register_parameter和register_buffer 详解
在参考yolo系列代码或其他开源代码,经常看到register_buffer和 register_parameter的使用,接下来将详细对他们进行介绍。
1. 前沿
在搭建网络时,我们 自定义的参数,往往不会保存到模型权重文件中,或者成为模型可学习的参数。即我们通过 net.named_parameters() (模型可学习参数)或 net.state_dict().items()(保存模型权重值)方法都无法遍历输出。那如何解决呢,这就需要用到本文讲的register_parameter和register_buffer方法。
2. register_parameter
register_parameter() 是 torch.nn.Module 类中的一个方法。
2.1 主要作用
- 用于定义
可学习参数 - 定义的参数可被保存到网络对象的参数中,可使用
net.parameters()或net.named_parameters()查看 - 定义的参数
可用 net.state_dict() 转换到字典中,进而保存到网络文件 / 网络参数文件中
2.2 函数说明
register_parameter(name,param)
参数:
-
name:参数名称
-
param:参数张量, 须是
torch.nn.Parameter()对象 或 None ,否则报错如下
TypeError: cannot assign 'torch.FloatTensor' object to parameter 'xx' (torch.nn.Parameter or None required)
2.3 举例说明
(1)自定义的参数未使用register_parameter
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=9, kernel_size=3, stride=1, padding=1, bias=False)
self.weight = torch.ones(10,10)
self.bias = torch.zeros(10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x * self.weight + self.bias
return x
net = MyModule()
print('\n', '*'*30+"net.named_parameters"+'*'*30, '\n')
for name, param in net.named_parameters():
print(name, param.shape)
print('\n', '*'*30+"net.state_dict"+'*'*30, '\n')
for key, val in net.state_dict().items():
print(key, val.shape)
输出:
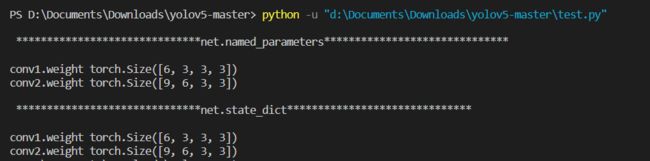
在网络搭建的代码中,我们自定义了self.weight和self.bias参数。我们思考下2个问题:1. 我们定义的self.weight和self.bias参数是否会保存到网络的参数中,是否能在优化器的作用下进行学习。2. 这些参数是否能够保存到模型文件中,从而可以利用state_dict中遍历出来。通过上面的打印信息我们发现:
- 使用
net.named_parameters()迭代网络中可学习的参数,发现输出的参数只有conv1和conv2的weight参数,并没有输出我们定义的self.weight和self.bias - 接下来使用
net.state_dict()方法迭代保存的参数,同样发现self.weight和self.bias参数也没有被输出出来。
(2)通过register_parameter方法来定义参数
- 接下来我们使用
register_parameter来定义weight和bias参数,看看会有啥效果。代码修改如下:
self.register_parameter('weight',torch.nn.Parameter(torch.ones(10,10)))
self.register_parameter('bias',torch.nn.Parameter(torch.zeros(10)))
完整代码
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=9, kernel_size=3, stride=1, padding=1, bias=False)
self.register_parameter('weight',torch.nn.Parameter(torch.ones(10,10)))
self.register_parameter('bias',torch.nn.Parameter(torch.zeros(10)))
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x * self.weight + self.bias
return x
net = MyModule()
print('\n', '*'*30+"net.named_parameters"+'*'*30, '\n')
for name, param in net.named_parameters():
print(name, param.shape)
print('\n', '*'*30+"net.state_dict"+'*'*30, '\n')
for key, val in net.state_dict().items():
print(key, val.shape)
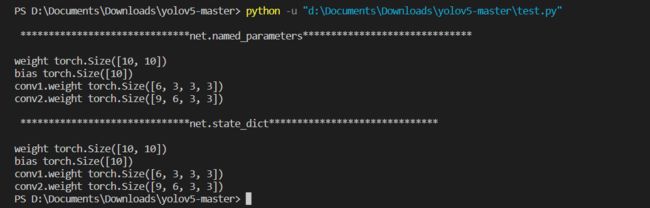
- 可以看到,使用了
register_parameter定义的参数weight和bias,可以通过net.named_parameters或者net.parameters迭代出来的,这说明weight和bias已经存到了网络的参数中,他们是可学习的参数 - 同时,通过
state_dict()也能将参数和值给迭代出来,就说明如果要保存模型权重或网络参数时,这两个参数时可以被保存起来的。
3 register_buffer()
register_buffer()是 torch.nn.Module() 类中的一个方法
3.1 作用
- 用于
定义不可学习的参数 - 定义的参数
不会被保存到网络对象的参数中,使用 net.parameters() 或 net.named_parameters() 查看不到 - 定义的
参数可用 net.state_dict() 转换到字典中,进而保存到网络文件 / 网络参数文件中
register_buffer() 用于在网络实例中 注册缓冲区,存储在缓冲区中的数据,类似于参数(但不是参数),它与参数的区别为:
-
参数:可以被优化器更新 (requires_grad=False / True) -
buffer 中的数据 (不可学习): 不会被优化器更新
3.2、举例说明
将定义的weight和bias,通过register_buffer来定义。
self.register_buffer('weight',torch.ones(10,10))
self.register_buffer('bias',torch.zeros(10))
运行完整代码看看效果:
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=9, kernel_size=3, stride=1, padding=1, bias=False)
self.register_buffer('weight',torch.ones(10,10))
self.register_buffer('bias',torch.zeros(10))
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x * self.weight + self.bias
return x
net = MyModule()z
print('\n', '*'*30+"net.named_parameters"+'*'*30, '\n')
for name, param in net.named_parameters():
print(name, param.shape)
print('\n', '*'*30+"net.state_dict"+'*'*30, '\n')
for key, val in net.state_dict().items():
print(key, val.shape)

我们可以看到:
- 通过
register_buffer定义的参数weight和bias,它是没有被named_parameter给迭代出来的,也就是说weight和bias不是网络的可学习参数,无法通过优化器来迭代更新,我们把它叫做buffer,而不是参数 - 然而我们使用
net.state_dict去迭代的话,weight和bias事可以被迭代出来的,这就说明使用register_buffer定义的数据,可以保持到模型或者权重文件中。
注意:
- 在使用
register_parameter定义参数时,必须定义为可学习的参数,因此需要通过torch.nn.Parameter去定义为一个可学习的参数 - 而我们使用
register_buffer定义参数时,是不需要通过torch.nn.Parameter去定义为可学习的参数的