空格分割的多次表达式“ TEXT ”的计算的结果。
A= a b c
B =$(foreach f,$(A),$(f).o)
all:
@echo B=$(B)

编译运行:

6.2.过滤函数 -filter
“filter”函数可以用来去除一个变量中的某些字符串, 我们下边的例子中就是用到了此函数。
1).找出符合PATTERN 格式的值
语法:$(filter PATTERN ⋯,TEXT)
函数功能:过滤掉字串“ TEXT”中所有不符合模式“ PATTERN ”的单词,保留所有符合此模式的单词。可以使用多个模式。模式中一般需要包含模式字符“%”。存在多个模式时,模式表达式之间使用空格分割。
返回值:空格分割的“ TEXT”字串中所有符合模式“ PATTERN ”的字串。
2).找出不符合PATTERN 格式的值
语法:$(filter-out PATTERN ⋯,TEXT)
函数功能:过滤掉字串“ TEXT”中所有符合模式“ PATTERN ”的单词,保留所有不符合此模式的单词。可以使用多个模式。模式中一般需要包含模式字符“%”。存在多个模式时,模式表达式之间使用空格分割。
返回值:空格分割的“ TEXT”字串中所有不符合模式“ PATTERN ”的字串。
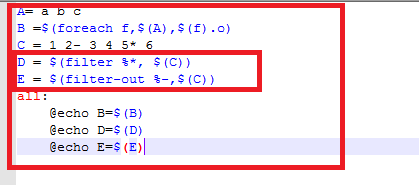
例子:
6.3.获取匹配模式文件名函数— wildcard
“PATTERN”使用 shell可识别的通配符,包括“ ?”(单字符)、“*”(多字符)等
语法:$(wildcard PATTERN)
函数功能:列出当前目录下所有符合模式“ PATTERN”格式的文件名。
返回值:空格分割的、存在当前目录下的所有符合模式“ PATTERN”的文件名。
例子:
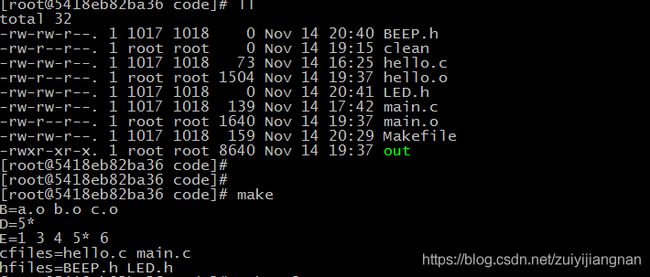
创建一个makefile添加几个c文件和h文件

编译输出结果:
该函数的功能是:以我们想要的文件格式寻找当前目录下存在的文件
例子2:
查找真实存在的文件,代码如下:
编译输出:

总结代码:
A= a b c
B =$(foreach f,$(A),$(f).o)
C = 1 2- 3 4 5* 6
D = $(filter %*, $(C))
E = $(filter-out %-,$(C))
cfiles = $(wildcard *.c)
hfiles = $(wildcard *.h)
file = hello.c main.c led.h Beep.h BEEP.h
file01 =$(wildcard $(file))
all:
@echo B=$(B)
@echo D=$(D)
@echo E=$(E)
@echo cfiles=$(cfiles)
@echo hfiles=$(hfiles)
@echo file =$(file01)
6.4.模式替换函数— patsubst
参数 “TEXT ”单词之间的多个空格在处理时被合并为一个空格,并忽略前导和结尾空格。
语法:$(patsubst PATTERN,REPLACEMENT,TEXT)
函数功能:搜索“ TEXT”中以空格分开的单词,将否符合模式“ TATTERN ”替换为“REPLACEMENT ”。参数“PATTERN”中可以使用模式通配符 “%”来代表一个单词中的若干字符。 如果参数“REPLACEMENT ”中也包含一个“%”,那么“ REPLACEMENT ”中的“ %”将是“ TATTERN”中的那个“ %”所代表的字符串。在“ TATTERN ”和“REPLACEMENT ”中,只有第一个“ %”被作为模式字符来处理,之后出现的不再作模式字符(作为一个字符)。在参数中如果需要将第一个出现的“ %”作为字符本身而不作为模式字符时,可使用反斜杠“ ”进行转义处理(转义处理的机制和使用静态模式的转义一致,
返回值:替换后的新字符串。
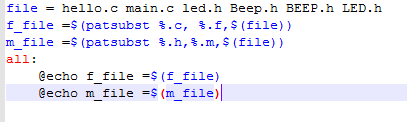
例子:
代码:
file = hello.c main.c led.h Beep.h BEEP.h LED.h
f_file =$(patsubst %.c, %.f,$(file))
m_file =$(patsubst %.h,%.m,$(file))
all:
@echo f_file =$(f_file)
@echo m_file =$(m_file)
编译输出:

7、Makefile综合例子
gcc 的参数
-M参数:
C/C++ 编译器都支持一个 “-M” 的选项,即自动找寻源文件中包含的头文件,并生成一个依赖关系。
-MF File
使用-MF 把这些依赖写入File文件汇总, 将覆写输出的依赖文件的名称
-MD
使用-MD参数,把一个文件的所有依赖写入指定文件,同时编译这个文件
采用5.2中的例子
1、添加一个hello.h文件
如下:
#define val 10
2、在hello.c中调用
#include
#include "hello.h"
void printHello(void){
printf("Hello World!\n");
printf("The val is %d\n",val);
}
运行结果:

看起来好像没有什么问题, 试着修改一下hello.h文件中val的值为20,试一下:
#define val 20
编译一下:

此时虽然改变了hello.h中的内容,但是系统检测不到,所以out的文件没有办法重新生成。当然此时可以make clean一下,然后再make就能重新生成新的out文件了,但是这不是最终的解决办法。
那么此时我们就需要去修改makefile文件了:其实没有办法生成新的out文件,是因为检测不到hello.o文件已经更新,而hello.o文件现在依赖于两个文件了,就是hello.c和hello.h可以看看在Makefile中,hell.o的依赖只有hello.c这个文件,所以可以在Makefile中加入这样一句:

编译输出:
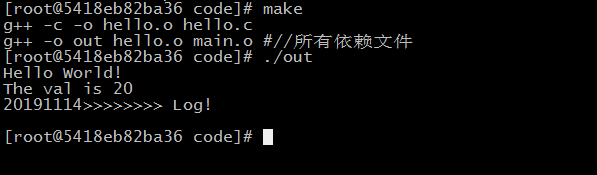
那么现在问题来了,我们此时hello.c的头文件依赖只有一个,而且还是我们清楚知道的。但是文件有成千上万个,而且依赖也有很多个,那此时怎么办,一个个查找是不可能的,而且漏掉一个可能导致编译出我们不想要的结果,怎么办?还有gcc 编译器有一个 -M 选项,可以去查找一个文件的所有依赖:
例如:查看hello.c文件的所有依赖
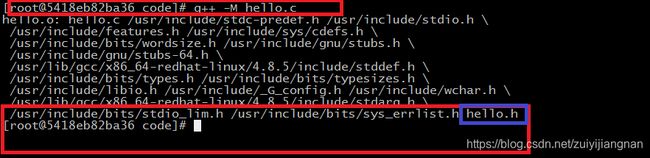
可以看出:hello.o依赖于 B.c 和一堆库函数文件,最后还有一个B.h既然我们可以通过一个命令检测到一个c文件所需要的依赖,那么我们就可以利用这个功能去简化Makefile,让Makefie变得灵活起来。
-MF File
功能:把依赖写入一个文件
当使用了 ‘-M’ 或者 ‘-MM’ 选项时,则把依赖关系写入名为 ‘File’ 的文件中。若同时也使用了 ‘-MD’ 或 ‘-MMD’,’-MF’ 将覆写输出的依赖文件的名称
例子:
把hello.c的所有依赖写入hello.d中
使用命令:gcc -M -MF hello.d hello.c
可以看到和使用命令: gcc -M hello.c的结果是一样的
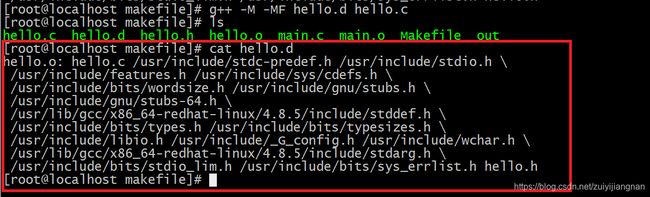
-MD
例子:
把一个.c的所有依赖写入文件,同时编译这个文件
使用命令:gcc -c -o hello.o hello.c -MD -MF hello.d
这样一来,这条命令就能把hello.c的依赖写入文件hello.d中,又能编译hello.c文件生成hello.o文件

可优化上面的代码
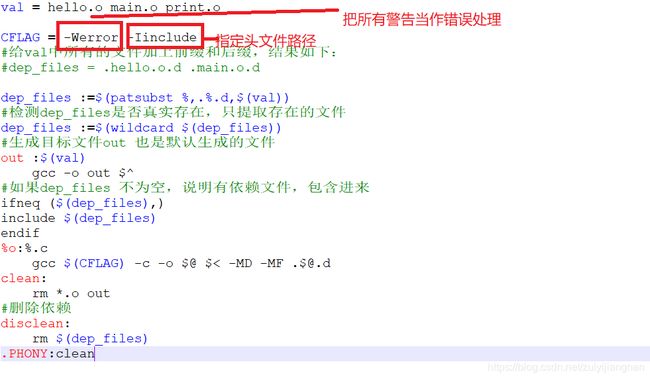
out: hello.o main.o
g++ -o out $^ #//所有依赖文件
hello.o:hello.c hello.h
%.o:%.c
g++ -c -o $@ $< -MD -MF [email protected]
clean:
rm *.o out
.PHONY:clean
代码
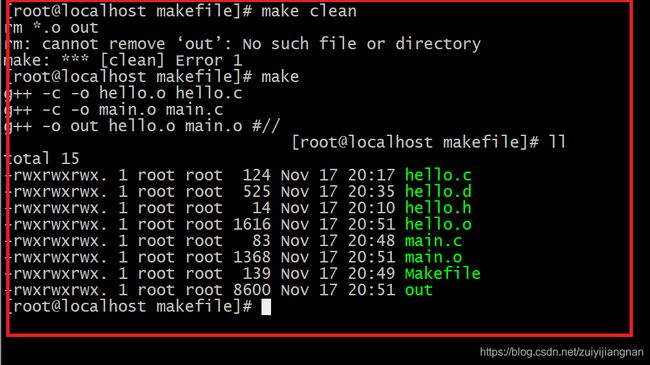
编译运行
既然我们可以把依赖文件写入一个文件,那我们可以把这些依赖文件给包含进来,这样就省去了下面这一句:
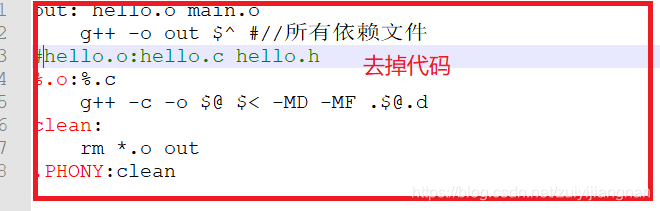
改成为:
此时我们就需要判断是否有.d 的文件,如果有才包含进入,如果没有则不包含:
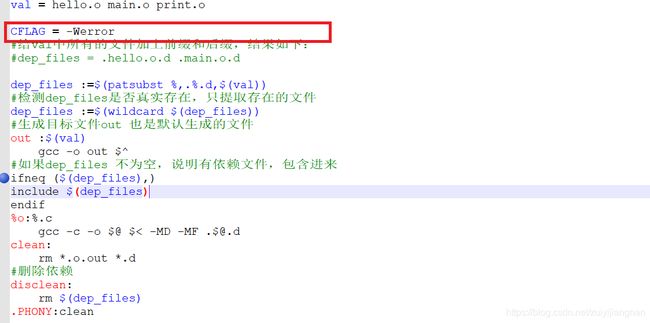
1).首先使用一个变量,将需要连接的文件放在一起:
val = hello.o main.o
2).那么他们相应的依赖文件就全部需要给他们就上后缀 .d,用到一个前面的函数:模式替换函数— patsubst,把val中所有的文件加上前缀(.)和后缀 (.d)
dep_files := $(patsubst %,.%.d,$(val))
3).使用 wildcard函数判断dep_files中文件是否真是存在
dep_files :=$(wildcard,$(dep_files ))
4).使用ifneq判断是否有依赖文件,如果变量dep_files 不等于空,说明有依赖文件,就使用include把依赖文件包含进入
ifneq($(dep_files ),)
#include $(dep_files)
endif
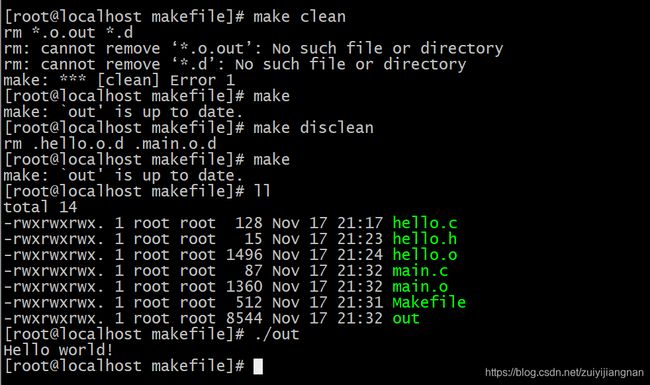
修改hello.h中val的值,然后再次make一下:


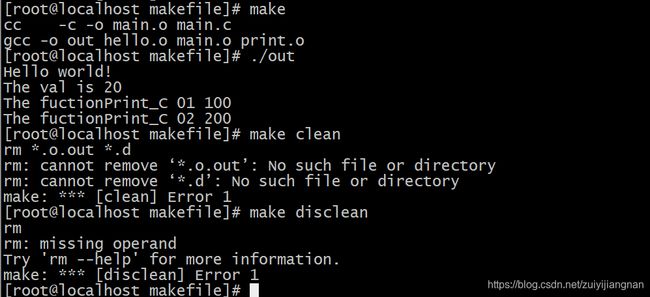
在上面的基础上,做个实验,增加一个print.c文件,然后增加beep.h和seed.h,接着让print.c调用beep.h和seed.h,最后主函数再调用print.c里边的函数:
CFLAG --编译参数
1).-Werror 选项,代表是把所有的警告都当作错误来处理。
2).-I 指定头文件搜索路径。我们一般都是创建一个include 文件夹,然后把头文件全部放进一个文件夹,然后再Makefile中指定默认头文件搜索路径。
提示:
#include < > 和 #include " " 的区别:
#include " " 表示在当前路径搜索头文件
#include < > 引用的是编译器的类库路径里面的头文件,一般是指定的路径
现在新建一个include文件夹,然后把所有的头文件放进去编译试一下:
 编译一下:
编译一下:
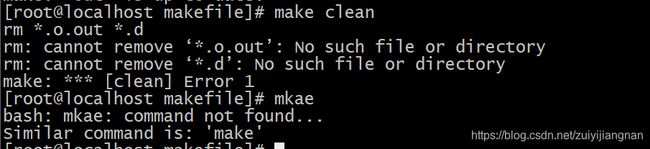
编译是找不到头文件,现在使用参数 I 指定gcc的头文件默认搜索路径:
运行结果: