Flink 入门案例和部署模式
1.Flink相关依赖
org.apache.flink
flink-scala_2.11
1.10.0
org.apache.flink
flink-streaming-scala_2.11
1.10.0
net.alchim31.maven
scala-maven-plugin
3.4.6
compile
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
1.2批处理案例
object wordCountBetch {
def main(args: Array[String]): Unit = {
//创建执行的环境
val env:ExecutionEnvironment =ExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
val wordAgg: AggregateDataSet[(String, Int)] = env.readTextFile("D:\\ideaProject\\flink-base\\test.txt").flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1)
wordAgg.print()
}
}
1.3流式处理案例
object wordCountStream {
def main(args: Array[String]): Unit = {
//创建执行的环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
val wordDS: DataStream[(String, Int)] = env.socketTextStream("127.0.0.1",9999).flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
wordDS.print()
//执行job
env.execute()
2.Flink 部署模式
逻列下flink的各种模式,在实际的生产中,方便使用
2.1 local 单机模式 测试环境使用
2.2 standalone集群模式 生产环境使用
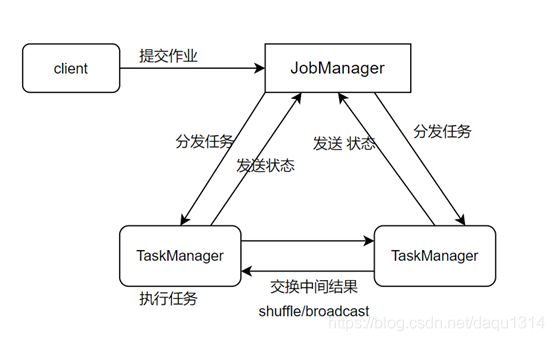
2.2.1阐述
Client:提交任务
JobManager:分发任务,接收反馈
TaskManager:接收任务,执行任务,反馈结果
2.2.2执行指令 案例
bin/flink run \
/export/servers/flink-1.6.0/examples/batch/WordCount.jar \
--input hdfs://cdh1:8020/test/input/wordcount.txt \
--output hdfs://cdh1:8020/test/output/result.txt \
2.3 Flink on yarn
2.3.1 Session-cluster 模式(时间短,规模小的作业)
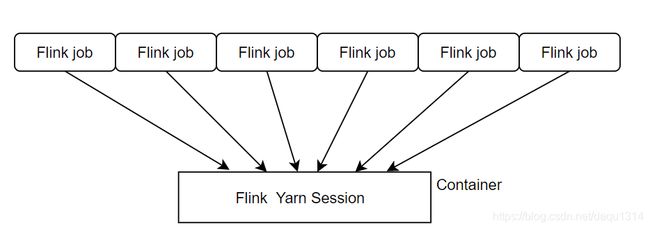
2.3.1.1阐述
Session-cluster 模式流程: 客户端提交作业,接着会向yarn申请资源,资源是固定的永久不变的,如果资源满了,下个flinkjob任务,就会无法提交任务,只有等到,当前的资源释放,才能执行下个flinkjob.
2.3.1.2 执行指令
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d-n :TaskManager的数量
-s 每个TaskManager的slot数量 默认的是 每个taskManager的slot个数是1,默认一个slot一个core
-jm:Jobmanager内存(MB)
-tm:taskManager 内存(MB)
-d:后台执行
./flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777是否运行可以查看 node01:8088
yarn application --kill application_1577588252906_00022.3.2 Per-Job-Cluster 模式(时间长,规模大的作业)
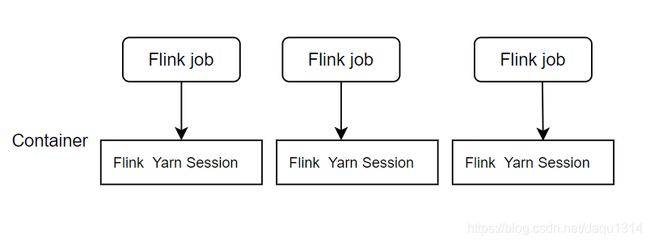
2.3.2.1阐述
一个flinkJob 对应一个集群,每个flinkjob提交任务时 都会单独的向yarn申请资源.一个作业失败不会影响到其他的任务的继续运行
2.3.2.2执行指令
./flink run –m yarn-cluster -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777