【毕业设计】深度学习猫狗分类算法研究与实现 - python opencv cnn
文章目录
- 0 前言
- 1 课题背景
- 2 使用CNN进行猫狗分类
- 3 数据集处理
- 4 神经网络的编写
- 5 Tensorflow计算图的构建
- 6 模型的训练和测试
- 7 预测效果
- 8 最后
0 前言
Hi,大家好,这里是丹成学长的毕设系列文章!
对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
基于深度学习猫狗分类
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md

1 课题背景
要说到深度学习图像分类的经典案例之一,那就是猫狗大战了。猫和狗在外观上的差别还是挺明显的,无论是体型、四肢、脸庞和毛发等等, 都是能通过肉眼很容易区分的。那么如何让机器来识别猫和狗呢?这就需要使用卷积神经网络来实现了。
本项目的主要目标是开发一个可以识别猫狗图像的系统。分析输入图像,然后预测输出。实现的模型可以根据需要扩展到网站或任何移动设备。我们的主要目标是让模型学习猫和狗的各种独特特征。一旦模型的训练完成,它将能够区分猫和狗的图像。
2 使用CNN进行猫狗分类
卷积神经网络 (CNN) 是一种算法,将图像作为输入,然后为图像的所有方面分配权重和偏差,从而区分彼此。神经网络可以通过使用成批的图像进行训练,每个图像都有一个标签来识别图像的真实性质(这里是猫或狗)。一个批次可以包含十分之几到数百个图像。
对于每张图像,将网络预测与相应的现有标签进行比较,并评估整个批次的网络预测与真实值之间的距离。然后,修改网络参数以最小化距离,从而增加网络的预测能力。类似地,每个批次的训练过程都是类似的。

3 数据集处理
猫狗照片的数据集直接从kaggle官网下载即可,下载后解压,这是我下载的数据:

相关代码
import os,shutil
original_data_dir = "G:/Data/Kaggle/dogcat/train"
base_dir = "G:/Data/Kaggle/dogcat/smallData"
if os.path.isdir(base_dir) == False:
os.mkdir(base_dir)
# 创建三个文件夹用来存放不同的数据:train,validation,test
train_dir = os.path.join(base_dir,'train')
if os.path.isdir(train_dir) == False:
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
if os.path.isdir(validation_dir) == False:
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')
if os.path.isdir(test_dir) == False:
os.mkdir(test_dir)
# 在文件中:train,validation,test分别创建cats,dogs文件夹用来存放对应的数据
train_cats_dir = os.path.join(train_dir,'cats')
if os.path.isdir(train_cats_dir) == False:
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
if os.path.isdir(train_dogs_dir) == False:
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats')
if os.path.isdir(validation_cats_dir) == False:
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
if os.path.isdir(validation_dogs_dir) == False:
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir,'cats')
if os.path.isdir(test_cats_dir) == False:
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
if os.path.isdir(test_dogs_dir) == False:
os.mkdir(test_dogs_dir)
#将原始数据拷贝到对应的文件夹中 cat
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_data_dir,fname)
dst = os.path.join(train_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_data_dir,fname)
dst = os.path.join(validation_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_data_dir,fname)
dst = os.path.join(test_cats_dir,fname)
shutil.copyfile(src,dst)
#将原始数据拷贝到对应的文件夹中 dog
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_data_dir,fname)
dst = os.path.join(train_dogs_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_data_dir,fname)
dst = os.path.join(validation_dogs_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_data_dir,fname)
dst = os.path.join(test_dogs_dir,fname)
shutil.copyfile(src,dst)
print('train cat images:', len(os.listdir(train_cats_dir)))
print('train dog images:', len(os.listdir(train_dogs_dir)))
print('validation cat images:', len(os.listdir(validation_cats_dir)))
print('validation dog images:', len(os.listdir(validation_dogs_dir)))
print('test cat images:', len(os.listdir(test_cats_dir)))
print('test dog images:', len(os.listdir(test_dogs_dir)))
train cat images: 1000
train dog images: 1000
validation cat images: 500
validation dog images: 500
test cat images: 500
test dog images: 500
4 神经网络的编写
cnn卷积神经网络的编写如下,编写卷积层、池化层和全连接层的代码
conv1_1 = tf.layers.conv2d(x, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_1')
conv1_2 = tf.layers.conv2d(conv1_1, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_2')
pool1 = tf.layers.max_pooling2d(conv1_2, (2, 2), (2, 2), name='pool1')
conv2_1 = tf.layers.conv2d(pool1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_1')
conv2_2 = tf.layers.conv2d(conv2_1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_2')
pool2 = tf.layers.max_pooling2d(conv2_2, (2, 2), (2, 2), name='pool2')
conv3_1 = tf.layers.conv2d(pool2, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_1')
conv3_2 = tf.layers.conv2d(conv3_1, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_2')
pool3 = tf.layers.max_pooling2d(conv3_2, (2, 2), (2, 2), name='pool3')
conv4_1 = tf.layers.conv2d(pool3, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_1')
conv4_2 = tf.layers.conv2d(conv4_1, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_2')
pool4 = tf.layers.max_pooling2d(conv4_2, (2, 2), (2, 2), name='pool4')
flatten = tf.layers.flatten(pool4)
fc1 = tf.layers.dense(flatten, 512, tf.nn.relu)
fc1_dropout = tf.nn.dropout(fc1, keep_prob=keep_prob)
fc2 = tf.layers.dense(fc1, 256, tf.nn.relu)
fc2_dropout = tf.nn.dropout(fc2, keep_prob=keep_prob)
fc3 = tf.layers.dense(fc2, 2, None)
5 Tensorflow计算图的构建
然后,再搭建tensorflow的计算图,定义占位符,计算损失函数、预测值和准确率等等
self.x = tf.placeholder(tf.float32, [None, IMAGE_SIZE, IMAGE_SIZE, 3], 'input_data')
self.y = tf.placeholder(tf.int64, [None], 'output_data')
self.keep_prob = tf.placeholder(tf.float32)
# 图片输入网络中
fc = self.conv_net(self.x, self.keep_prob)
self.loss = tf.losses.sparse_softmax_cross_entropy(labels=self.y, logits=fc)
self.y_ = tf.nn.softmax(fc) # 计算每一类的概率
self.predict = tf.argmax(fc, 1)
self.acc = tf.reduce_mean(tf.cast(tf.equal(self.predict, self.y), tf.float32))
self.train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(self.loss)
self.saver = tf.train.Saver(max_to_keep=1)
最后的saver是要将训练好的模型保存到本地。
6 模型的训练和测试
然后编写训练部分的代码,训练步骤为1万步
acc_list = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(TRAIN_STEP):
train_data, train_label, _ = self.batch_train_data.next_batch(TRAIN_SIZE)
eval_ops = [self.loss, self.acc, self.train_op]
eval_ops_results = sess.run(eval_ops, feed_dict={
self.x:train_data,
self.y:train_label,
self.keep_prob:0.7
})
loss_val, train_acc = eval_ops_results[0:2]
acc_list.append(train_acc)
if (i+1) % 100 == 0:
acc_mean = np.mean(acc_list)
print('step:{0},loss:{1:.5},acc:{2:.5},acc_mean:{3:.5}'.format(
i+1,loss_val,train_acc,acc_mean
))
if (i+1) % 1000 == 0:
test_acc_list = []
for j in range(TEST_STEP):
test_data, test_label, _ = self.batch_test_data.next_batch(TRAIN_SIZE)
acc_val = sess.run([self.acc],feed_dict={
self.x:test_data,
self.y:test_label,
self.keep_prob:1.0
})
test_acc_list.append(acc_val)
print('[Test ] step:{0}, mean_acc:{1:.5}'.format(
i+1, np.mean(test_acc_list)
))
# 保存训练后的模型
os.makedirs(SAVE_PATH, exist_ok=True)
self.saver.save(sess, SAVE_PATH + 'my_model.ckpt')
训练结果如下:
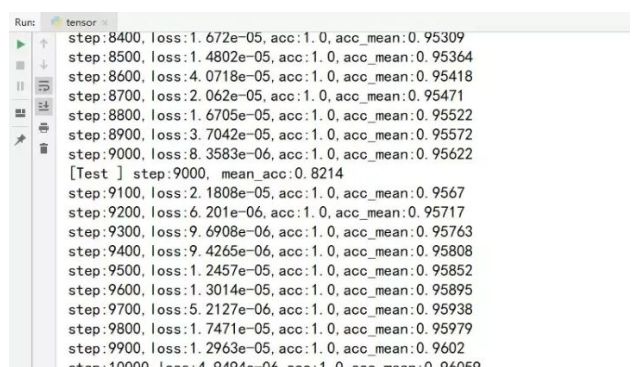
训练1万步后模型测试的平均准确率有0.82。
7 预测效果
选取三张图片测试
可见,模型准确率还是较高的。