初学者友好项目 - 使用 CNN 的猫狗分类
使用CNN进行猫狗分类
卷积神经网络 (CNN) 是一种算法,将图像作为输入,然后为图像的所有方面分配权重和偏差,从而区分彼此。神经网络可以通过使用成批的图像进行训练,每个图像都有一个标签来识别图像的真实性质(这里是猫或狗)。一个批次可以包含十分之几到数百个图像。
对于每张图像,将网络预测与相应的现有标签进行比较,并评估整个批次的网络预测与真实值之间的距离。然后,修改网络参数以最小化距离,从而增加网络的预测能力。类似地,每个批次的训练过程都是类似的。
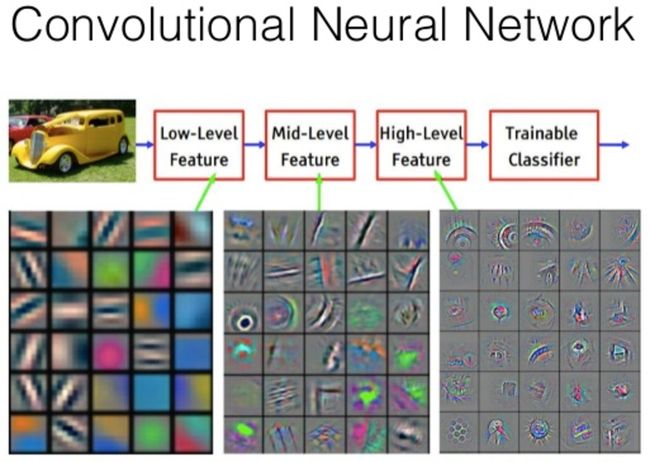
狗与猫的预测问题
本教程的主要目标是开发一个可以识别猫狗图像的系统。分析输入图像,然后预测输出。实现的模型可以根据需要扩展到网站或任何移动设备。Dogs vs Cats 数据集可以从 Kaggle 网站下载。该数据集包含一组猫和狗的图像。
我们的主要目标是让模型学习猫和狗的各种独特特征。一旦模型的训练完成,它将能够区分猫和狗的图像。
安装 Python 3.6 所需的包
Numpy -> 1.14.4 [图像被读取并存储在 NumPy 数组中]
TensorFlow -> 1.8.0 [Tensorflow 是 Keras 的后端]
Keras -> 2.1.6 [Keras 用于实现CNN]
导入库
NumPy- 用于处理数组、线性代数。
Pandas – 用于读/写数据
Matplotlib – 显示图像
TensorFlow Keras 模型——需要一个模型来正确预测
TensorFlow Keras 层——每个 NN 都需要层,而 CNN 需要几层。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Convolution2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
CNN 在称为过滤器的权重矩阵的帮助下处理图像。它们检测垂直和水平边缘等低级特征。通过每一层,过滤器识别高级特征。
我们首先初始化CNN,
#initializing the cnn
classifier=Sequential()
为了编译 CNN,我们使用了 adam 优化器。
自适应矩估计 (Adam) 是一种用于计算每个参数的单独学习率的方法。对于损失函数,我们使用二元交叉熵将类输出与每个预测概率进行比较。然后它根据与期望值的总距离计算惩罚分数。
图像增强是一种将不同类型的变换应用于原始图像的方法,生成同一图像的多个变换副本。由于移动、旋转、翻转等技术,图像在某些方面彼此不同。
因此,我们使用 Keras ImageDataGenerator 类来增强我们的图像。
#part2-fitting the cnn to the images
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
我们需要一种方法将我们的图像转换为内存中的成批数据数组,以便在训练期间将它们馈送到网络。ImageDataGenerator 可以很容易地用于此目的。所以,我们导入这个类并创建一个生成器的实例。我们使用 Keras 通过 ImageDataGenerator 类的 flow_from_directory 方法从磁盘检索图像。
# Generating images for the Test set
test_datagen = ImageDataGenerator(rescale = 1./255)
# Creating training set
training_set = train_datagen.flow_from_directory('C:/Users/khushi shah/AndroidStudioProjects/catanddog/dataset/training_set',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
# Creating the Test set
test_set = test_datagen.flow_from_directory('C:/Users/khushi shah/AndroidStudioProjects/catanddog/dataset/test_set',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
卷积
卷积是一种线性运算,涉及将权重与输入相乘。乘法是在输入数据数组和称为过滤器或内核的二维权重数组之间执行的。过滤器总是小于输入数据,并且在输入和过滤器数组之间执行点积。
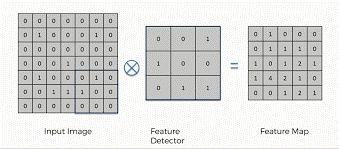
激活
添加激活函数是为了帮助 ANN 学习数据中的复杂模式。激活函数的主要需要是在神经网络中加入非线性。

池化
池化操作提供空间差异,使系统能够识别具有不同外观的对象。它涉及在特征图的每个通道上添加一个 2D 过滤器,从而总结过滤器覆盖的那个区域中的特征。
因此,池化基本上有助于减少网络中存在的参数和计算的数量。它逐步减小网络的空间大小,从而控制过拟合。这一层有两种操作;平均池化和最大池化。
在这里,我们使用最大池化,根据其名称,它只会从池中取出最大值。借助过滤器在输入中滑动,这是可能的,并且在每个步幅中,最大参数将被取出,其余参数将被丢弃。
与卷积层不同,池化层不会修改网络的深度。

全连接
最终池化层的输出是扁平化的全连接层的输入。
全连接过程的实际工作方式如下:
全连接层中的神经元检测某个特征并保留其值,然后将该值传达给狗和猫类,然后他们检查该特征并确定该特征是否与它们相关。

#step1-convolution
classifier.add(Convolution2D(32,3,3,input_shape=(64,64,3),activation='relu'))
#step2-maxpooling
classifier.add(MaxPooling2D(pool_size=(2,2)))
#step3-flattening
classifier.add(Flatten())
#step4-fullconnection
classifier.add(Dense(output_dim=128,activation='relu'))
classifier.add(Dense(output_dim=1,activation='sigmoid'))
我们正在将我们的模型拟合到训练集。这需要一些时间才能完成。
classifier.fit_generator(training_set,samples_per_epoch=8000,nb_epoch=25,validation_data=test_set,nb_val_samples=2000)


可以看出,我们在训练集上的准确度为 0.8115。
我们可以通过 predict_image 函数使用我们的模型预测新图像,其中我们必须提供新图像的路径作为图像路径并使用 predict 方法。如果概率大于 0.5,则图像将被预测为狗,否则为猫。
#to predict new images
def predict_image(imagepath, classifier):
predict = image.load_img(imagepath, target_size = (64, 64))
predict_modified = image.img_to_array(predict)
predict_modified = predict_modified / 255
predict_modified = np.expand_dims(predict_modified, axis = 0)
result = classifier.predict(predict_modified)
if result[0][0] >= 0.5:
prediction = 'dog'
probability = result[0][0]
print ("probability = " + str(probability))
else:
prediction = 'cat'
probability = 1 - result[0][0]
print ("probability = " + str(probability))
print("Prediction = " + prediction)
提供的功能
我们可以测试我们自己的图像并验证模型的准确性。
我们可以将代码直接集成到我们的其他项目中,并且可以扩展到网站或移动应用程序设备中。
只需找到合适的数据集,更改数据集并相应地训练模型,我们就可以将项目扩展到不同的实体。
应用
我们大致了解了如何执行图像分类。该项目的范围可以进一步扩展到具有自动化范围的不同行业,只需根据问题的需要来修改数据集。
结论
我希望你现在对卷积神经网络有一个基本的了解,并且可以对猫和狗的图像进行分类。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
