2021/01/28 k8s核心组件及工作流程



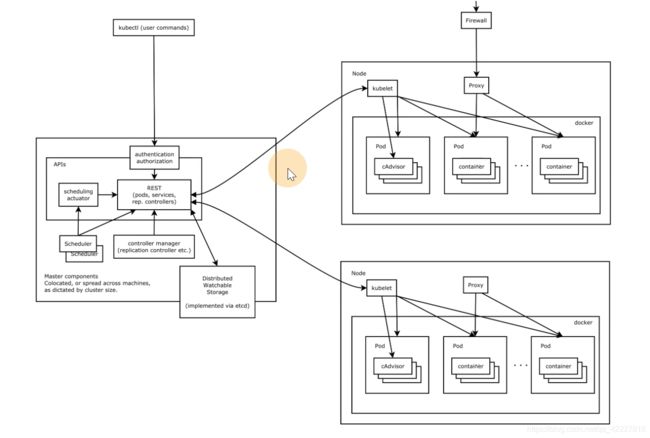
K8S用etcd(CP)存储数据,比如pod在哪个节点上
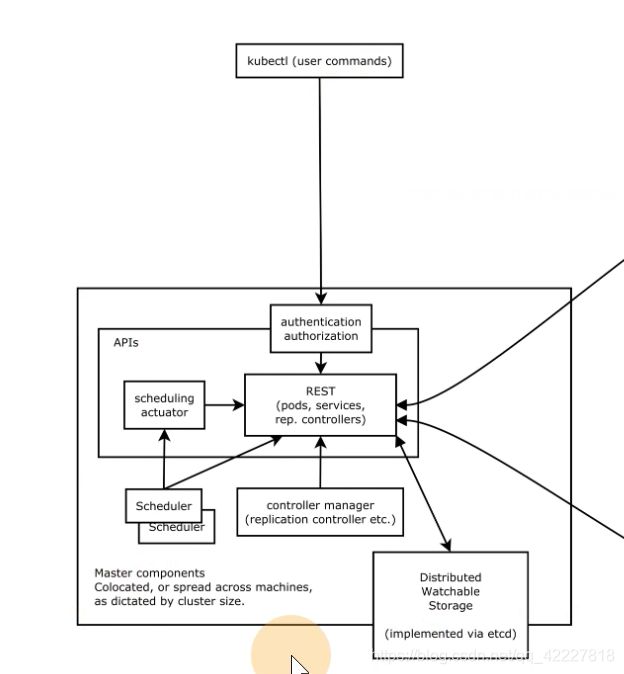
APIserver接收请求,整个集群的访问入口,还有安全访问控制authentication authorization,etcd的数据只能api去写入。
所有的数据想要同步只能通过apiserver来做。
scheduler把业务容器调度到最合适的节点上去

加入告诉K8S集群要启动两个副本,谁去保证有2个副本在启动,这是controller manager管理的,假如有一个挂了,它会再次启动。不管怎么样,它去保证副本数是2,副本控制器replication controller。
controller manager其实是一类控制器的总称,总合起来就可以让集群按照我们期望的方式去执行

工作节点上的各种状态,管理节点需要知道(比如跑了什么服务,状态是什么)kubelet类似master插在node地方上的大使,汇报想要的数据源。
kubelet功能分三个:启动pod,node节点状态(会监控一些数据源调用apiserver,传到etcd数据库里),健康检查。
proxy是去维护iptables规则。有一些负载均衡的任务


**所有命令都是通过apiserver,去做一些鉴权,写入etcd,之后,scheduler调度器监听apiserver是否有没有调度的pod,找遍所有节点,哪个节点打分最高就调度到哪个节点。调度好了通过apiserver写到etcd里。
kubelet也是通过监听apiserver bound pod,假如容器调度到自身了,就调用docker运行起来。docker跑起来后也是通过apiserver写入到etcd里
**


apiserver是所有的请求入口,control manage控制中枢,存储,scheduler主管调度,kubelet负责运行。
除了etcd,其他都是无数据无状态的,更好做高可用



其他组件需要监听

第2章 集群安装
2.1 集群安装详解

是集成在一个节点的简易K8S,是去测试的一个
![]()
现在两个是比较建议的


创建三台机器


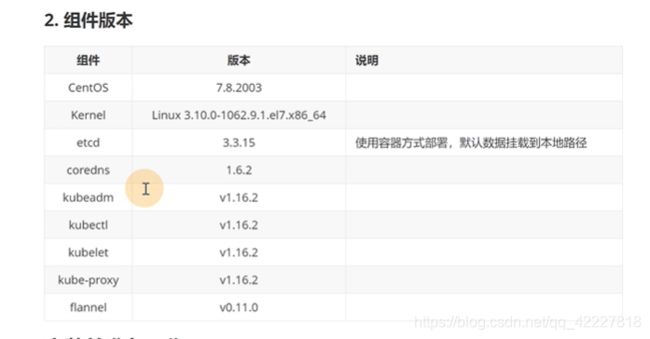
一般都是间隔一个版本去用,比如现在1.17那就使用1.15

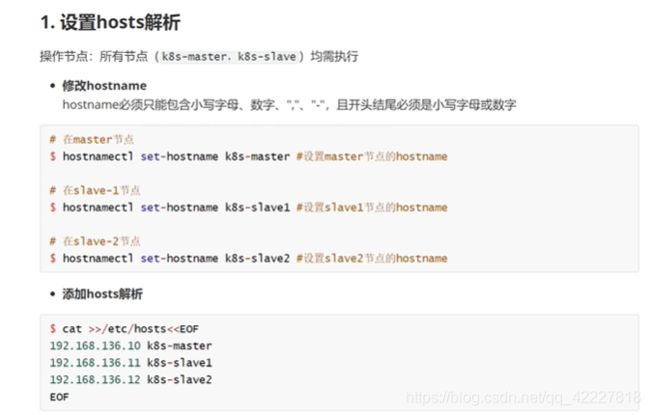
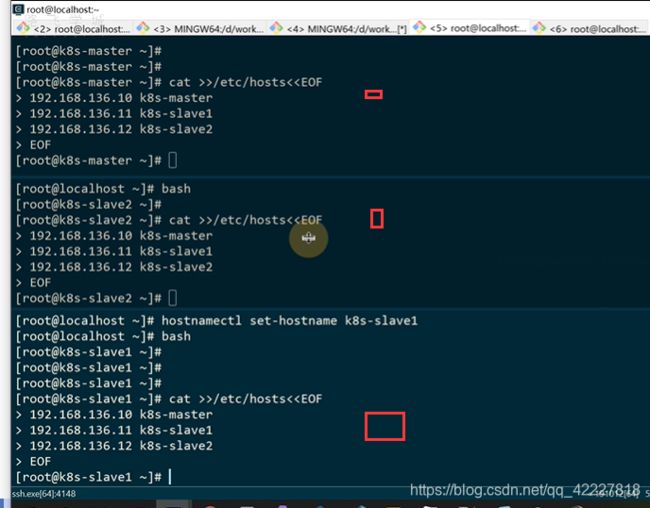
三台主机进行修改hosts

修改/etc/hosts
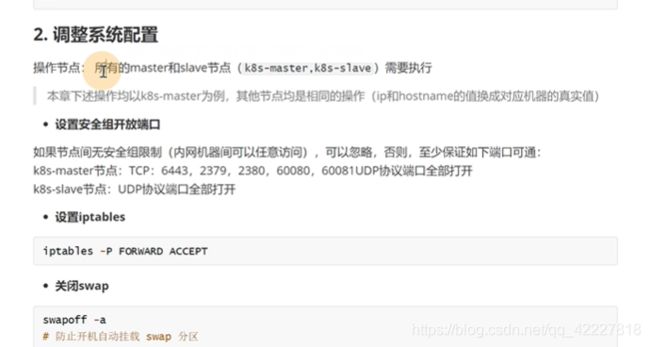
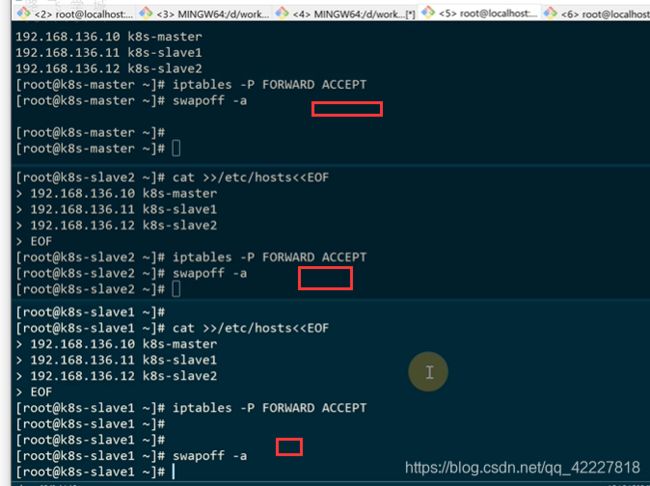
开启forward转发

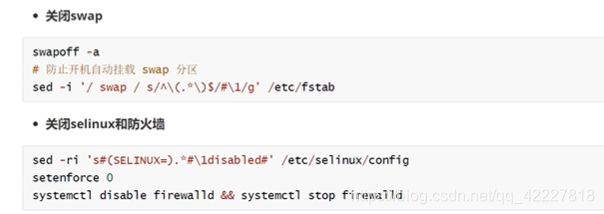
关闭swap,否则kubelet启动不起来


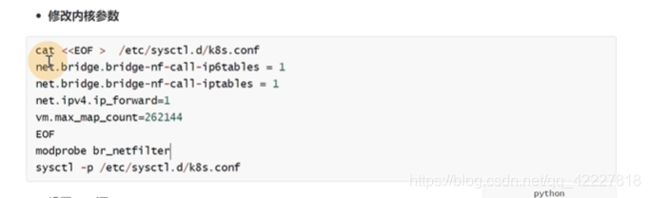
加载br_netfilter,是内核层面的包
![]()
有一个K8S的源


这一个镜像加速

指定的版本是1.16.2

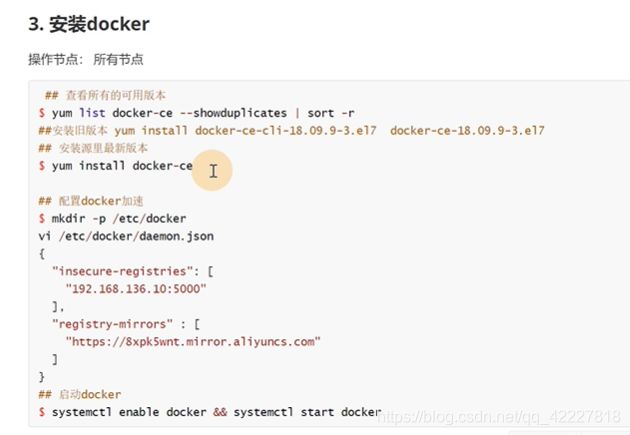
三台节点都去执行一下

只在master节点操作

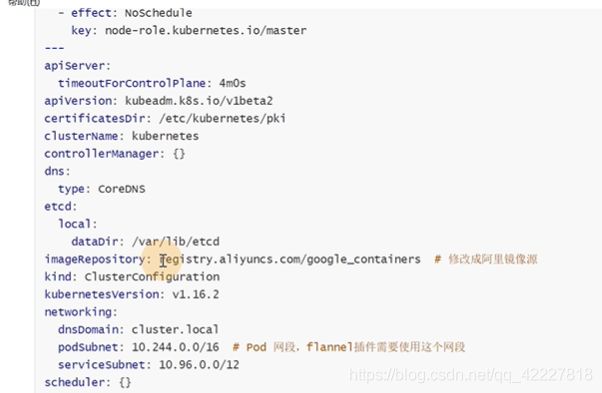
这里如果是多台,就需要改成lb的地址

让kubeadmin打印初始化的配置
![]()
这里的源改成阿里云的源
![]()
pod网段,默认是没有的,需要加一下,pod网段是跟宿主机无关的,虚拟网络,不管本地虚拟机是192.168的网段还是别的,都是可以用这个地址,只要这个段和物理机不要重复就行

这是kubeadm安装需要的初始化文件

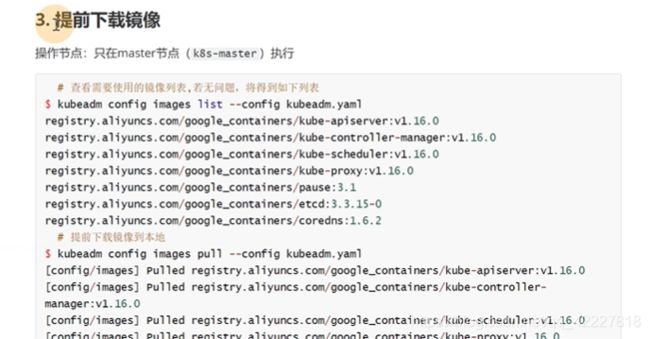
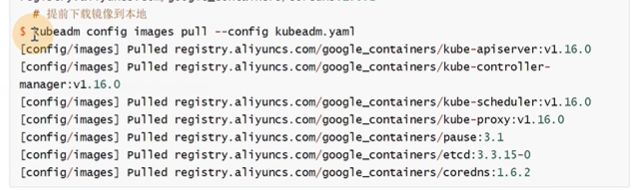
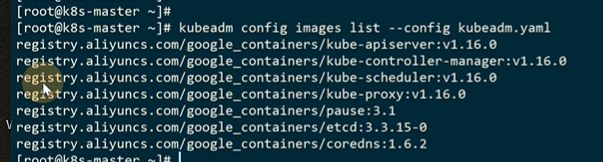
需要使用的镜像列表
拉取镜像

三个核心的组件

coredns是做内部dns解析的
![]()
阿里云的源不能用就用下面的方式

下面是dockerhub上,别人推的google镜像mirror


初始化master节点

手动如果去安装的话,controller-manager。scheduler,proxy都需要去配置,怎么和apiserver去调用通信,kubeadm的工具都帮你完成了、
master节点已经完成初始化了
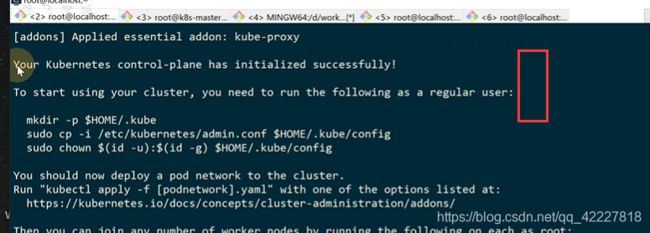


现在看到有一个节点,状态是notready,因为网络插件还没有安装
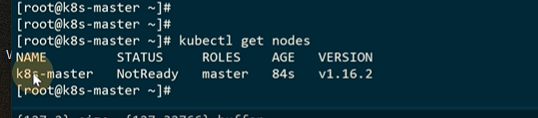
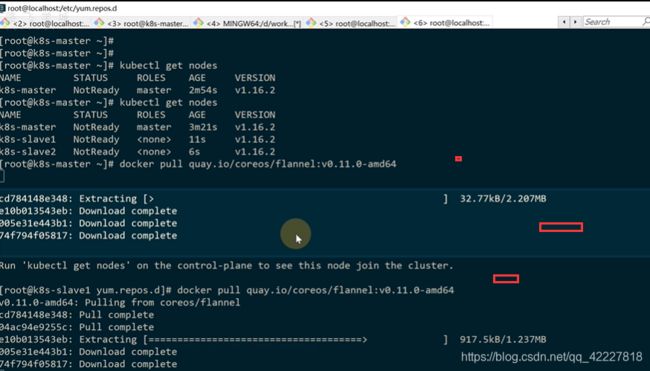
先把s’lave节点添加进去

输出什么就在slave节点上添加

因为每个K8S集群都需要一个CNI的一个网络插件

常用的插件有flannel,calico

多尝试几次,这个网站比较慢
![]()
需要修改一些配置

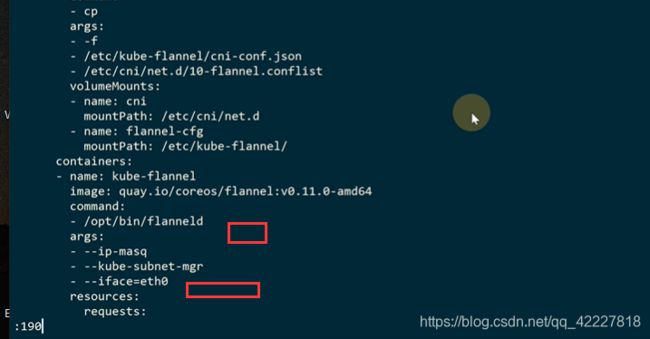
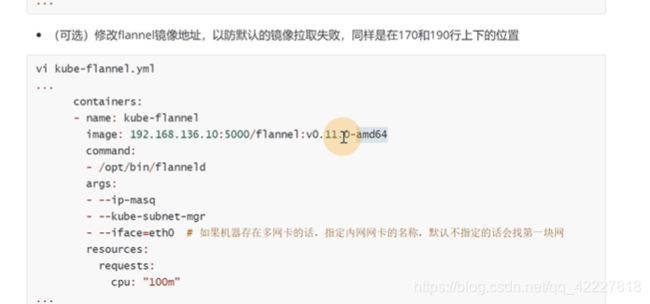
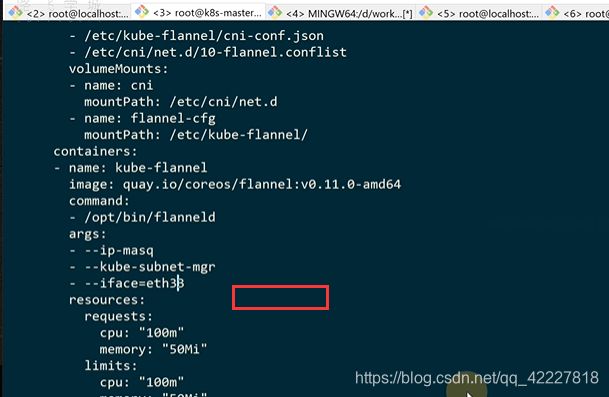
以防下载flannel镜像下载错误,可以换成私有的的地址


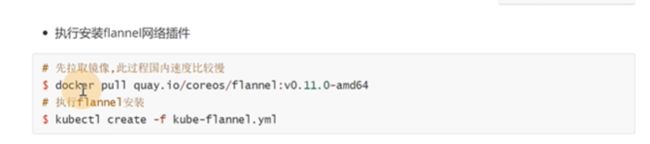
flannel是在每个节点都需要执行的
![]()
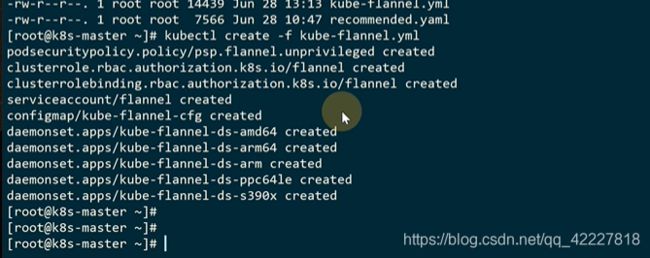
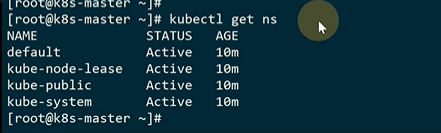
这里已经是ready状态了
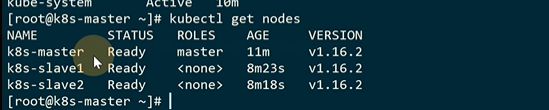

看一下日志

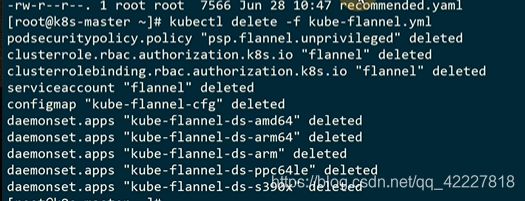
150行,改一下地址
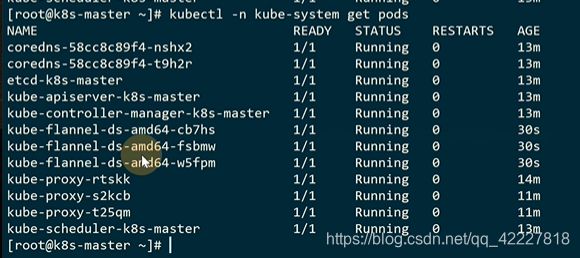




default正在创建中


可以直接去访问这个ip的



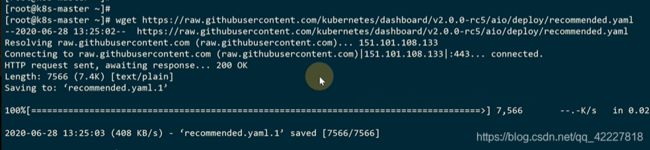

修改service为nodeport类型

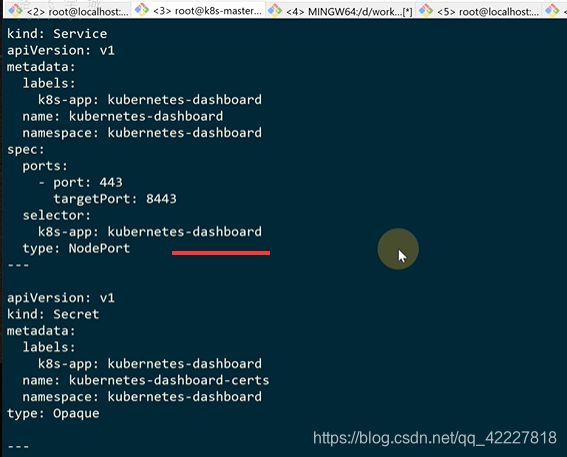

新加了一个dashboard



仪表盘的认证






拿到token


2.2 理解k8s的组件和资源
master上有三个核心组件,apiserver,controler manager,schedule,etcd
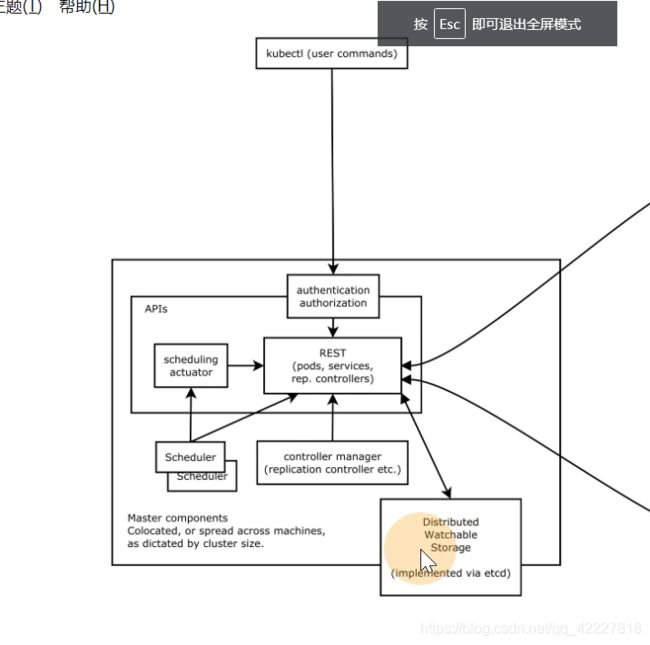
都是在master节点上
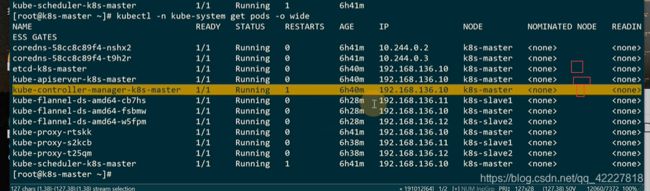
kubelet是一个systemd的管理服务

node和pod都是K8S的资源类型


kubectl api-resources可以查看所有的资源


pod和node

namespace,默认default

名称空间是K8S集群虚拟的概念。
整个K8S可以看作一个资源池,每个namespace就是对资源池的划分,也就是一个小池,里面有各种资源,pod,service

这里有true和false,是否是必须在一个名称空间里

node不是必须在一个名称空间里的,它是可以跨namespace的
![]()
这里其实是简写


同一个namespace有不同的资源


想要知道get方法如何使用

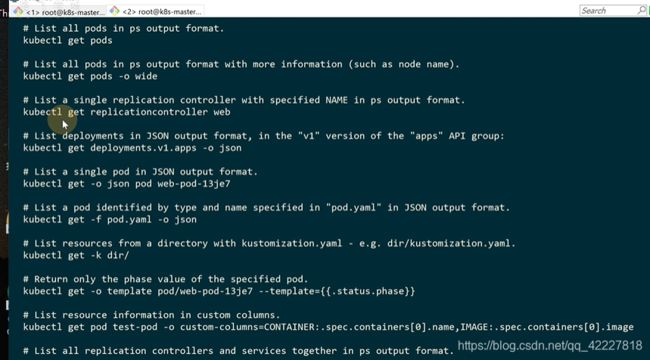
CKA考试的时候会用kubectl很多命令

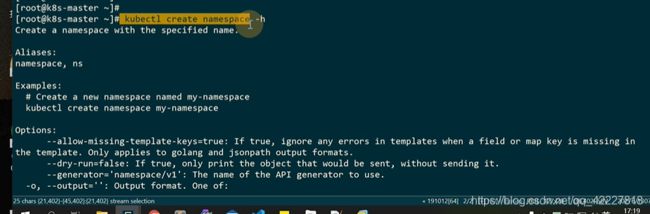
创建名称空间,不知道如何使用可以加-h

第3章 使用k8s管理业务应用实践
3.1 使用Pod管理业务应用入门
K8S调度最小单元是pod,(豆荚),pod里裹着容器
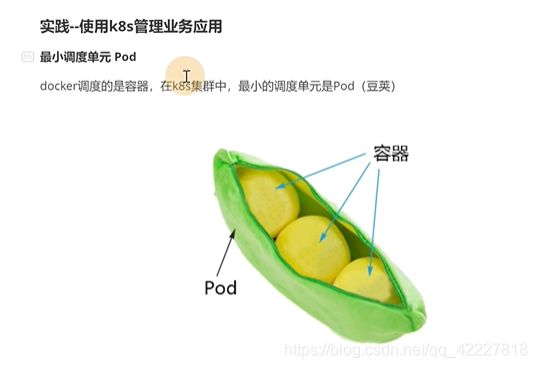
docker并不是唯一的容器引擎,还有RKT,也可以作为容器引擎。K8S作为一个管理平台,去管理容器,都要去兼容。就设计了pod,在pod这一层和容器进行了一个解耦。
容器网络,container网络模式可以去建立容器,管理网络加入到已经存在的容器里,也就是多个容器去共享一个网络空间。pod里的多容器支持的场景更加灵活。

使用yaml格式定义pod资源

如果改成JSON格式要表示这个yaml,也就是kv对
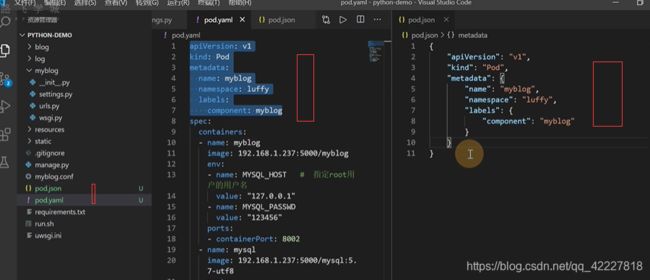
这个-杠对应的是一个数组

其实yaml比json省空间
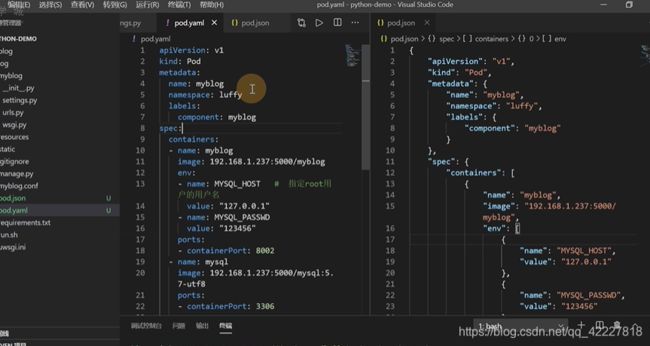
env,这是几个环境变量

kind是定义K8S哪种类型

apiversion通常表示这个功能的成熟程度,成熟之后就用v1
![]()

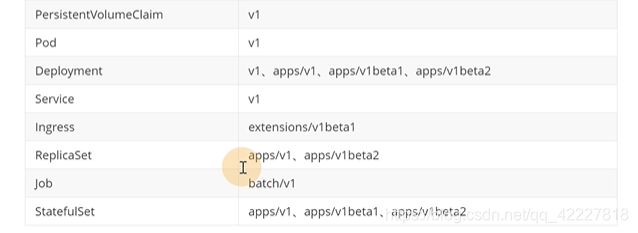
资源类型和apiversion对照表

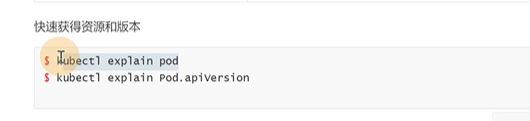
explain可以看这个pod的解释,把pod支持的每个属性都打印出来了
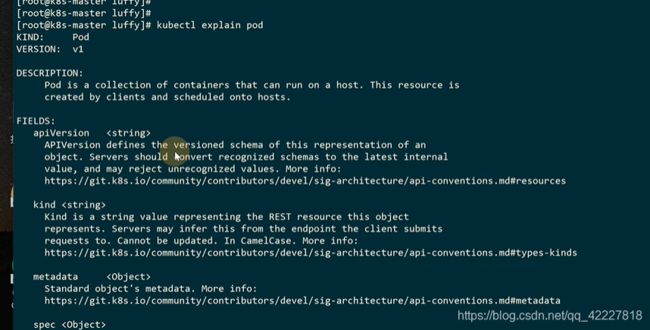
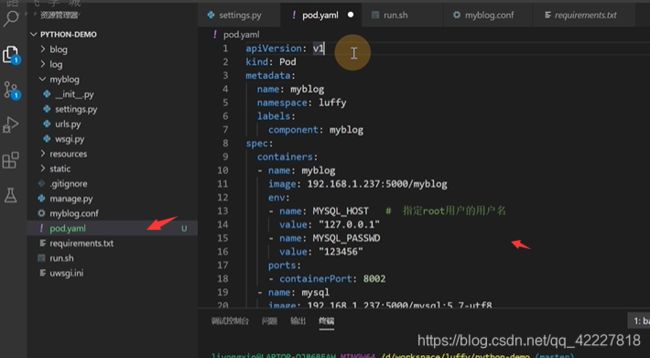
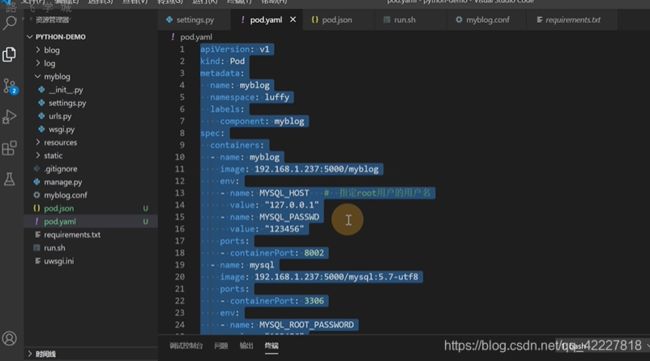
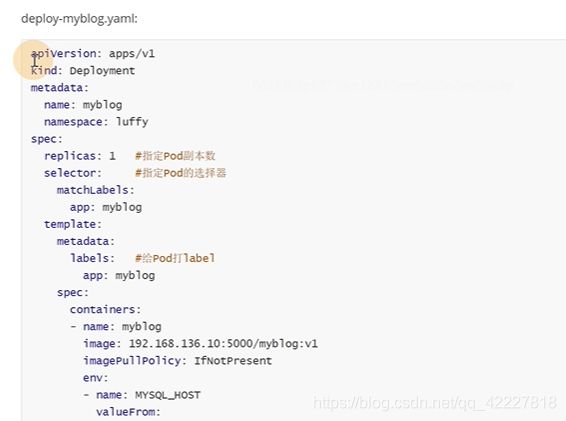
metadata是固定的,pod对象名字name是myblog,名称空间namespace是luffy,label标签,component:myblog
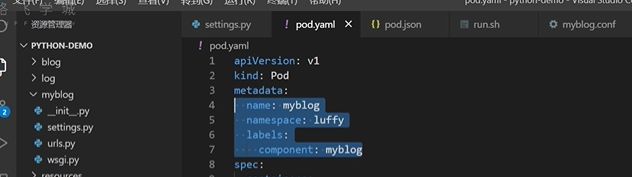
spec特定的一些属性,containers 容器是可以多个的,需要一个myblog镜像,一个mysql数据库,这里的name是容器的名字,可以跟pod的name属性无关
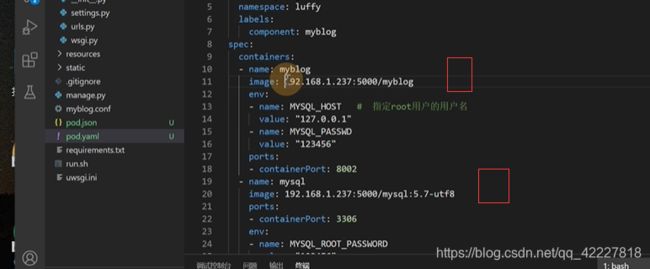
docker是用-e 传变量的


同一个pod容器是可以通过localhost通信的

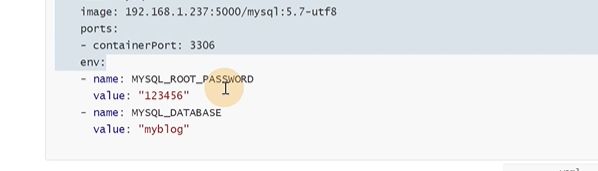
mysql运行的时候,初始化一个数据库


克隆一下项目地址



![]()
去创建一个镜像仓库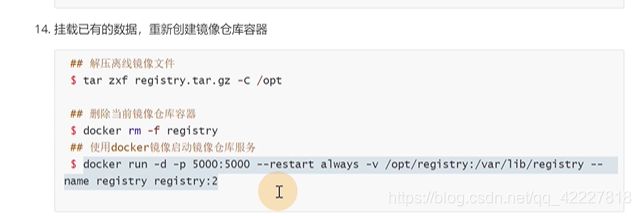
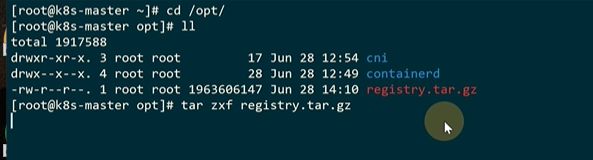
启动

本地仓库起来了

把yaml文件拷贝到机器上
制作一个mysql-utf8的镜像


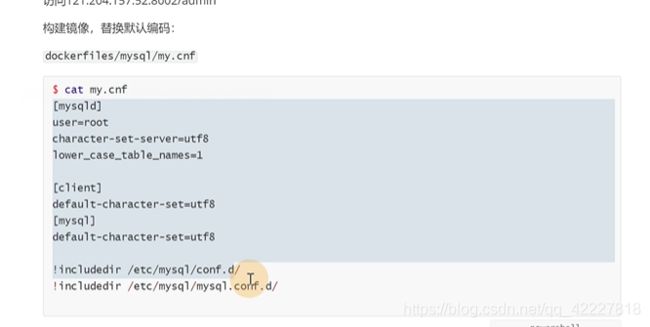
![]()


制作dockerfile

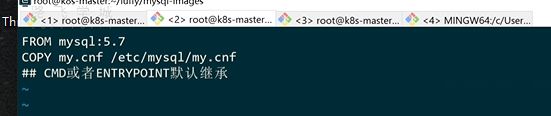
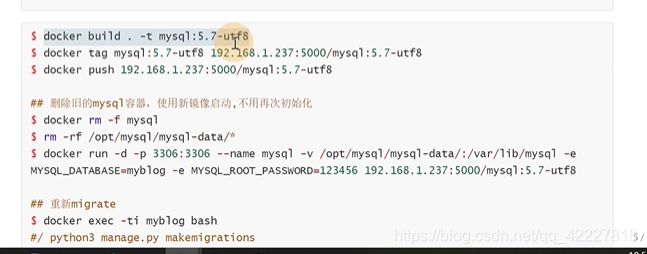

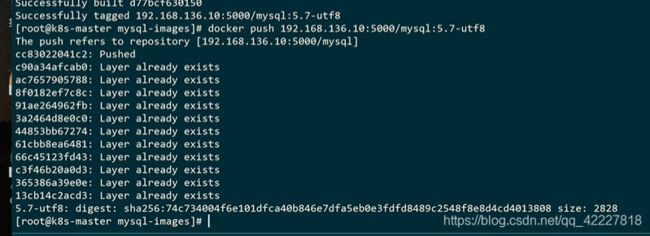
python项目镜像构建打tag并且推送到自建仓库上

现在yaml里的镜像都有了
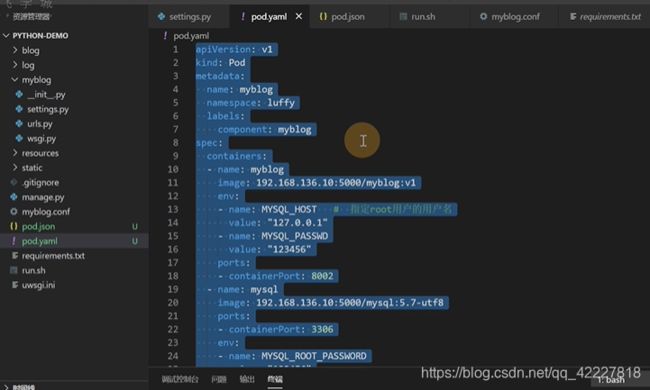

拷贝yaml

创建pod
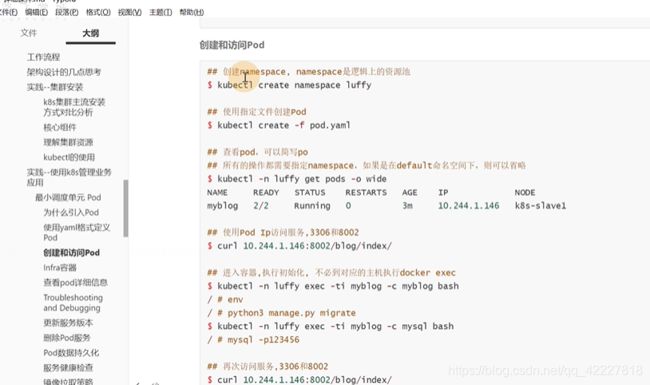
创建一个luffy的namespace



正在创建中


去slaveka

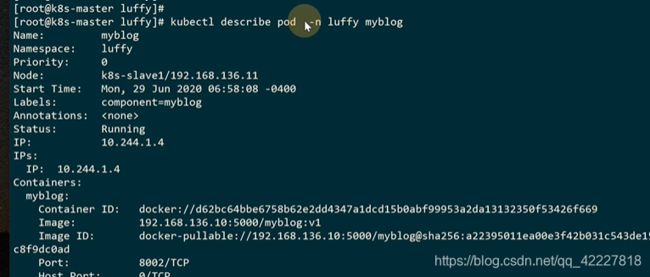
describe里有事件
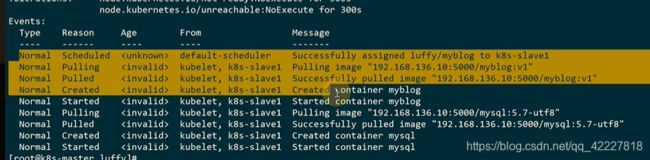
两个容器


访问podip端口

mysql需要做一下初始化
如果是用docker就只能到K8S-slave1节点上进入容器

默认进入的是myblog容器

想进入mysql容器可以-c

正常访问里面的数据库

再次进入myblog容器对mysql执行初始化,使用django的migrate
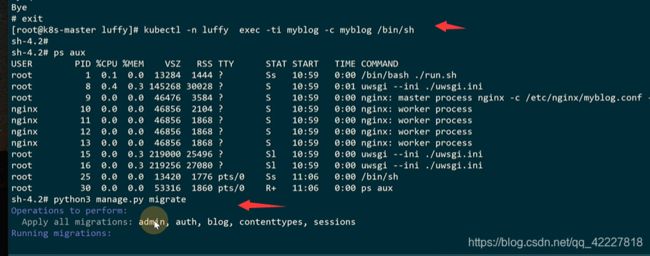
这里 的mysql就是localhost

现在就可以访问了

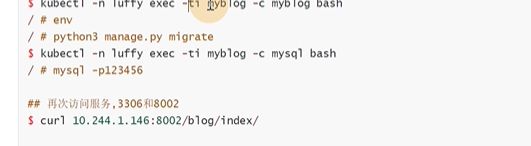
现在有三个容器,mysql,myblog,pause容器。
每个K8S创建pod的时候,都会去创建pause容器,基础设施的这样一个容器,它的作用就是创建网络名称空间,以后新加入pod里的容器都会用这个pause的网络名称空间。同一个pod内部容器都共享网络名称空间

pod容器里会去共享网络名称空间

mysql和myblog的ip地址都是一样的


容器名,pod名,名称空间,随机字符串
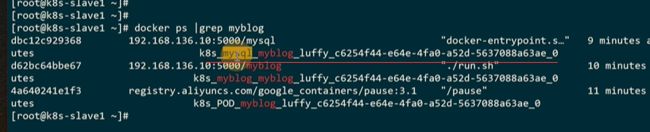

这个事件默认是一个小时,一个小时再看就没有数据了
也可以查看yaml

进入到一个pod里查看哪个容器的一些信息
logs查看容器日志

显示最新的10行

3.2 使用Pod管理业务应用进阶

镜像如何更新到K8S里去
修改成v2版本


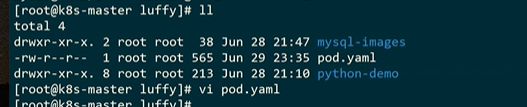
没有这个镜像,拉取镜像失败了
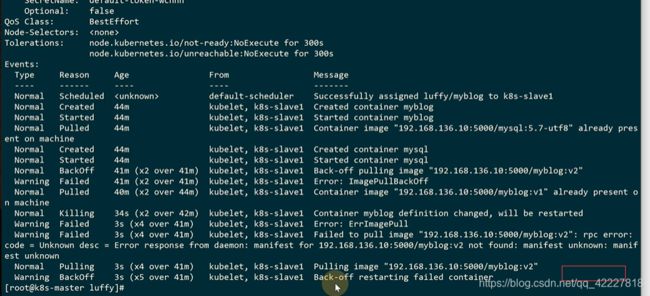

改回v1
![]()




通过文件删除,delete -f


也可以直接删除pod

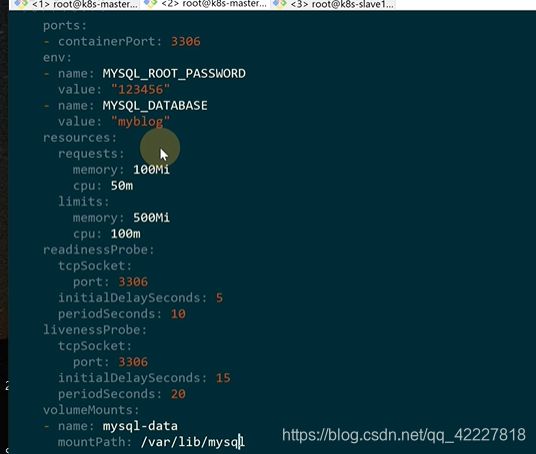
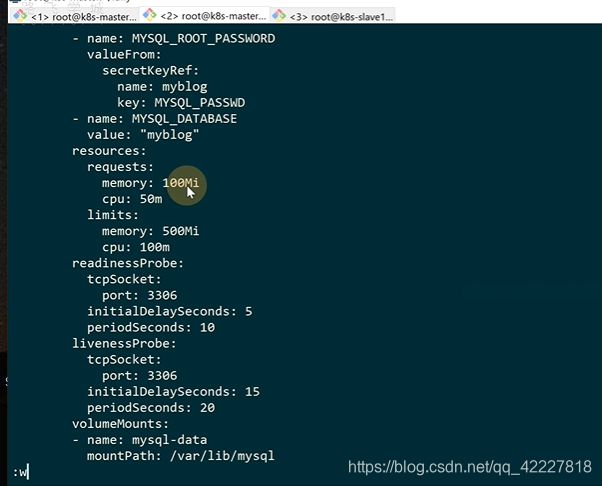
mysql数据需要持久化

在K8S里需要一个volumeMounts。这个关键字是和container一个级别的

这个volume定义的是每个container都可以使用的,是定义一个全局的,具体容器想用哪个都可以去挂载。

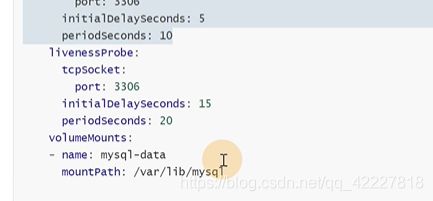
hostpath是主机上的目录,定义了一个volume叫mysql-data,类型是hostpath,挂载的宿主机就是path:/opt/mysql/data

这里是把上面定义的volume挂载上,

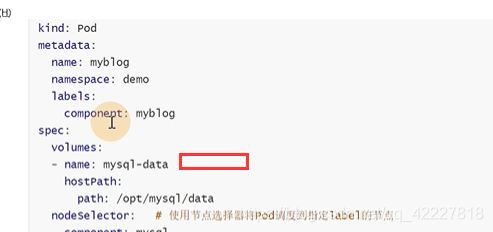
这两个名字应该是一致的。mountpath就是代表挂载到容器内的,也就是把宿主机的/opt/mysql/data挂载到/var/lib/mysql

但是现在只是针对slave1节点,pod飘到slave2节点就没有数据了

避免这个情况,就需要nodeselector做定义

nodeselector作用域也是整个pod,固定飘在mysql标签的节点上

![]()

把原来的删掉


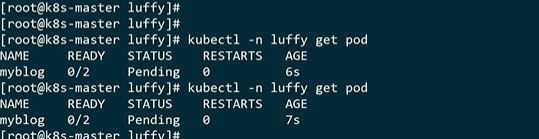
describe命令去查看为什么pending

查看node的标签


slave1的标签就多了一个

现在已经running了

node打上标签后,就检测到了合适的节点,就调度成功了

mysql的数据就可以在slave上的目录看到

这只是其中一种方式


这种方式需要定点,把pod和某一个node绑定死,想要实现pod来回调度,通过pv+pvc连接分布式存储的方案。现在ceph用的比较多,但是运维起来比较麻烦

K8S提供了健康检查的方式去判断服务是否运行正常。
livenessprobe,存活性探针

访问myblog的8002端口,路由是/blog/index

两次探针检测间隔时间,默认10秒
![]()
超时时间
![]()
httpget只是其中一种检测方式,这个url只要超过2秒未返回,或者状态码不是200-300之间,就认为是错误的

livenessprobe主要是去判断容器是否存活,如果不健康,则kublet会把容器杀掉,并根据容器重启策略重启。
如果没有livenessprobe探针,就默认永远成功


如果探测失败,去把pod杀掉,去做restartpod

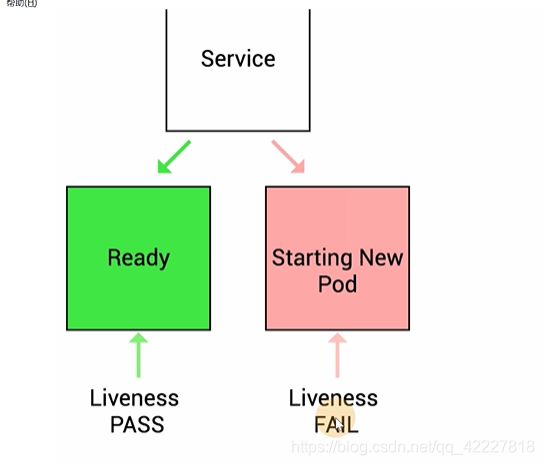
可用性探针就是判断容器是否能提供正常服务。ready是否为true

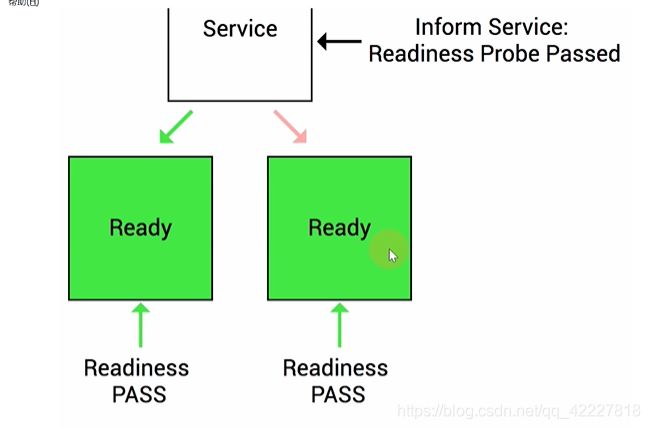
加入pod执行失败了

如果容器ready为false,endpoint controller控制器将此pod的endpoint从对于的service 的endpoint、列表删除。这个失败了,kubelet不会把pod删除掉,只是把流量断了

除了httpget方式,其他还有exec和tcpsocket,exec可以定义一个脚本,判断脚本返回值来决定true和flase。如果是0,容器就是健康的。
tcpsocket,就是pod建立tcp链接,建立成功,就代表容器健康


给myblog应用加上livenessprobe和readinessprobe




!在这里插入图片描述
再去生成

这里是1,mysql容器没有加健康检查,所以认为是1



这里现在都是500,没有做数据库migrate,也就是path访问不了
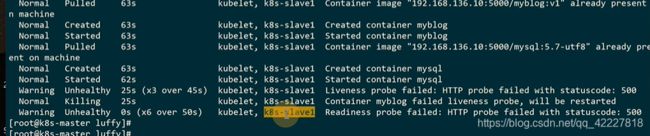

执行migrate



容器的异常退出或健康检查失败后,根据写的重启策略做重启


args可以理解为docker时候的CMD,这里的1号进程退出码是0,因为正常退出

![]()


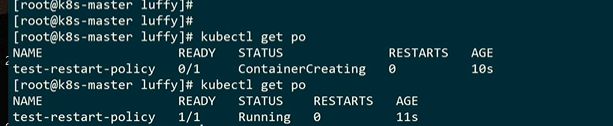
10秒钟就会退出,completed就是完成sleep了

crashloopbackoff,就是被杀掉了

always就是不管什么原因,容器进程退出后,就会帮你去重启


onfailure只有当容器异常退出,才会去重启
![]()

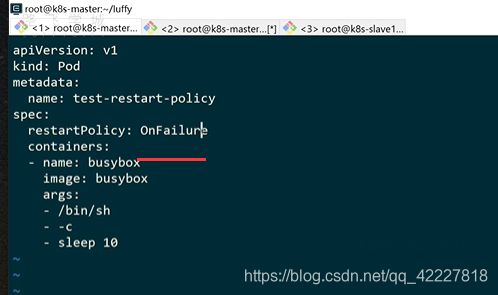

这个状态保持不动了,onfailure只针对非正常退出的场景



让脚本返回1,认为非正常退出
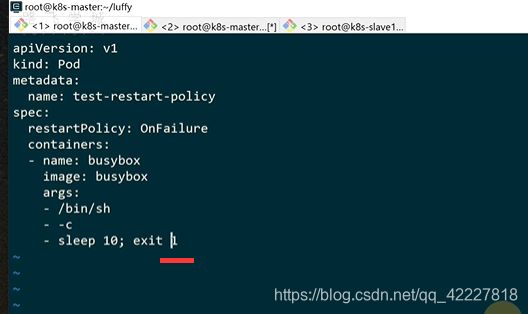
不重启就认为是ok的

exit 1就是非正常,变成error了


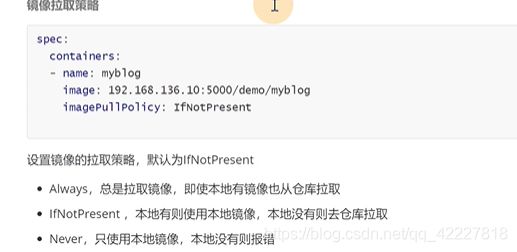

ifnotpresent 这里是给容器设置一个镜像的拉取策略
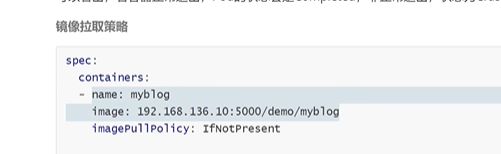
always。不管有没有都去拉
ifnotpresent,本地没有就去拉取

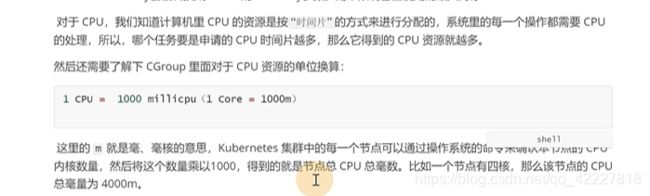
对于pod 可以做一些资源限制

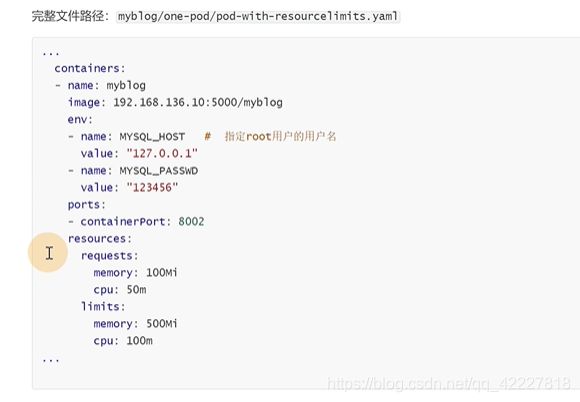
request是请求的,是资源调度阶段,容器的最小分配,limit是上限


、只是做一个调度的时候的判断依据
![]()
![]()
这个cpu只能写一个时间比,相对的值
![]()

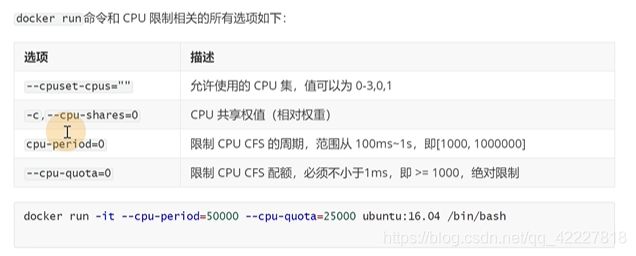
docker-run的时候相关的限制
![]()

3.3 使用Pod管理业务应用优化篇
这个是完善以后的yaml
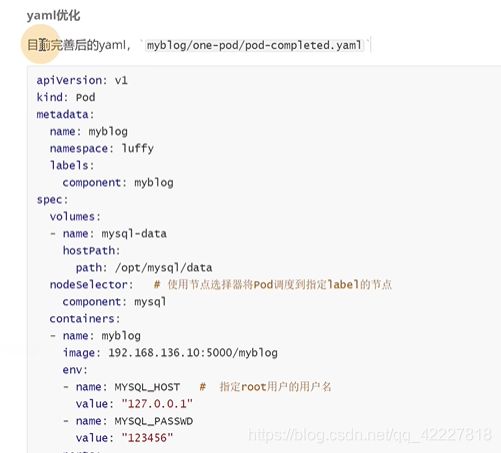


优化的地方,账号密码现在是明文

这个容器更新频率是很低的,只是 一个数据库,不应该和业务容器在一起
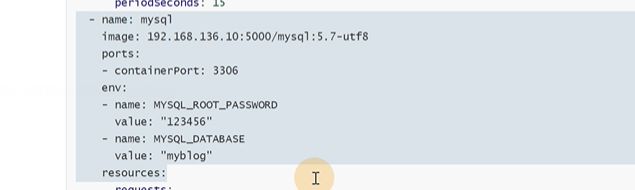

中间件不适合频繁更新,是为多个资源提供服务的。yaml不应该存在敏感信息


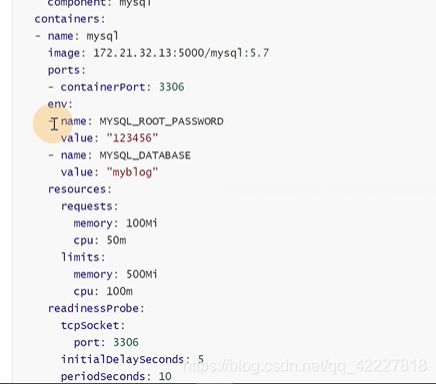

以host网络模式启动容器

node选择器


删除目前的pod

![]()
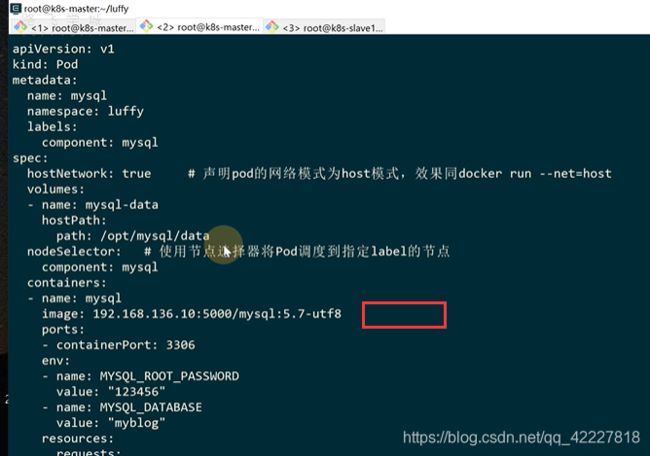
创建一个mysql pod


apply可以把镜像替换掉

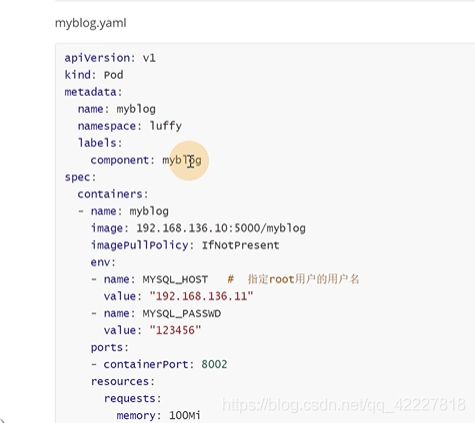

![]()


现在就都跑起来了

现在就可以访问到页面了

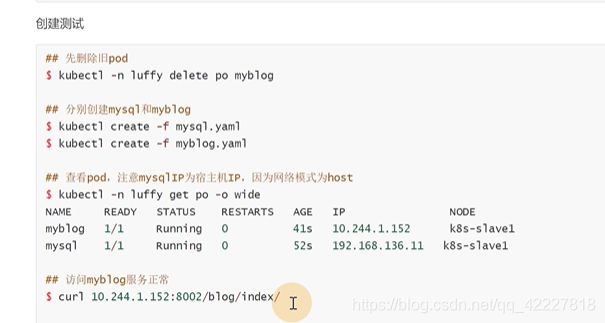
现在是两个pod
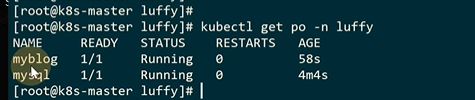

configmap和secret可以实现让配置文件和yaml文件分离,yaml文件不变,configmap和secret术语进行改变

namespace一定要和pod是一个
![]()
 、
、



2个术语


虽然K8S的所有资源都可以通过yaml创建,但是也可以通过kubectl这个命令创建configmap资源
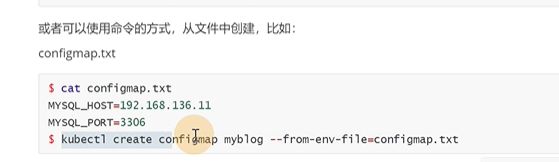

可以基于文件,目录创建configmap

从文件里创建,key1类似mysql_host
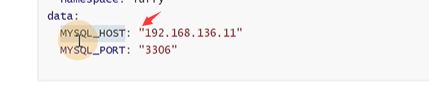

也可以从环境变量里创建

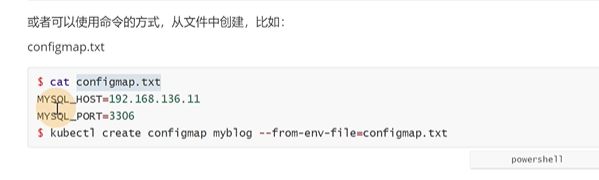
不知道怎么用还可以到官网查

secret和configmap的区别,secret管理敏感类信息,默认会base64编码存储

注意echo -n做一下base64加密
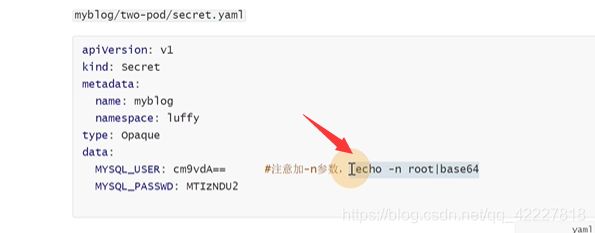
两次不一样
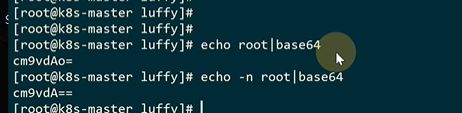
做一下解码。多一个换行


![]()
制作secret.yaml文件



这样就拿到数据
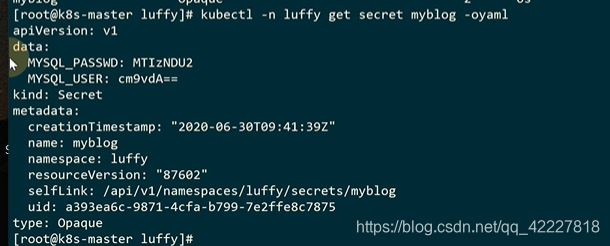
还可以通过文件创建
![]()

![]()

内容跟第一种方式一致,这是自动的去做的base64

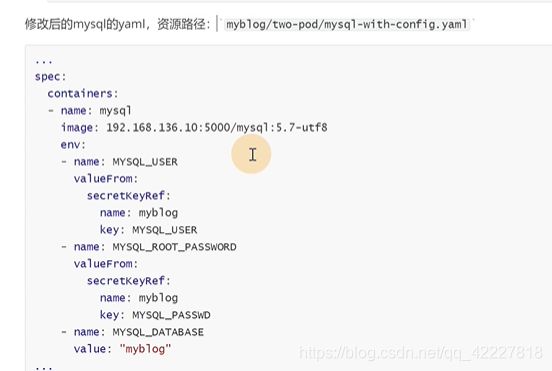
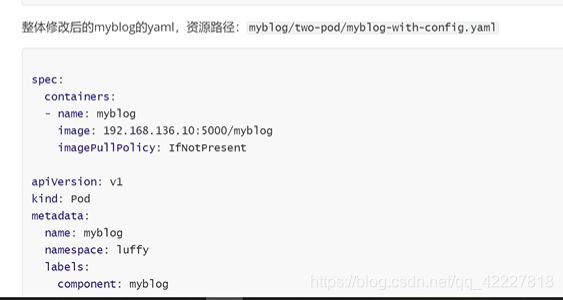
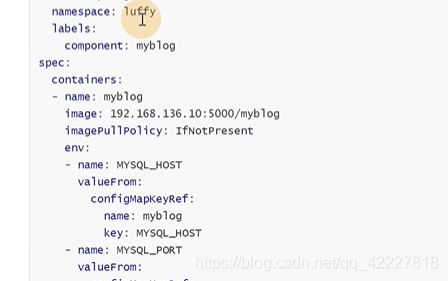
原来的env是key和value都能看,现在把配置写在了configmap,secret里


name是以前env里的key,value是从name叫myblog的configmap去引用源mysql_host的key

mysqluser就有点不一样了,就是从secret里引用
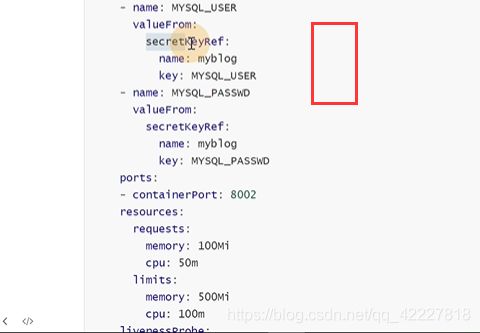

现在这个模板就可以不管什么环境都可以去部署了
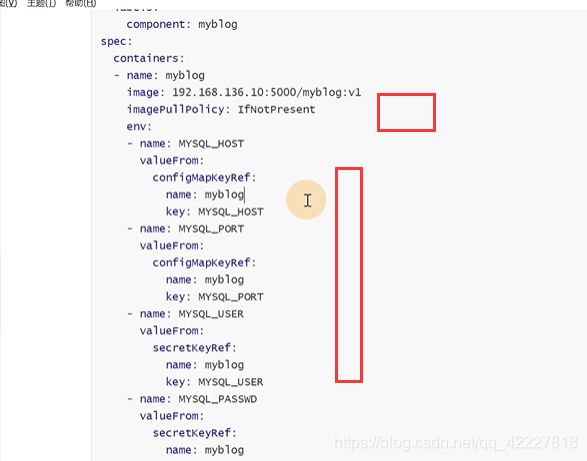


把旧的删除

创建新的




输入env查看变量

configmap和secret不能跨namespace使用,且更新后,pod内的env不会去更新

通过configmap和secret解决了变量的敏感信息带来的安全隐患


K8S默认就建立了很多namespace

可以直接拿它的来进行参考
这里更新了,kubelet会自动更新
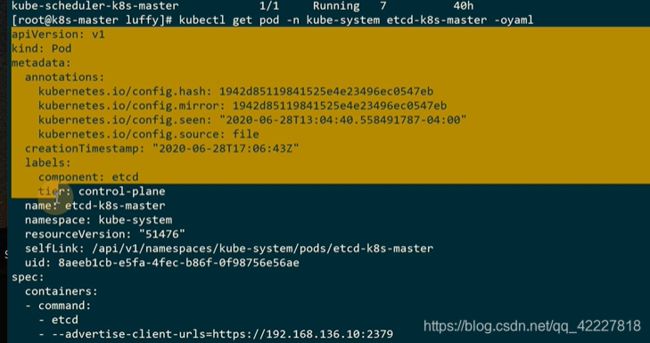
3.4 pod状态与生命周期

kubectl创建的时候,apiserver接收请求,至少一个容器启动,running,如果一个容器以非正常状态退出,进入failed,策略如果是onfailure,kubelet再杀掉,重新启动
一般是网络问题
![]()
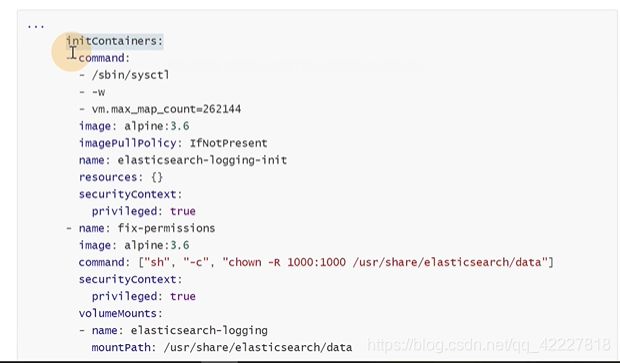
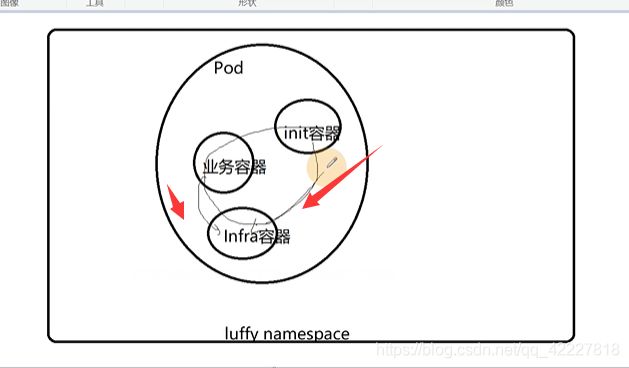
main是pod里主容器,一般是业务容器,infa是基础设施容器pause,init是pod的初始化容器

初始化容器的作用,验证业务依赖的组件是否正常启动。修改目录的权限(要求在容器内部有一定目录权限)

是和container一个级别的,可以定义多个初始化容器
第一个容器
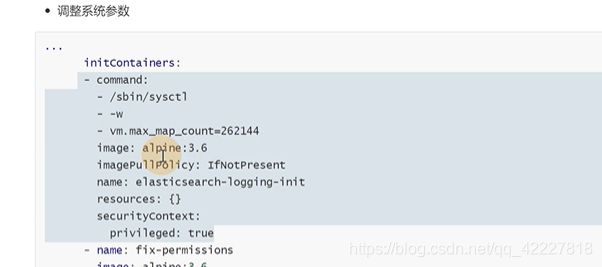 更新系统配置
更新系统配置

安全上下文
![]()
还有一个容器是fix-permissions,因为是用1000这个用户启动进程,如果不给目录1000的权限,可能会失败

这个目录一般是通过宿主机去挂载的,如果外部用的是root,可能挂载失败,没有权限,就需要fix-permissions把权限给它

main这个容器在启动的时候,还有生命周期,post start 启动后,pre stop停止前。类似关卡,一般容器运行main后,lieness和readiness做检测。
先启动初始化容器init,然后再去启动main容器
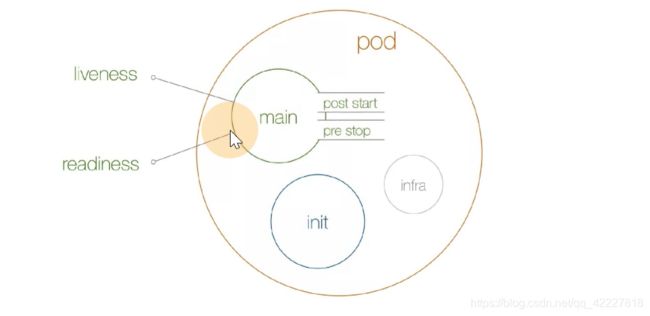
从0开始先执行init container,poststart 和maincontainer几乎同一时间运行,进行健康检查,然后停止前做操作


定义一个初始化容器
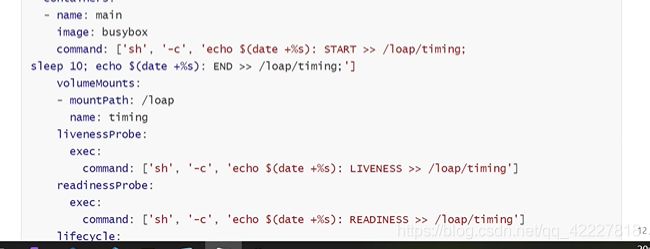

这里定义了本地路径挂载,把宿主机的tmp目录挂载到了容器的loap目录
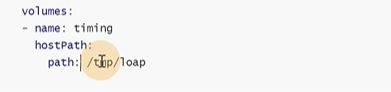
初始化容器往目录里写了数据

主容器

开始后,停止前是定义在lifecycle生命周期里的,和readinessprobe同级别

![]()

直接运行
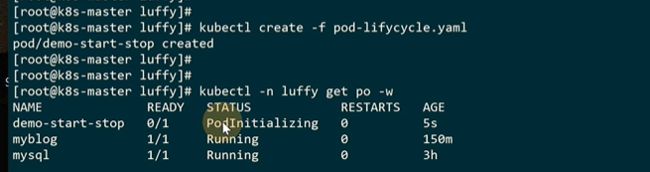
在slave1上

end之后重启了。是因为默认是always
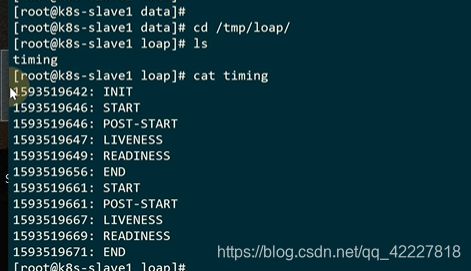
主动杀掉pod才会触发pre-stop

第4章 Pod控制器
4.1 使用Pod控制器管理Django应用
1.K8S为了与特定的容器进行解耦,引入了pod概念。
2.k8s使用yaml文件创建资源。
3.通过kubectl create|get|exec|logs|delete等操作K8S资源,必须指定namespce
4.每启动一个pod,为了实现网络空间共享,会先创建infra容器,并把其他容器网络加入该容器。
5.通过livenessprobe和readinessprobe去对容器的 存活性和就绪性做健康检查,livenessprobe主要是为了解决pod是否会不断的重启。readinness是关乎pod是否是ready,不ready,上层的 ingress controller会把流量断开。
6.request和limit限制资源
7.pod通过initcontainer和lifecycle分别来执行初始化、pod启动,删除时候的操作,使得功能更加全面和灵活。
8.编写yaml讲究方法,学习K8S,养成从官方网站查询 只是的习惯。

每个namespace都有一些资源,然后去定义pod,service,configmap

4.每启动一个pod,为了实现网络空间共享,会先创建infra容器,并把其他容器网络加入该容器。
他们两个加入infra容器,就可以通过127.0.0.1的来访问了

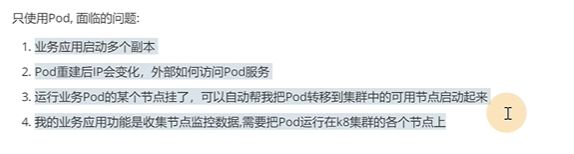
只用到pod吗,会面临一些问题:
1.业务应用启动多个副本,
2.pod重建后,ip变化,外部如何访问到pod服务
3.pod挂了,可以自动帮你把pod转移到集群中可用的节点启动起来
4.如果pod是收集节点的数据,需要运行在每个节点上

工作负载是管理pod的中间层,确保pod资源符合预期的状态,pod出现问题,会尝试重启,重启无效,会新建pod
**replicat是代替用户创建指定 数量的pod。
deployment是在repicaset之上的,用于管理无状态的应用,比如nginx,跑到哪里都可以。
daemonset确保集群中的每一个节点只运行特定的pod副本,通常能够用于实现系统级后台的任务。比如EFK服务。
job只要完成就立即退出,不需要重启或重建。
cronjob 周期性任务控制,不需要持续后台运行。
statefulset 管理有状态的应用,集群服务,es集群,zk集群,这样的每个集群里的节点都需要通信,节点之间还需要hostname命名要求的。
**

deployment是目前使用最多的副本控制器
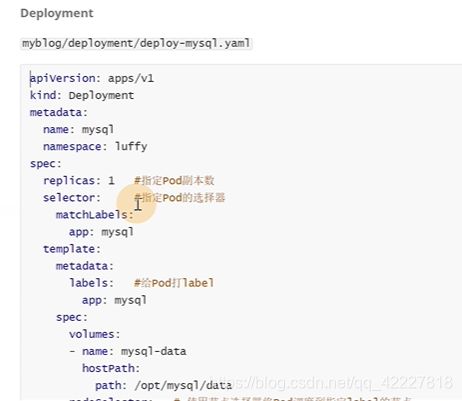


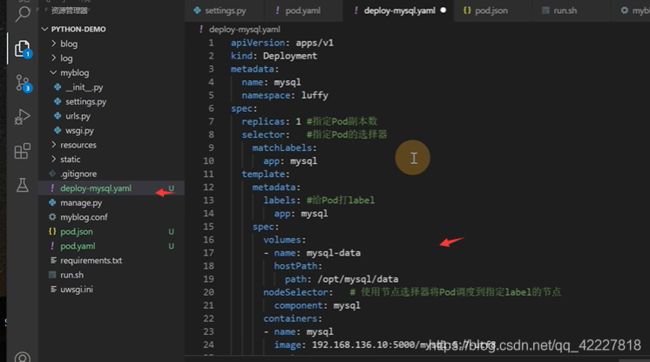
metadata一般 定义名字,名称空间,label标签

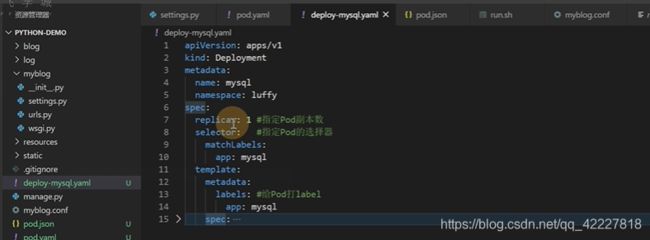
replicas期望的副本数
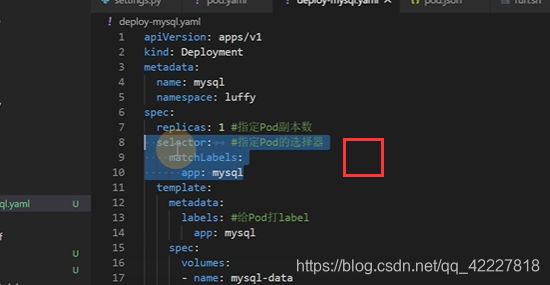
selector选择器,选择匹配标签是app=mysql的pod
模板理由metadata,,这都是固定的格式
上面是给deployment打label,下面是给pod打label,

10行和14行,这两个标签不一样会匹配不到,应该是一样的

现在定义了一个deployment,里面去管理了一个pod,找matchlabels,app=mysql的一个pod,正好在template里定义了一个app=mysql的pod
下面都是pod的定义

在yaml文件格式上也可以看到,是管理pod上层的pod控制器

![]()
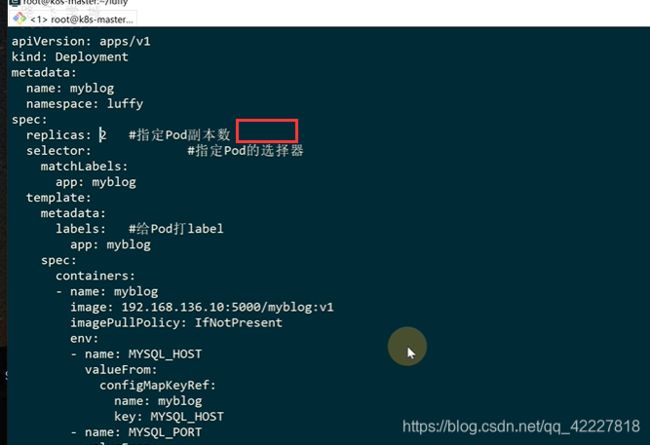
myblog的deployment




![]()



创建myblog


deployment下的两个pod

进入容器初始化数据库
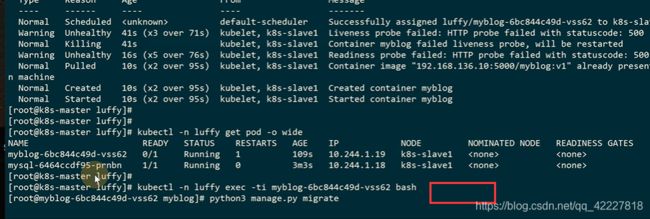
链接不上数据库

要用host模式,先把原来的删除

![]()

![]()
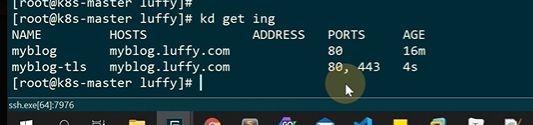
现在已经ready了



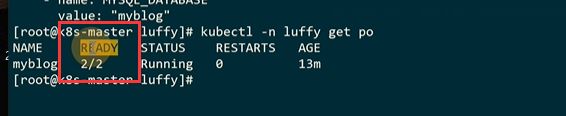
**创建deployment的时候,会创建replicas,会保证一个副本的数量 **

前面是replicas,后面是deployment

查看一下api-resources


删掉一个pod,查看副本控制器会如何管理

pod会重建一个

scale是伸缩一个资源,这个资源是deployment,–replicas副本数


现在数量就是2个了

pod驱逐eviction,某些 节点失联,会把pod驱逐到其他节点上

默认5分钟,kubecrotroller-manager会去检查节点是否ready,不ready会把pod调度到其他节点上


不想要默认5分钟,把这个参数定义到上面的yaml文件即可
![]()
节点如果内存不足也会驱逐其他pod

跟盘至少保持80%以上的容量
![]()
4.2 实现Django应用的滚动更新与服务回滚
deployment管理pod

现在只有一个版本叫v1


现在做一个v2版本

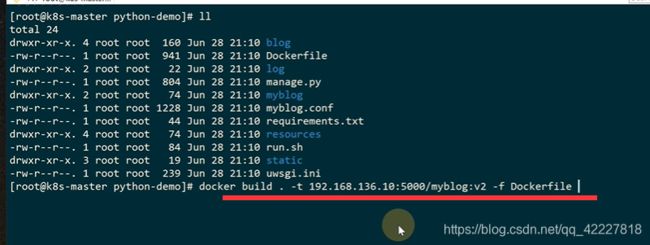
如果是给pod更新,那么直接更改镜像版本就行
这是第一种方式
![]()
在线编辑


现在用的是v1版本


这里改成v2版本

保存以后会自动更新

新启动一个,杀掉一个
也可以通过给deployment设置镜像

deployment后面的名字就是这里的name


如果不标注会有默认的策略

![]()
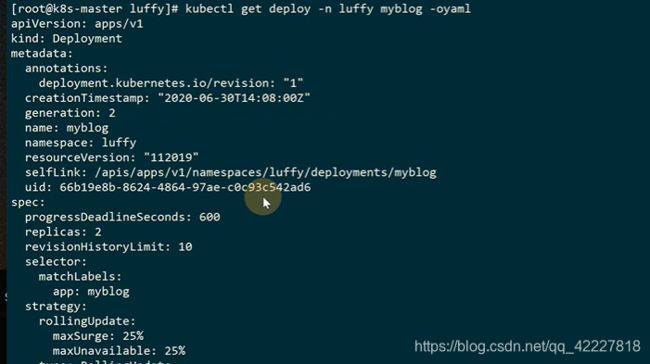
后面的这一串,其实就是hash整个deploy yaml文件得出来的

目标是从v1版本升级到v2版本,通过rs去逐步过度的过程

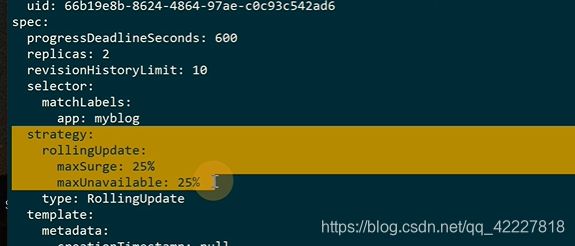
maxsurge最大激增数
maxunavailable最大可用数
![]()
maxsurge,在更新过程中,最多可以比预先设定 值多出几个pod数量,向上取整,5个+5*0.25=6.3,=7个

K8S整个更新过程中,最大副本数不能超过2+2*0.25=3


第一步,类似这样的情况,之前2 个还在,新启动一个新版本的

不能少于两个pod,在更新的时候,旧的保持不动,等新的ready,再把旧的删除


新启动一个pod,把老的下掉

K8S提供了自己的一套revision回滚机制


现在有两个版本

删掉deploy
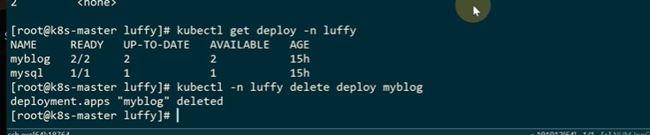

再去创建

第一次创建

![]()
在更新中
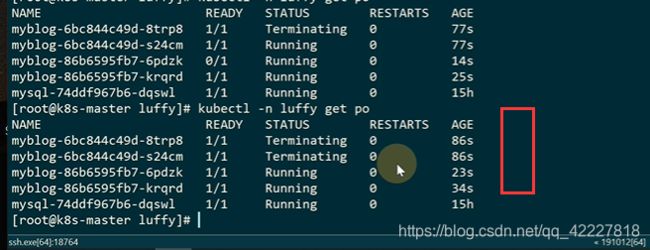
现在就是两个版本

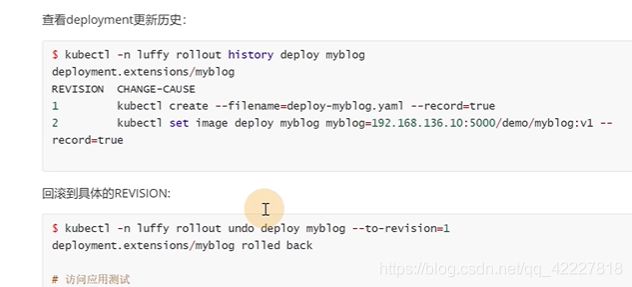
现在是v2版本


也是异步更新


现在就回到了v1版本了

第5章 负载均衡与服务发现
5.1 负载均衡与服务发现实现原理

不在K8S及群里,访问这个是不通的

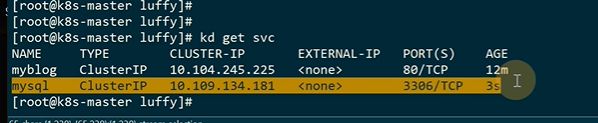
这是一个service的yaml

上面service的80端口转发到下面pod的8002端口
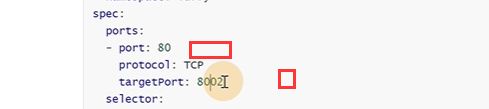
跟deployment一样,service也是有选择器的,找所有app=myblog的pod


现在label是app=myblog,后面是对应的rs出来的哈希值




现在就有service了

查看这个ip地址反代了哪些pod
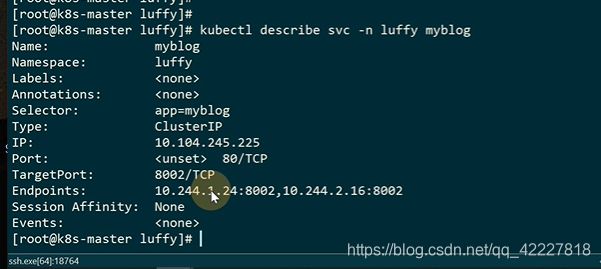
只要-l有数据,就会加到enpoint

可以加别名,避免一直敲

![]()

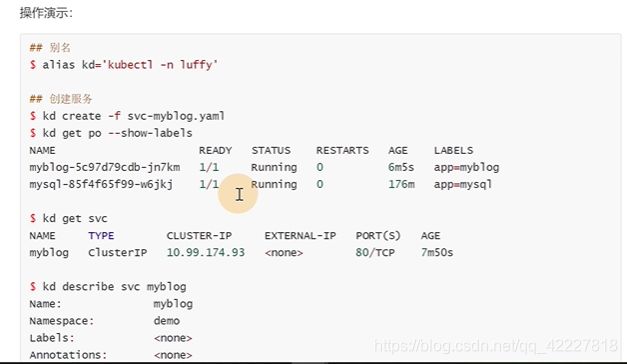
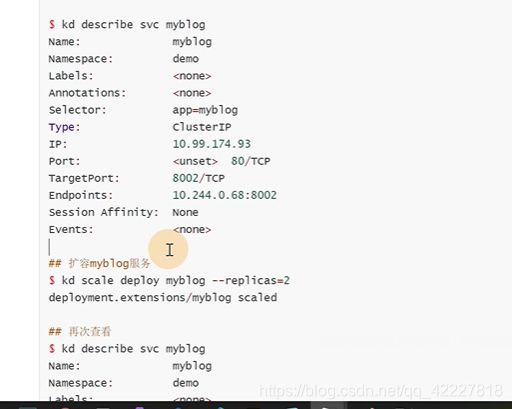
删掉的话会立即创建一个pod,ip地址就会改变

这里K8S强制删除,就不会等待docker指令,就直接操作etcd数据库把数据删除




K8S创建svc的时候,就会去创建同名的endpoints,也可以称为ep,endpoint-controller会控制流量的转发,如果pod健康就绪性检查没过,endpoint-controller会把pod删除
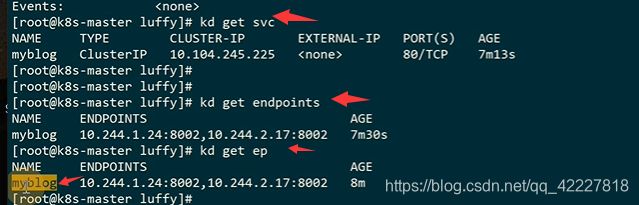
从上层的cluster ip反代到 下面的pod ip
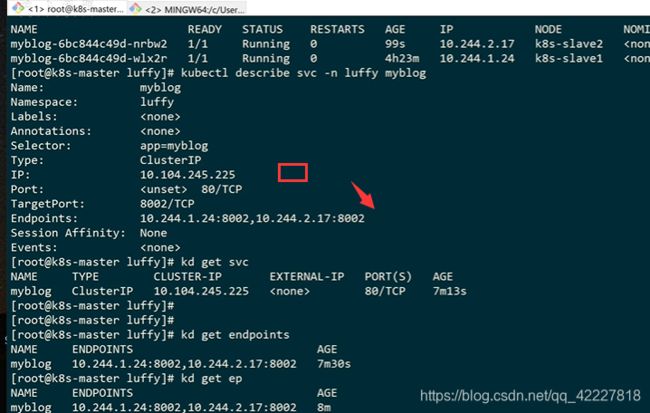

访问上层的cluster ip
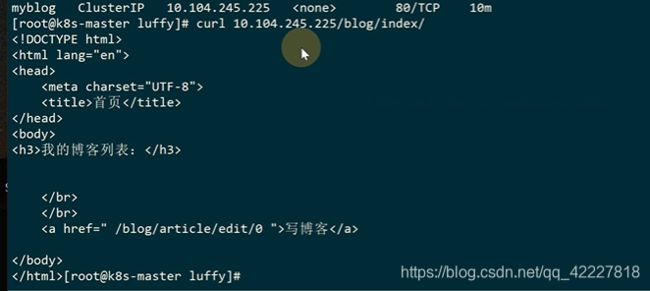
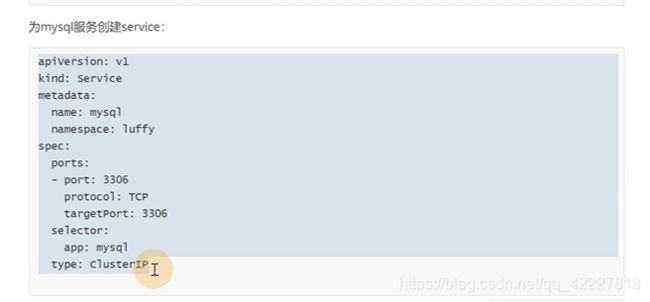
给mysql也创建service



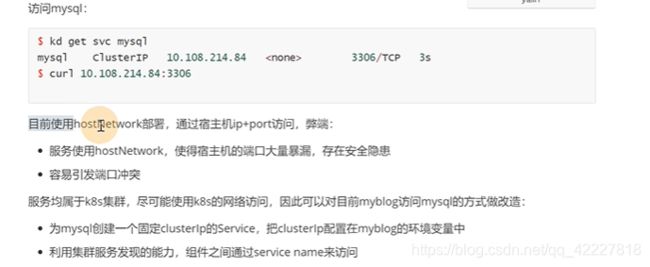
使用hostnetwork,有可能引发宿主机端口冲突


这样等于写死了ip,不是最终j解决方案
![]()
利用servicename来访问
![]()
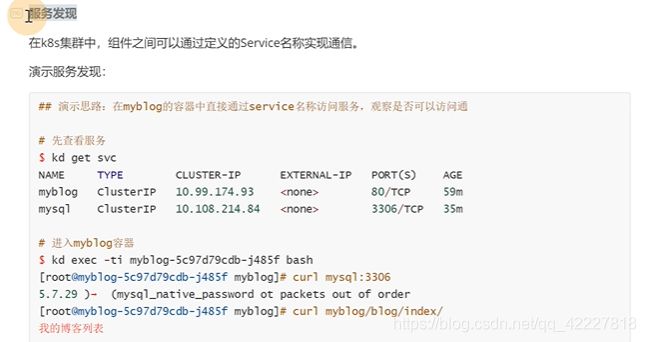

这样是可以访问到的

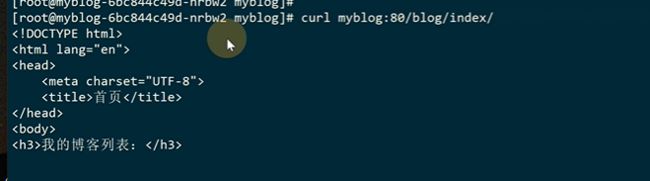
这样就可以实现去ip化,方便迁移
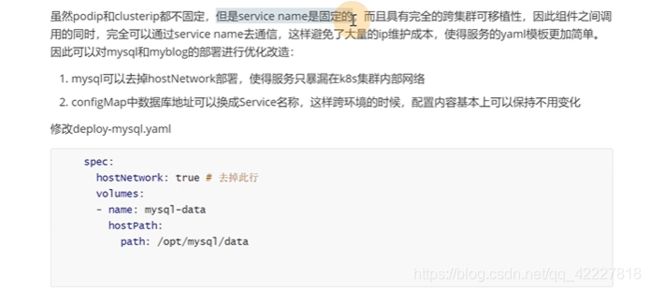
原来这里的ip地址,换成mysql


删掉这一行
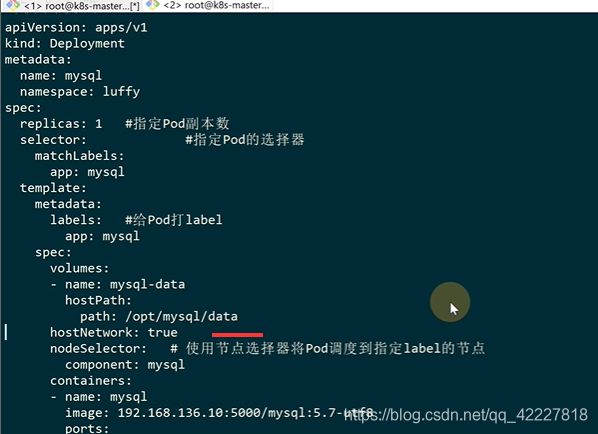
删掉重新 创建

修改configmap

需要加双引号

mysql新启动了pod,但是myblogready是0了

现在就已经切换

重启了一次拿到最新的configmap数据

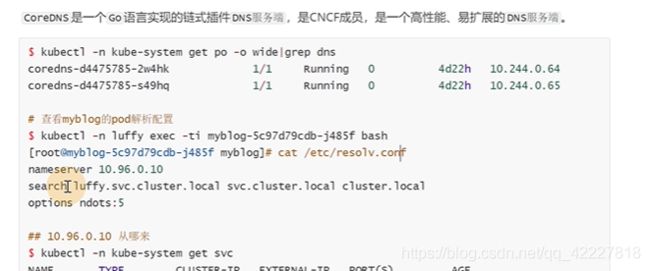
为什么可以通过servicename去访问,肯定有对应的dns服务器去做解析,coredns

系统相关的组件都在kube-system里
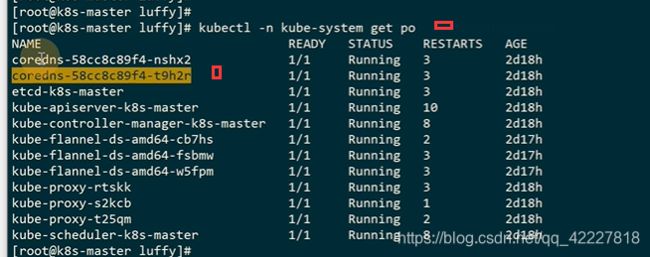
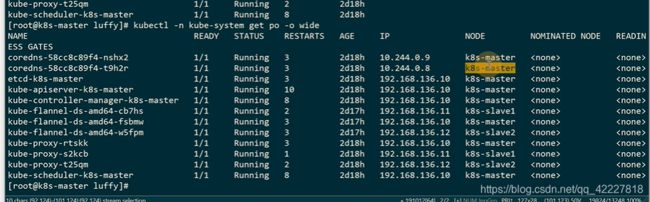
查看容器里的dns服务,这个ip从哪来

这里有一个kube-dns 的service,只要是kubeadm安装的,会固定10.96.0.10这ip,容器启动会把dns配置注入到容器里作为dns解析

还有一个搜索域

mysql因为匹配到了上面的搜索域才能被访问到,这也是为什么直接访问mysql短名也能被访问到的原因

这是namespace

这样可以完成一跨域的访问
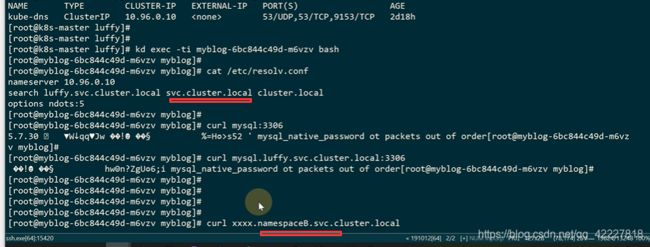
default的namespace里有一个kuberbetes的一条服务,这个也是K8s初始化安装的时候的service

clusterip可以通过宿主机直接访问,-k不带证书访问,默认 访问K8S服务组件是要带证书的

假如从luffy的名称空间里去访问default的,在这样实现了跨namespace访问
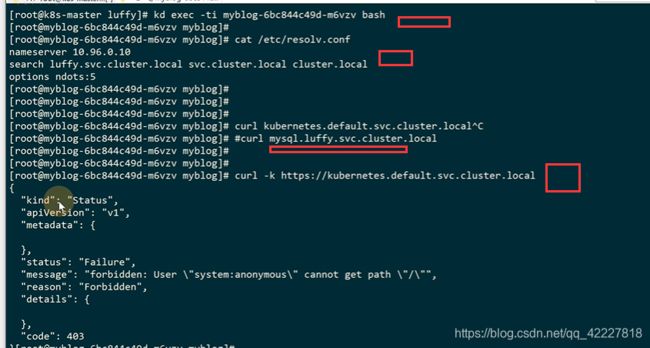

之前把mysql服务从host模式,改成了service,configmap把ip也去掉了,但是现在还不能 通过浏览器去访问
service有一种类型是clusterip 还有一种是nodeport,端口是30000到32767

![]()
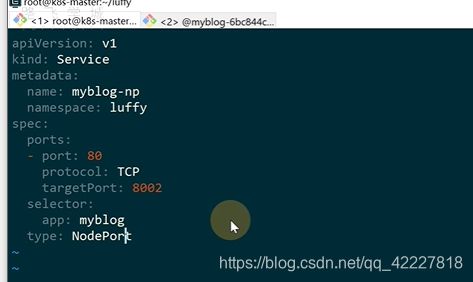

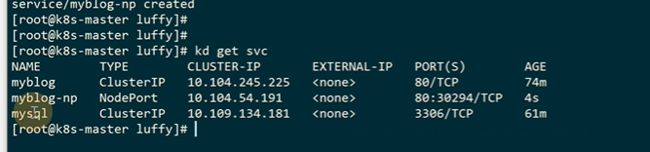
通过30294端口可以从外部访问

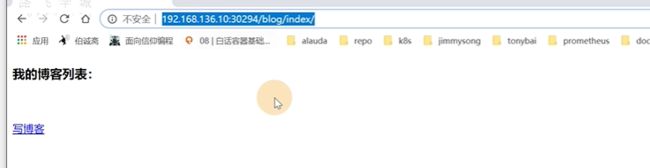
其他宿主机ip也可以

nodeport是集群里的每个节点都会监听

kube-proxy是agent运行在每个节点上,每个节点都会去部署应用
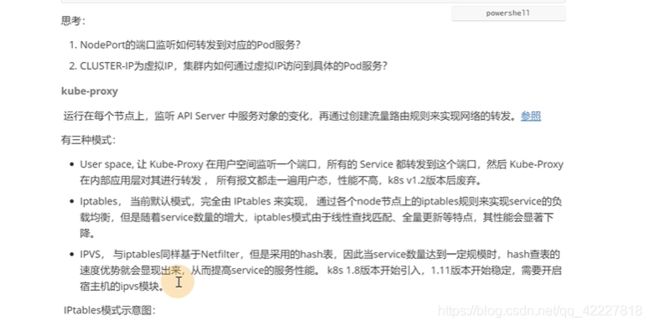
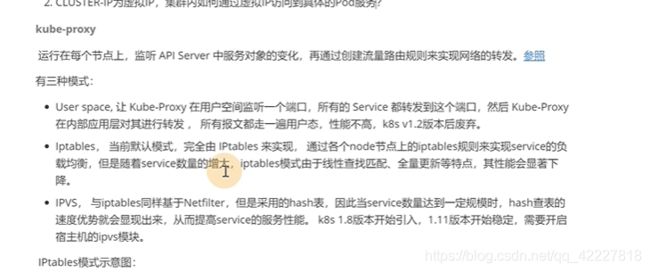
有三种模式

用户空间的,让kube-proxy在用户空间监听一个端口,所有的service转到这个端口,kube-proxy对其转发,所有报文都从一遍用户态,性能不高

不给kube-proxy指定,就会使用 iptables模式,用iptables来实现把流量转发到具体pod的规则

ipvs同样基于内核的netilter,但是采用哈希表,数量达到一定不过规模的时候,速度有优势,K8S1。18来引入,需要开启宿主机的ipvs模块


kube-proxy去针对一系列ptables规则去转发到pod,所以kube-proxy是daemonset服务,每个节点都需要
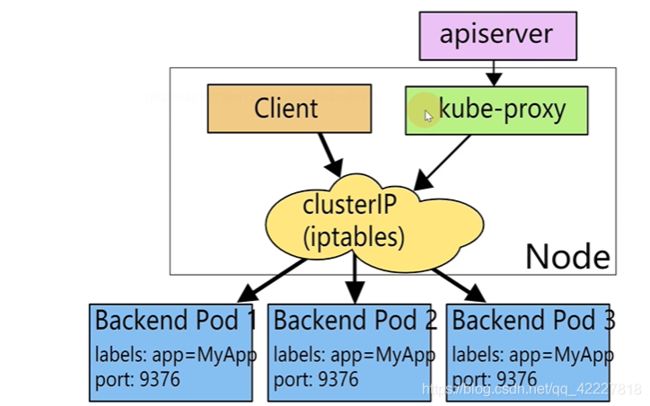
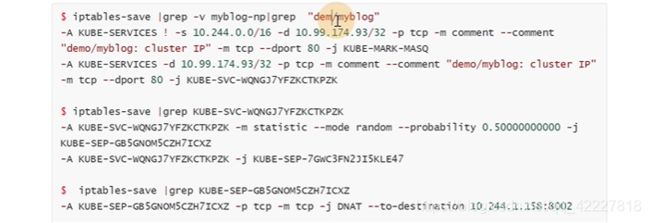
但是没看到具体往哪里pod转发的规则

random随机模式 0–probability可能性,有0.5的几率转发到KUBE-SVC-4RG7UZRJ,剩下的转发到另外一个

这个地址是clusterip,所有往这里去的流量转发到KUBE-SVC-4RG7UZRJ

dnat是目标地址转换
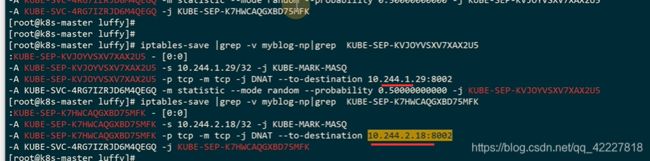
总结起来i就是访问clusterip的流量,有50%的纪律访问10.244.1.29,剩下的访问18上

也就是kube-proxy用iptables来实现流量转发,也就是通过 ipables的规则来实现一个lb,nodeport其实也跟clusterip一样

通过kubeproxy调用iptables规则,也就是内核的netfilter,来做一个lb

iptables加iptables规则,ipvs加ipvs规则

pod的ip需要前面的上层的lb自动更新,才有service概念
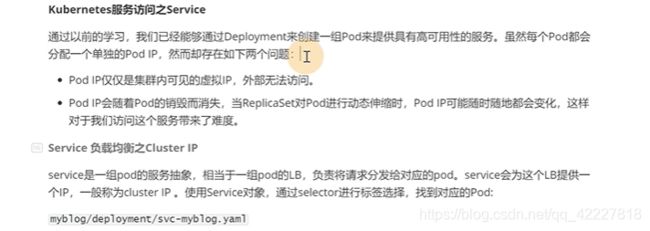
利用服务发现能力,通过组件之间的servicename来访问

pod启动的时候把dns注入到容器里
service没法通过集群外部访问,nodeport就可以实现让外部机器访问
为什么clusterip和nodeport可以转发到内部服务,就是因为kube-proxy
第6章 Ingerss实现七层原理
6.1 通过ingress实现业务应用7层代理
K8S的service,clusterip和nodePort都是4层负载。实现7层的负载就需要ingress。
ingress控制器,外部的流量通过7层转发到集群内部的组件,ingress是一个统称,实现有很多,nginx,countour,haproxy,trafik,istio。
现在用nginx,trafik,istio比较多
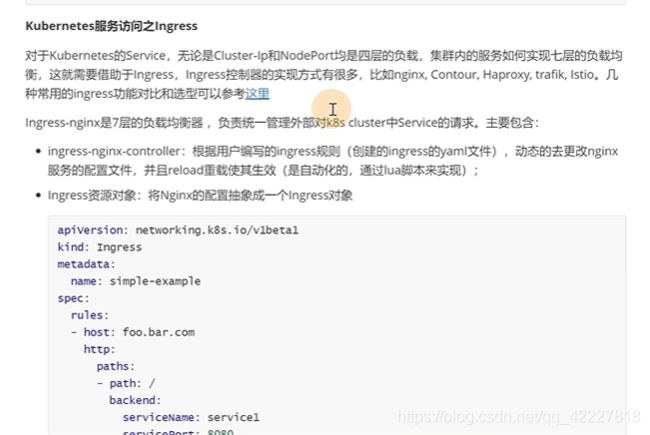

**这个控制组件是在K8S里用pod方式运行的,这个pod就会根据用户写的ingress规则,这个规则就对应ingress yaml文件。ingress是K8S里,新的resources,controller控制器去通过apiserver动态的查询ingress定义的文件,转换成nginx配置文件,通过reload方式让nginx生效 **

ingress对象,就是把nginx的配置抽象成了imgress资源
![]()
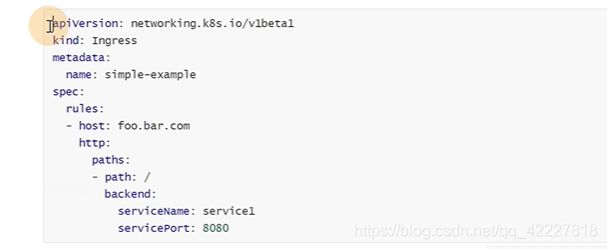
rules里是个数组,里面定义path,通过哪个域名去访问
可以直接配置servicename去访问

port是前面port
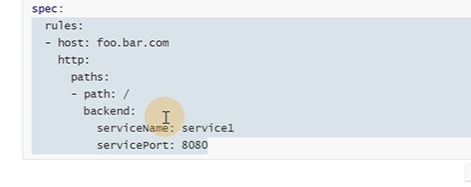
外部访问K8S集群服务,首先从ingress域名tea.foo.bar.com,下面的service知道访问哪些pod(通过abel selector)

实现逻辑
1.ingress controller去通过apiserver交互,动态感知ingress规则变化
2.读取ingress规则,按照规则,生成nginx配置
3.生成以后,写入到nginx-ingress-controller(等于一个nginx服务),nginx-ingress-controller写入到nginx.conf
4.最后reload

安装ingress-controler


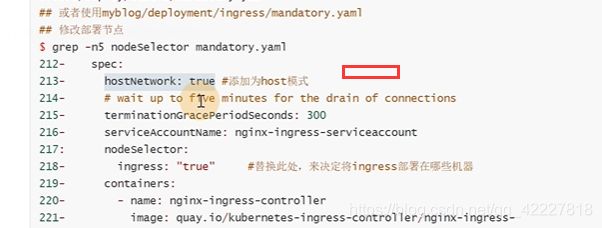
修改部署节点
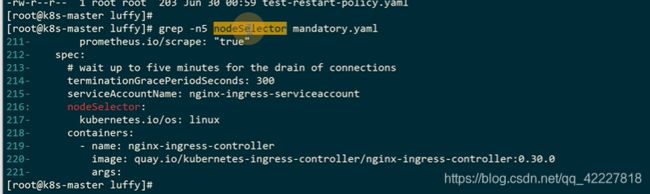
默认是这样一个label
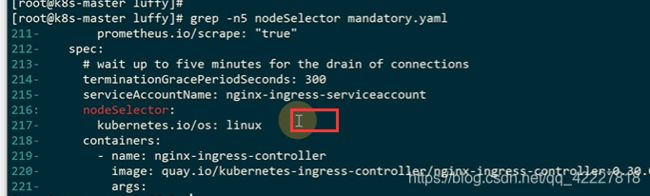

改成ingress=true

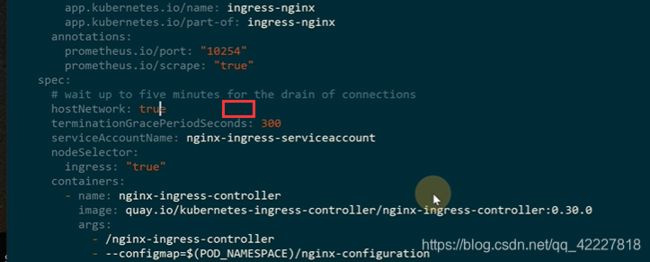
加一个hostnetwork
创建了一系列资源
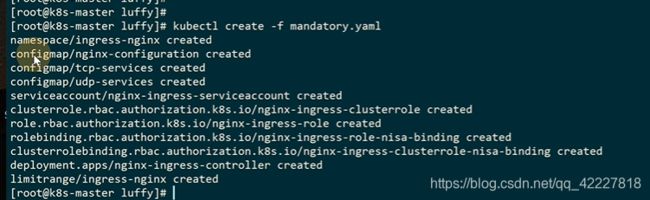
和ingress相关的资源都放在ingress-nginx这个名称空间里
![]()
controller也是用deployment,是workload使用范围最广的一个
![]()
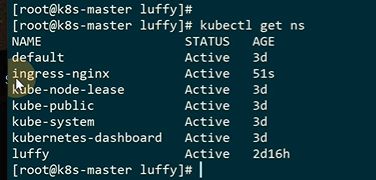


如果现在要通过ingres访问到myblog应用的时候该如何去做




之前的ingress=true已经打在K8S-Master上了,所以之前的pod调度成功了,不然iu是pendding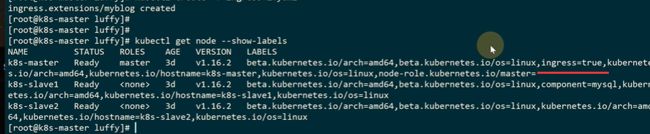
只要执行这个命令,节点上就打上标记了


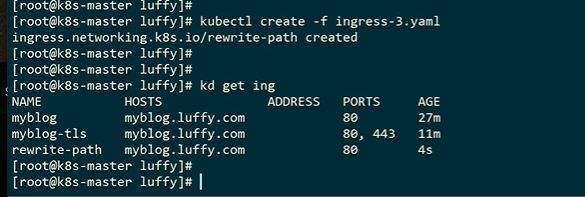
可以查看ingress

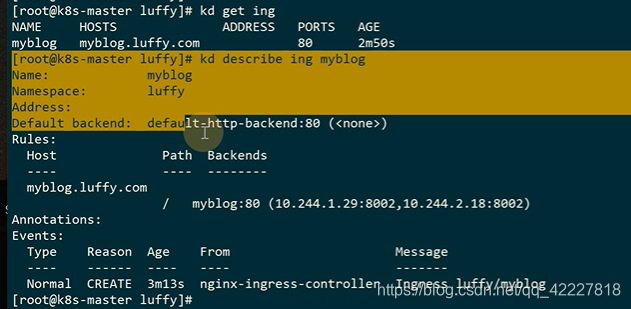
这是两个endpoint
![]()
ingress会去动态生成upstrem的配置,查看nginx的配置
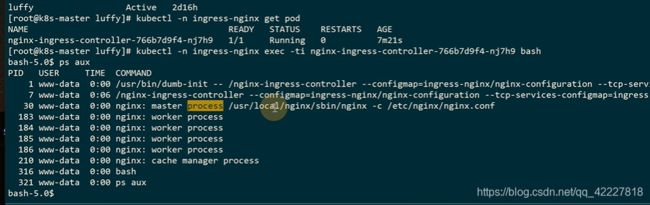
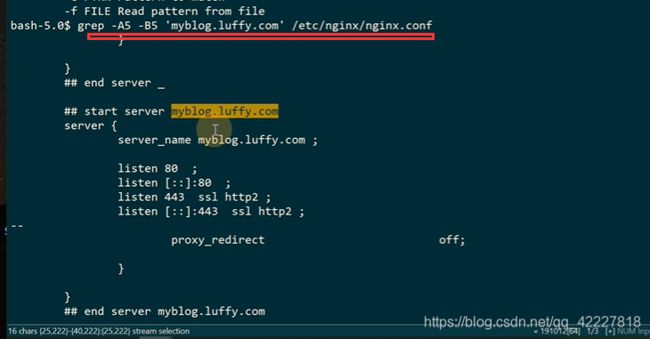
生成的配置文件还是很多的
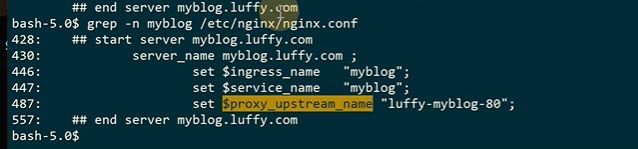
这里加上hostnetwork=true,宿主机的端口80就被监听了

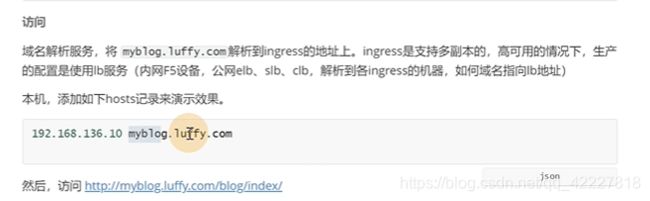
ingess是运行在10节点上

生产环境一般用lb

修改本机hosts

如果要https的,可以先自己自签名

crt就是一个证书文件,key就是私钥


secret就是来存储一些敏感信息
![]()
指定一下secretname即可

![]()


这里就多监听 了一个443
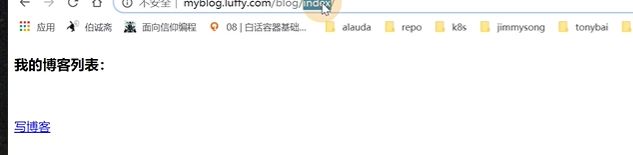
现在就可以了

多路径如何去实现
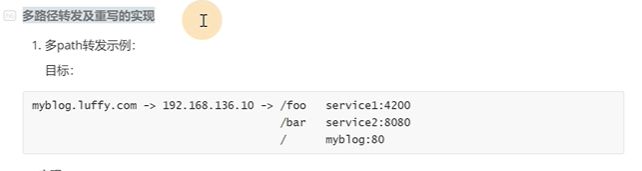

/跟一定要放在最后
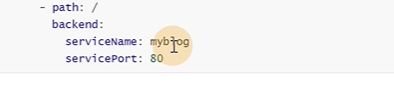
![]()


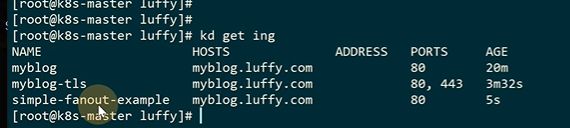
这样就实现 了多个转发
删除

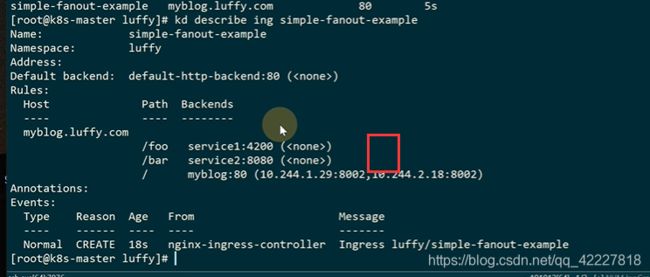
nginx url 重写

直接访问是这样的,admin这个路径是原样转发到后面的路径
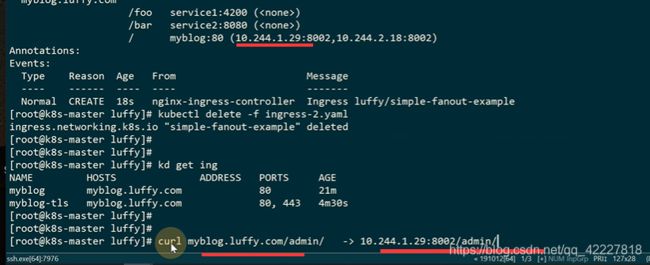
如果想要实现url这样重写

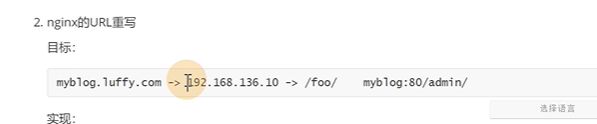
加了一个申明,rewrite-target重写的目标

![]()
![]()
name是rewrite-path
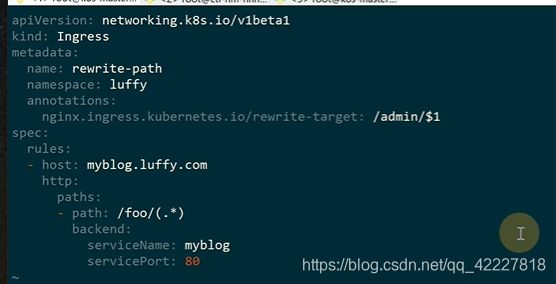
foo这个规则转发到admin,$1就是括号匹配到的

![]()
访问fooo转发到admin里

![]()
配置一下解析

先转到这个地址


转到了这个路径上

重写的不能和 默认 的ingress放在一起,只要是写了rewrite之后,是针对下面所有配置生效的,要实现规则,要保留两个ingress的数,一个是原生的,一个是针对重写的

第7章 小结
6.1 通过ingress实现业务应用7层代理
kubeadm有两个核心的命令,init,join

kube-proxy是daemon-set的组件,利用iptablees或者ipvs实现了防火墙

configmap存储一些基础 的数据,kv,secret去存储敏感数据,密码,证书
![]()
工作负载,还有daemonset,statsflust有状态服务(es,redis集群),conjob
![]()
去ip化,方便迁移

inges-controller调用apiserver拿到ingress配置转换成了nginx配置,controller里运行了一个nginx服务,动态reload
![]()