面经 | Java 基础 整理
文章目录
- Java 基础
-
- 一、整体观/理论/概念
-
- JDK和JRE的区别
- Java 为什么可以一次编写、到处运行?
- java运行快吗 是编译还是解释型语言
- 什么是API
- import java 和javax的区别
- 重写和重载的区别
- 面向对象和面向过程的区别
- 面向对象的三大特性: 封装 继承 多态
- 向上/向下转型
- 都有常量了为什么还要有枚举?
- 构造器 Constructor 是否可被 override
- 构造方法是什么
- 一个类没有声明构造方法,该程序能正确执行吗
- 构造方法的特性
- 调用子类构造方法之前,会先调用父类无参构造方法,其目的是?
- 在Java中定义一个不做事的构造方法的作用
- 基本数据类型和引用类型的区别
- heap和stack的区别
- Java 反射
- Java的序列化 vs 反序列化
- 什么时候需要序列化
- Java 序列化中如果有些字段不想进行序列化 怎么办
- Java和C++的区别
- 一、对象拷贝
-
- 什么是克隆
- 如何实现对象克隆
- 深拷贝 vs 浅拷贝
- 二、语法
-
- 引用传递和值传递
- 为什么Java只有值传递
- == 和equals的区别
- 对象的相等 vs 指向他们的引用相等
- 两个对象hashCode()相同,equals()一定为true吗
- 排序
-
- Collections.sort 和 Arrays.sort的区别
- final
- static
-
- 在一个静态方法内调用一个非静态成员为什么是非法的
- 静态方法和实例方法的区别
- 内部类
- 成员变量和局部变量的区别
- 如何创建对象
- 对象实体与对象引用的区别
- 返回值在类的方法里的作用
- Stream
-
-
- 2.32 Stream有哪些方法
-
- Math函数常用的方法
- BigDecimal对象
-
- 1)浮点数的计算
- 2)除法除不尽导致的无穷小数问题
- 3)BigDecimal的比较
- 获取键盘输入的方法
- System.out用法和要注意的点
- switch 和 if-else的区别
- 三、Java的数据类型
-
-
-
- 基本数据类型
- int 类型的数据范围
- 实例变量的默认值
-
-
- 四、字符串:String & StringBuilder & StringBuffer
-
-
- String属于基础数据类型吗?
- Java中操作字符串都有哪些类,它们都有哪些区别
-
- 1)可变性
- 2)线程安全
- 3)性能
- String str = "i";和String str = new String("i");的区别
- 字符串反转
- String类常用的方法
- char和String的区别字符型常量和字符串常量的区别
-
- 五、抽象类
-
- 抽象类和接口的区别
- 抽象类必须要有抽象方法吗
- 普通类和抽象类的区别
- 抽象类能用final修饰吗
- 六、集合类
-
- 概念
-
- 集合类的基本接口
- Collection 和 Collections 的区别
- Comparable 和 Comparator 接口是干什么的?列出它们的区别。
-
- 集合类为什么没有实现Clonable和Serializable接口
- 什么是迭代器Iterator
- Iterator怎么使用,有什么特点
-
- Iterator和ListIterator的区别
- 如何确保集合不被修改
- Java有哪些集合类
- List、Map、Set 三个接口,存取元素时,各有什么特点?
- 线程安全/不安全的集合类
- 自动装箱、自动拆箱
- 为什么要有包装类
- 包装类+缓存池
- Integer 和 Double类型要怎么判断相等
- int 和Integer有什么区别,二者在做 == 运算的时候会有什么结果?过程?
- 六-1、List
-
- 普通List
-
- List和Set有什么区别?
- ArrayList
-
- 介绍一下ArrayList的数据结构
- Array和ArrayList的区别
- ArrayList和LinkedList的区别
- ArrayList 和 Vector 的区别
- ArrayList,Vector,LinkedList 的存储性能和特性
- 六-2、Set
-
- Set那么用什么方法来区分重复与否呢
- 两个对象的内容相等,hashCode一定相等吗?
- HashSet
-
- HashSet的底层逻辑
- HashSet和TreeSet的区别
- TreeSet
-
- 原理
- 说一说TreeSet和HashSet的区别
- 六-3、Queue
-
- Queue大家族
-
- Dueue
- BlockingQueue
- AbstractQueue
- 常用方法
-
- add() offer() 插入
- element() peek() 获取值
- remove() poll() 删除
- 普通Queue
- BlockingQueue
-
- 2.30 BlockingQueue 有哪些方法,为什么这样设计
- 2.31 BlockingQueue 是怎么实现的
- 六-4、Map
-
- 1. 普通Map
-
- Map接口有哪些实现类
- Map put的过程
- 如何得到一个线程安全的Map
- Map和Set有什么区别?
- 2. HashMap(重点)
-
- HashMap put的过程(1.7 和1.8的区别)
- HashMap有哪些特点
- JDK7、JDK8实现的HashMap有什么区别
- HashMap 的底层实现原理
- HashMap 的扩容机制
- HashMap为什么用红黑树而不用B树?
- HashMap hash函数设计思想
- HashMap是如何解决哈希冲突的?
- HashMap的底层结构
- 链表是如何转成红黑树的
- 为什么要用红黑树
- HashMap 1.7中多线程的死循环的产生
- HashMap和HashTable的区别
- HashMap和ConcurrentHashMap的区别
-
- ConcurrentHashMap是怎么实现的
- 3. LinkedHashMap
-
- 使用场景
- 你对LinkedHashMap的理解
- 请介绍LinkedHashMap的底层原理
- 4. TreeMap
-
- 2.21 TreeMap的底层逻辑
- 什么是==红黑树==
- 七、异常
-
- Throwable异常类
-
- 总述
- 常见的异常类
- Throwable常用方法
- throw和throws的方法
- 异常处理
-
- try-catch-finally
- try-catch-finally那部分可以省略
- 如果在catch中return了,finally还会执行吗
- final、finally、finalize的区别
-
- final
- finally
- finalize
- 八、JVM
-
- JVM的结构
-
- JVM包含哪几部分
- 5.6 Java内存分布情况
- 5.4 本地方法栈有什么用
- 5.7 类存放在哪里
- 5.5 没有程序计数器PC会怎样
- 5.8 局部变量存放在哪里
- 5.9 Java代码编译过程
- 5.11 对象实例化的过程
- 5.12 元空间在栈内还是栈外
- 类加载器
-
- 对JVM类加载器的理解
- 双亲委派模型
-
- 5.14 双亲委派机制会被破坏吗?
- 垃圾回收
-
- 1. Java的垃圾回收机制
-
- 1)发生在哪里
- 2)什么时候可以被回收
- 3)确定一个对象是否可以被回收:
- 4)垃圾回收算法
- 2. 分代回收 GC
- IO流
-
-
-
- 3.1 介绍一下Java中的IO流
- 3.2 怎么用流打开一个大文件
-
-
- 其他
-
-
-
- 1.2 Java 文件可以有多个类吗
- 1.3 你对Java 访问权限的了解
- 1. 成员变量(全局变量)和局部变量的区别
-
-
Java 基础
一、整体观/理论/概念
JDK和JRE的区别
答:jdk是开发工具,给开发者用的;jre是运行时环境,用来运行java程序的;如果你需要编写java程序,需要安装JDK。如果你需要运行java程序,只需要安装JRE就可以了。
JDK包含JRE包含JVM
JDK: Java development kit Java 开发工具
JRE: Java runtime environment Java运行是环境
JDK包含JRE,JRE包含JVM,安装Eclipse你会发现它是运行不起来 是会报错的,只有安装了JDK,配置好了环境变量和path才可以运行成功。
【参考】
- 参考1
- 参考2
Java 为什么可以一次编写、到处运行?
运行过程:Java文件经过编译的.class的字节码文件,Java虚拟机JVM 再把字节码文件翻译成机器码,计算机再执行这个机器码,Java程序就得到运行了。
到处运行:靠的是jvm,不同平台下的jvm是不同的,但他们都能运行这个相同的字节码文件,Java 虚拟机再把这个字节码文件->当前平台下的机器码,java文件就可以实现到处运行。
java运行快吗 是编译还是解释型语言
JVM在执行字节码文件时,是读一行执行一行的,所以是解释型语言;
解释型语言运行得都比较慢。
【参考】
什么是API
其实就是被人写好的可以实现某种特定功能的函数,开发者只需要调用它提供的接口,然后传入它规定的参数,这个函数就会实现相应的功能。
import java 和javax的区别
一开始javax是对JavaAPI的扩展,后来也逐渐把这些扩展移到了java下面,所以现在可以说java包和javax是没有区别的
重写和重载的区别
重写:override 重载:overload
重载: 发生在同一个类中,比如写构造函数的时候一般会写无参构造方法和有参构造方法,方法名必须相同,参数列表不同(类型不同、个数不同、顺序),方法返回值也可以不同。
重写: 发生在父子类中,子类重写父类的方法,方法名、参数列表必须相同(返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类)如果父类
方法访问修饰符为 private 则子类就不能重写该方法。
面向对象和面向过程的区别
- 面向过程:性能比较高,不需要实例化,开销比较小;但没有对象易维护、易复用、易扩展
- 面向对象: 易维护、易复用、易扩展,封装、继承、多态可以降低系统的耦合度,使系统更加灵活、更加易于维护; 性能比面向过程低
面向对象的三大特性: 封装 继承 多态
1. 封装:将类的某些属性、信息封装在类的内部,不允许外部直接访问,而是通过类提供的方法来对类内部的信息进行访问或操作。
2. 继承:子类继承父类,是一种is-a的关系,子类继承到父类属性和方法,在父类基础上进行拓展,添加新的属性和方法,也可以重写父类的方法(父类的private属性和方法、构造方法不能被重写)
has-a:用来判断类与成员的关系,即类拥有某种属性或某种方法
3. 多态:对于同一个方法,不同的参数列表、不同的参数类型传进来可以有不同的处理方式,主要体现在继承和重载
继承:在继承的时候,一个父类可能有多个子类,子类A和子类B都重写了父类的同一个方法,但是子类AB的对象在调用这个方法的时候,都会根据当前子类重写的逻辑来处理,这就是多态。(多态也可以通过接口这种形式实现)
重载:在同一个类里,同一个方法名,不同的参数传进来,会有不同的处理方式,这就是重载;
多态的一种体现就是,你只定义了一个方法和一个参数类型,但却可以处理多种形态的参数,这就是多态。
多态比较难理解
向上/向下转型
向上:将子类对象赋值给父类对象(父类引用指向子类对象),在日常开发中我们大量使用向上转型,这样会充分发挥多态的特性
向下:将父类对象赋值给子类对象,这个是否需要强制类型转换,否则会编译报错(编译通过了也不一定能正确执行)
都有常量了为什么还要有枚举?
关键字:enum,调用时和静态常量一样,它能够更好地限定语义和判断每个值的合理性,它把值限定在了这几个值的范围之内,如果超出了这几个值的范围,在编译的时候就会报错,就能更好地检查每个值的合理性。
构造器 Constructor 是否可被 override
不可以
构造方法是什么
对对象进行初始化
一个类没有声明构造方法,该程序能正确执行吗
可以。会默认执行无参构造方法。
构造方法的特性
1.与类名相同,可以有无参和有参构造方法
2. 没有返回值,但不能用 void 声明构造函数;
3. 生成类的对象时自动执行,无需调用。
调用子类构造方法之前,会先调用父类无参构造方法,其目的是?
帮助子类做初始化工作
在Java中定义一个不做事的构造方法的作用
子类的对象在构造之前,如果没有用 super() 来调用父类特定的构造方法,则会先调用父类的无参构造方法。这个时候,如果父类中没有无参构造方法,那编译就会发生错误。
基本数据类型和引用类型的区别
- 基本:8种
- 引用类型:是指由多个值构成的对象
heap和stack的区别
- heap:堆内存,存对象
- stack:栈内存,存方法内的局部变量
Java 反射
Java的反射是Java能够动态获取信息、动态调用对象方法的一种机制。
在运行状态中,对于任何一个类,都能知道这个类的所有属性和方法;对于任意一个对象,都能调用它的任意方法和属性
Java的序列化 vs 反序列化
- 序列化:将java对象转换为字节流的过程
- 反序列化:将字节流转换为java对象的过程
什么时候需要序列化
Java对象在以下情况下需要
- 在网络上传输
- 持久化存储
Java 序列化中如果有些字段不想进行序列化 怎么办
对于不想进行序列化的变量,使用 transient 关键字修饰;
当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复;
transient 只能修饰变量,不能修饰类和方法
Java和C++的区别
同:都是面向对象的语言,都支持封装、继承和多态
异:
- 指针:Java 不提供指针来直接访问内存
- 继承:Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多
继承,但是接口可以多继承。 - 内存管理:Java 有自动内存管理机制,不需要程序员手动释放无用内存
一、对象拷贝
什么是克隆
对数据进行拷贝
如何实现对象克隆
实现Clonable接口,实现clone()方法
深拷贝 vs 浅拷贝
- 浅拷贝:只拷贝对象本身,不拷贝对象的引用
- 深拷贝:对象本身+引用
二、语法
引用传递和值传递
Java只有值传递,
实参:要传递给方法的实际参数,在方法外面
形参:方法名的参数列表,在方法里面
值传递:对形参的修改不会影响到实参的值
引用传递:对形参的修改会影响到实参的值
JVM中划分了好几块内存区域,其中有一个栈空间和一个堆空间,创建的所有对象存放在堆中,基本数据类型和局部变量是存放在栈中的。
当操作对象时,对象是存放在堆中的,我们拿到的只是这个对象的引用,通过对象的引用,就可以操作对象;如果是基本数据类型,那就复制一份值,传递给形参;如果是引用类型,那就将引用赋值一份传递给形参,形参拿到的始终是一个副本,无论如何都无法通过形参改变实参,毕竟形参只是操作的副本而已
为什么Java只有值传递
概念:值传递:对形参的修改不会影响到实参的值;引用传递:对形参的修改会影响到实参的值
原因:实参传递给形参时,形参拿到的始终都是一个副本而不是实参本身,所以无论形参怎么改变都不会影响到实参的值,所以是Java只有值传递
== 和equals的区别
都用用来判断相等的
“==”:判断两个对象的地址是否相等
equals:永远都是比较内容。默认执行 = =;如果重写了就是比较对象的内容,String重写了equals,所以String在用equals的时候比较的是内容。
对象的相等 vs 指向他们的引用相等
- 对象的相等:比较的是内容
- 引用相等:在内存中的地址
两个对象hashCode()相同,equals()一定为true吗
不一定。
hashCode:获取哈希码,由哈希码来确定对象在哈希表中的索引位置(Java的任何类都有hashCode函数)
equals是比较两个对象是否想等的,hashCode相同只能说明它们的哈希码相同,被散列到相同的索引位置,但并不能说明两个对象相等。
排序
Collections.sort 和 Arrays.sort的区别
- Collections.sort默认调用Arrays.sort方法,底层实现都是TimSort实现的(这是jdk1.7新增的,以前是归并排序)
- TimSort算法:对于没有排好序的部分进行排序,然后再合并(就是找到已经排好序数据的子序列,然后对剩余部分排序,然后合并起来)
final
1)变量:
1)基本数据类型:数值初始化了之后不能被修改;
2)引用类型:初始化之后就不能再指向其他对象了
2)类:不可派生类,不能再被继承,final类中的所有成员方法也都被隐式地指定为final方法
3)方法:方法锁定,对于方法所在的类,它的子类是不能够修改这个方法(所有private方法都隐式地指定为final)
不能修饰接口和抽象类 interface abstractClass
static
将类的成员属性和成员变量定义为static时,就意味着将他们声明为静态属性和静态方法,,不用创建对象,直接通过类名就可以调用。
只能修饰变量和方法,被static修饰的成员随着类的加载而加载,生命周期和类一样;
没有被static修饰的变量和方法只能通过创建对象的形式调用(new 类名.方法名的方式),只能以对象的形式存在,被static修饰的成员是优先于对象存在的,静态的方法在调用非静态的成员时,非静态的成员还没有存在,所以不能调用非静态的变量或方法
在一个静态方法内调用一个非静态成员为什么是非法的
由于静态方法可以不通过对象进行调用,因此在静态方法里,不能调用其他非
静态变量,也不可以访问非静态变量成员。
静态方法和实例方法的区别
- 调用:调用静态方法需要创建对象,用“类名.方法名”的方式;实例方法不需要创建对象
- 静态方法只能访问静态成员变量和静态方法;实例方法则没有限制
内部类
在一个类中定义的类就是内部类,不同的内部类其实就是作用范围不一样
public:类在本程序的任何地方都能使用,不加则代表这个类只能在所处的包下访问,
成员变量和局部变量的区别
概念:成员变量是类的成员变量,局部变量是方法内的局部变量
- 内存:成员变量是对象的一部分,跟对象一起保存在堆中;局部变量保存在栈中
- 生存时间:成员变量是对象的一部分,它随着对象的创建而存在;局部变量在方法调用完毕后会消失
- 赋值:成员变量如果没有被赋初值,则会自动以类型的默认值而赋值;而局部变量则不
会自动赋值。
如何创建对象
new
对象实体与对象引用的区别
- 对象实体:new了之后存放在堆中的,可以n个引用指向它
- 对象引用:存放在栈中的,是指向某个对象的(指向0或1个对象)
返回值在类的方法里的作用
方法的返回值:执行某个方法后返回的数据
返回值的作用:用于接收某个过程的结果,这个结果可能会被用于其他操作
Stream
2.32 Stream有哪些方法
Stream提供了大量的方法进行聚集操作,
中间方法:中间操作允许流保持打开状态,并允许直接调用后续方法。
- mapToInt(),boxed()
末端方法:末端方法是对流的最终操作。当对某个Stream执行末端方法后,该流将会被“消耗”且不再可用。 - toArray(),forEach()
在数组和list做转换的时候,就会用到strem
Math函数常用的方法
min()max()abs()round()pow()exp()
round():round(-1.5)等于多少——-1
- 正数:正常的四舍五入,到5了就会进一
- 负数:到5了不会进一,超过5了才会进一
【参考】
BigDecimal对象
1)浮点数的计算
- 直接用float和double会精度丢失,因为计算机底层是二进制运算,而二进制不能精确地表示十进制小数(一般先用float和double,小数点太多了就可以使用BigDecimal)
- 使用BigDecimal对象,BigDecimal是不可变对象,他的操作都不能改变原有对象的值,方法执行完毕不能改变对象的值,如果要获取方法执行的结果,就需要重新赋值(String也是如此)
2)除法除不尽导致的无穷小数问题
- scale参数:运算后保留几位小数
- RoundingMode:计算小数的方式
3)BigDecimal的比较
- equals:比较值和精度,二者完全一样才一样
- 需要使用compareTo方法,比较的值(前面的)更大返回1,更小返回-1,相等返回0
获取键盘输入的方法
- 方法1:创建一个Scanner对象来接收
- 方法2:通过 BufferedReader
System.out用法和要注意的点
- 控制台输出
- System.out
- print:输出字符串,不换行
- println:输出一行字符串,换行
- printf:格式化输出
- System.err
关键:加锁
- 异常输出
- e.printStackTrace:打印堆栈信息,默认调用的是System.err
- 日志输出
SLf4j里的simple实现是使用了 System.out 和 System.err实现的
switch 和 if-else的区别
效率不一样
- switch:判断对的时候会对每个case生成一个map表,通过传入的值直接找到对应的map,然后执行相应的case里面的逻辑
- if-else:一行一行对比的,比完一个else了之后再比下一个else
分支比较多的时候用switch会比较好
三、Java的数据类型
基本数据类型
有8类,又4类:
- 整型:byte 1字节 / short 2字节 / int 4字节 / long 8字节
- 浮点型:float 4字节 /double 8自己
- 字符型:char 2字节
- 布尔型:boolean 没有明确规定
String不是基本数据类型
int 类型的数据范围
int 4字节,32位,1 位用来存符号,[- 231, 231-1]
实例变量的默认值
对于8 种数据类型:
byte:0
short:0
int:0
long:0L
float:0.0F
double:0.0
char:‘\u0000’ 空
boolean:false
四、字符串:String & StringBuilder & StringBuffer
String属于基础数据类型吗?
不属于
Java中操作字符串都有哪些类,它们都有哪些区别
1)可变性
与final关键字有关
-
String:是用final关键字来保存字符串的,所以不可变;修改的时候,都会新创建一个String对象,然后再将当前对象的指针指向新的String对象。
-
StringBuilder 与StringBuffer 都继承自 AbstractStringBuilder 类, AbstractStringBuilder 没有用 final 关键字修饰,所以这两种对象都是可变的。
2)线程安全
- String:安全
AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了
一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公
共方法。 - StringBuilder 没有对公共方法进行加同步锁,线程不安全的。
- StringBuffer 加了同步锁,所以是线程安全的。
3)性能
String < StringBuffer 地址不一样 用可变的字符串类,StringBuilder & StringBuffer都可以,然后调用reverse()方法 1)形式:字符常量是单引号引起的一个字符 字符串常量是双引号引起的 关键字是abstract 接口–Interface 抽象类–Abstract Class 抽象类可以有具体的方法,不一定都是抽象方法 1)实例化:普通类可以实例化,抽象类不能,因为抽象类中没有"足够的信息"来描绘一个对象 不能,final不可派生类,抽象类就没有意义了;也不能修饰接口 Java集合类主要派生自两大集合类:Collection 和 Map,Collection 又派生出 List、Set、Queue三大集合类;Java 所有集合类都是这四个接口的实现。 因为集合类不够具体,克隆和序列化是跟具体的语义和含义相关的 用来对集合类进行遍历的,在遍历的过程中可以对集合类内的元素进行操作 常用方法: List、Set、Queue、Map 首先,List和Set继承自Collection接口,都是单列集合 其次,Map是双列集合,存储的是键值对,key不能重复 不安全:大部分不安全ArrayList、LinkList、HashMap、TreeMap、HashSet、TreeSet 基本数据类型 - 包装类之间的转换 - “箱”-包装类 包装类是为了更好地面向对象,Java是一种面向对象的语言,但8种数据类型中的任何一种都不是对象,没有对象的特性。为了更好的面向对象,Java 为每一个基本数据类型都定义了一个包装类。 缓存池也叫常量池,是事先存储一些常用数据用于节省空间的一种技术。大部分的包装类型都实现和缓存池。 (小学刚开始学数学的时候)不同单位的数据是不能直接比较的,如果要比较,必须先进行单位的换算,不同的数据类型之间的比较也要先进行数据类型的转换。 int 基本数据类型,Integer 是包装类;== 是基本数据类型之间的比较,所以Integer 会自动拆箱成int类型,然后再进行比较;返回 true or false。 Set无序,不可重复的集合; 实现:ArrayList的底层是用数组来实现的 底层实现:ArrayList的实现是基于数组,LinkedList的实现是基于双向链表; 同: 异: ArrayList < Vector < inkedList 不一定 HashSet依赖与HashMap,它的值是存在HashMap的key中的,所以key不允许重复。 HashSet是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap。 基本原理:TreeMap 都是派生自Set包装类的,无序、都不能重复;都是线程不安全 两个接口 Dueue、BlockingQueue;抽象类 AbstractQueue 代表双端队列的能力 代表阻塞队列的能力,可以用来实现生产者、消费者模型 抽象队列,提供了默认的实现 add():插入失败,抛异常 element():获取失败,抛异常 remove():删除失败,异常 “操作失败时:熟悉的单词抛异常,不熟悉的单词返回false” BlockingQueue 提供了4 组不同的方法用于插入、移除以及对队列中的元素进行检查; BlockingQueue是一个接口,它的实现类有ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue。它们的区别主要体现在存储结构上或对元素操作上的不同,但是对于put与take操作的原理是类似的。下面以ArrayBlockingQueue为例,来说明BlockingQueue的实现原理。 首次扩容:先判断数组是否为空,若数组为空则进行第一次扩容(resize); 1. Collections工具类,将线程不安全的Map包装成线程安全的Map; 都是无序、不能重复集合; 目的:优化查找性能 hash算法:取模, 1)先扩充数组: 2)链表转红黑树:(检查链表长度转换成红黑树之前,还会先检测当前数组数组是否到达一个阈值(64),如果没有到达这个容量,会放弃转换,先去扩充数组)为了解决碰撞,数组中的元素是单向链表类型。当链表长度到达一个阈值时(7或8),会将链表转换成红黑树提高性能(而当链表长度缩小到另一个阈值时(6),又会将红黑树转换回单向链表提高性能。) 首先,用红黑树是为了优化查找效率,B树一个节点可以存好多个数据,在数据量不是很多的情况下,数据都会“挤在”一个结点里面,这时候优化的效果并不是特别的好;而且必输一般是用在外存上的,B树的高度就是磁盘存取的次数,磁盘存储本来就慢,就更达不到优化查找效率的效果了。 拿取模来讲,如果取模的结构都是1,就都会存到对应的单向链表中; **为了提高查找效率,遍历树为O(logn),链表的遍历为O(n) 还不是很理解 1)线程安全: HashMap是线程不安全的 JDK7:Segment数组+链表 要求有序 内存的存储与插入的顺序保持一致, LinkedHashMap可以避免对HashMap、Hashtable里的key-value对进行排序(只要插入key-value对时保持顺序即可),同时又可避免使用TreeMap所增加的成本。 1)LinkedHashMap继承于HashMap,很多方法直接继承自HashMap, 对key进行排序,升序降序可以自定义Comparator比较器;基于红黑树(Red-Black tree)实现的,时间复杂度是O(logn)。 结点为空色或者黑色;红色代表活跃的点; 所有的异常类都继承自Throwable,Throwable有两个子类:Error、Exception try:用于捕获异常,里面写的是业务逻辑的代码。(其后可接零个或多个 catch 块,如果没有 catch块,则必须跟一个 finally 块。) catch:用于处理 try 捕获到的异常。 finally:无论是否捕获或处理异常,finally 块里的语句都会被执行。finally可省略 在以下 4 种特殊情况下,finally 块不会被执行: finally 当在 try 块或 catch 块中遇到 return 语句时,会先执行finally再return。 修饰符,修饰类、方法、变量 异常处理的finally块 动词,方法名,在垃圾回收的时候会用到,如果这个对象没有被引用,那就会对这个对象效用finalize方法,一个对象如果没有被引用的话,那分配给它的内存就会被回收。 【参考】final、finally、finalize的区别 执行过程:首先需要准备好编译好的 Java 字节码文件(即class文件),计算机要运行程序需要先通过一定方式(类加载器)将 class 文件加载到内存中(运行时数据区),但是字节码文件是JVM定义的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解释器(执行引擎)将字节码翻译成特定的操作系统指令集交给 CPU 去执行,这个过程中会需要调用到一些不同语言为 Java 提供的接口(例如驱动、地图制作等),这就用到了本地 Native 接口(本地库接口)。 JVM在执行Java程序的过程中会把它所管理的内存划分为几个数据区:分别是 本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别只是 方法区和Java堆,它用于存储已被虚拟机加载的类和变量 PC是控制程序跳转的 栈 .java -> .class -> (JVM) 机器码 对象实例化过程,就是执行类构造函数的过程,会根据实例化时是否有参数、有几个参数来匹配构造方法,进而进行实例化。 栈外:元空间占用的是本地内存 类加载器: 双亲委派模型:要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。 会被破坏,但更具体的我就没有了解得那么多了。 垃圾回收是对对象的回收,对象保存在堆中,所以垃圾回收是发生在堆中的 原先,一块内存分配给了一个对象,但是这个对象在之后就再也没有被引用过了,那这块内存就变成了垃圾,Java虚拟机的一个系统级线程就会自动回收这个内存块。 引用计数算法:没有使用根集 可达性分析算法:GCRoot 分为新生代和老年代,回收的都是新生代;老年代最多是15代 IO用于实现对数据的输入与输出操作,Java把不同的输入/输出源抽象表述为Stream,然后就可以重新对数据进行操作。 举例:比如在list和int[]数组互相转换的时候,就会用到stream();如果是list转为int[]数组… 不是直接把数据读入内存,而是分多次读入。 缓冲区:维护了一个缓冲区,通过与缓冲区的交互,减少内存与设备的交互次数。 可以,但最多一个public 修饰,且与文件名相同 访问权限的修饰词有三个:public、protected、private;形成四个等级的访问权限:public、default 无修饰词、protected、private。 成员变量可以理解为全局变量,
注意:String可以直接=一个字符串,StringBuilder & StringBuffer必须得newString str = “i”;和String str = new String(“i”);的区别
所以这两个字符串用==判断的时候是不一样,用equals()才相等,所以为了保险起见,一般判断字符串相等都会用equals() public static void main(String[] args) {
String a = "i";
String aa = new String("i");
if(a == aa) System.out.println("==");//false
if(a.equals(aa)) System.out.println("equals");//true
}
字符串反转
String类常用的方法
char和String的区别字符型常量和字符串常量的区别
若干个字符
2)含义:字符常量相当于一个整形值( ASCII 值),可以参加表达式运算 字
符串常量代表一个地址值(该字符串在内存中存放位置)
3)内存:字符常量只占 2 个字节 字符串常量占若干个字节(至少一个
字符结束标志) (== char 在 Java 中占两个字节==)
五、抽象类
抽象类和接口的区别
概念:抽象类是对对象的抽象,接口是对动作的抽象;类在实现接口和抽象类的时候用的关键词不一样,接口是implements实现,抽象类是extends;
区别:
1)实例化:接口不能实例化,因为它不是对象,只有对象才能实例化;
抽象类不能被实例化,因为一个抽象类中没有"足够的信息"来描绘一个对象
2)类的实现:类可以实现多个接口,但只能继承自一个抽象类(单继承)抽象类必须要有抽象方法吗
普通类和抽象类的区别
2)继承:都能被继承,继承抽象类的子类必须要重写继承的方法(除非子类也是抽象类)
3)final:接口中的实例变量默认是 final 类型的,而抽象类中则不一定
【参考】抽象类能用final修饰吗
六、集合类
概念
集合类的基本接口
Collection 和 Collections 的区别
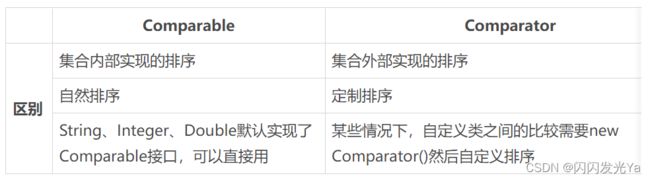
Comparable 和 Comparator 接口是干什么的?列出它们的区别。
集合类为什么没有实现Clonable和Serializable接口
什么是迭代器Iterator
Iterator怎么使用,有什么特点
特点:只能单向遍历Iterator和ListIterator的区别
如何确保集合不被修改
Java有哪些集合类
List、Map、Set 三个接口,存取元素时,各有什么特点?
线程安全/不安全的集合类
安全:Vector、HashTable自动装箱、自动拆箱
自动装箱:将基本类型赋值给包装类型,就完成了自动装箱
自动拆箱:将包装类型赋值给基本数据类型,就完成了自动拆箱为什么要有包装类
包装类+缓存池
在自动装箱时,如果基本数据类型的值在缓存的范围内,则不会重新创建对象,而是复用缓存池中实现创建好的对象。
Integer类型默认缓存了[-128, 127]的值,只要是这个范围的值自动装箱,都会返回相同的对象;所以如果是包装类型之间进行判断的话,要用equals(),不能用==,因为不同包装类缓存的范围不一样。
自动装箱:调用了包装类型的valueOf()方法
自动拆箱:调用了xxxValue()方法(如intVaule())
所以,在创建包装类对象时,要么使用自动装箱的方法,要么使用valueOf()方法,而不要直接new,因为vauleOf()方法利用了缓存,而直接new是直接在堆里创建对象,没有利用缓存。Integer 和 Double类型要怎么判断相等
为了不损失精度,一般都是低精度向高精度转换,所以要把Integer 转成 Double,然后再进行比较。
int 和Integer有什么区别,二者在做 == 运算的时候会有什么结果?过程?
六-1、List
普通List
List和Set有什么区别?
List有序,可以重复的集合。
都由Collections工具类派生的ArrayList
介绍一下ArrayList的数据结构
随机访问:O(1)
首次插入:默认第一次插入元素时创建大小为10的数组,超出限制时会增加50%的容量,并且数据以 System.arraycopy() 复制到新的数组,因此最好能给出数组大小的预估值。
增删:数组末尾效率较高,按下标,需要移动数据,时间复杂度O(n),影响到性能。Array和ArrayList的区别
ArrayList和LinkedList的区别
时间复杂度:随机访问O(1);O(N)
插入删除:链表会方便一点,不需要移动
内存:LinkedList比ArrayList更占内存,上一个指针,下一个指针ArrayList 和 Vector 的区别
ArrayList线程不安全;Vector线程安全(使用了synchronized 方法)ArrayList,Vector,LinkedList 的存储性能和特性
六-2、Set
Set那么用什么方法来区分重复与否呢
两个对象的内容相等,hashCode一定相等吗?
HashSet
HashSet的底层逻辑
它封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。HashSet和TreeSet的区别
TreeSet
原理
最大特点:有序
特殊方法:
celing: 返回>=传入值的最小值
floor: 返回<= 传入值的最大值
higher: 比传入值大的
lower: 比传入值小的
desendingSet: TreeSet倒序
pollFirst: 返回并删除第一个
pollLast: 返回并删除最后一个
使用场景:对调接口返回的数据,按某一维度排序、进行展示或别的消费??说一说TreeSet和HashSet的区别
区别:TreeSet可以实现排序,按自然顺序存储;HashSet是乱序
存储:TreeSet要自然排序,所以不能为null;HashSet就可以
实现:HashSet底层是采用哈希表实现的,而TreeSet底层是采用红黑树实现的六-3、Queue
Queue大家族
Dueue
BlockingQueue
AbstractQueue
常用方法
add() offer() 插入
offer():插入失败返回falseelement() peek() 获取值
peek():获取失败,返回nullremove() poll() 删除
poll():删除失败,null
抛异常:add remove element
返回false:offer poll peek普通Queue
BlockingQueue
2.30 BlockingQueue 有哪些方法,为什么这样设计
2.31 BlockingQueue 是怎么实现的
六-4、Map
1. 普通Map
Map接口有哪些实现类
如果需要用到线程安全的话,那就可以使用Collections工具把线程不安全的包装成线程安全的。Map put的过程
计算索引:通过hash算法,计算键值对在数组中的索引–哈希码;
插入数据:
如果当前位置元素为空,则直接插入数据;
如果当前位置元素非空,且key已存在,则直接覆盖其value;
如果当前位置元素非空,且key不存在,则将数据链到链表末端;
若链表长度达到8,则将链表转换成红黑树,并将数据插入树中;
再次扩容:如果数组中元素个数(size)超过threshold,则再次进行扩容操作。如何得到一个线程安全的Map
2. 使用ConcurrentHashMap
不建议使用Hashtable,虽然Hashtable是线程安全的,但是性能较差。Map和Set有什么区别?
Set存的是元素,Map存的元素的键值对,Map的key是一个Set集合,所以key不能重复。2. HashMap(重点)
HashMap put的过程(1.7 和1.8的区别)
HashMap有哪些特点
JDK7、JDK8实现的HashMap有什么区别
JDK7:数组+链表,hashCode哈希码冲突,链表太长,查找的时候时间消耗很高,降低了查找的效率,O(n)
JDK8:数组+链表+红黑树,链表长度超过8的时候,采用红黑树存储,O(logn),查找效率得到优化HashMap 的底层实现原理
存–put:调用hashCode获取哈希码,进而得到bucket的位置,存到相应链表
取–get:调用hashCode获取哈希码,然后到对应的bucket中查找HashMap 的扩容机制
首先:判断是否要扩容,是则按2的n次方扩充,更大的数组能在一定程度上减少碰撞(还有一个说法就是使用位运算代替取模预算(据说提升了5~8倍))
判断是否要扩容:负载因子,元素个数与数组容量之比HashMap为什么用红黑树而不用B树?
HashMap hash函数设计思想
HashMap是如何解决哈希冲突的?
当链表长度到达8时,会将链表转换成红黑树提高查找性能;
而当链表长度缩小到另一个阈值时,又会将红黑树转换回单向链表提高性能。HashMap的底层结构
链表是如何转成红黑树的
为什么要用红黑树
HashMap 1.7中多线程的死循环的产生
HashMap和HashTable的区别
2)性能:
3)null作为key,valueHashMap和ConcurrentHashMap的区别
ConcurrentMap是线程安全的ConcurrentHashMap是怎么实现的
JDK8:Node数组+链表+红黑树
还有呢3. LinkedHashMap
使用场景
你对LinkedHashMap的理解
使用双向链表来维护key-value对的顺序
需要维护元素的插入顺序,因此性能略低于HashMap的性能,但因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时将有较好的性能。请介绍LinkedHashMap的底层原理
2)特点是维持插入顺序,所以维护的是双向链表,HashMap是单向链表4. TreeMap
2.21 TreeMap的底层逻辑
红黑树的节点是Entry类型的,它包含了红黑树的6个基本组成:key、value、left、right、parent和color。什么是红黑树
根叶黑:根只能为黑色,每个叶子结点都是黑色的空结点;
不红红:不能有连续的红色结点
黑路同:从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点;
七、异常
Throwable异常类
总述

常见的异常类
1.空指针异常
2.ClassNotFoundExceptionThrowable常用方法
throw和throws的方法
异常处理
try-catch-finally
1.在 finally 语句块中发生了异常。
2.在前面的代码中用了 System.exit()退出程序。
3.程序所在的线程死亡。
4.关闭 CPU。try-catch-finally那部分可以省略
如果在catch中return了,finally还会执行吗
final、finally、finalize的区别
final
finally
finalize
八、JVM
JVM的结构
JVM包含哪几部分
5.6 Java内存分布情况
本地方法栈、程序计数器、虚拟机栈、|| 堆、数据区5.4 本地方法栈有什么用
本地方法栈:为虚拟机使用到的本地(Native)方法服务
虚拟机栈:为虚拟机执行Java方法(也就是字节码)服务5.7 类存放在哪里
5.5 没有程序计数器PC会怎样
没有PC,程序不能正常地跳转,进程也不能够进行正常的切换。5.8 局部变量存放在哪里
5.9 Java代码编译过程
5.11 对象实例化的过程
5.12 元空间在栈内还是栈外
类加载器
对JVM类加载器的理解
双亲委派模型
(Java平台通过委派模型去加载类。每个类加载器都有一个父加载器。)
1、当需要加载类时,会优先委派当前所在的类的加载器的父加载器去加载这个类。
2、如果父加载器无法加载到这个类时,再尝试在当前所在的类的加载器中加载这个类。5.14 双亲委派机制会被破坏吗?
垃圾回收
1. Java的垃圾回收机制
1)发生在哪里
2)什么时候可以被回收
3)确定一个对象是否可以被回收:
该算法使用引用计数器来区分存活对象和不再使用的对象。
每个对象对应一个引用计数器,初始时置为1;当对象被赋给任意变量时,引用计数器每次加1;当对象出了作用域后(该对象丢弃不再使用),引用计数器减1,一旦引用计数器为0,对象就满足了垃圾收集的条件。比如for循环里的循环变量i
从根对象开始,根据引用关系向下搜索,就是类似于图理论里面,一个对象就是一个结点,边就是引用关系,没有引用关系就没有边;如果根节点到某个点不可达,那就是他们之间没有引用关系,那这个对象就可以被回收。4)垃圾回收算法
2. 分代回收 GC
更详细的我还需要花一些时间
IO流
3.1 介绍一下Java中的IO流
3.2 怎么用流打开一个大文件
缓冲区是,缓冲区满了之后才能够读出;当缓冲区为空的时候才能写入。
多次对缓冲区的读出写入,从而实现大文件的读取。
其他
1.2 Java 文件可以有多个类吗
1.3 你对Java 访问权限的了解
修饰类:2 种权限:public、default
区别:作用范围在包这个等级,前:任意包下的任意类;后:当前包下的类。
修饰成员变量 / 成员方法:4 种权限
public:任意包的任意成员;default:当前包下的成员;protected:当前类的内部成员;private:只能被内部类的成员访问。1. 成员变量(全局变量)和局部变量的区别
作用范围:成员变量是整个类之内;局部变量是某个方法的范围内
默认初始值:成员变量无;局部-有