软考第三章----数据库系统
目录
一、数据库模式
1.三级模式-两级映射(选择题出现)
2.数据库的设计过程
二、ER模型
1.ER图
2.局部ER图集成
3.练习题1
三、关系代数与元组演算
1.关系代数(综合体中的选择题)
四、规范化理论
1.函数依赖
2.价值与用途
3.键
(1)键的分类
(2)求候选键
(3)练习题:
4.范式
(1)范式概念
(2)第一范式
(3)第二范式
(4)第三范式
(5)BCNF范式
(6)练习题
5.模式分解
(1)概念
(2)例题
五、并发控制
1.基本概念
2.并发控制存在的问题示例
3.封锁协议-解决并发问题
六、数据库完整性约束
七、数据库安全
八、数据库备份与恢复
1.数据备份
2.数据库故障与恢复
九、数据仓库与数据挖掘
1.基本概念
2.数据库挖掘方法分类
九、反规范化
十、大数据
十一、分布式数据库
该章内容在上午题和下午题中都有出现
重点:规范化理论(必考)、(必考)
一、数据库模式
1.三级模式-两级映射(选择题出现)

三级模式:
物理数据库在计算机中是一个文件
内模式(又称物理数据库模式),是和物理层次数据库直接关联的,负责管理存储数据的方式,即数据应以什么格式存放在物理文件上面,以及如何优化这些存储方式;该模式的关注点在于数据如何存放上面
概念模式,是数据库表这个级别,在该模式中,根据业务以及应用,数据被分成了若干张“表”,表之间会有相应的关联。
外模式,是数据库中的视图,对数据处理更积极灵活
两级映射:
外模式-概念模式映射指的是视图与表之间的映射,当表发生变化时只需要改映射而不需要改程序
概念模式-内模式映射是内部存储结构与表的映射关系,存储结构发生改变只需调整映射关系,不需修改用户应用程序。
2.数据库的设计过程

需求分析:处理整个系统对数据的要求,有从用户类别收集起来的需求,同时有转换过程中的关联需求 。
概念结构设计:做ER模型,与数据库管理系统无关的模型,与物理数据库无直接关系,将ER模型转成关系模式。转化过程中会有转换规则和规范化理论(必考)。
DBMS(数据库管理系统)与关系模式结合起来形成物理层次的设计。
数据流图,数据字典以及需求说明书都是需求分析阶段的产物,ER模型则为概念结构设计层次的产物,关系模式即为逻辑结构设计层次的产物
二、ER模型
1.ER图

2.局部ER图集成

3.练习题1

1.一个实体型转换为一个关系模式
1:1联系:即一一对应的关系中,一个实体型转换为一个关系模式,再把这种联系放在任意一个其他实体中,因此在此种转换中需要两个实体的参与。
1:n联系:即一对多的关系中,如部门实体与和员工实体之间;仍然是一个实体型转换为一个关系模型,但这种联系只能记录在多这边,如员工。
m:n联系,即多对多的关系中,此种关系至少需要三个实体参与。
2.答案:C
首先三个实体转化为三个关系模式,一个多对多最少转化成一个关系模式,一共是四个关系模式。
三、关系代数与元组演算
1.关系代数(综合体中的选择题)
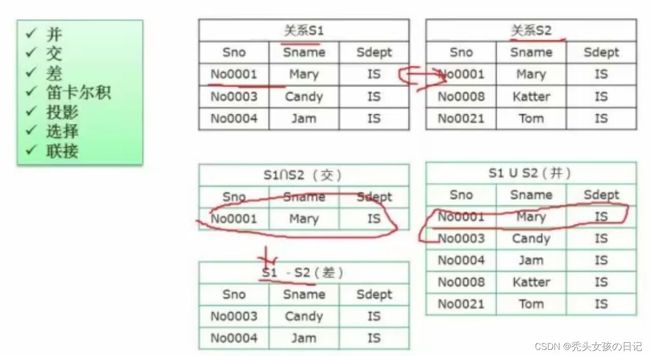
并:两个关系都会累加显示出来,重复部分只显示一个。
交:两个关系中相等的数据显示出来。
差:S1-S2(差)表示的是S1有的但是S2没有的数据。

笛卡尔积:S1的每一项与S2的所有项相结合。
投影:图中把S1的Sno,Sname项投影出来。该操作即将所选的“列”记录下来。
选择:图中选择字段Sno=No0003的数据。 该操作将所选的“行”记录下来。
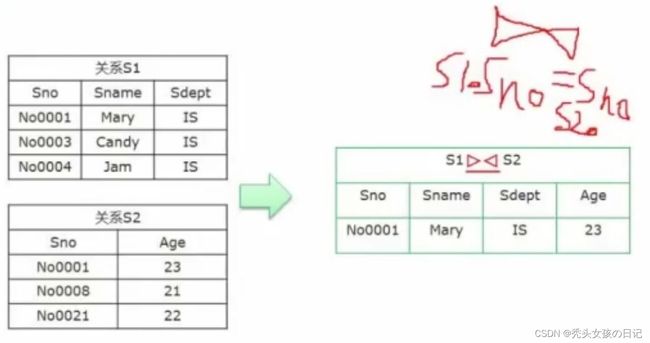
自然连接的结果以左侧关系为主,右侧关系去除重复列,如R(A,B,C,D,E)和E(C,D,E,F)进行自然连接的结果为:(A,B,R.C,R.D,R.E,F)
等值连接:S1.Sno=S2.Sno是S1和S2在Sno相等的情况下的连接。
四、规范化理论
1.函数依赖
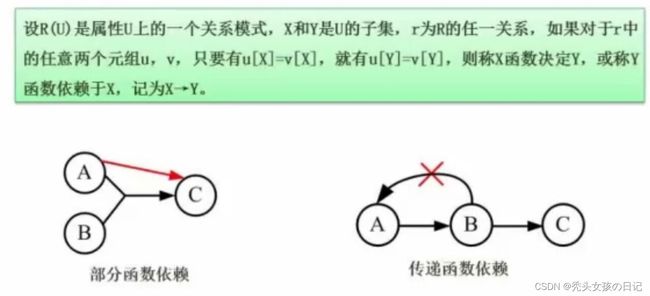
即函数关系,如学号对应姓名,姓名可以重复,但学号是唯一的,且唯一的学号对应相应了可重复的姓名
部分函数依赖(部分依赖):主键是两个属性的组合键,若主键中的一部分可以确定某个属性,则为部分函数依赖
传递函数依赖(传递依赖):即:若A可以确定B,B可以确定C,则A可以确定C(注意:B不能确定A,因为此时二者即为等价)。
2.价值与用途
在非规范化的关系模式中,可能存在的问题包括:数据冗余,更新异常,插入异常,删除异常。
价值包括:解决数据冗余,如在记录大学生所属系别时,记录为计算机系就比计算机科学系更为简便,在大量数据的处理中,这一点的改进极为重要。
3.键
(1)键的分类

超键是可以唯一标识元组的,可以冗余,但是候选键要消除多余的属性,不能有冗余现象,候选键可以有多个,但是主键只能有一个。
外键是表与表之间的关联。
例如(学号,姓名)可以确定性别,学号单独也可以确定性别,所以姓名属于冗余信息,于是(学号,姓名)是超键,但不是候选键。
(2)求候选键

(3)练习题:

答案:例1:A 例2: ABCD 例3:B
例1:从A1出发可以遍历所有结点。 其他两题类似。
4.范式
(1)范式概念

范式符号为NF;范式分为一级范式。二级范式,三级范式.......;随着范式等级的提高,规范程度就会越高,数据表的拆分也将越来越细,而数据表拆分过细会造成性能方面的问题,因此,我们通常对范式的等级采取折中的方式,即做到三级范式
主属性是候选键中的属性,非主属性是候选键之外的属性。
(2)第一范式

去掉高级职称人数
(3)第二范式
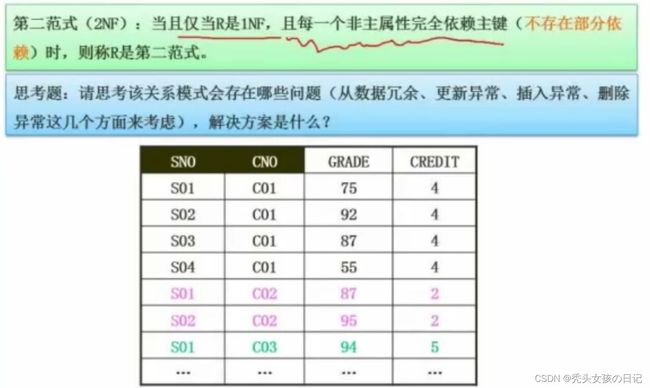
SNO和CNO可以确定GRADE,但是仅仅CNO就可以确定CREDIT,存在非主属性存在部分函数依赖。
主键是单属性一定是第二范式。
存在数据冗余,更新异常,插入异常,删除异常
解决方法:拆分。把CNO和CREDIT另外做个表。
(4)第三范式
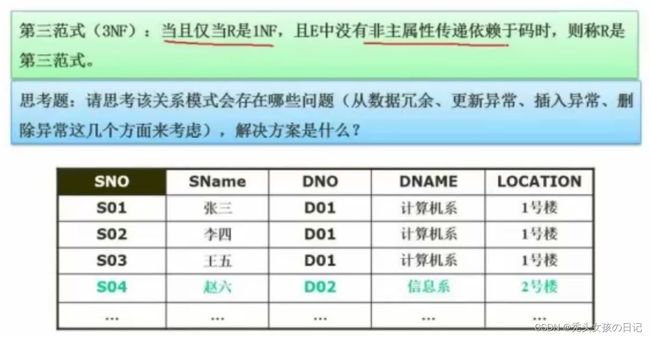
具有数据冗余,更新异常,插入异常,删除异常。
必须达到第二范式才能达到第三范式。
解决方案:将DNO、DNAME、LOCATION做成一个新表。
(5)BCNF范式

候选键:SJ、ST
S、T、J都是主属性,已经属于第三范式。
SJ->T(SJ是候选键),T->J(T不是候选键,所以不是BC范式)。
(6)练习题

答案:(1)C (2)D (3)A
(1)表一只有部门号是主键,属于第二范式,A、B、D排除
(2)建立部门和职工之间的关系,职工和部门是多对一的关系,应该在多的一方增加外键
(3)部门号和职工号建立了关联,不需要部门号,商品名称属于冗余信息
5.模式分解
(1)概念

范式级别不够时,采取把模式进行拆分,拆分后级别就会上升。
保持函数依赖的分解表示分解前有什么函数依赖,分解后依旧是那些函数依赖。
保持函数依赖分解的简单例子:若R(A,B,C)有函数依赖A->B,B->c,则R(A,B,C)可以分解成R1(A,B),R2(B,C)。
冗余性质的函数依赖可以不用保持。
有损:图像压缩等,无损:文件压缩等
(2)例题
①例一

②例二:列表法

第一行:原关系模式中的字段,第一列是拆分后的子关系模式;
a1代表的意思:在第一行第一列,字段名为学号,在成绩这个子关系模块中;
b12代表的意思是在第一行第二列,字段名为姓名,成绩子关系模式中没有这个字段,所以用b表示;
以此类推完成初始表。
之后要根据函数关系修改表:
①学号->姓名这个函数依赖是a1->a2,在第二行学生表中,此时第一行成绩表中可以把b12修改成a2(因为b12也是由a1决定),表示成绩表与学生表建立联系;
②以此类推,第三行课程号->课程名这个函数依赖是a3->a4,第一行的成绩关系模式中a3->b14也是由a3决定的,把b13修改成a4,表示课程表和成绩表建立联系;
③若其中有子关系模块全为a,则判断此次分解为无损联接分解。

③例三(此方法只适用一分为二的关系模式)

R1-R2的意思是把R1当中与R2相同的元素去掉
R1∩R2->(R1-R2)和R1∩R2->(R2-R2)当中只有一个满足条件就行。
五、并发控制
1.基本概念

事务是多个操作封装起来,多个操作都有关联性,例如转账事务有转出操作和转入操作,二者要么并发,要么都不发生,以保持一样的状态。
原子性:事务中的操作要么做要么不做,把事务看成一个原子值,不能拆分;
一致性:数据在事务执行前后是一致的。比如转账事务执行前后金钱数目不变;
隔离性:多个事务之间无联系,无不干扰;
持续性:事务执行之后的结果、影响都是持续的。
2.并发控制存在的问题示例

ROLLBACK:回滚
3.封锁协议-解决并发问题

X锁是写锁,S锁是读锁,事务加了X锁就不能加S锁(任何锁都不行),但是事务加了S锁还可以继续加X锁 ;
一级封锁协议:写数据前加X锁,事务结束后释放;
二级封锁协议:读数据前加S锁,读完释放,再在写数据前加X锁,事务结束后释放;
三级封锁协议:读数据前加S锁,再在写数据前加X锁(现在有双重锁),事务结束后释放两锁。
两段锁协议:可串行化
死锁有预防的方法,也可以在产生死锁的时候进行甄别、解决。
六、数据库完整性约束

实体完整性约束:给数据表定义主键,主键值不能为空不能重复;
参照完整性约束:外键的完整性约束,要求填入的数据必须是对应表的主键,外键允许为空;
用户自定义完整性:用户可以设置字段类型,比如年龄只能是数字,不能是200等等。
完整性约束目的是检查数据的正确性;
触发器可以写脚本来约束数据库中对数据的要求。
七、数据库安全

八、数据库备份与恢复
1.数据备份


差量备份是根据上一次完全备份之后变化的数据 ;
增量备份是根据上一次的备份,不管什么类型的备份都可以;
增量备份速度快,分量少,恢复很麻烦,要按时间把每次增量备份都恢复一次;
差量备份被破坏时,只需要恢复上次的完全备份,再恢复此次的差量备份;
备份被破坏的时候数据可能恢复不完整,比如下一次备份还未进行,数据库就被破坏了,此时日志文件就起作用了。
日志文件比备份文件在恢复时先起作用。
2.数据库故障与恢复
 九、数据仓库与数据挖掘
九、数据仓库与数据挖掘
1.基本概念
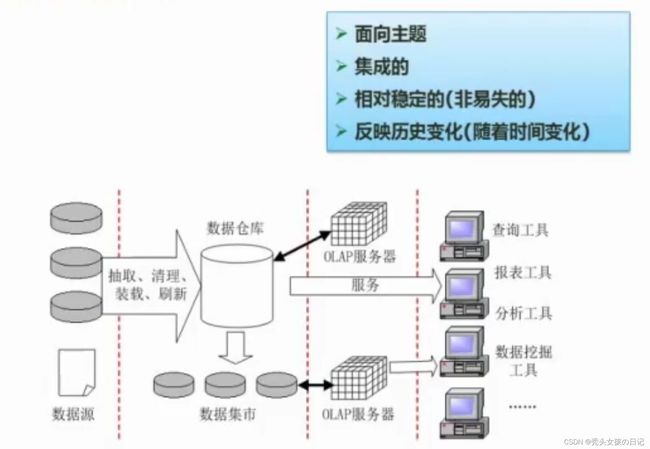
应用于BI(商业智能)
数据仓库与数据库的区别:
①数据库是用于数据存储的需求,系统中积累的数据越多,性能逐渐下降。优化的主流做法是删除历史数据。历史数据可有可用性,可以单独弄个地方存储起来,这种数据一般都不用修改,只用于查询分析统计,不需要数据库的增删改,所以把这些历史数据放入数据仓库中。
②数据仓库中的数据都是有主题的,比如按业务来分等等;
③数据仓库会记录一些集成之后的数据,比如日报表、月报表,而数据库不会;
④数据仓库具有稳定性,因为它不需要像数据库一样做一些频繁的增删改查;
⑤数据仓库需要抽取(不同数据源的诗句抽取)、清理(数据格式不一致)、装载(装入数据仓库)、刷新;
数据集市是部门级的数,降低风险率;
OPAL服务器是联机分析处理器,最表层是数据前端工具,如查询工具,报表工具,数据挖掘工具,分析工具;
数据挖掘工具与查询工具的不同之处:查询工具是有目的的搜索数据,而数据挖掘是无目的的搜索数据并在其基础上挖掘出一些未知的信息特性,并应用在商业领域。比如商品的季节性,顾客的偏好等等;
2.数据库挖掘方法分类

九、反规范化

反规范化的技术:(1)增加派生性冗余:增加冗余
(2)增加冗余列
(3)重新组表
(4)分割表:包括垂直分割和水平分割
十、大数据

对海量数据处理的相关技术,量变引起质变,与云计算、虚拟化结合起来。

十一、分布式数据库
透明
1.分片透明:是指用户不必知道数据是如何分片的,它们对数据的操作在全局关系上进行,即关系如何分片对用户是透明的,因此,当分片改变时,应用程序可以不变。分片透明性是最高层次的透明性,如果用户能在全局关系一级操作,则数据如何分布,如何存储等细节不必关心,其应用程序的编写与集中式数据库相同
2.复制透明:用户不用关心数据库在网络中各个结点的复制情况,被复制的数据的更新都由系统自动完成。在分布式数据库系统中,可以把一个场地的数据复制到其他场地存放,应用程序可以使用复制到本地的数据在本地完成分布式操作,避免通过网络传输数据,提高了系统的运行和查询效率,但是对于复制数据的更新操作,就要涉及到对所有复制数据的更新
3.位置透明:是指用户不必知道所操作的数据放在何处,即数据分配到哪个或哪些站点存储对用户是透明的
4.逻辑透明:是最低层次的透明性,该透明性提供数据到局部数据库的映像,即用户不必关心局部DBMS支持哪种数据模型、使用哪种数据操纵语言,数据模型和操纵语言的转换是由系统完成的。因此,逻辑透明对异构型和同构异构的分布式数据库是非常重要的