语义分割的常用指标详解
1 混淆矩阵
假设有6个类别,L为10个真实标签的取值,P为对应的预测的标签值,先计算对应的n(类别数,这里假设为6)xL+P:
bin的值一定是分类数的平方。混淆矩阵先将真实标签和预测标签抻成一维向量,做一个对应关系(nxL+P),再将这个对应的一维向量抻成二维矩阵,如下图,很奇妙地将真实值与预测值之间的像素点对应起来了。
如上图示例,混淆矩阵要表达的含义:
- 混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;
- 每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目;每一列中的数值表示真实数据被预测为该类的数目。
若类别数n为2,则混淆矩阵可表示为下面的形式:

True Positive(TP):真正类。样本的真实类别是正类,并且模型识别的结果也是正类。
False Negative(FN):假负类。样本的真实类别是正类,但是模型将其识别为负类。
False Positive(FP):假正类。样本的真实类别是负类,但是模型将其识别为正类。
True Negative(TN):真负类。样本的真实类别是负类,并且模型将其识别为负类。
从混淆矩阵当中,可以得到更高级的分类指标:Accuracy(精确率),Precision(正确率或者准确率),Recall(召回率),Specificity(特异性),Sensitivity(灵敏度)。
2 分类指标
我们假设总共有k+1个类(从![]() 到
到![]() ,包括一个void class 或 background),
,包括一个void class 或 background),![]() 表示的类别i被推断为类别j的像素量。
表示的类别i被推断为类别j的像素量。
2.1 准确率(Accuracy):精确率是最常用的分类性能指标。可以用来表示模型的精度,即模型识别正确的个数/样本的总个数。一般情况下,模型的精度越高,说明模型的效果越好。是针对原来的所有样本而言的。
Accuracy=(TP+TN)/(TP+FN+FP+TN)
2.2 精确率(Precision):又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。一般情况下,查准率越高,说明模型的效果越好。大白话为“你预测为正例的里面有多少是对的”,是针对预测结果而言的。
precision = TP/(TP+FP)
2.3 召回率(Recall):又称为查全率,召回率表现出在实际正样本中,分类器能预测出多少。表示的是,模型正确识别出为正类的样本的数量占总的正类样本数量的比值。一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。是针对原来的正样本而言的。
Recall(召回率) = Sensitivity(敏感指标,True Positive Rate,TPR)= 查全率
Recall = TP/(TP+FN)
查准率和查全率是一对矛盾的指标。一般来说,查准率高时,查全率旺旺偏低;二查全率高时,查准率往往偏低。
2.4 特异度(Specificity):特异性指标,表示的是模型识别为负类的样本的数量,占总的负类样本数量的比值。
Specificity = TN/(TN +FP)
负正类率(False Positive Rate, FPR),计算公式为:FPR=FP/(TN+FP),计算的是模型错识别为正类的负类样本占所有负类样本的比例,一般越低越好。
Specificity = 1 - FPR
2.5 Fβ_Score:Fβ的物理意义就是将正确率和召回率的一种加权平均,在合并的过程中,召回率的权重是正确率的β倍。
F1分数认为召回率和正确率同等重要,F2分数认为召回率的重要程度是正确率的2倍,而F0.5分数认为召回率的重要程度是正确率的一半。比较常用的是F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。
F1_Score:数学定义为 F1分数(F1-Score),又称为平衡 F分数(Balanced Score),它被定义为正确率和召回率的调和平均数。在 β=1 的情况,F1-Score的值是从0到1的,1是最好,0是最差。
2.6 ROC曲线&AUC
ROC曲线作用:评价一个值分类器的优劣,在敏感度和特异度之间找一个平衡
ROC曲线特点:正负样本分布发生变化或阈值选取发生变化时, ROC曲线不会随之发生变化
横轴表示1 - 特异度,记为x(t);纵轴表示敏感度,记为y(t)。 t为阈值,对应图中的V,即图中表示当t=0.49时的ROC曲线
真正率(TPR) = 灵敏度 = TP/(TP+FN)
假正率(FPR) = 1- 特异度 = FP/(FP+TN)
注意:我们发现TPR和FPR分别是基于实际表现1和0出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。正因为如此,所以无论样本是否平衡,都不会被影响。举个例子,总样本中,90%是正样本,10%是负样本。我们知道用准确率是有水分的,但是用TPR和FPR不一样。TPR只关注90%正样本中有多少是被真正覆盖的,而与那10%毫无关系,同理,FPR只关注10%负样本中有多少是被错误覆盖的,也与那90%毫无关系,所以可以得出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用TPR和FPR作为ROC/AUC的指标的原因。

1 - 特异度 = FP/(TN+FP) :健康人中有多少被预测为有 病,越低越好
敏感度 = TP / (TP + FN):有病的样本中有多少被预测为有病,越高越好
两者相互抑制,敏感度越大越好,1-特异度越小越好
ROC曲线中的四个点:
(0,0)表示都无病
(1,0)结果最差,即有病的样本全部预测为无病,无病的样 本全部预测为有病
(0,1)结果最好,即有病的样本全部预测为有病,无病的样 本全部预测为无病
(1,1)表示都有病
ROC曲线越靠近(0,1)点越好,越偏离中心斜45度线越
AUC是ROC曲线下面积大小,取值范围[0,1],越大越好
AUC含义:随机选取一对正负样本,正样本得分 > 负样本得分的概率
AUC特点:不随正负样本分布的改变而改变,不随阈值的改变而改变。分类器需要给定阈值,如阈值为0.5时,表示分类结果>0.5的样本为正样本,<0.5的样本为负样本。阈值的选取会影响基础指标,如Acc等是可以通过改变阈值(超参)找到最优解的。
2.7 Pixel Accuracy(PA):即像素精度。标记正确的像素占总像素数的比例。
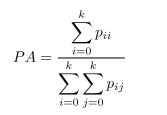
2.8 Mean Pixel Accuracy(MPA):即均类像素精度。每个类被正确标记的像素个数的比例,再求所有类的平均。

2.9 Intersection over Union(IoU):即交并比。真实和预测的交集/真实和预测的并集,图像分割面向的是真实掩码和预测掩码的交集和并集。求出来不是一个数,而是类别数目个数,每个类别算出来一个数。也称为Jaccard相似系数(Jaccard similarity coefficient)。而Jaccard distance的值则等于(1-Jaccard系数)。
2.10 Mean Intersection over Union(MIoU):即平均交并比。该指标是各种基准数据集最常用的标准之一,绝大多数的图像语义分割论文中的模型评估比较都以此作为主要评估指标。IoU是计算每个类别的,这里求其平均。

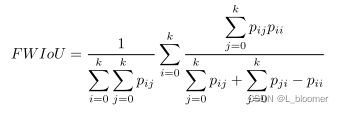
2.11 Frequency Weighted Intersection over Union(FWIoU):即频率权重交并比。是对原始 MIoU 的改进,它会根据每个分类出现的频率,对每个类给予不同权重。
2.12 dice similarity coefficient (dice)系数:传统的分割任务中,IOU是一个很重要的评价指标,而在三维医学图像分割领域,大部分的paper和项目采用dice系数来评价模型性能。
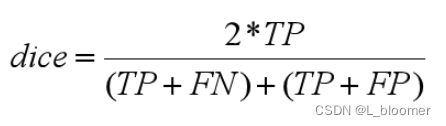
3 混淆矩阵延申出各个评价指标
从混淆矩阵中,可以衍生出各种评价的指标。如下是截取的wiki上的一个截图

参考:
[机器学习笔记] 混淆矩阵(Confusion Matrix)
混淆矩阵、精确率、召回率、F1值、ROC曲线、AUC曲线