浅谈数据库中间件Redis
摘要 Redis是基于内存存储介质,注重于读写效率的键值对(即key-value)数据库中间件。支持string、list、hash、set、sorted set等多种数据类型,补充了关系型数据库无法实现的功能。
1.软件作用
Redis以消息队列的形式存在,作为内嵌的List存在,满足实时的高并发需求。而通常在一个电商类型的数据处理过程之中,有关商品,热销,推荐排序的队列,通常存放在Redis之中,期间也包扩Storm对于Redis列表的读取和更新。其性能极高,Redis能支持超过 100K+ 每秒的读写频率。并且Redis具有丰富的数据类型,它支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作,方便且简单,易于掌握。
Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。Redis还具有丰富的特性,支持 publish/subscribe, 通知, key 过期等等特性。但百密一疏,所有的东西总有它的另一面,Redis的缺点就是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
2.软件体系结构
互联网数据目前基本使用两种方式来存储,关系数据库或者key value。但是这些互联网业务本身并不属于这两种数据类型,比如用户在社会化平台中的关系,它是一个list,如果要用关系数据库存储就需要转换成一种多行记录的形式,这种形式存在很多冗余数据,每一行需要存储一些重复信息。如果用key value存储则修改和删除比较麻烦,需要将全部数据读出再写入。Redis在内存中设计了各种数据类型,让业务能够高速原子的访问这些数据结构,并且不需要关心持久存储的问题,从架构上解决了前面两种存储需要走一些弯路的问题。Redis 新版本增加了VM特性。让Redis数据容量突破了物理内存的限制。并实现了数据冷热分离。Redis作为一个key value存在,很多开发者自然的使用set/get方式来使用Redis,实际上这并不是最优化的使用方法。尤其在未启用VM情况下,Redis全部数据需要放入内存,节约内存尤其重要。假如一个key-value单元需要最小占用512字节,即使只存一个字节也占了512字节。这时候就有一个设计模式,可以把key复用,几个key-value放入一个key中,value再作为一个set存入,这样同样512字节就会存放10-100倍的容量。
Redis有两种存储方式,默认是RDB方式,实现方法是定时将内存的快照(snapshot)持久化到硬盘,这种方法缺点是持久化之后如果出现crash则会丢失一段数据,因为RDB是在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。 优点:使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能 缺点:RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候。
3.软件原理
redis以内存作为数据存储介质,所以读写数据的效率极高,远远超过数据库。以设置和获取一个256字节字符串为例,它的读取速度可高达110000次/s,写速度高达81000次/s。不同于MySQL等关系型数据库,它是一个key-value存储系统。和Memcached类似,为了保证效率,数据都是缓存在内存中,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样相区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。并且Redis支持主从模式,可以配置集群,这样更利于支撑起大型的项目,这也是Redis的一大亮点。
4.开发应用
众多语言都支持Redis,因为Redis交换数据快,所以在服务器中常用来存储一些需要频繁调取的数据,这样可以大大节省系统直接读取磁盘来获得数据的I/O开销,更重要的是可以极大提升速度。
拿大型网站来举个例子,比如a网站首页一天有100万人访问,其中有一个板块为推荐新闻。要是直接从数据库查询,那么一天就要多消耗100万次数据库请求。上面已经说过,Redis支持丰富的数据类型,所以这完全可以用Redis来完成,将这种热点数据存到Redis(内存)中,要用的时候,直接从内存取,极大的提高了速度和节约了服务器的开销。
5.环境搭建及测试
(1)下载软件
Windows的Redis安装包需要到以下GitHub链接找到。链接:https://github.com/MSOpenTech/redis。打开网站后,找到Release,点击前往下载页面。在该页面中找到最新版本的软件安装包,其中以.msi为扩展名的文件是微软格式的安装包,以Windows为电脑系统的用户可以下载,直接双击即可。
(2)安装软件
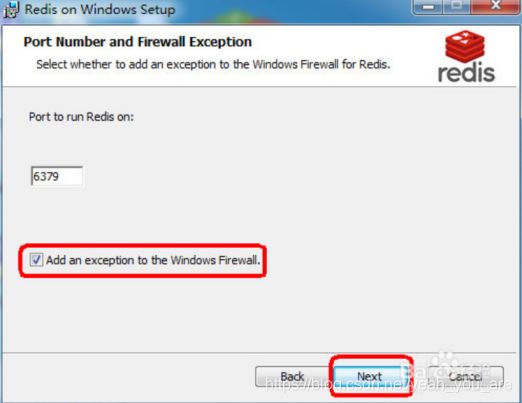
开始安装软件,点击next,一般都是点击同意安装协议,即I agree,这些都不用过多赘述。其中如下图所示,点击选择该项,这是添加Redis安装目录到PATH系统变量里面的,要仔细注意。另其中还有一步骤是设置Redis占用内存的最大值,一般学习实验100M足够,注意设置就好。
安装完成之后,找到redis.windows-service.conf配置文件,可以用记事本打开该文件,找到含有requirepass字符的位置,在下一行键入requirepass 12345,这是设置Redis的密码为12345,访问redis必须输入此密码。最后进入电脑命令行操作,找到Redis安装路径下,键入redis-cli进入Redis的客户端,在键入auth 12345(先前设置的密码),如图所示,即安装成功。

(3)代码测试
代码:
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import org.junit.Test;
import redis.clients.jedis.Jedis;
public class RedisConnect {
final static String host = "localhost";
final static int port = 6379;
final static String password = "12345";
private static Jedis jedis;
static {
jedis = new Jedis(host,port);
jedis.auth(password);
System.out.println("连接Redis数据库成功。。。");
System.out.println("服务正在运行:"+jedis.ping());
}
@Test
public void testString() {
jedis.set("name", "XXX");
System.out.println(jedis.get("name"));
//追加操作
jedis.append("name", "是我的名字");
System.out.println(jedis.get("name"));
//删除键
Long result = jedis.del("name2");
System.out.println(result);//返回long型, 1表示成功 0表示失败
//设置多个键值对
jedis.mset("age","23","address","安徽");
System.out.println(jedis.mget("name","age","address"));
System.out.println(jedis.get("age"));
}
@Test
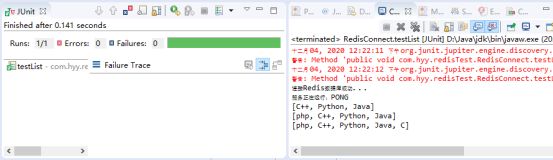
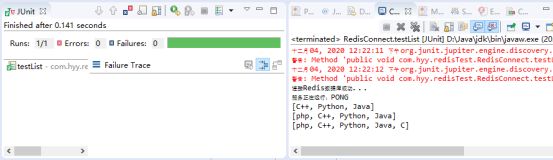
public void testList() {
//开始前,先移除所有的内容
jedis.del("Programming language");
//LPUSH key value1 [value2] 将一个或多个值插入到列表头部
jedis.lpush("Programming language", "Java");
jedis.lpush("Programming language", "Python");
jedis.lpush("Programming language", "C++");
//获取数据 返回一个list [Python, Java]
//第一个是key,第二个是起始位置,第三个是结束位置
//其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。
//你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
System.out.println( jedis.lrange("Programming language", 0, -1) );
//LPUSHX key value 将一个值插入到已存在的列表头部
jedis.lpushx("Programming language", "php");
System.out.println( jedis.lrange("Programming language", 0, -1) );
//RPUSH key value1 [value2] 在列表中添加一个或多个值
jedis.rpush("Programming language", "C");
System.out.println( jedis.lrange("Programming language", 0, -1) );
}
@Test
public void testSet() {
//向集合添加一个或多个成员
jedis.sadd("webSite", "阿里巴巴","网易");
jedis.sadd("webSite", "腾讯");
//SCARD key 获取集合的成员数
System.out.println( jedis.scard("webSite") );
//SMEMBERS key 返回集合中的所有成员 返回类型列表[阿里巴巴, 腾讯, 网易]注意顺序不唯一
System.out.println( jedis.smembers("webSite") );
//SSCAN key cursor [MATCH pattern] [COUNT count] 迭代集合中的元素
System.out.println(jedis.sscan("webSite", "0") );
}
@Test
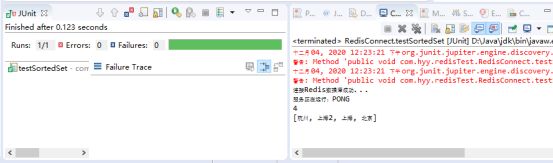
public void testSortedSet() {
jedis.zadd("city", 0, "北京");
jedis.zadd("city", 1, "上海");
jedis.zadd("city", 1, "上海2");
jedis.zadd("city", 2, "杭州");
//ZCARD key 获取有序集合的成员数
System.out.println( jedis.zcard("city") );
//ZREVRANK key member 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 java中的方法是zrevrangeByScore
//2指的是最大的分数
Set<String> a = jedis.zrevrangeByScore("city", 2, 0);
System.out.println( a );
}
@Test
public void testHash() {
Map<String, String> map = new HashMap<String, String>();
map.put("name", "某某");
map.put("age", "20");
//存数据
jedis.hmset("user", map);
//读取数据 返回一个列表类型
List<String> a = jedis.hmget("user", "name","age");
System.out.println(a);
System.out.println(jedis.hmget("user", "name","age") );
//hkeys key 获取所有哈希表中的字段 返回一个列表[name,age]
System.out.println(jedis.hkeys("user"));
//hvals key 获取哈希表中所有值
System.out.println(jedis.hvals("user"));
//hlen key 获取哈希表中字段的数量
System.out.println(jedis.hlen("user"));
//获取所有的键 迭代操作
Iterator<String> iter = jedis.hkeys("user").iterator();
while (iter.hasNext()) {
String key = iter.next();
System.out.println(key+"--"+jedis.hmget("user", key));
}
}
}
部分测试结果: