K8S知识点总结
一、K8S介绍:
Kubernetes(k8s)是Google开源的容器集群管理系统。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模 容器集群管理的便捷性。
1.K8S优势:
容器编排;轻量级;开源;弹性伸缩;负载均衡
2.重要概念:

Cluster: 是 计算、存储和网络资源的集合,k8s利用这些资源运行各种基于容器的应用.
Master: master是cluster的大脑,他的主要职责是调度,即决定将应用放在那里运行。master运行linux操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个master。
Node: 职责是运行容器应用。node由master管理,node负责监控并汇报容器的状态,同时根据master的要求管理容器的生命周期。node运行在linux的操作系统上,可以是物理机或者是虚拟机。
Pod: pod是k8s的最小工作单元。每个pod包含一个或者多个容器。pod中的容器会作为一个整体被master调度到一个node上运行。
Controller: k8s通常不会直接创建pod,而是通过controller来管理pod的。controller中定义了pod的部署特性,比如有几个剧本,在什么样的node上运行等。为了满足不同的业务场景,
k8s提供了多种controller,包括deployment、replicaset、daemonset、statefulset、job等。
Deployment: 是最常用的controller。deployment可以管理pod的多个副本,并确保pod按照期望的状态运行。
Replicaset: 实现了pod的多副本管理。使用deployment时会自动创建replicaset,也就是说deployment是通过replicaset来管理pod的多个副本的,我们通常不需要直接使用replicaset。
Daemonset: 用于每个node最多只运行一个pod副本的场景。正如其名称所示的,daemonset通常用于运行daemon。
Job: 用于运行结束就删除的应用,而其他controller中的pod通常是长期持续运行的。
Service: deployment可以部署多个副本,每个pod 都有自己的IP,外界如何访问这些副本那?答案是service。k8s的 service定义了外界访问一组特定pod的方式。service有自己的IP和端口,
service为pod提供了负载均衡。k8s运行容器pod与访问容器这两项任务分别由controller和service执行。
Namespace: 可以将一个物理的cluster逻辑上划分成多个虚拟cluster,每个cluster就是一个namespace。不同的namespace里的资源是完全隔离的。
二. k8s架构分析
k8s的集群由master和node组成,节点上运行着若干k8s服务
1.master节点:
master节点之上运行着的后台服务有kube-apiserver 、kube-scheduler、kube-controller-manager、etcd和pod网络。
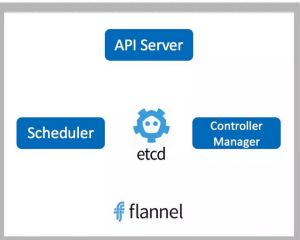
1.API Server: API Server是k8s的前端接口,各种客户端工具以及k8s其他组件,可以通过它管理集群的各种资源。
2.Scheduler: scheduer负责决定将pod放在哪个node上运行。另外scheduler在调度时会充分考虑集群的架构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。
3.Controller Manager: 负责管理集群的各种资源,保证资源处于预期的状态。
4.etcd: 负责保存k8s集群的配置信息和各种资源的状态信息,当数据发生变化时,etcd会快速的通知k8s相关组件。
5.pod网络:pod要能够相互通信,k8s集群必须掌握pod网络,fannel是其中一个可选的方案。
2.Node节点:
node是pod运行的地方。node上运行的k8s组件有kublet、kube-proxy和pod网络(例如flannel)
1.kubelet: 是node的agent,当scheduler去确定在某个node上运行pod后,会将pod的具体配置信息发送给该节点的kubelet,kubelet会根据遮羞信息创建和运行容器,并向master报告运行状态。
2.kube-proxy: 每个node都会运行kube-proxy服务,外界通过service访问pod,kube-proxy负责将降访问service的TCP/UDP数据流转发到后端的容器。如果有多个副本,kube-proxy会实现负载均衡。
3.pod网络:pod能能够互相通信,k8s集群必须部署pod网络,flannel是其中一个可以选择的方案
3.部署过程:
1.kubectl 发送部署请求到 API Server。
2.API Server 通知 Controller Manager 创建一个 deployment 资源。
3.Scheduler 执行调度任务,将两个副本 Pod 分发到 k8s-node1 和 k8s-node2。
4.k8s-node1 和 k8s-node2 上的 kubectl 在各自的节点上创建并运行 Pod。
三.deployment—yml文件
命令vs配置文件(yml文件)
1.命令方式简单直接快捷,上手快;适合临时测试或实验。
2.配置文件方式提供了创建的模板,可以重复部署;易于管理;适合正规,跨环境,规模化部署。
案例:启动nginx pod ,副本为3
1. 命令行方式: kubectl run nginx –image=nginx -r 3
2 .编写yml文件

执行yml 文件:kubectl apply -f nginx.yml
给node打标签
1.kubectl label node ken3 disk=ssd
2.将pod加入到标签节点上(在yml文件中修改)
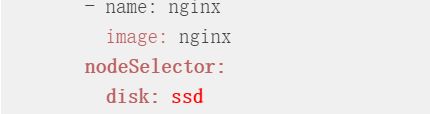
3.执行yml文件后查看pod,会发现运行在标签为disk=ssd的节点上。
四.Job
容器按照持续运行的时间可分为两类:服务类容器和工作类容器。服务类容器通常持续提供服务,需要一直运行,比如 http server,daemon 等。工作类容器则是一次性任务,比如批处理程序,完成后容器就退出。Kubernetes 的 Deployment、ReplicaSet 和 DaemonSet 都用于管理服务类容器;对于工作类容器,我们用 Job。
1.Job配置文件

restartPolicy 指定什么情况下需要重启容器。对于 Job,只能设置为 Never 或者 OnFailure。对于其他 controller(比如 Deployment)可以设置为 Always 。
如果Job失败会发生什么?
会自动生成很多pod。因为在job中期待完成数是1.但是因为job内部有错误,无法完成相应的任务,而且重启策略是Never,表示容器从来不会重启,所以系统为了完成工作,就会一直开启新的容器,试图去完成自己的工作。如果重启策略为OnFailure的话,只有一个pod,但pod会一直重启!
注意:
restartPolicy 表示pod重启策略
Always: 这个是默认值,pod退出就会自动重启
Never: 这个表示容器退出不会重启
OnFailure: 表示容器再失败退出的时候才会重启,容器正常退出不会重启
imagePullPolicy 表示镜像拉取的策略
Always: 这个是默认值,表示每次执行yml文件都会去拉取dockerhub中的镜像
Never: 总是不拉取镜像
IfNotPresent: 本地不存在才会去拉取镜像
五.cronjob
1.cj的yml文件

六.service
1.每个 Pod 都有自己的 IP 地址。当 controller 用新 Pod 替代发生故障的 Pod 时,新 Pod 会分配到新的 IP 地址。这样就产生了一个问题:
如果一组 Pod 对外提供服务(比如 HTTP),它们的 IP 很有可能发生变化,那么客户端如何找到并访问这个服务呢?Kubernetes 给出的解决方案是 Service。
Kubernetes Service 从逻辑上代表了一组 Pod,具体是哪些 Pod 则是由 label 来挑选。Service 有自己 IP,而且这个 IP 是不变的。客户端只需要访问 Service 的 IP,Kubernetes 则负责建立和维护 Service 与 Pod 的映射关系。无论后端 Pod 如何变化,对客户端不会有任何影响,因为 Service 没有变。
2.创建service:
先创建deployment文件(如上)
再创建service文件:
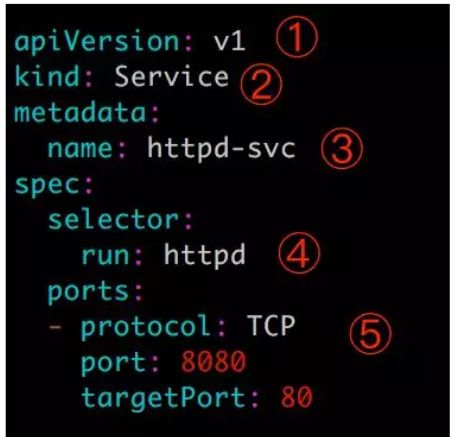
selector 指明挑选那些 label 为 run: httpd 的 Pod 作为 Service 的后端。
将 Service 的 8080 端口映射到 Pod 的 80 端口,使用 TCP 协议。(tcp协议可省略,默认的)
七.DNS访问
此时我们通过另一个容器来访问刚才的pod
1.启动容器busybox
2.通过名称访问service中运行的pod(进入到容器busybox中)
Wget httpd-svc:80
发现可以访问。但要注意,通过名称访问,只能在同一名称空间。如果不是在同一名称空间,需要指定namespace. 执行如下:
1.修改yml文件:

2.同样启动容器busybox,并指定名称空间进行访问
Wget httpd2-svc.kube-public:80
3.或者在启动容器busybox时就指定名称空间
Kubectl run -it –image=busybox -n kube-public /bin/sh
八.外网如何访问pod?(这里主要讲通过端口形式)
1.编写service的文件

在原有文件添加type:NodePort,表示暴露一个随机端口出来。外部访问只需加上这个端口就可以访问。
2.固定宿主机端口
(1).编写service的yml文件(加上固定端口号即可)

几个端口表示的含义
port:表示svc的端口
targetPort: pod的端口
nodePort: 需要映射到宿主机的端口
九.数据管理(volume)
1.emptyDir
emptyDir 是最基础的 Volume 类型。一个 emptyDir Volume 是 Host 上的一个空目录。emptyDir Volume 对于容器来说是持久的,对于 Pod 则不是。当 Pod 从节点删除时,Volume 的内容也会被删除。但如果只是容器被销毁而 Pod 还在,则 Volume 不受影响。emptyDir Volume 的生命周期与 Pod 一致。
实践emptyDir(相当于docker中Docker Management Volume)

emptyDir 是 Host 上创建的临时目录,其优点是能够方便地为 Pod 中的容器提供共享存储,不需要额外的配置。但它不具备持久性,如果 Pod 不存在了,emptyDir 也就没有了。
2.hostpath
hostPath Volume 的作用是将 Docker Host 文件系统中已经存在的目录 mount 给 Pod 的容器。大部分应用都不会使用 hostPath Volume,因为这实际上增加了 Pod 与节点的耦合,限制了 Pod 的使用。不过那些需要访问 Kubernetes 或 Docker 内部数据(配置文件和二进制库)的应用则需要使用 hostPath。
实践hostPath(效果相当于执行: docker run -v /tmp:/usr/share/nginx/html
编写yml文件

3.NFS
1.环境准备:控制节点部署好NFS,节点需要下载nfs-utils支持nfs文件类型
2.编写yml文件

4.pv&pvc
PersistenVolume(pv)是外部存储系统中的一块存储空间,由管理员创建和维护。与volume一样,pv具有持久性,生命周期独立于Pod。
PersistentVolumeClaim(pvc)是对pv的申请。Pvc通常由普通用户创建和维护。需要为pod分配存储资源时,用户可以创建一个pvc,指明存储资源的容量大小和访问模式等信息,K8s会查找并提供满足条件的pv.
有了PersistentVolumeClaim,用户只需要告诉k8s需要什么样的存储资源,而不必关心真正的空间从哪里分配,如何访问等底层细节信息。这些Storage Provider的底层信息交给管理员来处理。

实践PV/PVC
1.部署NFS
2.编写pv的yml文件
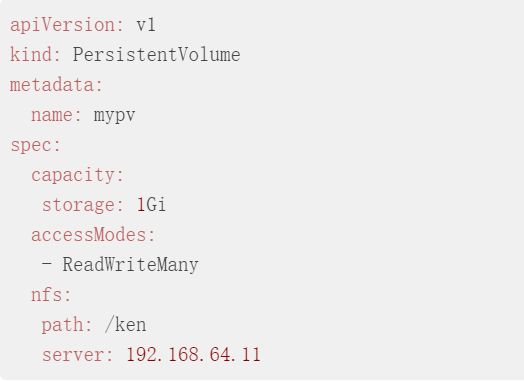
3.执行yml文件并查看pv
注意:
accessModes有三类
ReadWriteOnce – 可以被单个节点进行读写挂载
ReadOnlyMany – 可以被多个节点进行只读挂载
ReadWriteMany – 可以被多个节点进行读写挂载
4.创建pvc
编写pvc的yml文件
执行yml文件并查看pvc
5.使用pvc
编写部署nginx的yml文件

执行yml文件并进行测试
5.如何释放pv
1.先停掉pod
2.删除pvc
3.删除pv
十.应用机密信息与配置管理
Secret
应用启动过程中可能需要一些敏感信息,比如访问数据库的用户名密码或者秘钥。将这些信息直接保存在容器镜像中显然不妥,Kubernetes 提供的解决方案是 Secret。
Secret 会以密文的方式存储数据,避免了直接在配置文件中保存敏感信息。Secret 会以 Volume 的形式被 mount 到 Pod,容器可通过文件的方式使用 Secret 中的敏感数据;此外,容器也可以环境变量的方式使用这些数据。
实践Secret
1.创建Secret
加密用户及密码: echo ‘123’ | base64
编写secret的yml文件

执行yml文件并查看,获取加密密码
2.使用secret
两种方式:1.以volume形式挂载在pod上;2.以环境变量形式使用
以volume的形式挂载到pod
1.创建pod并编写yml文件

执行yml文件并进入到pod 查看secret
Volume形式可以动态更新密码
以环境变量方式使用secret
1.编写yml文件

执行文件并进入到Pod验证