import java.io 是什么意思_Java IO 详解
Java IO 详解
初学java,一直搞不懂java里面的io关系,在网上找了很多大多都是给个结构图草草描述也看的不是很懂。而且没有结合到java7 的最新技术,所以自己来整理一下,有错的话请指正,也希望大家提出宝贵意见。
首先看个图:(如果你也是初学者,我相信你看了真个人都不好了,想想java设计者真是煞费苦心啊!)
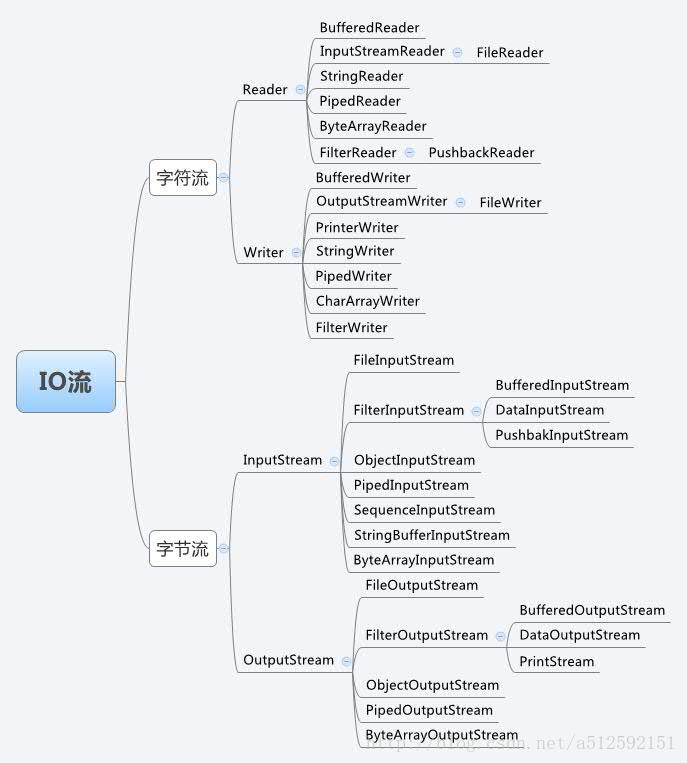
这是java io 比较基本的一些处理流,除此之外我们还会提到一些比较深入的基于io的处理类,比如console类,SteamTokenzier,Externalizable接口,Serializable接口等等一些高级用法极其原理。
一、java io的开始:文件
1. 我们主要讲的是流,流的本质也是对文件的处理,我们循序渐进一步一步从文件将到流去。
2. java 处理文件的类 File,java提供了十分详细的文件处理方法,举了其中几个例子,其余的可以去
Java代码 ![]()
package com.hxw.io;
import java.io.*;
public class FileExample{
public static void main(String[] args) {
createFile();
}
/**
* 文件处理示例
*/
public static void createFile() {
File f=new File("E:/电脑桌面/jar/files/create.txt");
try{
f.createNewFile(); //当且仅当不存在具有此抽象路径名指定名称的文件时,不可分地创建一个新的空文件。
System.out.println("该分区大小"+f.getTotalSpace()/(1024*1024*1024)+"G"); //返回由此抽象路径名表示的文件或目录的名称。
f.mkdirs(); //创建此抽象路径名指定的目录,包括所有必需但不存在的父目录。
// f.delete(); // 删除此抽象路径名表示的文件或目录
System.out.println("文件名 "+f.getName()); // 返回由此抽象路径名表示的文件或目录的名称。
System.out.println("文件父目录字符串 "+f.getParent());// 返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。
}catch (Exception e) {
e.printStackTrace();
}
}
}
二、字节流:
1.字节流有输入和输出流,我们首先看输入流InputStream,我们首先解析一个例子(FileInputStream)。
Java代码 ![]()
package com.hxw.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class FileCount {
/**
* 我们写一个检测文件长度的小程序,别看这个程序挺长的,你忽略try catch块后发现也就那么几行而已。
*/
publicstatic void main(String[] args) {
//TODO 自动生成的方法存根
int count=0; //统计文件字节长度
InputStreamstreamReader = null; //文件输入流
try{
streamReader=newFileInputStream(new File("D:/David/Java/java 高级进阶/files/tiger.jpg"));
/*1.new File()里面的文件地址也可以写成D:\\David\\Java\\java 高级进阶\\files\\tiger.jpg,前一个\是用来对后一个
* 进行转换的,FileInputStream是有缓冲区的,所以用完之后必须关闭,否则可能导致内存占满,数据丢失。
*/
while(streamReader.read()!=-1) { //读取文件字节,并递增指针到下一个字节
count++;
}
System.out.println("---长度是: "+count+" 字节");
}catch (final IOException e) {
//TODO 自动生成的 catch 块
e.printStackTrace();
}finally{
try{
streamReader.close();
}catch (IOException e) {
//TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
}
我们一步一步来,首先,上面的程序存在问题是,每读取一个自己我都要去用到FileInputStream,我输出的结果是“---长度是: 64982 字节”,那么进行了64982次操作!可能想象如果文件十分庞大,这样的操作肯定会出大问题,所以引出了缓冲区的概念。可以将streamReader.read()改成streamReader.read(byte[]b)此方法读取的字节数目等于字节数组的长度,读取的数据被存储在字节数组中,返回读取的字节数,InputStream还有其他方法mark,reset,markSupported方法,例如:
markSupported 判断该输入流能支持mark 和 reset 方法。
mark用于标记当前位置;在读取一定数量的数据(小于readlimit的数据)后使用reset可以回到mark标记的位置。
FileInputStream不支持mark/reset操作;BufferedInputStream支持此操作;
mark(readlimit)的含义是在当前位置作一个标记,制定可以重新读取的最大字节数,也就是说你如果标记后读取的字节数大于readlimit,你就再也回不到回来的位置了。
通常InputStream的read()返回-1后,说明到达文件尾,不能再读取。除非使用了mark/reset。
2.FileOutputStream 循序渐进版, InputStream是所有字节输出流的父类,子类有ByteArrayOutputStream,FileOutputStream,ObjectOutputStreanm,这些我们在后面都会一一说到。先说FileOutputStream
我以一个文件复制程序来说,顺便演示一下缓存区的使用。(Java I/O默认是不缓冲流的,所谓“缓冲”就是先把从流中得到的一块字节序列暂存在一个被称为buffer的内部字节数组里,然后你可以一下子取到这一整块的字节数据,没有缓冲的流只能一个字节一个字节读,效率孰高孰低一目了然。有两个特殊的输入流实现了缓冲功能,一个是我们常用的BufferedInputStream.)
Java代码