基于yolov5的智慧交通监测系统
本项目实现了智慧交通监测、红绿灯监测、行人监测、车辆识别、斑马线闯红灯监测等多种监测功能。
目录
背景
演示效果:
检测代码样例:
最后的检测效果如图所示
项目具体的工作流程为:
总结:
背景
针对城市交通拥堵问题,提出了一种基于yolov5的智慧交通监测系统。该系统利用了yolov5的智能感知、云计算以及通信等功能,实现车辆的定位跟踪和远程监控。系统首先通过yolov5摄像头采集车辆实时位置信息,然后将采集到的信息以数据流和图像流形式展示给客户端。实验结果表明,该系统可实时监测车辆的行驶轨迹和位置信息,具有一定的实用价值。
演示效果:
python闯红灯检测斑马线检测红绿灯检测车速检测车流量统计车牌识别智慧交通系统
检测代码样例:
import argparse
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized, TracedModel
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz, trace = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size, not opt.no_trace
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if trace:
model = TracedModel(model, device, opt.img_size)
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
old_img_w = old_img_h = imgsz
old_img_b = 1
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Warmup
if device.type != 'cpu' and (old_img_b != img.shape[0] or old_img_h != img.shape[2] or old_img_w != img.shape[3]):
old_img_b = img.shape[0]
old_img_h = img.shape[2]
old_img_w = img.shape[3]
for i in range(3):
model(img, augment=opt.augment)[0]
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
t2 = time_synchronized()
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t3 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
if names[int(c)] == 'car'or names[int(c)] == 'bus' or names[int(c)] == 'truck':
s += f"{n} {'vehicle'}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
# print('label:',label)
if "car" in label or "bus" in label or "truck" in label:
# plot_one_box(xyxy, im0, label='vehicle', color=colors[int(cls)], line_thickness=1)
plot_one_box(xyxy, im0, label='vehicle', color=colors[0], line_thickness=1)
# Print time (inference + NMS)
print(f'{s}Done. ({(1E3 * (t2 - t1)):.1f}ms) Inference, ({(1E3 * (t3 - t2)):.1f}ms) NMS')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(0) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
print(f" The image with the result is saved in: {save_path}")
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='car.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='res_output', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--no-trace', action='store_true', help='don`t trace model')
opt = parser.parse_args()
# print(opt)
with torch.no_grad():
detect()
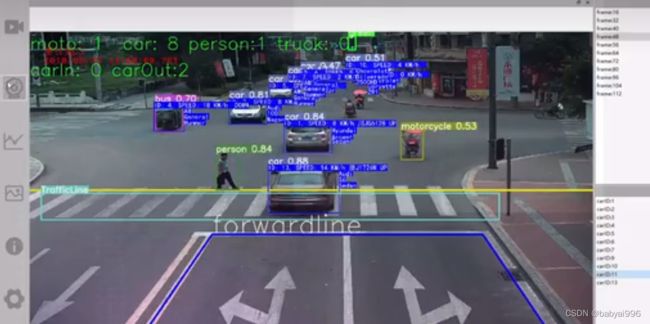
最后的检测效果如图所示
项目具体的工作流程为:
(a)建立了“智慧监控中心”的数据库,并根据用户需要对数据库进行了数据存储设计和数据分析与处理设计。
(b)客户端软件中的车载信息显示器实时显示车辆位置、速度以及车速等交通信息。
(c)利用yolov5对车辆运动轨迹进行实时追踪和记录,从而实现“智慧监控中心”中车辆实时位置数据与历史记录数据的同步传输。
(d)利用智能摄像头采集交通信号等数据并将其传输到服务器中进行处理和分析,从而实现远程控制和历史记录功能。
总结:
随着我国城市化进程的加快,城市规模迅速扩大和人口数量的不断增加,交通拥堵问题日益严重,对居民日常生活及城市形象产生了巨大影响。本项目旨在推动智慧城市建设,利用信息化手段,不断为智慧城市创建提供新的想法和思路。
不当之处还请批评指正!